基于多结构卷积神经网络特征融合的场景分类方法及系统与流程
本发明涉及数字图像处理技术领域,特别涉及到遥感图像处理,具体涉及基于多结构卷积神经网络特征融合的场景分类方法及系统。
背景技术:
随着卫星遥感技术的发展,遥感图像场景分类成为了一个活跃的研究课题,其目的是将提取出的覆盖多种地面类型或地面对象的遥感图像子区域划分为不同的语义类别,它已经广泛用于各种实际遥感应用,如土地资源管理,城市规划等。学习高效的图像表示是遥感图像场景分类任务的核心。由于实际场景图像之间的高类内差异性和高类间相似性,基于具有低级别手工设计特征的特征编码方法或无监督特征学习的场景分类任务的方法仅能够生成具有有限表示能力的中级图像特征,这从根本上限制了场景分类任务的性能。
最近,随着深度学习尤其是卷积神经网络的发展,卷积神经网络在对象识别和检测方面表现出惊人的性能。不少研究者也将其用于遥感图像场景分类中,且取得了非常好的分类性能。虽然目前的方法可以进一步提高分类性能,但这些方法的局限性之一是只使用一种卷积神经网络结构提取场景图像的特征,而忽略了不同卷积神经网络结构提取特征的互补性。这在一定程度上制约了它的实际应用,所以如何将卷积神经网络更好的应用到遥感图像分类的算法模型中,提高分类精度,是卷积神经网络研究中需要研究解决的主要问题。
技术实现要素:
本发明要解决的技术问题在于,针对上述目前遥感图像处理过程中分类精度不高的技术问题,提供基于多结构卷积神经网络特征融合的场景分类方法及系统解决上述技术缺陷。
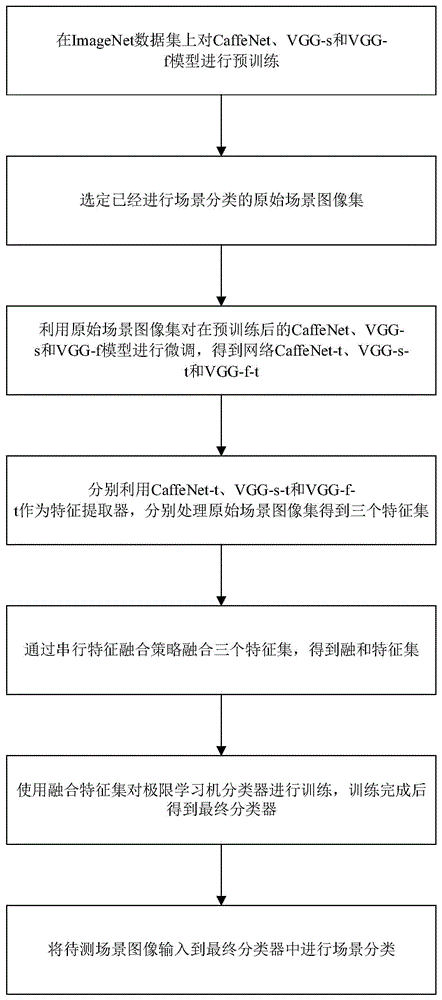
基于多结构卷积神经网络特征融合的场景分类方法,包括:
s1、选择caffenet、vgg-s和vgg-f模型,在imagenet数据集上对caffenet、vgg-s和vgg-f模型进行预训练;
s2、选定已经进行场景分类的原始场景图像集;
s3、利用原始场景图像集对在预训练后的caffenet、vgg-s和vgg-f模型进行微调,得到网络caffenet-t、vgg-s-t和vgg-f-t;
s4、分别利用caffenet-t、vgg-s-t和vgg-f-t作为特征提取器,分别处理原始场景图像集,以提取原始场景图像集中的每一张图像的特征,从卷积神经网络的倒数第二个全连接层得到特征集fcaffe-t、fvgg-s-t和fvgg-f-t;
s5、通过串行特征融合策略融合三个特征集fcaffe-t、fvgg-s-t和fvgg-f-t,得到融和特征集;
s6、使用融合特征集对极限学习机分类器进行训练,训练完成后得到最终分类器;
s7、将待测场景图像输入到最终分类器中进行场景分类。
进一步的,所述步骤s3中对caffenet、vgg-s和vgg-f模型进行微调具体包括:
s31、设定微调迭代次数n、学习率α和批尺寸mini_batch;
s32、正向传播训练:计算在当前的系数下,该网络结构具有的真实分类效果,迭代过程如下:
xi+1=fi(ui),
ui=wixi+bi,
其中,xi为第i层的输入;wi是第i层的权值向量,它作用在其输入的数据中;bi为第i层的附加偏置向量;fi(·)表示第i层的激活函数,ui为对输入进行卷积操作后的结果;
s33、反向传播训练:通过网络输出与真实标签的比较,不断地迭代更新系数,使得输出结果接近期望值,迭代过程如下:
其中,学习率α为反向传播强度的控制因子,l(w,b)为损失函数;
s34、根据s31设定的迭代次数n,重复步骤s32和s33n次。
进一步的,所述步骤s4中,从caffenet-t的倒数第二个完全连接层中提取特征为fcaffe-t,从vgg-s-t的倒数第二个完全连接层中提取特征为fvgg-s-t,从vgg-f-t的倒数第二个完全连接层中提取特征为fvgg-f-t,特征维度都为4096。
进一步的,所述步骤s5中串行特征融合策略具体包括:
s51、使用kpca降维方法分别对每一个4096维的特征fcaffe-t、fvgg-s-t和fvgg-f-t进行降维,降维后的特征维度均为2048;
s52、使用串行特征融合的方法将降维后的特征进行融合,融合后的特征的维度为6144;
s53、使用kpca降维方法对融合后的特征向量再进行一次降维处理,最终得到的融合特征作为图像的最终表示,维度为4096。
基于多结构卷积神经网络特征融合的场景分类系统,包括:处理器及存储设备;所述处理器加载并执行所述存储设备中的指令及数据用于实现任意一种基于多结构卷积神经网络特征融合的场景分类方法。
与现有技术相比,本发明的有益效果在于:
1、针对卷积神经网络和极限学习机两者的优点和缺点,提出了使用卷积神经网络作为特征提取器,极限学习机作为分类器的遥感场景分类框架,可以充分发挥两者的优点,提高分类精度。
2、采用先降维再融合再降维的特征融合方法,可以在加快训练分类器速度和提高分类精度的前提下,最大程度的去除冗余信息和噪声以降低最终的特征向量的维度。
3、融合多结构卷积神经网络特征,融合后的特征能够充分利用不同卷积神经网络结构提取特征的互补性,能够有效的提高特征向量的区分性,可以显著提高卷积神经网络的分类性能,对遥感图像场景具有更好的特征表达能力和分类精度。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1为本发明基于多结构卷积神经网络特征融合的场景分类方法流程图;
图2为aid数据集示例图像;
图3为对aid数据集进行分类的混淆矩阵。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
基于多结构卷积神经网络特征融合的场景分类方法,如图1所示,包括:
s1、选择caffenet、vgg-s和vgg-f模型,在imagenet数据集上对caffenet、vgg-s和vgg-f模型进行预训练;
s2、选定已经进行场景分类的原始场景图像集;
s3、利用原始场景图像集对在预训练后的caffenet、vgg-s和vgg-f模型进行微调,得到网络caffenet-t、vgg-s-t和vgg-f-t;
s4、分别利用caffenet-t、vgg-s-t和vgg-f-t作为特征提取器,分别处理原始场景图像集,以提取原始场景图像集中的每一张图像的特征,从卷积神经网络的倒数第二个全连接层得到特征集fcaffe-t、fvgg-s-t和fvgg-f-t;
s5、通过串行特征融合策略融合三个特征集fcaffe-t、fvgg-s-t和fvgg-f-t,得到融和特征集;
s6、使用融合特征集对极限学习机分类器进行训练,训练完成后得到最终分类器;
s7、将待测场景图像输入到最终分类器中进行场景分类。
步骤s3中对caffenet、vgg-s和vgg-f模型进行微调具体包括:
s31、设定微调迭代次数n、学习率α和批尺寸mini_batch;
s32、正向传播训练:计算在当前的系数下,该网络结构具有的真实分类效果,迭代过程如下:
xi+1=fi(ui),
ui=wixi+bi,
其中,xi为第i层的输入;wi是第i层的权值向量,它作用在其输入的数据中;bi为第i层的附加偏置向量;fi(·)表示第i层的激活函数,ui为对输入进行卷积操作后的结果;
s33、反向传播训练:通过网络输出与真实标签的比较,不断地迭代更新系数,使得输出结果接近期望值,迭代过程如下:
其中,学习率α为反向传播强度的控制因子,l(w,b)为损失函数;
s34、根据s31设定的迭代次数n,重复步骤s32和s33n次。
步骤s4中,从caffenet-t的倒数第二个完全连接层中提取特征为fcaffe-t,从vgg-s-t的倒数第二个完全连接层中提取特征为fvgg-s-t,从vgg-f-t的倒数第二个完全连接层中提取特征为fvgg-f-t,特征维度都为4096。
步骤s5中串行特征融合策略具体包括:
s51、使用kpca降维方法分别对每一个4096维的特征fcaffe-t、fvgg-s-t和fvgg-f-t进行降维,降维后的特征维度均为2048;
s52、使用串行特征融合的方法将降维后的特征进行融合,融合后的特征的维度为6144;
s53、使用kpca降维方法对融合后的特征向量再进行一次降维处理,最终得到的融合特征作为图像的最终表示,维度为4096。
本发明的实施例如下:
1、选取的原始场景图像集为aid数据集,该数据集包括airport、bareland、baseballfield、beach、bridge、center、church、commercial、denseresidential、desert、farmland、forest、industrial、meadow、mediumresidential、mountain、park、parking、playground、pond、port、railwaystation、resort、river、school、sparseresidential、square、stadium、storagetanks和viaduct等30个遥感图像场景类别,图像总数为10000个,如图2所示列出了每个类的一个示例图像。不同场景类别的图像数量从220到420不等,图像大小为600×600个像素,图像的空间分辨率从约8米变化到约0.5米;
2、对该图像数据集进行划分,每个类中随机选择20%的图像作为训练集(原始场景图像集),剩下的80%的图像作为测试集(待测场景图像);
3、根据卷积层滤波器数量和大小的不同,选择了3个不同结构的卷积神经网络caffenet、vgg-s和vgg-f作为实验模型;
4、利用训练集对在imagenet数据集上训练好的三个卷积神经网络caffenet、vgg-s和vgg-f进行微调,训练迭代次数为500次,得到微调后的网络caffenet-t、vgg-s-t和vgg-f-t;
5、分别利用caffenet-t、vgg-s-t和vgg-f-t作为特征提取器,处理原始场景图像集,从卷积神经网络的倒数第二个全连接层得到特征fcaffe-t、fvgg-s-t和fvgg-f-t;
6、使用kpca降维方法和串行特征融合策略融合不同结构卷积神经网络提取的特征fcaffe-t、fvgg-s-t和fvgg-f-t,将融合后的特征作为原始图像最终特征表示;
7、使用极限学习机(elm)分类器进行融合特征的最终分类,步骤如下:
(1)根据原始数据训练集和测试集的划分,将融合后的特征分为训练特征集和测试特征集;
(2)利用训练特征集训练支持极限学习机分类器;
(3)利用训练好的支持极限学习机分类器对测试特征集进行分类;
(4)计算最终的分类准确度。
实验得到的混淆矩阵如图3所示,其中横轴为真实值,纵轴为预测值。
从图3中可以看出,该方法在在13个类上的准确度超过了95%,得到的92.54%的总体准确度优于现有的很多最先进的方法,由此可以证明该方法用于遥感图像场景分类的有效性。一些类间差异较小的类型,如denseresidential、mediumresidential和sparseresidential也可以进行准确分类。然而,主要的混淆是school与commercial,resort和park之间的混淆。如图2所示,school与commercial有相同的图像分布;resort和park有类似的物体和图像纹理,例如绿化带和建筑物。因此,这些类很容易混淆。
表1列出了使用该方法的分类准确度以及使用单一卷积神经网络结构进行分类或作为特征提取器的分类准确度。从表中可以看出,通过融合3个简单cnn结构的全连接层特征,可获得比单一cnn更好的分类性能,这也表明利用不同cnn结构提取特征的互补性,可以显著提高cnn的分类性能。另外,卷积神经网络与极限学习机结合可以提高分类准确度。
表1
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!