一种基于知识库的服刑人员个性化循证矫正推荐方法与流程
本发明涉及个性化推荐领域,具体涉及一种基于知识库的服刑人员个性化循证矫正推荐方法。
背景技术:
随着数据分析技术和互联网+在不同行业中的深入,基于数据分析的服刑人员改造工程业务需求愈加强烈。在高管制、反侦察的监狱对抗环境下,传统的调查问卷、量表等研究方法存在手段单一、主观性强的问题,并且随着时间的累积,服刑人员的数据信息呈现爆炸性增长的趋势,在大数据环境下如何高效的选取矫正策略成为下一步研究的热点。
近年来,为了提高教育改造质量,降低再犯罪率,监狱系统率先引入了“循证矫正”的概念和方法,并在多个单位开展循证矫正的试点工作。由于针对服刑人员的循证矫正策略在国内发展不平衡、推广程度低,适应于国内服刑人员的循证矫正策略仍在积极探索之中,随着互联网+在各行各业的逐步深入以及知识库技术的大量应用,结合个性化推荐技术对循证矫正策略进行深入研究探索,具有深远的研究前景和广阔的应用空间。
技术实现要素:
本发明的目的是基于当前对个性化推荐技术和循证矫正研究的基础之上,提出了一种提高循证矫正策略个性化推荐的精度,在更好地矫正服刑人员的同时减少了监管人员的工作量的基于知识库的服刑人员个性化循证矫正推荐方法。
本发明具体采用如下技术方案:
一种基于知识库的服刑人员个性化循证矫正推荐方法,具体包括以下步骤:
步骤一:服刑人员画像建模;
步骤二:在服刑人员画像建模和案例知识库的基础上,融合情景感知信息,结合张量分解算法和基于回归树的上下文自动编码技术,综合考虑服刑人员、矫正策略、上下文信息对矫正效果的影响;
步骤三:利用终端设备干警干预信息和服刑人员交互信息,通过基于q-learning的强化学习框架对循证矫正方法进行不断的评估、反馈,动态调整矫正方法智能推荐算法模型,实现基于服刑人员全维度画像的循证矫正;
步骤四:针对终端设备矫正资源,利用标签信息对矫正资源进行分析与筛选,形成面向服刑人员的完整矫正方案。
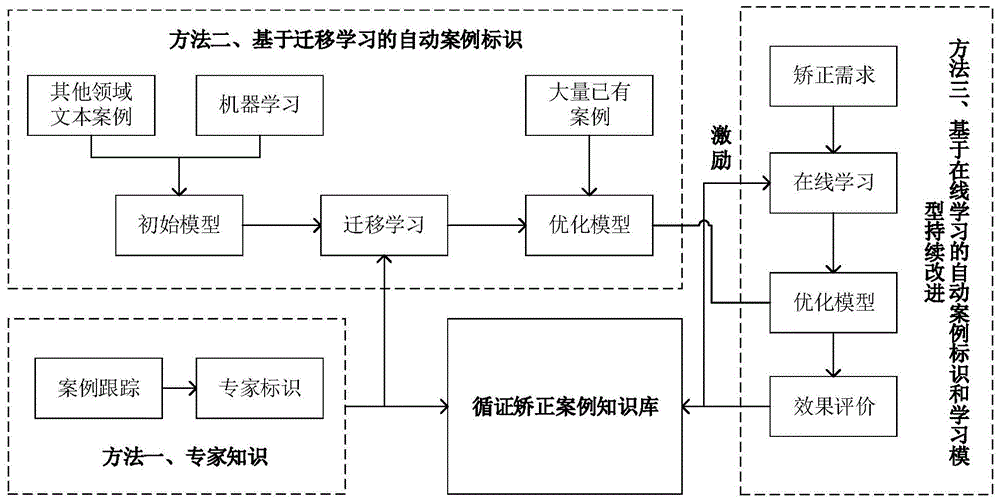
优选地,所述步骤二中的案例知识库的构建包括以下三种方法:
方法一:专家跟踪矫正案例,构成基本的专家标记的标准知识;
方法二:采用迁移学习法,将使用相关领域标准文本训练出的初始模型迁移到本案例知识库构建中,并结合专家标记的标准知识对初始模型进行优化,从而实现对非标准化案例进行自动语义识别;
方法三:采用在线增量学习法,结合实际使用过程中形成的矫正案例和矫正策略推荐系统推荐的矫正策略,在线提取案例知识和优化学习模型,持续对语义标识模型进行优化。
优选地,所述步骤一具体包括以下步骤:
1.1:自大规模服刑人员用户中完成信息的收集与处理,收集服刑人员的年龄、性别等静态数据;收集服刑人员的心理、生理等动态数据;
1.2:对收集到的服刑人员的动态、静态数据进行预处理;
1.3:利用服刑人员的年龄、性别以及案例记录等静态数据,通过式(1)所示的tf-idf算法,进行特征关键词提取生成服刑人员的个性化标签,完成用户静态属性建模;利用服刑人员的心理、生理等动态数据,通过逻辑回归算法进行用户动态行为建模;从静态和动态两个方面刻画服刑人员画像,构建服刑人员全维度画像模型,
其中,nij代表该词在文件dj中出现的次数,∑knk,j代表文件dj中所有词汇出现的次数总和,|d|代表是语料库中的文件总数,{j:ti∈dj}代表包含词ti的文件数目。
优选地,所述步骤二具体包括以下步骤:
在服刑人员画像建模和案例知识库的基础上,融合情景感知信息,结合张量分解算法和基于回归树的上下文自动编码技术,如式(2)所示,综合考虑服刑人员、矫正策略、上下文信息对矫正效果的影响。
其中,ymik和fmik表示服刑人员m在上下文k下对循证矫正策略i的实际打分和预测打分,bk表示上下文偏置,umd表示服刑人员m的d维隐语义向量的第d个元素,vid表示物品i的d维隐语义向量的第d个元素,ckd表示上下文k的d维隐语义向量的第d个元素。
优选地,所述步骤三具体包括以下步骤:
利用终端设备干警干预信息和服刑人员交互信息,通过基于q-learning的强化学习框架对循证矫正策略进行不断的评估、反馈,动态调整矫正策略智能推荐算法模型,实现基于服刑人员全维度画像的循证矫正策略个性化智能推荐算法,如式(3)所示
q(s,a)←q(s,a)+α[r+βmaxα'q(s',a')-q(s,a)](3)
其中,q(s,a)代表在状态s下使用循证矫正策略a的回报,α代表学习率,r代表服刑人员改造情况的即时反馈,β是折扣因子。
本发明具有如下有益效果:
该基于知识库的服刑人员个性化循证矫正推荐方法基于少量循证矫正专家知识和大量已有非标准化案例,构建结构化和标准化案例知识库,为矫正策略推荐系统提供支撑;基于服刑人员全维度画像建模的循证矫正策略个性化智能推荐算法,有效地缓解了服刑人员矫正策略单一的问题,提高了循证矫正策略个性化推荐的精度,在更好地矫正服刑人员的同时减少了监管人员的工作量。
附图说明
图1为循证矫正案例知识库的构建方法示意图;
图2为个性化智能推荐循证矫正推荐方法架构图。
具体实施方式
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
结合图1和图2,一种基于知识库的服刑人员个性化循证矫正推荐方法,具体包括以下步骤:
步骤一:服刑人员画像建模;
1.1:自大规模服刑人员用户中完成信息的收集与处理,收集服刑人员的年龄、性别等静态数据;收集服刑人员的心理、生理等动态数据;
1.2:对收集到的服刑人员的动态、静态数据进行预处理;
1.3:利用服刑人员的年龄、性别以及案例记录等静态数据,通过式(1)所示的tf-idf算法,进行特征关键词提取生成服刑人员的个性化标签,完成用户静态属性建模;利用服刑人员的心理、生理等动态数据,通过逻辑回归算法进行用户动态行为建模;从静态和动态两个方面刻画服刑人员画像,构建服刑人员全维度画像模型,
其中,nij代表该词在文件dj中出现的次数,∑knk,j代表文件dj中所有词汇出现的次数总和,|d|代表是语料库中的文件总数,{j:ti∈dj}代表包含词ti的文件数目。
步骤二:在服刑人员画像建模和案例知识库的基础上,融合情景感知信息,结合张量分解算法和基于回归树的上下文自动编码技术,综合考虑服刑人员、矫正策略、上下文信息对矫正效果的影响;
步骤二具体包括以下步骤:
在服刑人员画像建模和案例知识库的基础上,融合情景感知信息,结合张量分解算法和基于回归树的上下文自动编码技术,如式(2)所示,综合考虑服刑人员、矫正策略、上下文信息对矫正效果的影响。
其中,ymik和fmik表示服刑人员m在上下文k下对循证矫正策略i的实际打分和预测打分,bk表示上下文偏置,umd表示服刑人员m的d维隐语义向量的第d个元素,vid表示物品i的d维隐语义向量的第d个元素,ckd表示上下文k的d维隐语义向量的第d个元素。
案例知识库的构建包括以下三种方法:
方法一:专家跟踪矫正案例,构成基本的专家标记的标准知识;
方法二:采用迁移学习法,将使用相关领域标准文本训练出的初始模型迁移到本案例知识库构建中,并结合专家标记的标准知识对初始模型进行优化,从而实现对非标准化案例进行自动语义识别;
方法三:采用在线增量学习法,结合实际使用过程中形成的矫正案例和矫正策略推荐系统推荐的矫正策略,在线提取案例知识和优化学习模型,持续对语义标识模型进行优化。
步骤三:利用终端设备干警干预信息和服刑人员交互信息,通过基于q-learning的强化学习框架对循证矫正方法进行不断的评估、反馈,动态调整矫正方法智能推荐算法模型,实现基于服刑人员全维度画像的循证矫正;
步骤三具体包括以下步骤:
利用终端设备干警干预信息和服刑人员交互信息,通过基于q-learning的强化学习框架对循证矫正策略进行不断的评估、反馈,动态调整矫正策略智能推荐算法模型,实现基于服刑人员全维度画像的循证矫正策略个性化智能推荐算法,如式(3)所示
q(s,a)←q(s,a)+α[r+βmaxα'q(s',a')-q(s,a)](3)
其中,q(s,a)代表在状态s下使用循证矫正策略a的回报,α代表学习率,r代表服刑人员改造情况的即时反馈,β是折扣因子。
步骤四:针对终端设备矫正资源,利用标签信息对矫正资源进行分析与筛选,形成面向服刑人员的完整矫正方案。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!