基于视觉语义引导的图像去模糊方法与流程
本发明涉及计算机视觉和人工智能领域,尤其是涉及一种基于视觉语义引导的图像去模糊方法。
背景技术:
运动模糊是摄影中普遍存在的问题,尤其是在使用轻型设备时,例如移动设备手机和车载摄像头。为了消除运动模糊,已经提出了许多工作,其可以成功地增强具有光运动模糊的图像。最新的方法采用了生成性对抗网络(gan)来估计模糊和清晰图像之间的对抗性损失和特征一致性损失。去模糊的问题分为两种类型:盲目和非盲目的去模糊。早期作品主要关注非盲目去模糊,假设模糊核已知。最近,大多数去模糊的作品关注更实际但具有挑战性的情况,即盲目去模糊,其通常采用具有未知模糊核的卷积神经网络(cnn)。在模糊类型方面,模糊图像可以用均匀的或非均匀的模糊核合成用于训练。后者可以处理空间变化的模糊,这引起了广泛的研究关注。例如,一些工作采用完全卷积网络(fcn)来估计非盲解卷积后的运动流。但是,这种方法在训练期间需要提供先前的运动流图。为了克服这个缺陷,一些工作提出了一种基于u-net的端到端编码器-解码器模型,用于视频和单图像去模糊。另外一些工作提出了一种基于gan的图像去模糊与多分量损失函数,它实现了非均匀盲去模糊的最新结果。然而,所有上述工作都集中在去模糊轻微模糊的图像上,这些图像不能很好地处理具有模糊语义内容的严重模糊图像。
中国专利cn109345474a公开一种基于梯度域和深度学习的图像运动模糊盲去除方法,步骤是:采用引导滤波后梯度域图像作为基础图像,将l0滤波后梯度域图像及对应的清晰图像作为样本,将清晰图像与不同模糊核进行随机卷积,加上1%的高斯白噪声,生成运动模糊图像,前述引导滤波后梯度域图像、l0滤波后梯度域图像及运动模糊图像构成训练数据集;构造深度卷积神经网络,用训练数据集学习深度卷积神经网络的权重数据,学习到用于运动模糊核估计的深度卷积神经网络;提取网络训练的权重数据,获得运动模糊核,优化图像先验约束的去卷积函数,利用全变分项获得待处理运动模糊图像的去模糊图像。
中国专利cn108510451a公开一种基于双层卷积神经网络的重建车牌的方法,对清晰车牌图像基于随机模糊核做模糊处理,生成对应模糊车牌图像;从模糊车牌图像中截取固定尺寸的模糊图像块输入到预先设计好的去模糊卷积神经网络中,得到去模糊图像特征层;将同一块模糊车牌图像块输入到预先设计好的图像增强卷积神经网络中,得到图像增强掩码集;将去模糊图像特征层和图像增强掩码集合并成双层聚合特征集,训练模型获得重建卷积参数;将实际场景中的模糊车牌图像输入到双层卷积神经网络中与重建卷积参数卷积计算,得到重建后的车牌图像。本发明能够改善模糊退化图像的质量,同时提高图像对比度,提高图像的清晰度,增强图像的边缘和纹理细节信息。
尽管取得了令人兴奋的进展,但上述方法由于快速运动模糊导致的语义内容的含糊性,很难处理严重模糊的图像。因此在给定正确的语义指导的情况下,可以恢复更清晰的图像。事实上,即使给出了信息较少的严重模糊图像,人类也可以轻松地感知语义内容,然后在视觉皮层中的活动重建大脑中的场景。另一方面,推断语义内容(实体和关系)是许多高级语义相关计算机视觉任务的核心目标,如图像自动描述。因此,自然的想法是否可以利用图像自动描述来指导图像去模糊这一种新颖的自上而下的方式。
技术实现要素:
本发明的目的是采用基于结构化空间语义嵌入的全新深度学习网络设计,以解决图像(特别是严重模糊的图像)去模糊中没有考虑图像语义内容等问题,提供一种基于视觉语义引导的图像去模糊方法。
本发明包括以下步骤:
1)提出结构化空间语义嵌入模型,称为s3e-deblur,构造结构空间语义树(s3树)用于自动推断结构化内容和在推理期间提供结构化空间特征,连接图像语义理解和图像去模糊两大模块,在多任务中实现语义的建模和嵌入,以获得最佳的特征图;
在步骤1)中,所述构造结构空间语义树包括三个步骤:卷积解耦、卷积组合和语义分类,具体步骤如下:
(1.1)在卷积解耦中,首先从卷积神经网络cnn(采用通用的resnet-152模型)的最后一个卷积层中提取模糊图像的视觉特征图,然后将特征图卷积到不同的语义空间,即主语、对象和关系,以分离语义内容;
(1.2)在卷积组合中,语义树的两个子节点的特征图被卷积并合并到其父节点的特征图中;
(1.3)在语义分类中,根据预处理的实体/关系词汇表,每个节点的特征图被映射到实体/关系类别空间,其中特征图分别通过非线性函数,平均池化操作和完全连接操作,并转换为特征向量。
2)在模糊图像去模糊过程中,将步骤1)中获得的最佳的特征图采用卷积与合并操作输入到去模糊模块中;该去模糊模块基于树结构的生成对抗网络(gan)进行训练;其中损失函数包括:s3树引导的对抗损失以及s3树引导的内容损失;
在步骤2)中,所述将步骤1)中获得的最佳的特征图采用卷积与合并操作输入到去模糊模块中的具体方法可为:将步骤1)中得到的主语/关系/宾语的特征图以及对抗网络的生成器的卷积图进行再一次卷积的操作并嵌入到对抗网络的下一个卷积层中;通过这种方式,利用高级的语义信息对图像去模糊进行指导,生成比较清晰的图像;在训练阶段,利用gan的判别器对生成的图像和真实图像进行判别,从而实现在s3树的参数优化过程中优化去模糊的生成器和判别器参数。
3)模糊图像自动描述和图像去模糊协同训练,对树模型进行行优化。
在步骤3)中,所述模糊图像自动描述可采用常用的负对数似然作为重建损失来训练模糊图像自动描述模型;所述图像去模糊将s3树的分类损失、图像自动描述的重建损失、图像去模糊的对抗性损失联合最小化,从而得到最优的模型参数用于图像去模糊。
本发明将图像去模糊与图像自动描述联系起来以加强去模糊。为此,本发明解决了两个基本挑战,即在图像自动描述中建模语义并将语义嵌入到图像去模糊中。一方面,为了克服标题的任意语法,构造了一个结构化的语义树结构,其中语义内容(实体和关系)在给定严重模糊的图像的情况下被自动解析。另一方面,为了在空间上将语义内容与模糊图像对齐,为树节点设计空间语义表示,其中每个实体/关系以特征映射的形式表示,同时树结构的结点间进行卷积操作。
附图说明
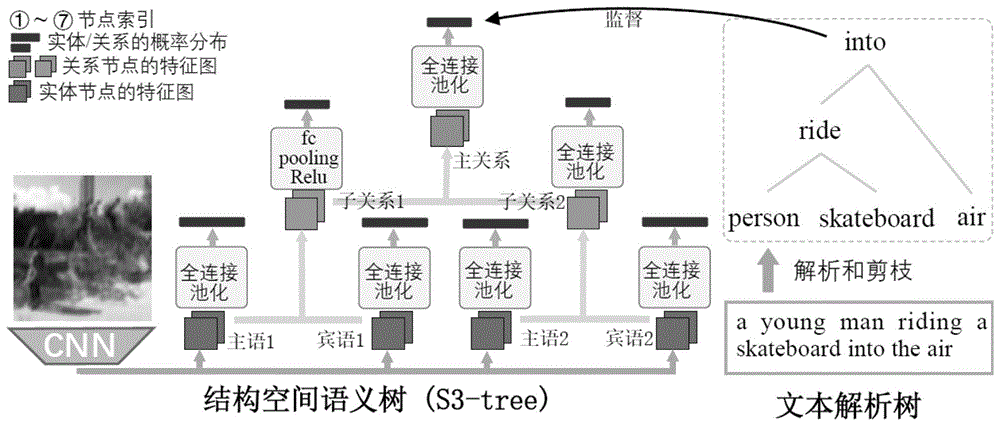
图1结构空间语义树模型框架图。输入模糊图像,模型在训练阶段在文本解析树的监督下完成图像语义树的自动构建学习,在生成树的阶段,模型能够自动对模糊图像自动构建语义树。
图2模型在通用的模糊图像数据集gopro上的效果。最左边是输入的模糊图像,中间是比较方法,最右边是本发明提出的方法。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
图1是结构空间语义树模型框架图。输入模糊图像,模型在训练阶段在文本解析树的监督下完成图像语义树的自动构建学习,在生成树的阶段,模型能够自动对模糊图像自动构建语义树。图2是模型在通用的模糊图像数据集gopro上的效果。最左边是输入的模糊图像,中间是比较方法,最右边是本发明提出的方法所得到结果。
本发明实施例包括以下步骤:
步骤1在模糊图像自动描述中,目的是在给定一对模糊图像和描述该图像的标题的情况下学习s3树模型的参数,其中树模型可用于自动推断结构化内容和在推理期间提供结构化空间特征。s3树的体系结构如图1所示,它由三个操作组成:卷积解耦,卷积组合和语义分类。
步骤1.1在卷积解耦中,首先从cnn(采用通用的resnet-152模型)的最后一个卷积层中提取模糊图像的视觉特征图。然后将特征图卷积到不同的语义空间,即主语,对象和关系,以分离语义内容。具体而言,将cnn提取到的视觉特征图通过卷积核映射到主语和宾语两种特征空间上(如图1所示),得到主语和宾语空间上的卷积特征图。这里的卷积核参数在模型训练过程中自动学习,从而使得给定cnn对应层上的任何一个特征图,都能够得到对应的主语和宾语空间上的卷积特征图,以此用于表示带有空间的实体语义结构信息;将得到的主语和宾语作为树的叶子节点。
步骤1.2在卷积组合中,树的两个子节点的特征图被卷积并合并到其父节点的特征图中。具体而言,我们将步骤1.1中得到的主语和宾语空间上的特征图通过卷积操作,合并到一个关系节点上(如图1所示),得到关系空间的特征图,以此用于表示带有空间的关系语义结构信息。这里的卷积核参数在模型训练过程中自动学习。
步骤1.3在语义分类中,根据预处理的实体/关系词汇表,将步骤1.1和步骤1.2中的每个节点的特征图映射到实体/关系类别空间,其中特征图分别通过非线性函数,平均池化操作和完全连接操作,并转换为特征向量。实体/关系的分类由文本解析树中的相应标签监督,即每个节点的特征向量用于计算实体/关系类别标签的交叉熵损失。由此,我们通过该损失对树模型的所有参数进行训练,实现空间结构化语义的自动表示。
步骤2在模糊图像去模糊中,将步骤1中获得的最佳的特征图采用卷积与合并操作输入到去模糊模块中。该模块基于树结构的生成对抗网络(gan)进行训练。其中损失函数包括:s3树引导的对抗损失以及s3树引导的内容损失。具体而言,我们将步骤1中得到的主语/关系/宾语的特征图以及对抗网络的生成器的卷积图进行再一次卷积的操作并嵌入到对抗网络的下一个卷积层中。通过这种方式,我们利用高级的语义信息对图像去模糊进行指导,生成比较清晰的图像。在训练阶段,我们利用gan的判别器对生成的图像和真实图像进行判别,从而实现在s3树的参数优化过程中优化去模糊的生成器和判别器参数。
步骤3为了优化树模型,提出模糊图像自动描述和图像去模糊协同训练的机制,其中对于图像自动描述,采用常用的负对数似然作为重建损失来训练模糊图像自动描述模型。s3树的分类损失,图像自动描述的重建损失,图像去模糊的对抗性损失被联合最小化,从而得到最有的模型参数用于图像去模糊。
综上,本发明设计了一种新型的深度学习网络结构,即结构化空间语义树结构,用以连接图像语义理解和图像去模糊两大模块,在多任务中实现语义的建模和嵌入。具体而言,提出了用于图像去模糊的结构化空间语义嵌入模型,称为s3e-deblur,其中构造结构化空间语义树(s3树)以桥接图像去模糊和图像自动描述。特别地,给定严重模糊的图像,其深度特征首先分别从图像去模糊和图像自动描述中的卷积神经网络(cnn)中提取。然后,通过使用所提出的s3树,将图像自动描述的特征映射分离成不同的语义(实体/关系)空间。之后,树节点的特征映射被耦合并嵌入到图像去模糊中的卷积层中。同时,语义标签(实体/关系)的预测概率分布被引入解码器(即,递归神经网络(rnn))以用于图像自动描述中的字幕生成。最后,对s3-tree,图像自动描述和图像去模糊进行协同训练,以多任务端到端方式优化整体模型。
- 还没有人留言评论。精彩留言会获得点赞!