一种基于深度强化学习的智慧家庭能量管理方法及系统与流程
本发明涉及一种基于深度强化学习的智慧家庭能量管理方法及系统,属于智慧家庭能量管理技术领域。
背景技术:
作为下一代电力系统,智能电网的典型特征是在电能产生、传输、分配和消耗过程中使用大量信息和通信技术(例如物联网技术)。在智能电网环境中,智慧家庭面临许多节省能量成本的机遇,例如通过智能调度能量存储系统和可控负载,从而利用电价时间分集特性降低能量成本。作为一种可控负载,暖通空调系统能量消耗约占家庭总能耗的40%,因而在节约能量成本方面具有极大潜力。由于暖通空调系统的主要目的是保证用户的热舒适,所以需要在不牺牲用户热舒适的情况下,最小化智慧家庭能量成本。
目前已有大量联合考虑智慧家庭能量优化和用户热舒适的研究工作,包括李雅普诺夫最优化方法、模型预测控制方法等。尽管在上述工作中已经取得了一些进展,但是这些方法需要用到简化的数学模型(例如,等效热参数模型)来模拟建筑热动力学模型。由于建筑热动力学模型受众多因素影响(如外部环境、太阳辐射强度、建筑材质、暖通空调系统的输入功率等),建立既准确又易于高效控制的建筑热动力学模型非常有挑战。为了克服该挑战,最近研究工作通过利用实时数据进行暖通空调系统的控制,其采用方法包括:多智能体强化学习、批量强化学习等。虽然基于强化学习的方法不需要建立建筑热动力学模型,但为处理高维状态空间而使用非线性函数估计器(例如:神经网络)来表征行为值函数时,这些方法表现出不稳定甚至不收敛。为了有效地处理高维连续状态空间,深度强化学习被提出且在atari和go游戏中得到了成功验证。此外,深度强化学习2017年被首次成功应用到建筑暖通空调系统控制中。然而,该工作采用的深度q网络并不适合高维连续的行为空间,原因是行为空间离散化时会导致行为数量呈爆炸式增长,进而导致低的计算效率、性能降级和需要更多的训练数据。在2019年,一些研究工作考虑了基于深度强化学习的室内热舒适控制。此外,部分工作考虑了基于深度强化学习的能量存储系统控制。然而,现有研究均未考虑智慧家庭环境下能量存储系统与暖通空调系统的联合协调调度,进而不能在动态环境下充分降低能量成本。
技术实现要素:
针对现有技术的不足,本发明的目的在于提供一种基于深度强化学习的智慧家庭能量管理方法及系统,以解决现有技术中存在的上述技术问题。
为解决上述技术问题,本发明提出了一种基于深度强化学习的智慧家庭能量管理方法,包括如下步骤:
获取智慧家庭的当前环境状态;
本地深度神经网络根据所述当前环境状态,输出能量存储系统或/和可控负载的当前行为;
根据所述当前行为,对能量存储系统或/和可控负载实施控制;
获取智慧家庭的下一时间步环境状态和下一时间步奖励;
将所述当前环境状态、所述当前行为、所述下一时间步环境状态、所述下一时间步奖励发送至云端经验池;
从云端经验池中提取训练样本集,以所述奖励最大化为目标,利用深度确定性策略梯度算法对云端深度神经网络进行训练;
将训练好的云端深度神经网络参数更新至本地深度神经网络。
进一步地,所述可控负载为暖通空调系统。
进一步地,所述环境状态的表达式如下:
st=(pt,bt,bt,ttout,tt,vt,t′),
式中,st为智慧家庭在t时刻的环境状态,pt为t时刻的分布式发电机输出功率,bt为t时刻的刚性负载需求功率,bt为t时刻的能量存储系统储能水平,ttout为t时刻的室外温度,tt为t时刻的室内温度,vt为t时刻的买电电价,t′为t时刻的当前绝对时间在一天内的相对时间。
进一步地,所述行为的表达式如下:
at=(ft,et),
式中,at为能量存储系统或/和暖通空调系统在t时刻的行为,ft为能量存储系统在t时刻的充放电功率,ft≥0表示充电,ft<0表示放电,et为暖通空调系统在t时刻的输入功率。
进一步地,所述奖励函数表达式如下:
rt=-β(c1,t(st-1,at-1)+c2,t(st-1,at-1))-c3,t(st),
式中,rt为t时刻的奖励,β为能量系统的成本相对于温度违背导致的惩罚成本的重要性系数,c1,t(st-1,at-1)为t时刻因能量买卖导致的惩罚,st-1为智慧家庭在t时刻的上一时间步的环境状态,at-1为能量存储系统或/和暖通空调系统在t时刻的上一时间步的行为,c2,t(st-1,at-1)为t时刻因能量存储系统折损产生的惩罚,c3,t(st)为t时刻因违背室内舒适温度范围导致的惩罚。
进一步地,能量存储系统存储水平的动态变化模型如下:
bt+1=bt+ηcct+dt/ηd,其中,
ηc∈(0,1],ηd∈(0,1],bmin≤bt≤bmax,
0≤ct≤cmax,-dmax≤dt≤0,ct·dt=0;
式中,bt+1为能量存储系统在t时刻的下一时间步的存储水平,bmin为能量存储系统的最小存储水平,bmax为能量存储系统的最高存储水平,ηc为能量存储系统的充电效率,ηd为能量存储系统的放电效率,ct为能量存储系统在t时刻的充电功率,dt为能量存储系统在t时刻的放电功率,cmax为能量存储系统充电功率最大值,dmax为能量存储系统放电功率最大值。
进一步地,暖通空调系统输入功率的动态变化模型如下:
0≤et≤emax;
式中,et为暖通空调系统在t时刻的输入功率,emax为暖通空调系统额定功率,所述暖通空调系统的输入功率能够连续调节。
进一步地,所述云端深度神经网络包括行动者网络、目标行动者网络、评论家网络、目标评论家网络,所述本地深度神经网络与行动者网络和目标行动者网络的结构相同;
本地深度神经网络输入层的神经元个数与环境状态的分量数相对应,本地深度神经网络隐藏层所采用的激活函数包括线性整流函数,本地深度神经网络输出层的神经元个数与行为的分量数相对应,本地深度神经网络输出层所采用的激活函数包括双曲正切函数或/和sigmoid函数;
评论家网络和目标评论家网络的结构相同,其输入层包括两个分别与环境状态和行为相关的独立子层,环境状态相关子层的神经元个数与环境状态的分量数相对应,行为相关子层的神经元个数与行为的分量数相对应,两子层分别连接有若干隐藏层,与两子层分别连接的若干隐藏层的最后一个隐藏层的神经元个数相同,所述最后一个隐藏层的输出求和后输入至新的隐藏层,所述新的隐藏层所采用的激活函数包括线性整流函数,与所述新的隐藏层连接的输出层所采用的激活函数包括线性激活函数。
为解决上述技术问题,本发明还提出了一种基于深度强化学习的智慧家庭能量管理系统,包括:
信息采集模块,用于获取智慧家庭的当前环境状态、下一时间步环境状态和下一时间步奖励,以及将所述当前环境状态、所述当前行为、所述下一时间步环境状态、所述下一时间步奖励发送至云端经验池;
本地深度神经网络,用于根据所述当前环境状态,输出能量存储系统或/和可控负载的当前行为;
行为控制模块,用于根据所述当前行为,对能量存储系统或/和可控负载实施控制;
在线学习模块,用于从云端经验池中提取训练样本集,以所述奖励最大化为目标,利用深度确定性策略梯度算法对云端深度神经网络进行训练,并将训练好的云端深度神经网络参数更新至本地深度神经网络。
与现有技术相比,本发明所达到的有益效果:本发明方法采用在线学习模式,即性能测试由本地深度神经网络完成,本地深度神经网络的参数由云端深度神经网络训练后定期更新。该能量管理方法可应对环境变化带来的性能降级,因而具有鲁棒性;且仅根据当前环境状态对能量存储系统的充放电功率和暖通空调系统的输入功率进行控制,无需知晓任何不确定性系统参数的先验信息和建筑热动力学模型,适用性广。
附图说明
图1是本发明具体实施方式提供的一种基于深度强化学习的智慧家庭能量管理方法所述马尔可夫决策过程示意图;
图2是本发明具体实施方式提供的一种基于深度强化学习的智慧家庭能量管理方法的工作流程图;
图3是本发明方法实施例所述本地深度神经网络的结构示意图;
图4是本发明方法实施例所述评论家网络和目标评论家网络的结构示意图;
图5是本发明方法实施例所述云端深度神经网络的训练过程示意图;
图6是本发明方法实施例与其他方法的性能对比图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
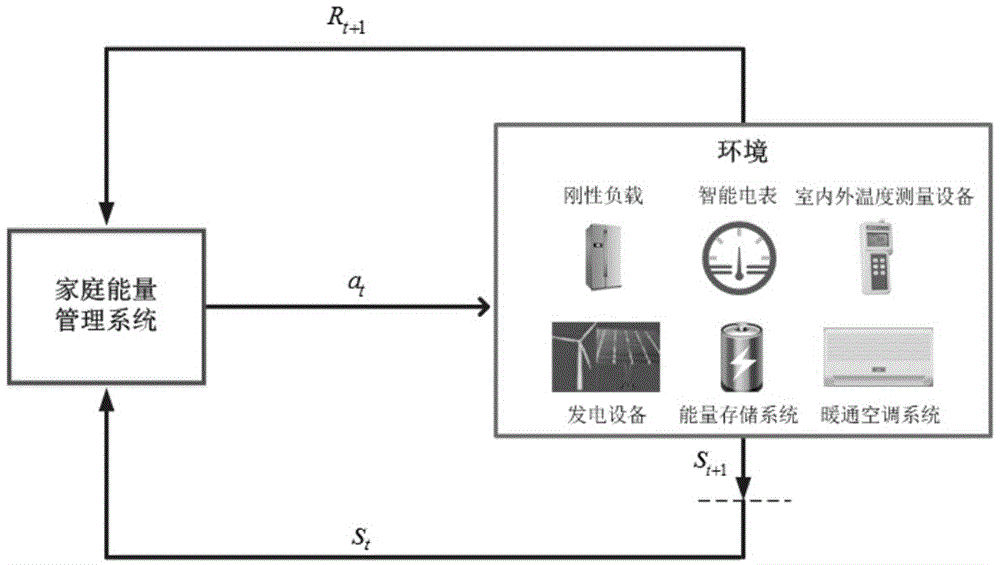
本发明具体实施方式提供了一种基于深度强化学习的智慧家庭能量管理方法,所述智慧家庭整体结构包括分布式发电机(如太阳能等)、能量存储系统、刚性负载(即不可调度的负载,如电冰箱等)、可控负载(即可调度的负载,如暖通空调系统)以及家庭能量管理系统。其中,家庭能量管理系统与分布式发电机、能量存储系统、刚性负载、暖通空调系统、智能电表、室内外温度测量设备以及云端之间存在信息交互。
由于存在来自多方面的不确定性(如太阳能等可再生能源的发电输出、刚性负载需求,室外温度和电价存在不确定性)和系统存在的时间耦合约束(能量存储系统的储能水平、室内温度动态性),设计出有效调度能量存储系统和暖通空调系统的最优能量管理方法非常具有挑战性。为克服上述挑战,本发明核心设计思想如下:首先,在无建筑热动力学模型和维持室内温度在舒适范围的情况下,将最小化智慧家庭能量成本这一能量管理问题建模为马尔可夫决策过程,如图1所示,是本发明具体实施方式提供的一种基于深度强化学习的智慧家庭能量管理方法所述马尔可夫决策过程示意图;然后,设计基于深度确定性策略梯度算法的能量管理方法,采用在线学习模式,本地行为选择所需深度神经网络的参数由云端训练后定期更新。该能量管理方法可应对环境变化带来的性能降级,因而具有鲁棒性;该方法仅仅根据当前环境状态对能量存储系统的充放电功率和暖通空调系统的输入功率进行行为选择,因而无需知晓任何不确定性系统参数的先验信息,适用性广。
如图2所示,是本发明具体实施方式提供的一种基于深度强化学习的智慧家庭能量管理方法的工作流程图,所述方法包括如下设计步骤:
步骤一,将在无建筑热动力学模型和维持室内温度在舒适范围的情况下最小化智慧家庭能量成本这一能量管理问题建模为马尔可夫决策过程,基于马尔可夫决策过程设计环境状态、行为、奖励函数。
在上述智慧家庭能量成本最小化问题中,目标函数是智慧家庭能量成本,包括智慧家庭与电网进行能量买卖产生的电费c1,t和能量存储系统充放电折损产生的费用c2,t,其表达式如下:
c2,t=ψ(|ct|+|dt|),
式中,c1,t为t时刻智慧家庭与电网进行能量买卖产生的电费,c2,t为t时刻能量存储系统充放电折损产生的费用,vt为t时刻的买电电价,ut为t时刻的卖电电价,gt为t时刻智慧家庭与电网买卖的电量,ψ为能量存储系统的折旧系数,ct为t时刻能量存储系统的充电功率,dt为t时刻能量存储系统的放电功率;当gt>0时,智能家庭买电,成本为c1,t=vtgt;gt≤0时,成本为c1,t=utgt。
由于还需要维持室内温度在舒适范围,因而该马尔可夫决策过程的决策变量有:智慧家庭与大电网之间的能量买卖数量、能量存储系统的充放电功率、暖通空调系统的输入功率;需考虑的约束有:与能量存储系统相关的约束、与暖通空调系统相关的约束、与能量守恒相关的约束,具体如下:
(1)能量存储系统存储水平的动态变化模型为:bt+1=bt+ηcct+dt/ηd,式中,bt+1为能量存储系统在t时刻的下一时间步的存储水平,bt为能量存储系统在t时刻的存储水平;ηc∈(0,1],为能量存储系统的充电效率;ηd∈(0,1],为能量存储系统的放电效率。为不失一般性和描述简便,假定t的长度为1小时,则功率和电量可以交替使用。
(2)由于能量存储系统的容量有限,能量存储系统存储水平bt应处于能量存储系统的最小存储水平bmin与最高存储水平bmax之间,即:bmin≤bt≤bmax。
(3)能量存储系统的充电功率和放电功率均受限于其对应的额定功率,即:0≤ct≤cmax,-dmax≤dt≤0,式中,cmax为能量存储系统的充电功率最大值,dmax为能量存储系统的放电功率最大值。
(4)为保护能量存储系统,其充电和放电行为不能同时发生,即:ct·dt=0。
(5)暖风空调系统在t时刻的输入功率et小于其额定功率emax,即0≤et≤exam,且输入功率et可连续调节。
(6)智慧家庭能量系统需要保持能量供需平衡,即:gt+pt+dt=bt+et+ct。式中,pt为分布式发电机在t时刻的功率输出,bt为刚性负载在t时刻的需求功率。
由于智慧家庭中下一时间步的室内温度仅与暖通空调系统输入功率、当前时刻室内温度和环境影响(如室外温度、太阳能辐射等)相关;能量存储系统下一时间步的储能水平仅与当前储能水平和充放电功率相关,与以前的状态和行为无关。因而对于能量存储系统和暖通空调系统的控制,可被认为是马尔科夫决策过程。值得说明的是,由于太阳能等可再生能源的发电输出和电价在实际生活中可能并不具有马尔可夫性,因而马尔可夫决策过程仅仅是智慧家庭能量优化问题的近似描述。对于非严格的马尔可夫决策过程依然可以通过强化学习的方法解决,而且本发明的结果也能够证实其有效性。在实际中,对于非马尔可夫决策过程,可以在本发明公布的马尔可夫过程模型的基础上,采用近似状态、循环神经网络、端到端记忆策略网络、资格迹等来改善性能。
本实施例中,马尔可夫决策过程的主要构成包括:环境状态、行为、奖励函数,其设计分别如下:
(1)环境状态。t时刻的环境状态用st表示,共与七个分量相关联,分别为:t时刻的分布式发电机输出功率pt、t时刻的刚性负载需求功率bt、t时刻的能量存储系统储能水平bt、t时刻的室外温度ttout、t时刻的室内温度tt、t时刻的买电电价vt、t时刻的当前绝对时间在一天内的相对时间t′(如第24小时相当于第0小时,第26小时相当于第2小时),因而环境状态可设计为st=(pt,bt,bt,ttout,tt,vt,t′)。由于向大电网买电的电价经常与卖电电价相关,不失一般性,可假定ut=δvt,其中δ为常数;在实际生活中,如果智慧家庭卖电电价ut独立于买电电价vt,则可将ut作为另一个分量加入。
(2)行为。t时刻的行为用at表示,包括能量存储系统的充电功率ct和放电功率dt,以及暖通空调系统的输入功率et。根据能量守恒可知,当ct、dt、et已知后,智慧家庭与大电网之间的能量买卖数量即可获知。为保护能量存储系统在使用过程中免受损坏,需设置其充电模式和放电模式不可同时运行,此时设定能量存储系统的充放电功率ft∈[-dmax,cmax],当ft≥0时表示充电,此时ct=ft且dt=0;相反,当ft<0时表示放电,此时dt=ft且ct=0,因而该马尔科夫决策过程的行为可表示为:at=(ft,et),即与两个分量相关联。为确保能量存储系统在充电或放电过程中不超出其容量限制,需满足以下要求:
min{-dmax,(bmin-bt)ηd}≤dt≤0,ft<0。
(3)奖励函数。t时刻的奖励函数用rt表示,包括三个组成部分:1.因能量买卖导致的惩罚c1,t(st-1,at-1),即前述t时刻智慧家庭与电网进行能量买卖产生的电费,其与t时刻的上一时间步的环境状态和行为相关联;2.因能量存储系统折损产生的惩罚c2,t(st-1,at-1),即前述t时刻能量存储系统充放电折损产生的费用,同样与t时刻的上一时间步的环境状态和行为相关联;3.因违背室内舒适温度范围导致的惩罚c3,t(st)=([tt-tmax]++[tmin-tt]+),其与当前环境状态相关,式中,tmax为室内最高温度,tmin为室内最低温度,[·]+=max(·,0);
rt=-β(c1,t(st-1,at-1)+c2,t(st-1,at-1))-c3,t(st),式中,β为能量系统的成本相对于温度违背导致的惩罚成本的重要性系数。
步骤二,以奖励最大化为目标,利用深度确定性策略梯度算法训练出不同环境状态下能量存储系统和可控负载的最优行为。
在每个时刻,智慧家庭能量管理系统希望最大化未来的折扣奖励总和,未来的折扣奖励总和表达式为:
为了避免获取状态转移概率,本发明方法设计了基于深度确定性策略梯度的能量管理方法,其实际运行过程如下:(1)观测获取当前环境状态;(2)本地深度神经网络根据所述当前环境状态,输出能量存储系统和暖通空调系统的当前行为;(3)根据当前行为,对能量存储系统和暖通空调系统实施控制;(4)获知下一时间步环境状态和下一时间步奖励,所述下一时间步奖励是能量存储系统和暖通空调系统当前行为所对应产生的结果;(5)将所述当前环境状态、所述当前行为、所述下一时间步环境状态、所述下一时间步奖励发送至位于云端服务器的经验池中;(6)当有需要进行本地深度神经网络权重更新时,从云端经验池中提取训练样本集,以奖励最大化为目标,利用深度确定性策略梯度算法对云端深度神经网络进行训练;(7)将训练好的云端深度神经网络参数定期更新至本地深度神经网络,进而用于实际性能测试。
所述云端深度神经网络包括行动者网络、目标行动者网络、评论家网络、目标评论家网络,其中行动者网络和目标行动者网络与本地深度神经网络的结构相同,评论家网络与目标评论家网络的结构相同。
如图3所示,是本发明方法实施例中所述本地深度神经网络的结构示意图,其网络结构包含输入层、多个隐藏层和输出层,其中,输入层神经元个数为7,与环境状态的7个分量对应;隐藏层的神经元个数可根据需要设定,采用的激活函数为线性整流函数;输出层包含2个,与行为的两个分量对应,分别是能量存储系统的充放电功率和暖通空调系统的输入功率,采用的激活函数分别为双曲正切函数和sigmoid函数。
如图4所示,是本发明方法实施例所述评论家网络和目标评论家网络的结构示意图,具体结构如下:输入层包含两个分别对应环境状态和行为且各自独立的子层,环境状态相关的子输入层后面连接有若干个隐藏层,行为相关的子输入层后面也连接有若干个隐藏层,环境状态相关的最后一个隐藏层神经元个数与行为相关的最后一个隐藏层神经元个数相同,上述两类隐藏层输出求和后输入到新的隐藏层,该新的隐藏层所采用的激活函数为线性整流函数;最后为输出层,其激活函数为线性激活函数。
如图5所示,是本发明方法实施例中所述云端深度神经网络的训练过程示意图。首先,从经验池中随机抽取小批量数据,基于这些数据得到评论家网络的输出和目标网络的输出;然后,根据两者的差值对评论家网络的网络参数进行更新;进一步,利用训练数据中的当前环境状态作为行动者网络的输入,行动者网络对应输出一个行为,该行为和训练数据中的当前输入一起输入到评论家网络,进而得到行为值函数。该行为值函数可用于计算策略梯度。紧接着,利用策略梯度对行动者网络参数进行更新。等行动者网络和评论家网络参数更新完毕后,对目标行动者网络和目标评论家网络进行更新。上述过程一直迭代,直到平均奖励收敛。
步骤三,智慧家庭能量管理系统智能体的行为控制模块根据本地深度神经网络输出的当前行为,对能量存储系统和可控负载实施控制。
本发明具体实施方式还提供了一种基于深度强化学习的智慧家庭能量管理系统,包括:本地智能体和云端服务器,所述本地智能体部署有信息采集模块、行为控制模块和本地深度神经网络,所述云端服务器部署有云端经验池、在线学习模块和云端深度神经网络;
所述信息采集模块,用于观测获取智慧家庭的当前环境状态、下一时间步环境状态和下一时间步奖励,以及将所述当前环境状态、所述当前行为、所述下一时间步环境状态、所述下一时间步奖励发送至云端经验池;
所述本地深度神经网络,用于根据所述当前环境状态,输出能量存储系统和可控负载的当前行为;
所述行为控制模块,用于根据本地深度神经网络输出的当前行为,对能量存储系统和可控负载实施控制;
所述云端经验池,用于存储所述当前环境状态、所述当前行为、所述下一时间步环境状态、所述下一时间步奖励;
所述在线学习模块,用于从云端经验池中提取训练样本集,以所述奖励最大化为目标,利用深度确定性策略梯度算法对云端深度神经网络进行训练,并将训练好的云端深度神经网络参数更新至本地深度神经网络。
本发明实施例与现有技术相比,能够取得以下有益效果:
1)综合考虑了可再生能源发电、刚性负载、能量存储系统、暖通空调系统、能量买卖、室内外环境、动态电价在内的智慧家庭能量成本最小化问题,并将该问题建模为马尔可夫决策过程(mdp),设计了环境状态、行为和奖励函数;
2)提出了基于深度确定性策略梯度算法的能量管理方法,该方法无需知晓任何不确定性系统参数(例如:可再生能源发电输出、刚性负载需求、室外温度和电价)的先验信息和建筑热动力学模型。
3)提出了在线学习方式可帮助智慧家庭能量管理系统智能体应对环境变化带来的性能降级问题,因而具有高鲁棒性。
4)本发明的方法具有高效性。基于实际数据的性能仿真表明:相比现有方法,本发明的方法可在不牺牲用户热舒适的前提下,降低能量成本13.33%-25.59%。
如图6所示,是本发明方法实施例与其他方法的性能对比图,对比方案一:不考虑能量存储系统,采用传统的开/关方式对暖通空调系统进行控制,以制冷模式为例,当室内温度高于设定温度上限时,开启暖通空调系统;当室内温度低于设定温度下限时,关闭暖通空调系统。对比方案二:不考虑能量存储系统,使用深度确定性策略梯度对暖通空调系统进行控制,系统输入的分布式发电机发电、刚性负载、室外温度和电价数据均来自2018年6月1日至8月30日美国德克萨斯州pecanstreet数据库。相较于对比方案一和对比方案二,本发明方法实施例能够在维持用户热舒适的前提下,分别降低能量成本25.59%和13.33%。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!