一种数据出版物学术影响力评价预测方法与流程
本发明涉及学术影响力评价、影响力预测、生长曲线拟合等技术领域,提出了一种数据出版物学术影响力评价预测方法。
背景技术:
科学数据是进行科研活动的重要成果产出,对科技创新、经济发展和社会发展具有重要意义。随着信息技术的日新月异,科学数据正以前所未有的速度增长。国际数据公司(idc)最新报告“dataage2025”指出全球信息化数据量2015年为12zb,到2020年将达到47zb,全球信息化数据量将以每两年翻一番的速度快速增长。idc统计数据显示,全球仅有3%的潜在有价值的数据被开发利用,而经过深入分析和挖掘的数据则更少。
科学数据只有开放共享、广泛传播才能充分发挥其价值。数据作为科学研究的主要成果形式之一,客观准确地对数据的影响力进行评价,有利于提升数据资源作为一项学术成果的社会认可度,有助于提高数据工作者的学术地位和影响,最终激发数据工作者出版数据的内在动力,推动数据的开放共享。
而传统开放共享模式下由于缺乏有效的评价、激励、引用机制等原因,影响了科学数据的开放共享程度和传播重用效率。数据出版模式的出现,能够很好地解决传统数据开放共享模式中存在的诸多问题。数据出版模式提倡以数据论文(datapaper)的方式出版数据。数据论文作为一种开放访问并经过同行评议的新型出版物,对具有科学价值的数据集进行描述,结合传统期刊论文内容和结构化描述模式,使数据更具发现性、引用性、解释性和重用性。随着数据出版模式的推广,逐步出现了一些以数据论文方式进行数据集出版的数据期刊,如earthsystemsciencedata、scientificdata等。
为了有效量化和评价数据的影响力以及数据工作者的贡献度,以及进一步推动数据的开放共享、传播与重用,ands、dcc、oecd、force11、rda、datacite、dryad、dataverse、gesis等越来越多的国际组织或研究机构出台了数据引用的指导原则和规范。我国国家标准化管理委员也于2018年正式发布了《信息技术科学数据引用》国家标准。
通过全球多个组织、机构、研究学者的不断努力,数据引用机制不断被完善,数据出版模式逐渐被认可,数据引用意识和文化也逐步得到培养。而这些努力也为数据影响力评价研究工作的开展奠定了良好的基础。
科学数据影响力研究已经得到国外学术界和国内一些学者的关注,其研究内容涵盖影响力评价理论、指标体系、方法、应用等多个方面。但整体来看,目前科学数据影响力研究仍处于初级阶段。
国际上多个研究机构或组织长期致力于开展数据影响力的传统文献计量、替代计量和新指标的研究工作。其中世界数据系统数据出版文献计量学工作组通过数据计量学的理论研究和实践推动数据计量学的应用和发展。美国的国家信息标准委员会致力于数据影响力替代评估指标相关标准研究和实践工作。casrai科研管理信息标准推进委员会致力于数据级计量评价标准规范的研究以及促进相关标准的统一等工作。
国内顾立平等学者于2013年提出了利用网络用户行为和科学社群影响力的altmetrics计量方法对开放数据的影响力进行评价。2014年,plos、cdl和dataone合作启动试点项目开展数据级计量指标研究,并于2015年提出了一套多维计量指标集datalevelmetrics,从浏览、下载、评论、推荐、引用等多个维度测量科研数据的影响力和使用情况。随着数据出版概念的普及以及datacitationindex(dci)的发布,逐渐出现了一些利用引文分析等文献计量方法对科学数据进行影响力评价的研究。丁楠、雷淑义等学者基于dci利用引用次数、h指数等文献计量指标对数据以及数据出版平台、机构、学科的影响力进行评价。lin等学者通过调查发现,引用指标仍然是最受当前科学界认可的最有效的数据影响力评价指标。2016年peters等学者基于dci探讨了数据引用与altmetric、impactstory、plumx三种替代计量工具对数据影响力评分之间的关系,通过研究未发现数据的引文数量与altmetrics评分之间存在显著相关性。多位学者指出,利用文献引文计量方法进行影响力评价存在滞后性,无法及时反映成果的实时影响力情况。而且引文计量统计工作难度大、依赖第三方文献计量服务,需要实时跟踪和更新。常用的社交网络转发量等替代计量指标存在数据统计难度大、与引文量相关性不强等问题。
因此,如何从数据期刊或数据存储库自身替代计量指标出发,探索一种数据期刊或数据存储库可自主实现、高效、等价可替代的数据引用影响力评价及预测模型则显得尤为关键。
多位学者研究指出,常用的浏览次数、下载次数、转发量、评论数等替代计量指标与引用次数之间未见显著相关性。随着数据引用机制的逐步完善,越来越多的在线出版平台提供了标准化的引用格式说明,以及bib、ris等引用格式文件下载功能。而引用格式文件下载的目的性非常单一,基本可以等同理解为将要进行论文发表的行为。可以说,引用格式文件下载与引用次数息息相关,是转化为引用次数的重要输入。
技术实现要素:
为了解决现有技术问题,本发明提出一种数据出版物学术影响力评价预测方法,通过引用转化率数据来拟合曲线,根据拟合的方程预估目标时间段引用次数,用该引用次数表征引用影响力,本方法能够有效评价并预测各个数据论文的引用影响力情况。
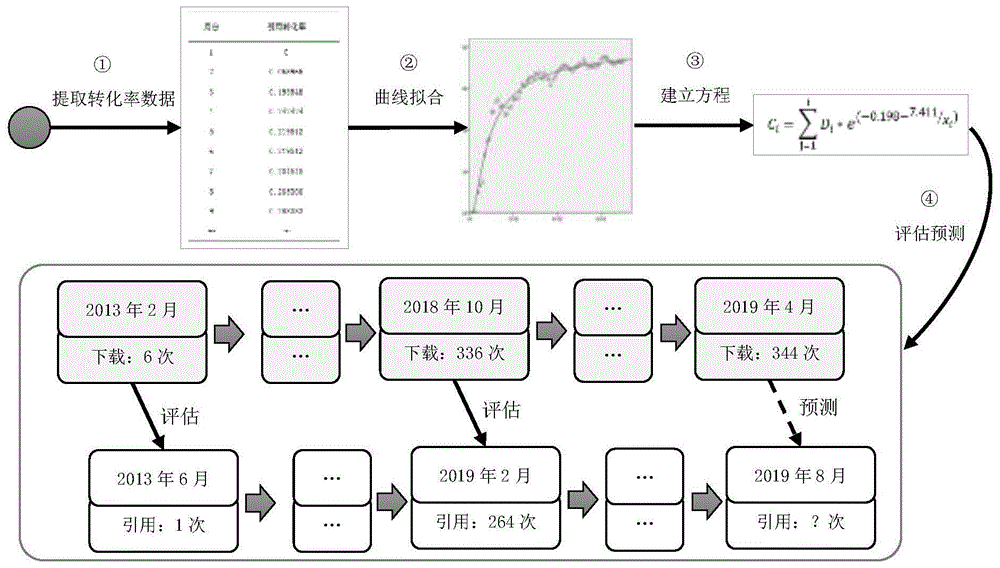
本发明提出的一种数据出版物学术影响力评价预测方法,如图1所示,其步骤如下:
(1)提取数据论文个体的引用转化率数据;
(2)选择回归模型,利用曲线拟合方法进行回归分析;
(3)构建数据论文个体专用影响力评价预测模型;
(4)根据引用转化率所处阶段,利用模型进行引用影响力评价或预测。
通过分析,引用转化率随时间成s生长曲线模型,因此选择s模型进行拟合。
当引用转化率处于增长期阶段,可以利用模型进行评估或者预测;当引用转化率进入稳定期后,可直接利用稳定阶段的引用转化率乘以引用格式文件下载次数进行评估或预测。
本发明还提出一种数据出版物学术影响力评价预测系统,其包括存储器和处理器,该存储器存储计算机程序,该程序被配置为由该处理器执行,该程序包括用于执行上述方法中各步骤的指令。
本发明还提出一种存储计算机程序的计算机可读存储介质,该计算机程序包括指令,该指令当由系统的处理器执行时使得该系统执行上述方法中的各个步骤。
本发明取得的有益效果为:
科学数据只有开放共享、广泛传播才能充分发挥其价值。准确评价数据的学术影响力,是促进数据开放共享的关键一环。数据出版模式的出现以及数据引用机制的不断完善为数据的学术影响力评价开辟了蹊径。传统文献计量存在时间滞后性等问题,常用替代计量指标存在评价偏差大等问题
为了能够有效评价并预测各个数据论文的引用影响力情况,本发明一步提出了“引用转化率”的概念。通过对样本数据绘制引用转化率随时间变化曲线,可以发现引用转化率变化曲线符合s生长曲线模型的特征:变化曲线存在明显的延迟期(施引论文撰写到最终出版的时间)和快速增长期(首次出现施引文献到进入稳定期之前),并最终进入引用转化率稳定期(进入稳定期后引用转化率将基本维持在一个固定值上下轻微波动)。因此,本发明基于“引用转化率”利用s生长曲线模型拟合方法构建数据引用影响力评价预测模型。在“引用转化率”增长期阶段,可以通过该模型评估和预测数据论文的引用影响力情况。当进入“引用转化率”稳定期之后,可以利用引用转化率直接进行数据论文的引用影响力情况的评估和预测。经样本数据验证,本发明所构建的数据论文个体影响力评价预测模型在对样本数据论文的引用影响力评价和预测中均有良好表现。
本发明的研究工作对其他数据期刊和数据存储库进行数据学术影响力评价预测的探索与实践具有一定的启发和借鉴意义。随着数据出版模式的不断普及以及数据引用文化和意识的不断增强,其他数据期刊或者数据存储库只需按照标准的数据引用规范提供数据引用格式说明或者引用格式文件下载功能,并做好数据引用格式说明或者文件被下载使用的记录和统计工作,即可逐步构建数据论文或数据的影响力评价预测模型。
附图说明
图1是数据论文个体专用影响力评价预测模型的构建步骤图。
图2是引用转化率月度变化趋势图。
图3是中低被引次数数据论文引用转化率随季度变化趋势图。
图4是曲线拟合模型与实际引用转化率分布效果图。
图5是模型计算逐月引用次数与实际引用次数对比图。
图6是抽样数据论文引用转化率生长曲线与拟合效果图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
为了能够准确评价并预测数据期刊中各个数据论文的引用影响力情况,本发明提出了“引用转化率”的概念。通过“引用转化率”随时间的演变规律研究发现,“引用转化率”演变符合s生长曲线特征。本发明进一步基于s生长模型利用曲线拟合方法构建了数据论文个体数据影响力评价预测模型。同时,本发明选取了一定数量的样本数据集,对构建模型的评估和预测效果进行了验证。
引用转化率(定义):一篇被引用次数为yi的数据论文i的引用格式文件被下载xi次,则定义该论文的引用格式文件下载次数与引用次数之间的引用转化率ti为:
即需要
由于施引论文的撰写到出版均需要一定的过程,因此一篇论文从发表到引用数据可统计通常需要数月甚至更长的时间。以“adescriptionofthegloballand-surfaceprecipitationdataproductsoftheglobalprecipitationclimatologycentrewithsampleapplicationsincludingcentennial(trend)analysisfrom1901-present”(简称样本a)为例,该数据论文发表时间为2013年2月,当月引用格式文件下载次数为16次。数据论文发表4个月之后,截止2013年6月才首次可以检索到该数据论文的1篇施引论文。通过映射关系,可以认为2013年2月的16次引用格式文件下载,转化为2013年6月1次引用。以此类推,2018年10月累计336次引用格式文件下载转化为2019年2月的累计264次引用。因此2019年4月的引用格式文件下载累计次数可以预测2019年8月份的总引用次数。
1)数据准备
爬取earthsystemsciencedata(essd)数据期刊中338个数据论文对应的metrics页面,通过jsoup工具解析获得了这些数据论文对应的8,920个逐月引用格式文件下载次数数据。另外,基于webofscience提供的检索服务,利用爬虫程序获取了这些数据论文的所有施引论文6,186篇,并通过jsoup工具包解析获得了施引论文的出版年月信息。由于部分施引论文的出版月份信息存在缺失,通过google学术搜索逐一进行了核对和补齐。最终通过excel数据分类统计功能获得逐月施引论文数量分布情况(对于被引次数较低且增长缓慢的数据论文按照季度、半年或者年度进行统计)。
在上述数据准备工作基础上,利用转化率公式
表1.样例数据论文引用转化率逐月变化情况
2)曲线拟合
(1)曲线拟合回归模型选择
如图2和图3所示,通过对12个抽样样本的引用转化率逐月变化情况及4个中低被引数据论文的引用转化率随季度变化情况绘制的折线图可以发现,引用转化率随时间变化符合s生长曲线的图像形状特征:变化曲线存在明显的延迟期(施引论文撰写到最终出版的时间)和快速增长期(首次出现施引文献到正式进入稳定期),并最终进入引用转化率稳定期(进入稳定期后引用转化率将基本维持在一个固定值上下轻微波动)。故采用s模型进行曲线拟合。
s生长曲线模型方程为:
其中,y表示因变量引用转化率,β0为常数,β1为回归系数,x为时间(月份/季度/年份)。
(2)s生长曲线模型拟合
以样本a为例,选择“月份”作为自变量,“引用转化率”作为因变量,采用“s模型”进行曲线拟合,得到如下实验结果,其中表2为曲线拟合模型汇总信息,表3位曲线拟合系数信息。
表2.曲线拟合模型汇总
表3.曲线拟合系数信息表
(3)模型构建与实验结果检验
从表2曲线拟合结果可见,曲线拟合的数据引用影响力评价预测模型r方为0.971,表明基于s生长曲线模型对引用转化率的拟合程度非常高。在图4样本a的s生长曲线模型拟合结果中可以直观看到,每月实际引用转化率基本在拟合曲线上或者附近分布。且自变量月份的sig.为0.000,小于0.005,表明自变量对因变量引用转化率有显著影响。
通过表3曲线拟合系数信息表,可以构建样本a的引用转化率yi随月份xi的s生长曲线模型如下:
因此xi月份的累计引用次数ci基于引用格式文件总下载次数
其中:di为i月份的引用格式文件下载次数。该公式(3)为影响力评价预测模型具体参数化的方程。
通过逐月引用格式文件累计下载次数利用评估计算公式(3)即可获得每月累计引用次数,模型计算结果与实际引用次数对比效果见图5。可见样本a模型计算结果与实际引用次数吻合度较高,模型针对样本a的引用次数评估计算效果良好。表4进一步对16个样本数据的回归模型汇总信息进行了详细展示,可以看到仅有2个模型的r方<0.80,其他模型r方均大于0.80,有一半样本(8个)的模型r方甚至高于0.95。
表4.抽样数据论文专用影响力评估预测模型与评估预测效果
图6详细展示了16个抽样数据论文的引用转化率随月份或者季度的变化情况。从图中可以清晰地看到各个样本数据的引用转化率均符合s生长曲线的图像特征,也可以看到不同样本的引用转化率当前所处的生长阶段。同时还可以直观看到,利用s生长曲线进行拟合的引用转化率变化曲线与实际数据拟合程度较高。
此外,利用构建的数据论文个体专用影响力评价预测模型对16个抽样数据论文进行了预测检验。实验过程中,首先去掉了16个样本最近3个月的引用转化率数据之后,重新构建了专用影响力评价预测模型。然后根据各个样本引用转化率所处的阶段进行判断:如果样本引用转化率处在增长期,则利用新构建的模型预测3个月之后的引用情况;如果样本引用转化率处在稳定期,直接用稳定期参考引用转化率数据乘以引用格式文件累计下载次数进行预测(为了降低稳定期引用转化率波动造成的影响,选择最新5次引用转化率求平均后作为稳定期参考引用转化率)。预测结果见表4中“预测误差”列,从结果中可见,所有预测结果误差均小于5%,预测结果准确度较高。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!