一种引入注意力机制的自然场景文本检测方法与流程
本发明涉及一种引入注意力机制的自然场景文本检测方法,属于文本检测方法
技术领域:
。
背景技术:
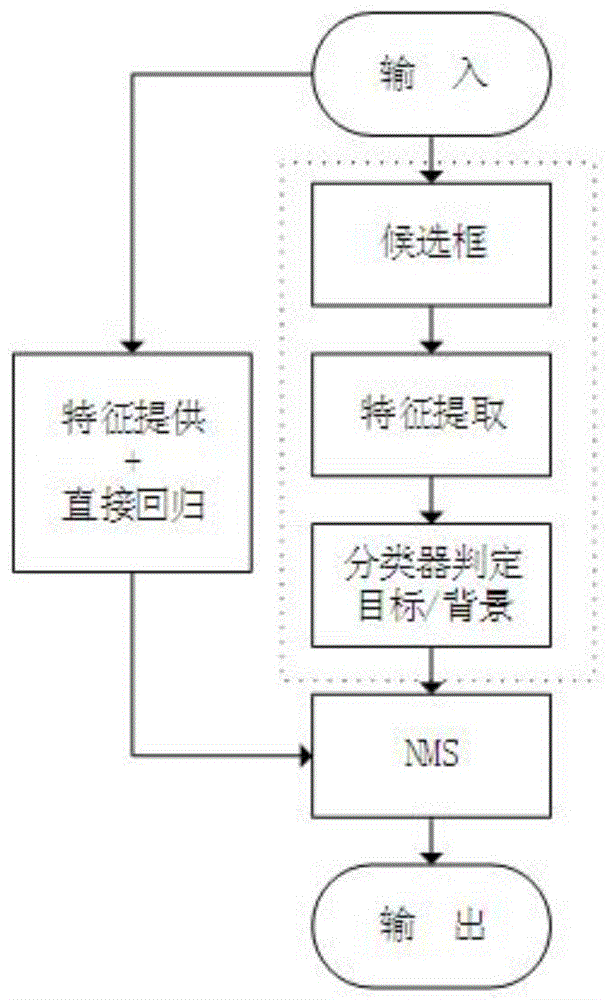
:基于原始检测目标的分类策略主要有基于角色的检测算法,其过程为首先检测单个字符或文本的一部分,然后将其分组成一个单词。基于字的检测方法:它是与一般物体检测类似的方式直接提取文本。基于文本行的检测算法:该方法首先检测文本行,然后再分逐个分成单词。基于目标边界框形状的分类策略的检测方法可以分为两类,第一类为水平或接近水平的检测方法,这类方法专注于检测图像中的水平或接近水平的文本。第二类为多方向的检测方法,与水平或接近水平检测方法相比,多方向的文本检测更加稳健,因为自然场景下的文本可以在图像中处于任意方向,这类的主要研究方法有利用检测多方向文本的旋转不变特征,首先在特征计算之前估计检测目标的中心、比例、方向信息,然后根据尺寸变化、颜色自相似性和结构自相似性进行链级特征。而east算法中提出了一种快速、准确的场景文本检测流水线,该流水线只有两个阶段。管道采用完全卷积网络(fcn)模型,直接生成字或文本行级别的预测,不包括冗余和缓慢的中间步骤。生成的文本预测,可以是旋转的矩形或四边形,发送到非最大抑制以产生最终结果,如图2所示,该方法存在提取长文本受限,长文本的检测效果差。技术实现要素:本发明要解决的技术问题是:提供一种引入注意力机制的自然场景文本检测方法,以解决上述现有技术中存在的问题。本发明采取的技术方案为:一种引入注意力机制的自然场景文本检测方法,该方法为:在利用pvanet网络进行下图像采样的过程中,利用中间的文本特征信息的空间关系生成空间注意力模块,空间注意力模块用来捕捉二维空间中对于目标区判定的重要性信息,每次卷积生成的特征信息为i∈r1×h×w,并经过sgmod函数激活,其表达式为:ws(i)=σf7×7pool(i)(4)其中f7×7为卷积操作,卷积核为7×7的卷积层,在图像采样的过程中通过unpool池化的方式提取特征用于对目标位特征的逼近生成通道注意力模块,然后经过共享网络mlp进行调整,其表达式为:wc(i′)=σmlp(unpool(i))=σw1w0i′(5)式中σ为singmod激活函数,w0∈rc/r×c和w1∈rc×c/r分别为mlp的权重,最后在特征融合的过程中,将通道注意力权重和空间注意力权重构成整个分支注意力模型,其过程表示为:i′=(ws(i)+1)⊙i(6)i″=(wc(i′)+1)⊙i′(7)式中⊙为对应矩阵元素相乘,由于每个模块最后都需要使用sigmod函数来激活,使注意力通道每个元素值在[0,1]之间,达到注意力模块强化有用图像信息和抑制无用信息的效果。本发明的有益效果:与现有技术相比,本发明针对east算法在对于文本方向特征提取时视野受限的问题,通过在主干网络pvanet中引入注意力机制,获得一种attention-east检测方法,使得训练模型在提取文本目标特征时更加关注有用信息和抑制无用信息,实验证明该方法有效提升了east算法检测长文本的能力,在没有损失检测效率的同时提升了检测精度。附图说明图1是目标检测算法基本流程图;图2是east算法结构图;图3是attention-east算法结构图;图4是east算法长文本检测效果图;图5是attention-east算法长文本检测效果图。具体实施方式下面结合附图及具体的实施例对本发明进行进一步介绍。视觉注意的可行性主要归功于合理的假设,即人类视觉不会立即整体处理整个图像;相反,人们只在需要的时间和地点专注于整个视觉空间的选择性部分。具体而言,注意力不是将图像编码成静态矢量,而是允许图像特征从手边的句子上下文演化,从而导致对杂乱图像的更丰富和更长的描述。通过这种方式,视觉注意力可以被视为一种动态特征提取机制,它随着时间的推移结合了上下文定位。当在描述图像中检测目标的特征和信息的图像处理任务中加入注意力机制,注意力模块需要处理的特征信息包含明确的序列项a={a1,a2,a3,…,al},ai∈rd,其中l代表特征向量的个数,d代表的是空间维度。因此所采用的注意力机制需要计算出当前时刻t每个特征向量ai的权重αt,i,公式如下:eti=fatt(ai,ht-1)(1)其中,fatt()代表多层感知机,eti代表中间变量,ht-1代表的是上个时刻的隐含状态,k代表特征向量的下标。计算出权重后,模型就可以对输入的序列a进行筛选,得到筛选后的序列项为:最终收函数μ来决定该注意机制是硬注意力还是软注意力。实施例1:如图3-图5所示,一种引入注意力机制的自然场景文本检测方法,该方法为:在利用pvanet网络进行下图像采样的过程中,利用中间的文本特征信息的空间关系生成空间注意力模块,空间注意力模块用来捕捉二维空间中对于目标区判定的重要性信息,每次卷积生成的特征信息为i∈r1×h×w,并经过sgmod函数激活,其表达式为:ws(i)=σf7×7pool(i)(4)其中f7×7为卷积操作,卷积核为7×7的卷积层,在图像采样的过程中通过unpool池化的方式提取特征用于对目标位特征的逼近生成通道注意力模块,然后经过共享网络mlp进行调整,其表达式为:wc(i′)=σmlp(unpool(i))=σw1w0i′(5)式中σ为singmod激活函数,w0∈rc/r×c和w1∈rc×c/r分别为mlp的权重,最后在特征融合的过程中,将通道注意力权重和空间注意力权重构成整个分支注意力模型,其过程表示为:i′=(ws(i)+1)⊙i(6)i″=(wc(i′)+1)⊙i′(7)式中⊙为对应矩阵元素相乘,由于每个模块最后都需要使用sigmod函数来激活,使注意力通道每个元素值在[0,1]之间,达到注意力模块强化有用图像信息和抑制无用信息的效果。本发明的文件检测方法中损失函数为:l=ls+λglg(8)其中,ls和lg分别表示分数图和几何图形的损失,而λg表示两个损失之间的重要性。在发明中,将λg设为1,为了简化训练过程,本发明引入的类平衡交叉熵:其中是分数图的预测值,y*是基本的真实值。参数β是正负样本之间的平衡因子,由下式得出:为了使大文本区域和小文本区域生成精确的几何预测,保持回归损失尺度不变,旋转矩形框rbox回归部分采用iou损失函数,因为它对不同尺度的对象是固定,其表达式为:其中表示为预测的几何形状,r*是其对应的真实形状,相交矩形的宽度和高度分别为:其中d1,d2,d3和d4分别表示像素到其对应矩形的上、右、下和左边界的距离。联合区由以下公式给出:由此计算交叉或者联合区域,旋转角损失计算如下:式中,是对旋转角度的预测,θ*表示实际值。最后计算出总的几何损失为:lg=lr+λθlθ(15)在实验过程中本发明将λθ设置成10。如图3所示的算法中,该算法的关键部分是引入了注意力模块的神经网络模型,通过训练直接从全图像预测文本实例及其几何图形的存在。该模型是一个完全卷积的神经网络,适用于文本检测,输出每像素密集的单词或文本行预测。这消除了中间步骤,如候选方案、文本区域形成和单词划分。后处理步骤仅包括预测几何图形上的阈值和nms。由attention-east算法结构图,该算法应用于文本检测主要由三个部分构成,包括特征提取网络、特征融合网络和输出层:一、特征提取网络:首先在icdar数据集上对卷积神经网络进行预训练,用来生成神经网络模型的初始化参数。然后基于pvanet模型在特征提取阶段中经过卷积操作提取四个级别的特征图,其大小分别为输入图像的1/32、1/16、1/8和1/4。接着利用空间注意力特征模块计算每个特征图的空间注意力特征,用来关注文本的特征,并记为fi(i=1,2,3,4)作为输出用于特征合并;二、特征融合网络:在该网络中采用逐层合并的方法对特征提取网提取的特征进行合并,其计算公式如下:在每次合并的过程中,首先将来自上一个阶段的特征图首先被输入到一个采样层来扩大其大小;然后经过通道注意力特征模块关注文本位置特征信息。接与当前层特征提取网络的文本特征图进行合并。最后通过卷积操作conv1×1来减少通道数量和计算量,卷积操作conv3×3将局部信息融合来产生该合并阶段的输出hi(i=1,2,3,4)。在最在最后一个合并阶段之后,卷积操作conv3×3层会生成合并分支的最终特征图并将其送到输出层;三、输出层:在输出层中包含若干个卷积conv1×1操作,以将32个通道的特征图投影到1个通道的分数特征图和一个多通道几何图形特征图。几何特征图采用旋转矩形框对检测到的文本进行位置回归,其中通过四个通道来描述矩形文本框,分别表示从像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离,一个通道表示文本框的旋转角度。最后以生成的旋转矩形框来标注图像中检测到的文本,检测效果如下图5如示。模型训练:对于本发明提出的模型按照east算法的训练方式采用adam优化器对网络进行端到端的训练。为了加快学习速度,将原始图像512×512的训练样本每次统一打包成24个进行批处理。adam的学习率从1e-3开始,每27300个小批量下降到十分之一,停在1e-5,对网络进行训练,直到性能改善趋于平稳。实验验证与分析:实验环境:本实验是在ubuntu18.04lts操作系统上进行,开发语言为python3.6,集成开发环境为pycharm,深度学习框架是gpu版本的tensorflow。硬件配置cpu为四核八线程的i7-6700k,其主频4ghz,内存为32gb,gpu为nvidiagtx1080t,显存11g。实验结果:本实验采用的数据集为icdar挑战赛所用的数据集,该数据集也是当文本目标检测算法中比较流行的数据集,其中共有1500张图片,其中1000张图片用于模型训练,其作图片用于测试集,其文本区域由四边形的四个顶点进行注释,对应于目标文本中的四边几何图形,这些图片均由手机或相机随机拍摄,因此,场景中的文本信息是任意方向的,而且可能受到自然环境的影响,这些特征有利于对文本检测算法的估计检验。本发明引入注意力机制的attention-east算法与east算法在处理自然场景下的长文本的检测结果对比如图4-5所示,可以看出通过加入注意力机制对于提取文本和方位的特征信息的增强,提高了文本检测视野,有效改善了对于长文本的检测效果。同时,本发明使用召回率(recall)、准确率(precision)和加权调和平均值f-measured三个指标来评价本发明检测方法在icdar数据集上的训练效果。实验结果如表1所示,通过实验结果可以表明,本文提出的引入注意力机制的方法相比原east算法在文本检测性能指标均有所提升。表1各文本检测算法实验结果对比数据算法使用召回率准确率加权调和平均值attention-east0.79020.84010.8144east0.78310.82240.8022为分析引入注意力模块后在检测效率上对于原east算法的影响,在本文的实验环境下采用每秒帧率(framepersecond,fps)这一指标来评价本文算法和原east算法的检测效率,表示每秒处理的图片数量,将测试集500张检测图片随机分成5份分别进行测试。实验结果表2所示,可以看出加注入注意力模块后,并没有损失原算法的检测效率。表2两种算法文本检测效率对比数据(fps)以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内,因此,本发明的保护范围应以所述权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1