基于人工智能的移民关系知识图谱生成方法和机器人系统与流程
本发明涉及信息技术领域,特别是涉及一种基于人工智能的移民关系知识图谱生成方法和机器人系统。
背景技术:
在实现本发明过程中,发明人发现现有技术中至少存在如下问题:现有移民关系只限于区分是否为移民,而没有将移民前后的时间与移民前后地点结合起来分析。
因此,现有技术还有待于改进和发展。
技术实现要素:
基于此,有必要针对现有技术中的缺陷或不足,提供基于人工智能的移民关系知识图谱生成方法和机器人系统,以解决现有技术中移民关系生成时没有将时间和空间综合考虑的缺点。
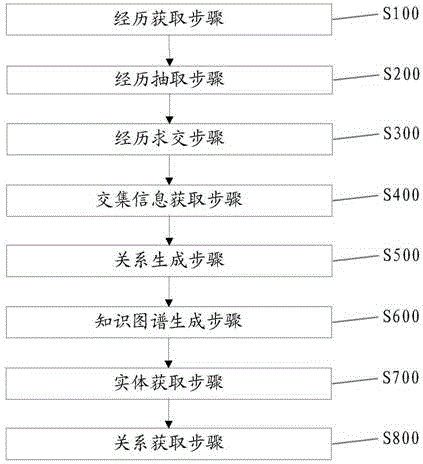
第一方面,本发明实施例提供一种移民关系知识图谱生成方法,所述方法包括:
经历获取步骤,获取每个移民的移民经历;
经历抽取步骤,从每个移民的移民经历中抽取每个经历的时间段及该时间段移民所在的地域;
经历求交步骤,求属于不同移民的每两个经历的交集;
交集信息获取步骤,通过对经历进行匹配获取具有交集的每两个经历,获取交集部分的信息;
关系生成步骤,根据移民的经历,判断每两个移民之间的关系,生成该关系的实体、标签、属性进行关联后加入移民关系知识库;
知识图谱生成步骤,用于将每个移民作为移民关系知识图谱中的一个实体,将移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民的移民关系知识图谱中对应的实体之间的关联关系;
实体获取步骤,获取移民关系知识图谱中与任一实体具有关联关系的实体;
关系获取步骤,获取与第一移民在知识图谱中具备关系的第二移民,获取该第一移民与该第二移民之间的关系,计算该第一移民与该第二移民之间的关系的权重和,根据对应的关系权重和从高到低对与该第一移民有关系的每一移民进行排序。
优选地,
所述经历获取步骤包括:
移民前和移民后经历获取步骤,获取每个移民的简历中的移民前经历和移民后经历;
所述经历抽取步骤包括:
移民前经历抽取步骤,从每个移民的简历的移民前经历中抽取每个移民前经历的时间段及该时间段移民所在的地域;
移民后经历抽取步骤,从简历的移民后经历中抽取每个移民后经历的时间段及该时间段移民所在的地域。
优选地,
交集信息获取步骤包括:
第一交集信息获取步骤,通过对经历进行匹配获取时间段交集不为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的时间段和地域信息;
第二交集信息获取步骤,通过对经历进行匹配获取时间段交集为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的地域信息;
关系生成步骤包括:
同时段关系生成步骤,根据移民的经历,判断每两个移民之间的同时段关系,生成该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
不同时段关系生成步骤,根据移民的经历,判断每两个移民之间的不同时段关系,生成该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库。
优选地,
同时段关系生成步骤包括:
移民前经历同时段关系生成步骤,如果所述两个经历分别为两个移民的移民前经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民前老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民后经历同时段关系生成步骤,如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民前移民后经历同时段关系生成步骤,如果所述两个经历分别为一个移民的移民前经历和另一个移民的移民后经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民前后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
不同时段关系生成步骤包括:
移民前经历不同时段关系生成步骤,如果所述每两个经历分别为两个移民的移民前经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民后经历不同时段关系生成步骤,如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民前移民后经历不同时段关系生成步骤,如果所述两个经历分别为一个移民的移民前经历和另一个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前后老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库。
优选地,
知识图谱生成步骤包括:
同时段移民关系知识图谱生成步骤,将每个移民作为同时段移民关系知识图谱中的一个实体,将同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在同时段移民关系知识图谱中对应的实体之间的关联关系;
不同时段移民关系知识图谱生成步骤,将每个移民作为不同时段移民关系知识图谱中的一个实体,将不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在不同时段移民关系知识图谱中对应的实体之间的关联关系;
混合时段移民关系知识图谱生成步骤,将每个移民作为移民关系知识图谱中的一个实体,将同时段移民关系知识库及不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在移民关系知识图谱中对应的实体之间的关联关系;
实体获取步骤包括:
同时段实体获取步骤,获取同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有同时段的移民前老乡、移民后老乡、移民前后老乡;
不同时段实体获取步骤,获取不同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有不同时段的移民前老乡、移民后老乡、移民前后老乡;
混合时段实体获取步骤,获取移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有移民前老乡、移民后老乡、移民前后老乡。
优选地,
关系获取步骤具体包括:根据上述步骤获取与一个移民在知识图谱中具备某类关系的所有移民,获取该个移民与该所有移民中每一移民之间的关系,将关系中时间段的长度作为p1,将关系中的最低地域级别作为p2,计算f(p1,p2)作为该关系的权重,计算该个移民与该所有移民中每一移民之间的所有关系的权重和,根据对应的关系权重和从高到低对与该移民有该类关系的每一移民进行排序,排序越靠前的移民与该移民的该类关系越密切,排序最靠前的移民与该移民的该类关系最密切。
第二方面,本发明实施例提供一种移民关系知识图谱生成系统,所述系统包括:
经历获取模块,用于获取每个移民的移民经历;
经历抽取模块,用于从每个移民的移民经历中抽取每个经历的时间段及该时间段移民所在的地域;
经历求交模块,用于求属于不同移民的每两个经历的交集;
交集信息获取模块,用于通过对经历进行匹配获取具有交集的每两个经历,获取交集部分的信息;
关系生成模块,用于根据移民的经历,判断每两个移民之间的关系,生成该关系的实体、标签、属性进行关联后加入移民关系知识库;
知识图谱生成模块,用于将每个移民作为移民关系知识图谱中的一个实体,将移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民的移民关系知识图谱中对应的实体之间的关联关系;
实体获取模块,获取移民关系知识图谱中与任一实体具有关联关系的实体;
关系获取模块,获取与第一移民在知识图谱中具备关系的第二移民,获取该第一移民与该第二移民之间的关系,计算该第一移民与该第二移民之间的关系的权重和,根据对应的关系权重和从高到低对与该第一移民有关系的每一移民进行排序。
第三方面,本发明实施例提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现第一方面实施例中任一项所述方法的步骤。
第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面实施例中任一项所述方法的步骤。
第五方面,本发明实施例提供一种移民关系知识图谱生成机器人系统,所述机器人系统包括存储器和处理器,所述存储器存储有机器人程序,所述处理器执行所述机器人程序时实现第一方面实施例中任一项所述方法的步骤。
本发明实施例提供的基于人工智能的移民关系知识图谱生成方法和机器人系统,包括:经历获取步骤,经历抽取步骤,经历求交步骤,交集信息获取步骤,关系生成步骤,知识图谱生成步骤,实体获取步骤。上述方法和系统通过基于人工智能的移民关系知识图谱生成方法生成和获得更为精准的移民之间关系,具体到某一级地域,例如移民前所在地区、移民后所在地区,可以区分同时段和不同时段的关系,例如有的移民之间虽然有移民后所在国家相同的关系,但是在不同时间属于不同国家。可以精确地生成和得到两个移民之间的关系所在的具体时间段具体各级地域。可以根据关系对应的交集中时间段的长短和地域级别来判断与一个移民关系最密切的移民,并能根据关系的密切程度对这个移民的所有有关系移民进行排序。
附图说明
图1为本发明的实施例1提供的移民关系知识图谱生成方法的流程图;
图2为本发明的实施例2提供的移民关系知识图谱生成方法的流程图;
图3为本发明的实施例3提供的移民关系知识图谱生成方法的流程图;
图4为本发明的实施例4提供的移民关系知识图谱生成方法的流程图;
图5为本发明的实施例5提供的知识图谱的示意图;
图6为本发明的实施例6提供的知识图谱的示意图;
图7为本发明的实施例7提供的知识图谱的示意图;
图8为本发明的实施例8提供的移民关系知识图谱生成方法的流程图;
图9为本发明的实施例9提供的移民关系知识图谱生成系统的原理框图。
具体实施方式
下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
(一)本发明的各种实施例中的方法包括以下步骤的各种组合:
实施例1:
如图1所示,提供一种移民关系知识图谱生成方法,包括经历获取步骤s100、经历抽取步骤s200、经历求交步骤s300、交集信息获取步骤s400、关系生成步骤s500。
经历获取步骤s100,用于获取每个移民的移民经历。所述简历包括移民的个人简历,也包括从社交网站等网络信息中获取的简历,还包括所有包含有移民的经历的信息。
经历抽取步骤s200,用于从每个移民的移民经历中抽取每个经历的时间段及该时间段移民所在的地域。所述地域指的是一个空间范围,包括国家、省、市等区域、地区。
经历求交步骤s300,用于求属于不同移民的每两个经历的交集
例如:
张三的移民前经历2010.9-2014.7a1移民前所在国家b11移民前所在地区与李四的移民后经历2018.9-2019.7a1移民前所在国家b12移民前所在地区的交集为a1移民前所在国家
例如,
张三的移民前经历2014.9-2017.7a21移民前所在国家b21移民前所在地区与李四的移民前经历2015.9-2018.7a21移民前所在国家b21移民前所在地区的交集为2015.9-2017.7a21移民前所在国家b21移民前所在地区
交集信息获取步骤s400,用于通过对经历进行匹配获取具有交集的每两个经历,获取交集部分的信息。
关系生成步骤s500,用于根据移民的经历,判断每两个移民之间的关系,生成该关系的实体、标签、属性进行关联后加入移民关系知识库。
知识图谱生成步骤s600,用于将每个移民作为移民关系知识图谱中的一个实体,将移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民的移民关系知识图谱中对应的实体之间的关联关系。
实体获取步骤s700,获取移民关系知识图谱中与任一实体具有关联关系的实体。
关系获取步骤s800,获取与第一移民在知识图谱中具备关系的第二移民,获取该第一移民与该第二移民之间的关系,计算该第一移民与该第二移民之间的关系的权重和,根据对应的关系权重和从高到低对与该第一移民有关系的每一移民进行排序。
实施例2:
如图2所示,根据实施例1提供的移民关系知识图谱生成方法,
其中,经历获取步骤s100包括移民前和移民后经历获取步骤s110。
移民前和移民后经历获取步骤s110,用于获取每个移民的简历中的移民前经历和移民后经历。
简历可以通过移民输入,也可以从百度百科或其它网站上获取,获取从中提取移民前经历和移民后经历。
例如
张三
移民前经历
2014.9-2017.7a2移民前所在国家b21移民前所在地区
移民后经历
2017.9-2018.7a3移民后所在国家b31移民后所在地区
李四
移民前经历
2015.9-2018.7a2移民前所在国家b21移民前所在地区
移民后经历
2018.9-2019.7a1移民后所在国家b12移民后所在地区
其中,经历抽取步骤s200包括移民前经历抽取步骤s210、移民后经历抽取步骤s220。
移民前经历抽取步骤s210,用于从每个移民的简历的移民前经历中抽取每个移民前经历的时间段及该时间段移民所在的地域
例如
从张三的移民前经历中抽取
2014.9-2017.7a2移民前所在国家b21移民前所在地区
从李四的移民前经历中抽取
2015.9-2018.7a2移民前所在国家b21移民前所在地区
移民后经历抽取步骤s220,用于从简历的移民后经历中抽取每个移民后经历的时间段及该时间段移民所在的地域
例如
从张三的移民后经历中抽取
2017.9-2018.7a3移民后所在国家b31移民后所在地区
从李四的移民后经历中抽取
2018.9-2019.7a1移民后所在国家b12移民后所在地区
实施例3:
如图3所示,根据实施例1提供的移民关系知识图谱生成方法,
其中,交集信息获取步骤s400包括第一交集信息获取步骤s410。
第一交集信息获取步骤s410,用于通过对经历进行匹配获取时间段交集不为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的时间段和地域信息。
求两个移民经历(移民a的一个经历、移民b的一个经历)的地域交集的具体步骤
从移民a经历的地域信息中分别提取一级地域名称(例如移民后所在国家名,根据“移民前所在国家”等关键词识别和提取)、二级地域名称(例如移民前所在地区名,根据“移民前所在地区”等关键词识别和提取)等多级地域名称
同样,从移民b经历的地域信息中分别提取一级地域名称、二级地域名称等多级地域名称
如果移民a与移民b的一级地域名称相同但二级地域名称不同,则该两个移民的地域交集为该一级地域名称
如果移民a与移民b的一级地域名称相同且二级地域名称相同但三级地域名称不同,则该两个移民的地域交集为该一级地域名称二级地域名称
如果移民a与移民b的一级地域名称相同且二级地域名称相同且三级地域名称相同但四级地域名称不同,则该两个移民的地域交集为该一级地域名称二级地域名称三级地域名称
如此类推。
求两个移民经历(移民a的一个经历、移民b的一个经历)的时间段交集的具体步骤为取2个时间段的共同时间段作为交集的结果。
例如
交集2015.9-2017.7a21移民前所在国家b21移民前所在地区对应的属于张三、李四的两个经历:
张三的移民前经历2014.9-2017.7a21移民前所在国家b21移民前所在地区
李四的移民前经历2015.9-2018.7a21移民前所在国家b21移民前所在地区
交集部分的时间段为:2015.9-2017.7
交集部分的地域信息为:a21移民前所在国家b21移民前所在地区
其中,关系生成步骤s500包括同时段关系生成步骤s510。
同时段关系生成步骤s510,用于根据移民的经历,判断每两个移民之间的同时段关系,生成该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民前经历同时段关系生成步骤s511,用于如果所述两个经历分别为两个移民的移民前经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民前老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
例如
交集2015.9-2017.7a21移民前所在国家b21移民前所在地区对应的属于张三、李四的两个经历:
张三的移民前经历2014.9-2017.7a21移民前所在国家b21移民前所在地区
李四的移民前经历2015.9-2018.7a21移民前所在国家b21移民前所在地区
分别为两个移民的移民前经历
则这两个移民具有同时段关系,将这两个移民的姓名“张三、李四”作为该关系的实体,将同时段移民前老乡关系作为该关系的标签,将交集部分的时间段2015.9-2017.7和地域信息a21移民前所在国家b21移民前所在地区作为该关系的属性,加入同时段移民关系知识库;
移民后经历同时段关系生成步骤s512,如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民前移民后经历同时段关系生成步骤s513,如果所述两个经历分别为一个移民的移民前经历和另一个移民的移民后经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民前后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
实施例4:
如图4所示,根据实施例1提供的移民关系知识图谱生成方法,
其中,交集信息获取步骤s400包括第二交集信息获取步骤s420。
第二交集信息获取步骤s420,用于通过对经历进行匹配获取时间段交集为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的地域信息例如
交集a1移民前所在国家对应的属于张三、李四的两个经历:
张三的移民前经历2010.9-2014.7a1移民前所在国家b11移民前所在地区李四的移民后经历2018.9-2019.7a1移民前所在国家b12移民前所在地区交集部分的时间段为空
交集部分的地域信息为:a1移民前所在国家
其中,关系生成步骤s500包括不同时段关系生成步骤s520。
不同时段关系生成步骤s520,用于根据移民的经历,判断每两个移民之间的不同时段关系,生成该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库。
移民前经历不同时段关系生成步骤s521,用于如果所述每两个经历分别为两个移民的移民前经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民后经历不同时段关系生成步骤s522,用于如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民前移民后经历不同时段关系生成步骤s523,如果所述两个经历分别为一个移民的移民前经历和另一个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前后老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
例如
交集a1移民前所在国家对应的属于张三、李四的两个经历:
张三的移民前经历2010.9-2014.7a1移民前所在国家b11移民前所在地区李四的移民后经历2018.9-2019.7a1移民前所在国家b12移民前所在地区分别为一个移民的移民前经历和另一个移民的移民后经历
则这两个移民具有不同时段关系,将这两个移民的姓名“张三、李四”作为该关系的实体,将不同时段移民前后老乡关系作为该关系的标签,将交集部分的地域信息a1移民前所在国家作为该关系的属性,加入不同时段移民关系知识库;
实施例5:
如图5所示,根据实施例1提供的移民关系知识图谱生成方法,
知识图谱生成步骤s600包括:
同时段移民关系知识图谱生成步骤s610:将每个移民作为同时段移民关系知识图谱中的一个实体,将同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在同时段移民关系知识图谱中对应的实体之间的关联关系。
实体获取步骤s700包括:
同时段实体获取步骤s710:获取同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有同时段的移民前老乡、移民后老乡、移民前后老乡。获取同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有同时段同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
实施例6:
如图6所示,根据实施例1提供的移民关系知识图谱生成方法,
知识图谱生成步骤s600包括:
不同时段移民关系知识图谱生成步骤s620:将每个移民作为不同时段移民关系知识图谱中的一个实体,将不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在不同时段移民关系知识图谱中对应的实体之间的关联关系,
实体获取步骤s700包括:
不同时段实体获取步骤s720:获取不同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有不同时段的移民前老乡、移民后老乡、移民前后老乡。获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
进一步,获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称且含有“移民前老乡”关键词的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的移民前老乡。
进一步,获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称且含有“移民后老乡”关键词的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的移民后老乡。
进一步,获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称且含有“移民前后老乡”关键词的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的移民前后老乡。
进一步,获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称且含有“移民前老乡”关键词且含有该一实体身份为同级关键词的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的同级。
实施例7:
如图7所示,根据实施例1提供的移民关系知识图谱生成方法,
知识图谱生成步骤s600包括:
混合时段移民关系知识图谱生成步骤s630:将每个移民作为移民关系知识图谱中的一个实体,将同时段移民关系知识库及不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在移民关系知识图谱中对应的实体之间的关联关系。
实体获取步骤s700包括:
混合时段实体获取步骤s730:获取移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有移民前老乡、移民后老乡、移民前后老乡。获取移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
例如,
获取移民关系知识图谱中与张三具有关联关系的所有实体,可以得到张三的移民前老乡有李四、王二,移民后老乡有李四、王二,移民前后老乡有李四。
例如,
k为2时,获取移民关系知识图谱中与张三具有的关联关系中具有第2级地域名称(对应移民前所在地区、移民后所在地区)的所有实体,可以得到张三的所有同第2级地域的移民前老乡有李四、王二,移民后老乡有李四,移民前后老乡没有
实施例8:
如图8所示,根据实施例5、6、7提供的移民关系知识图谱生成方法进行组合使用。
实施例9:
如图9所示,根据实施例1提供的移民关系知识图谱生成方法,
关系获取步骤s800具体包括:根据上述步骤获取与一个移民在知识图谱中具备某类关系的所有移民,获取该个移民与该所有移民中每一移民之间的关系,将关系中时间段的长度作为p1,将关系中的最低地域级别作为p2,计算f(p1,p2)作为该关系的权重,计算该个移民与该所有移民中每一移民之间的所有关系的权重和,根据对应的关系权重和从高到低对与该移民有该类关系的每一移民进行排序,排序越靠前的移民与该移民的该类关系越密切,排序最靠前的移民与该移民的该类关系最密切。
其中,p1以年为地域,时间段的长度不是整年时,向上取整为整年,最低地域为k级地域时p2为k,f(p1,p2)可以有多种实现方式,例如f(p1,p2)=p1*p2+p2
例如
根据上述步骤获取与张三在知识图谱中具备关系的所有移民李四、王二,获取张三与李四之间的关系、张三与王二之间的关系,
将张三与李四之间的关系“不同时段移民后老乡关系、a3移民后所在国家b31移民后所在地区”中时间段的长度0作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=p1*p2+p2=2作为该关系的权重。
将张三与李四之间的关系“不同时段移民前后老乡关系、a1移民前所在国家”中时间段的长度0作为p1,将关系中的最低地域级别1作为p2,计算f(p1,p2)=p1*p2+p2=1作为该关系的权重。
将张三与李四之间的关系“同时段移民前老乡关系、2015.9-2017.7a21移民前所在国家b21移民前所在地区”中时间段的长度2作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=p1*p2+p2=6作为该关系的权重。
计算张三与李四之间的所有关系的权重和为2+1+6=9
将张三与王二之间的关系“同时段移民后老乡关系、2017.9-2018.7a3移民后所在国家”中时间段的长度1作为p1,将关系中的最低地域级别1作为p2,计算f(p1,p2)=max(p1*p2+p2)=2作为该关系的权重,
将张三与王二之间的关系“同时段移民前老乡关系、2014.9-2017.7a2移民前所在国家b21移民前所在地区”中时间段的长度3作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=max(p1*p2+p2)=8作为该关系的权重,
将张三与王二之间的关系“同时段移民前老乡关系、2010.9-2014.7a1移民前所在国家b11移民前所在地区”中时间段的长度4作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=max(p1*p2+p2)=10作为该关系的权重,
计算张三与王二之间的所有关系的权重和为2+8+10=20
根据关系的权重从高到低对与该移民有关系的所述每一移民进行排序为王二、李四,
王二与张三的关系更密切,排序最靠前的王二与张三的关系最密切。
例如
根据上述步骤获取与张三在知识图谱中具备同时段移民前老乡关系的所有移民李四、王二,获取张三与李四之间的关系、张三与王二之间的关系,
将张三与李四之间的关系“同时段移民前老乡关系、2015.9-2017.7a21移民前所在国家b21移民前所在地区”中时间段的长度2作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=p1*p2+p2=6作为该关系的权重。
计算张三与李四之间的所有关系的权重和为6=6
将张三与王二之间的关系“同时段移民前老乡关系、2014.9-2017.7a2移民前所在国家b21移民前所在地区”中时间段的长度3作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=max(p1*p2+p2)=8作为该关系的权重,
将张三与王二之间的关系“同时段移民前老乡关系、2010.9-2014.7a1移民前所在国家b11移民前所在地区”中时间段的长度4作为p1,将关系中的最低地域级别2作为p2,计算f(p1,p2)=max(p1*p2+p2)=10作为该关系的权重,
计算张三与王二之间的所有关系的权重和为8+10=18
根据关系的权重从高到低对与该移民有同时段移民前老乡关系的所述每一移民进行排序为王二、李四,
王二与张三的同时段移民前老乡关系更密切,排序最靠前的王二与张三的同时段移民前老乡关系最密切。
效果:可以获得更为精准的移民之间关系,具体到某一级地域,例如同一移民前所在地区、同一移民后所在地区,可以区分同时段和不同时段的关系,例如有的移民之间虽然有同一移民后所在国家的关系,但是在不同时间属于不同移民后所在国家。可以精确地得到两个移民之间的关系所在的具体时间段具体各级地域。可以根据关系对应的交集中时间段的长短和地域级别来判断与一个移民关系最密切的移民,并能根据关系的密切程度对这个移民的所有有关系移民进行排序
实施例10:
如图9所示,提供一种移民关系知识图谱生成系统,包括经历获取模块100、经历抽取模块200、经历求交模块300、交集信息获取模块400、关系生成模块500、等模块。
经历获取模块100,用于获取每个移民的移民经历。
经历抽取模块200,用于从每个移民的移民经历中抽取每个经历的时间段及该时间段移民所在的地域。
经历求交模块300,用于求属于不同移民的每两个经历的交集
交集信息获取模块400,用于通过对经历进行匹配获取具有交集的每两个经历,获取交集部分的信息。
关系生成模块500,用于根据移民的经历,判断每两个移民之间的关系,生成该关系的实体、标签、属性进行关联后加入移民关系知识库。
实施例11:
根据实施例10提供的移民关系知识图谱生成系统,
其中,经历获取模块100包括移民前和移民后经历获取模块110。
移民前和移民后经历获取模块110,用于获取每个移民的简历中的移民前经历和移民后经历。
其中,经历抽取模块200包括移民前经历抽取模块210、移民后经历抽取模块220。
移民前经历抽取模块210,用于从每个移民的简历的移民前经历中抽取每个移民前经历的时间段及该时间段移民所在的地域
实施例12:
根据实施例10提供的移民关系知识图谱生成系统,
其中,交集信息获取模块400包括第一交集信息获取模块410。
第一交集信息获取模块410,用于通过对经历进行匹配获取时间段交集不为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的时间段和地域信息。
其中,关系生成模块500包括同时段关系生成模块510。
同时段关系生成模块510,用于根据移民的经历,判断每两个移民之间的同时段关系,生成该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民前经历同时段关系生成模块511,用于如果所述两个经历分别为两个移民的移民前经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民前老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
移民后经历同时段关系生成模块512,如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有同时段关系,将这两个移民的姓名作为该关系的实体,将同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入同时段移民关系知识库;
实施例13:
根据实施例10提供的移民关系知识图谱生成系统,
其中,交集信息获取模块400包括第二交集信息获取模块420。
第二交集信息获取模块420,用于通过对经历进行匹配获取时间段交集为空且地域交集不为空的属于不同移民的每两个经历,获取交集部分的地域信息
其中,关系生成模块500包括不同时段关系生成模块520。
不同时段关系生成模块520,用于根据移民的经历,判断每两个移民之间的不同时段关系,生成该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库。
移民前经历不同时段关系生成模块521,用于如果所述每两个经历分别为两个移民的移民前经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民后经历不同时段关系生成模块522,用于如果所述两个经历分别为两个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民后老乡关系作为该关系的标签,将交集部分的时间段和地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库;
移民前移民后经历不同时段关系生成模块523,如果所述两个经历分别为一个移民的移民前经历和另一个移民的移民后经历,则这两个移民具有不同时段关系,将这两个移民的姓名作为该关系的实体,将不同时段移民前后老乡关系作为该关系的标签,将交集部分的地域信息作为该关系的属性,将该关系的实体、标签、属性进行关联后加入不同时段移民关系知识库。
实施例14:
根据实施例10提供的移民关系知识图谱生成系统,
知识图谱生成模块600包括:
同时段移民关系知识图谱生成模块610:将每个移民作为同时段移民关系知识图谱中的一个实体,将同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在同时段移民关系知识图谱中对应的实体之间的关联关系。
实体获取模块700包括:
同时段实体获取模块710:获取同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有同时段的移民前老乡、移民后老乡、移民前后老乡。获取同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有同时段同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
实施例15:
根据实施例10提供的移民关系知识图谱生成系统,
知识图谱生成模块600包括:
不同时段移民关系知识图谱生成模块620:将每个移民作为不同时段移民关系知识图谱中的一个实体,将不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在不同时段移民关系知识图谱中对应的实体之间的关联关系,
实体获取模块700包括:
不同时段实体获取模块720:获取不同时段移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有不同时段的移民前老乡、移民后老乡、移民前后老乡。获取不同时段移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有不同时段同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
实施例16:
根据实施例10提供的移民关系知识图谱生成系统,
知识图谱生成模块600包括:
混合时段移民关系知识图谱生成模块630:将每个移民作为移民关系知识图谱中的一个实体,将同时段移民关系知识库及不同时段移民关系知识库中每个关系的关系标签及其属性作为该关系中两个移民在移民关系知识图谱中对应的实体之间的关联关系。
实体获取模块700包括:
混合时段实体获取模块730:获取移民关系知识图谱中与任一实体具有关联关系的所有实体,可以得到该一实体对应的移民的所有移民前老乡、移民后老乡、移民前后老乡。获取移民关系知识图谱中与任一实体具有的关联关系中具有第k级地域名称的所有实体,可以得到该一实体对应的移民的所有同第k级地域的移民前老乡、移民后老乡、移民前后老乡。k为大于1的自然数。
实施例17:
根据实施例14、15、16提供的移民关系知识图谱生成系统可以进行组合使用。
实施例18:
根据实施例10提供的移民关系知识图谱生成系统,
关系获取模块800具体包括:根据上述步骤获取与一个移民在知识图谱中具备某类关系的所有移民,获取该个移民与该所有移民中每一移民之间的关系,将关系中时间段的长度作为p1,将关系中的最低地域级别作为p2,计算f(p1,p2)作为该关系的权重,计算该个移民与该所有移民中每一移民之间的所有关系的权重和,根据对应的关系权重和从高到低对与该移民有该类关系的每一移民进行排序,排序越靠前的移民与该移民的该类关系越密切,排序最靠前的移民与该移民的该类关系最密切。
上述各实施例中的方法和系统可以在计算机、服务器、云服务器、超级计算机、机器人、嵌入式设备、电子设备等上执行和部署。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!