一种基于增强自编码器的室内目标物体6D姿态估计方法与流程
本发明涉及姿态估计领域,具体公开一种基于增强自编码器的室内目标物体6d姿态估计方法。
背景技术:
单幅彩色图像的目标检测与物体6d姿态在工业与移动机器人操作、虚拟现实、增强现实的人机交互中都起着非常重要的作用,遮挡问题在6d姿态估计问题中是最具有挑战性的问题之一。
目前姿态估计的主流方法中,主要分为基于模板匹配的方法、基于点的方法、基于描述子的方法、基于特征学习方法和基于卷积神经网络端到端的方法。这些方法在处理复杂环境下的遮挡问题,鲁棒性不是很理想。
基于模板匹配的方法需要对检测的目标物体做大量采样工作,提取足够锅并且鲁棒匹配末班,在对模板进行匹配才能得到大致的物体姿态,最后再使用icp精化结果,虽然模版匹配方法对于低纹理的物体可以比较高效的进行姿态估计,但是其对姿态大量变化的物体就非常麻烦,因为其需要大量的模版去匹配,而且其无法解决物体遮挡问题。
基于点的方法基本是通过点云上面少量点对构成描述子来做的,通过任意两个点都计算ppf描述子,构建模型哈希表,以描述子为键,以这两个点为点对,通过两个点云的匹配来计算其刚体变换矩阵,求得物体姿态,但是这种方法非常耗时耗力;
基于描述子的方法是提高匹配点的精度,从而提升物体姿态的准确度,不过点的方法和描述子的方法耗时耗力巨大,都比较依赖点的质量,且需要丰富的纹理特征;
基于特征学习的方法是通过学习物体的特征来进行物体姿态估计,通过传统的机器学习方法(如随机森林)学习物体特征来回归预测物体的姿态,如latent-classhoughforests系列工作,但是这类方法很难处理对称性物体和遮挡物体;
基于卷积神经网络端到端的方法是最近比较流行的方法,但是该方法需要大量的训练数据,尤其是三维的标注数据非常难以获得,这类方法先用卷积神经网络提取特征点,然后用pnp方法计算出姿态(包括三维旋转矩阵r与三维平移矩阵t),但是这些方法大多是针对单个目标,没有考虑多个目标之间的遮挡情况,虽然也有学者提出多个目标的方法如singleshot6d和ssd-6d,但是对于遮挡效果并不太好,浙江大学提出的pvnet对于遮挡效果不错,但是其方法是基于像素投票的,比较耗费资源且对结果做了很多处理,算法比较复杂。
综上所述,现有技术存在的问题是:基于模板匹配的方法对于遮挡物体表现不理想,且需要后续复杂处理;基于点的方法和基于描述子的方法对点质量和纹理特征要求较高;基于特征学习的方法很难处理对称性物体和遮挡物体;基于卷积神经网络端到端的方法对于多目标在杂乱场景及物体之间的遮挡解决不好,后续处理较多,无法满足实际应用需求。
技术实现要素:
针对现有技术存在的问题,本发明提出了一种基于增强自编码器的室内目标物体6d姿态估计方法与系统。
为实现上述目的,本发明的技术方案为一种基于增强自编码器的室内目标物体6d姿态估计方法与系统,具体技术方案包括以下步骤:
本发明方法分成三个阶段:
多目标物体检测阶段:
首先输入单幅彩色图像到改进版的fasterr-cnn,然后rpn网络提取出候选框,再通过全卷积网络输出目标类别概率和二维边界框;
增强自编码器(aae)预测物体关键点阶段:
利用概率期望连接多目标物体检测阶段与增强自编码器预测物体关键点阶段,通过训练改进版的堆叠式降噪自动编码器(sdae)对感兴趣区域编解码出相同尺寸的无噪声感兴趣区域,再通过全连接层(fc)预测出目标物体在二维图像上的关键点;
计算目标物体的6d姿态估计阶段:
根据关键点计算出目标物体的6d姿态。
所述的多目标物体检测阶段的具体步骤如下:
1-1.输入单幅彩色图像到fasterr-cnn的特征提取器resnet101网络中进行特征提取,得到特征图,该特征图会用在后面的区域提名网络(rpn网络)和全卷积层(fcn);
1-2.将得到的特征图输入给rpn网络,rpn网络使用9个锚点,因为使用到的数据集linemod中的目标类别多为小目标,所以锚点尺度大小分别设置为128*128、192*192和256*256像素,长宽比分别为1∶1、1∶2和2∶1,得到候选框;
1-3将步骤1-1得到的特征图和步骤1-2得到的候选框输入给下采样池化模块,将感兴趣区域映射产生固定大小为7*7像素的特征图;
1-4将步骤1-3的特征图输入给代替全连接层的全卷积层,得到目标物体的类别和二维边界框,目标物体的类别用概率表示,边界框指目标物体在图像中的左上角和右下角坐标点组成的矩形框区域。
所述的增强自编码器预测物体关键点的具体步骤如下:
2-1.采用改进版的堆叠式去噪自编码器(sade),sdae是逐层训练的去噪自动编码器(dae),为了让网络训练收敛,采用relu的方法,并且通过修改sdae的网络结构与隐变量参数,得到增强自编码器,从而提高去噪能力;
2-2.将多目标物体检测阶段得到的感兴趣区域(rois)输入给增强自编码器进行训练,感兴趣区域的尺寸大小调整为128*128像素;
2-3.将尺寸为128*128的感兴趣区域输入给增强自编码器的编码器(encoder),编码器是对输入编码映射为隐变量的过程,这个隐变量中包含了输入的所有特征,由6个卷积层、6个relu激活层、1个flatten压平层和1个全连接层,其中隐变量单元设为128;
2-4.将编码器编码后的隐变量输入给解码器(decoder),解码器对隐变量进行解码,由6个卷积层、6个relu激活层、1个flatten压平层和1个全连接层组成,隐变量单元设为128,得到新的感兴趣区域i,依然是用隐变量进行表示;
2-5.步骤2-2和2-3获得了新的感兴趣区域的隐变量表示,再此基础上加上一个全连接层,用于预测物体的三维包围盒的8个关键点在感兴趣区域的投影。
所述的计算物体的6d姿态估计阶段的具体步骤如下:
3-1.将增强自编码器预测到的物体的三维包围盒的8个关键点在感兴趣区域的投影输入给epnp算法;
3-2.提取linemod数据集自带的点云模型(.ply)中的世界坐标系下的特征点,此特征点是三维坐标点,表示为(x,y,z);
3-3.提取linemod数据集自带的相机内参矩阵,相机参数是固定的;
3-4.相机的畸变参数矩阵设为1个8维全0的矩阵;
3-5.将三维坐标点、8个关键点、相机内参矩阵和相机的畸变参数矩阵输入给opencv的solvepnp求解出三维旋转矩阵r和三维平移矩阵t,从而求得目标物体的6d姿态。
本发明方法实现过程中涉及到的网络损失函数设置的具体步骤如下:
网络损失函数由四部分组成:多目标物体检测阶段的损失函数、增强自编码器重建感兴趣区域的损失函数、增强自编码器预测目标物体关键点的损失函数和计算目标物体姿态的损失函数,每部分的损失函数组成如下所述:
(1)多目标物体检测阶段损失函数记为loss1,包括类别损失函数lcls、目标物体二维边界框损失函数lbox,如公式(1)所示:
loss1=loss(p,u,bu,bv,θ,x,y,z)=lcls(p,u)+[u≥1]lbox(bu,bv)(1)
其中,类别损失函数lcls使用交叉熵损失函数,如公式(1)所示:
lcls(p,u)=-log(pu)(2)
对于每个感兴趣区域使用lcls来输出每一类别的概率大小p=(p0,...,pc),目标类别共有c+1类,u表示类别;
二维边界框的损失函数lbox采用smoothl1loss回归损失函数,如公式(3)和(4)所示:
其中,
公式(3)中
(2)增强自编码器重建感兴趣区域的损失函数为lrois,记为loss2,loss2采用mseloss回归损失函数,定义如公式(5)和(6)所示:
loss2=lrois=∑i∈[1,n]mseloss(irois-irois_restore)(5)
其中,
公式中irois代表感兴趣区域的真实值,irois_restore代表重建出的感兴趣区域的重建值,即经过增强自编码器编解码出的感兴趣区域;
(3)增强自编码器预测目标物体关键点的损失函数lkeypoints,记为loss3,loss3也采用smoothl1loss回归损失函数,定义如公式(7)所示:
其中,
(4)计算目标物体姿态的损失函数lpose,记为loss4,loss4也采用smoothl1loss回归损失函数,定义如公式(8)所示;
其中,r表示三维旋转矩阵预测值,
所以模型总的损失函数为公式(9)所示:
本发明方法中利用概率期望连接多目标物体检测阶段与增强自编码器预测物体关键点阶段的具体步骤如下:
首先假设多目标物体检测截断需要学习的权重参数为w,增强编码器阶段需要学习的权重参数为v,由于在计算物体的6d姿态结果与多目标物体检测部分的权重参数w没有直接的导数关系,即多目标物体检测部分与增强自编码器部分无法直接进行前向与后向传播,因此利用增强学习的方法——“动作与奖惩相互作用”实现,即:
(1)首先假设计算物体的6d姿态的评价策略二维重投影或模型顶点平均三维距离作为奖励函数与惩罚函数;
(2)奖-惩函数求得的结果作为奖励或惩罚;
(3)将计算出的6d姿态作为,当奖励或惩罚不符合时,就反向传播loss3更新权重参数v,直到奖励或惩罚符合;姿态包括三维旋转矩阵r与三维平移矩阵t;
其中奖-惩项与多目标物体检测输出的类别有概率关系,如多目标物体检测输出的类别结果x%概率为物体a,此时就有了物体a对应的增强自编码器,即影响最终输出的奖-惩项结果与多目标物体检测有概率关系,所以想实现loss3的前向与反向传播,不需要直接对奖-惩项直接求导,只要对概率求导即可,继而求出所有概率求导后的期望,公式(10)是计算可学习权重参数w和v的导数:
其中,
p(j|w)=exp(-loss1)(11)
reward=lpose(·)=2dprojection(k,r,t)(12)
或者
reward=lpose(·)=add(r,t)(13)
上面公式(10)和(11)中,j代表训练样本,p(j|w)表示选择类别的概率,通过loss1归一化方法exp(-loss1)求得,
所述的v与w求解方式相同,loss2与loss1求解方式相同。
本发明中多目标物体检测阶段采用的评价策略是交并比iou方法,iou是指目标物体的预测二维包围盒与真实二维包围盒的重叠程度α,当iou>α表示正样本,iou定义如公式(15)所示:
其中pr_bbox表示预测的二维边界框,gt_bbox表示真实的二维边界框,交集与并集是二维边界框所占区域的重叠与合并区域。
本发明中6d姿态估计阶段的评价策略采用二维重投影和模型顶点平均三维距离评价方法,分别参考公式(16)和(17)所示:
其中m表示物体3d模型顶点数目,m为物体3d模型顶点集合,k表示相机的内参,x为模型(.ply点云模型)网格顶点;
其中m表示物体3d模型顶点数目,m为物体3d模型顶点集合,rpred表示预测的旋转矩阵,tpred表示预测的平移矩阵,rgt表示实际的旋转矩阵,tgt为实际的平移矩阵;
所述的linemod数据集,其中的鸡蛋盒eggbox和钻头driller是对称物体,其评价方法采用adds,如公式(18)所示:
本发明中用于训练与测试的数据集制作具体步骤如下:
训练使用的数据集是linemod原始数据集,测试使用的数据集采用linemod遮挡数据集,训练与测试的数据集为多目标linemod数据集,其中训练数据集是根据原始数据集合成而来,具体过程为:
①根据原始linemod数据集提供的mask掩模图像,计算出目标在图像中的二维包围盒区域;
②根据二维包围盒在图像中的坐标位置,计算出对应位置的jpeg彩色图像位置;
③linemod图像中共目标的二维包围盒为前景,其余为背景,将背景替换成voc2012中的图像;
④重复步骤①②③,将linemod中13类目标按照上述步骤②随机贴在voc2012图像中,保证每张图像中有13中类别的目标;
⑤对生成的多目标linemod图像进行数据增强。
综上所述,本发明的增益效果如下:
本发明属于目标姿态估计领域,公开了一种基于增强自编码器的室内目标物体6d姿态估计方法与系统。所述的方法分成三个阶段:多目标物体检测阶段首先输入单幅彩色图像到改进版的fasterr-cnn,然后rpn网络提取出候选框,再通过全卷积(fcn)网络输出目标类别概率和二维边界框;概率期望连接增强自编码器(aae)预测物体关键点阶段,通过训练改进版的堆叠式降噪自动编码器(sdae)对感兴趣区域编解码出相同尺寸的无噪声感兴趣区域,再通过全连接层(fc)预测出目标物体在二维图像上的关键点;计算物体姿态阶段pnp根据关键点计算出目标的6d姿态。使用linemod数据集训练后,本发明对于背景杂乱与物体存在遮挡的情况下具有很强的鲁棒性,对光照、颜色不敏感且不要求物体具有丰富的纹理特征。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通发票技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
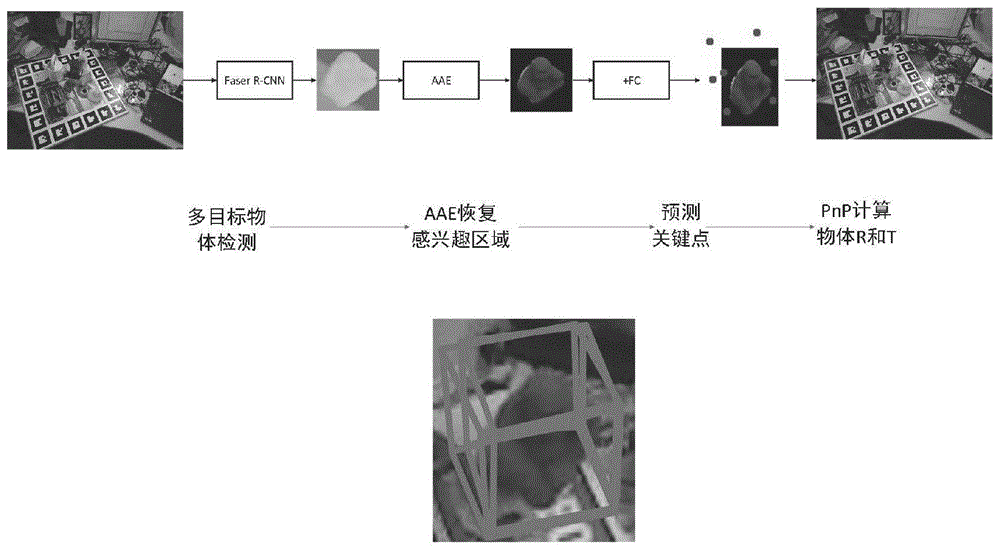
图1是本发明提出方法的整体流程效果图及效果局部放大图;
图2是本发明提出的增强自编码器(aae)的网络结构图;
具体实施方式
为了使本发明的技术方案更加清楚明白,以下结合实施例,对发明内容做更加详细地说明,但发明的保护范围不限于下述的实例,本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
下面结合附图对原理做进一步说明。
如图1所示是本发明提出方法的整体流程图,用实现效果形式显示,以linemod中的ape猿猴类别为例,具体的操作步骤为:
一种基于增强自编码器的室内目标物体6d姿态估计方法与系统,所述的方法分成三个阶段:多目标物体检测阶段首先输入单幅彩色图像到改进版的fasterr-cnn,然后rpn网络提取出候选框,再通过全卷积(fcn)网络输出目标类别概率和二维边界框;概率期望连接增强自编码器(aae)预测物体关键点阶段,通过训练改进版的堆叠式降噪自动编码器(sdae)对感兴趣区域编解码出相同尺寸的无噪声感兴趣区域,再通过全连接层(fc)预测出目标物体在二维图像上的关键点;计算物体姿态阶段pnp根据关键点计算出目标的6d姿态。
多目标物体检测阶段的主要实现步骤有三步:resnet101残差网络提取特征;rpn区域提名网络提取一定数量的rois感兴趣区域;最后经过roihead模块对rois进行类别预测与二维边界框回归,roihead主要包括roialign和fcn两个模块,下面对着三步进行更进一步的解释:
第一步resnet101残差网络提取特征:
(1)输入多目标linemod数据集的彩色图像作为训练样本,此多目标数据集与原始的linemd数据集不同,原始数据集为单目标图像和单目标标注,而多目标数据集是本发明方法合成的,其中地彩色图像宽高尺寸为640*480像素,与在将图像输入之前还需要做两件事:fasterr-cnn要求的图像尺寸为1000*600像素,所以需要将linemod彩色图像更改尺寸为1000*600,标注信息会随之自动更改;同时,为了增加模型的泛化性,对图像进行数据增强,通过改变图像的亮度、对比度、随机增加mask掩膜(图像中显示为黑色小块)、随机增加高斯噪声等;将处理过的多目标彩色图像输入给resnet101残差网络来提取特征;
(2)不同于fasterr-cnn提出的vgg16作为特征提取器,为了提取更多、更好地特征来表征图像,本发明采用网络更深、表征能力的resnet101残差网络作为特征提取器,resnet101可以提取出一定数量的特征图,resnet101的网络结构为:
卷积第1层采用7*7卷积核,输入3,输出64,步长为2;再经过一层下采样层,下采样步长为2;
卷积第2层采用1*1卷积核,输入64,输出64,步长为1;
卷积第3层采用3*3卷积核,输入64,输出64,步长为1;
卷积第2层采用1*1卷积核,输入64,输出256,步长为1;
卷积第5层为第1层后的下采样结果,采用1*1卷积核,输入64,输出256,步长为1;
卷积第6层采用1*1卷积核,输入256,输出64,步长为1;
卷积第7层采用3*3卷积核,输入64,输出64,步长为1;
卷积第8层采用1*1卷积核,输入64,输出256,步长为1;
卷积第9~11层为第6~8层1次;
卷积第12层采用1*1卷积核,输入256,输出128,步长为2;
卷积第13层采用3*3卷积核,输入128,输出128,步长为1;
卷积第14层采用1*1卷积核,输入128,输出256,步长为1;
卷积第15层为第11层后的结果,采用1*1卷积核,输入256,输出512,步长为2;
卷积第16~21层为第12~14层2次;
卷积第23层采用1*1卷积核,输入512,输出256,步长为2;
卷积第24层采用3*3卷积核,输入256,输出256,步长为1;
卷积第25层采用1*1卷积核,输入256,输出1024,步长为1;
卷积第26层为第21层后的结果,采用1*1卷积核,输入512,输出1024,步长为2;
卷积第27层采用1*1卷积核,输入1024,输出512,步长为1;
卷积第28层采用3*3卷积核,输入256,输出256,步长为1;
卷积第29层采用1*1卷积核,输入256,输出1024,步长为1;
卷积第30~93为第27~29重复21次;
卷积第94用1*1卷积核,输入1024,输出512,步长为1;
卷积第95用3*3卷积核,输入256,输出256,步长为1;
卷积第96用1*1卷积核,输入256,输出2048,步长为1;
卷积第97层为第93层的结果,采用1*1卷积核,输入1024,输出2048,步长为1;
卷积第98采用1*1卷积核,输入2048,输出512,步长为1;
卷积第99用3*3卷积核,输入512,输出512,步长为1;
卷积第100用1*1卷积核,输入512,输出2048,步长为1;
卷积第101~103为第98~100层重复1次的结果,然后经过一个平均池化层;
最后连接一个全连接层,输入为2048,输出位类别的数量,本发明采用的linemod数据集类别数量为13类。
第二步rpn区域提名网络对resnet101提取出的特征图(featuresmaps)进行提取感兴趣区域(rois),rpn的操作核心是锚点(anchors),rpn神经网络使用9个锚点,大小为128*128,256*256,单位是像素,3个长宽比为1:1的锚点,3个长宽比为1:2的锚点,3个长宽比为2:1的锚点,主要有4个过程:
(1)对于每张图片,利用它的featuremap,计算(h/16)×(w/16)×9(大概20000)个anchor属于前景的概率,以及对应的位置参数;
(2)选取概率较大的12000个anchor;
(3)利用回归的位置参数,修正这12000个anchor的位置,得到rois;
(4)利用非极大值((non-maximumsuppression,nms)抑制,选出概率最大的2000个rois;
第三步roihead在rpn给出的2000候选框和resnet101提取的特征图之上继续进行分类和位置参数的回归,主要包括roialign固定rois的尺寸为7*7像素和fcn输出类别概率与二维包围盒两个部分,具体过程如下:
(1)fasterr-cnn使用的roipooling方法,但是该方法在经过两次量化后会造成一定偏差,此偏差势必会对后层的回归定位产生影响,所以本发明借鉴maskr-cnn的roialign,roialign对rois区域内的像素采用双线性插值法进行计算,缩减了两次量化带来的偏差,一般对于大目标来说roipooling与roialign的差别不大,但是对于小目标roialign更精准一些,因为本发明使用的linemod数据集中类别基本都是小目标,所以采用roialign的方法将rois量化为固定尺寸7*7的感兴趣区域;
(2)本发明使用fcn全卷积网络代替全连接层将roialign输出的固定大小的rois映射成一个固定长度的特征向量,fcn相比全连接层可大幅度减少网络参数量,再经过平均池化层后,输出两个分支:一个是输出目标物体的类别概率,一个是回归物体二维边界框。
如图2所示,概率期望连接增强自编码器(aae)预测物体关键点阶段主要分成两个阶段增强自编码器重建感兴趣区域和预测物体关键点,具体过程如下:
增强自编码器(aae)重建感兴趣区域是对fasterr-cnn得到的rois感兴趣区域进行编-解码(encoder-decode㈡,本发明采用的增强自编码器(aae)是改进版的堆叠式去噪自编码器(sade),sdae是逐层训练的去噪自动编码器(dae),也可以采用dropout、relu的方法,为了让网络训练收敛,本发明采用的是relu的方法;首先利用编码器encoder对感兴趣区域进行编码,编码是一个降维下采样的过程,将感兴趣区域编码成一个128维的隐变量(lantentcode);然后通过解码器decoder对这个128维的隐变量进行上采样操作,类似于翻卷积,重建出一个相同尺寸的感兴趣区域,从图2中的输入可以看到输入的感兴趣区域颜色和遮挡是非常明显的,经过aae重建出的是目标很清晰的感兴趣区域,如果颜色、遮挡等相对于目标物体如ape)是噪声,那么正式经过改进版的堆叠式去噪声自动编码器(sdae)将噪声(颜色、遮挡等)去掉,恢复出无任何噪声的感兴趣区域,然后在此无噪声的重建感兴趣区域基础上做后续操作,明显比在存在噪声的感兴趣区域上更直接,重建感兴趣区域的具体网络结构为:
卷积第1层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为3,输出为64,步长为2,填充为2;
卷积第2层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为64,输出为128,步长为2,填充为2;
卷积第3层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为128,输出为256,步长为2,填充为2;
卷积第4层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为256,输出为512,步长为2,填充为2;
卷积第5层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为512,步长为2,填充为2;
卷积第6层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为512,步长为2,填充为2;
再通过flatten压片层将第6层的输出映射成一维的特征向量方便计算;
然后再通过一个全连接层fc输出128维的隐变量,输入为2048
上一步encoder已经将感兴趣区域的特征提取出来,保存在输出的128维隐变量中,将encoder输出的128维隐变量输入给decoder用来上采样操作,恢复与原来相同大小的感兴趣区域,且恢复的感兴趣区域只有目标物体没有任何其他噪声,具体的网络结构如下:
卷积第1层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为512,步长为1,填充为2;
卷积第2层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为512,步长为1,填充为2;
卷积第3层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为256,步长为1,填充为2;
卷积第4层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为256,输出为128,步长为1,填充为2;
卷积第5层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为128,输出为64,步长为1,填充为2;
卷积第6层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为64,输出为512,步长为1,填充为2;
卷积第7层使用5*5尺寸的卷积核,对输入的感兴趣区域进行特征提取,输入为512,输出为3,步长为1,填充为2;
在卷积第1~7层之间都有一个relu激活函数层和上采样unsample(sacle_factor=2.0,mode=nearest)层,sacle_factor代表比例因子,用来控制图像宽和高的比例,mode=nearest代表使用功能最近邻方法;
再通过sigmoid()函数层将变量映射到(0,1)区间,方便计算及网络收敛。
增强自编码器(aae)预测物体关键点指在已经重建新的感兴趣区域的基础上,进行预测感兴趣区域内目标物体的关键点,重建感兴趣区域后,感兴趣区域已经是无噪声的感兴趣区域;然后通过编码器encoder对无噪声的感兴趣区域编码成128维隐变量,编码器将感兴趣区域的所有特征都提取出来了,再通过一个全连接层fc输出需要的维度,类似于resnet101最后一层的全连接层输出13种类别一样,这里是输出目标物体的8个关键点,效果如图2所示,
具体实现过程如下:
(1)首先使用恢复感兴趣区域的预训练模型,连接到解码器encoder,网络结构参数不变,这一步骤会将无噪声的感兴趣区域编码成128维隐变量;
(2)再通过一个全连接层输出16维向量,输入为128维隐变量,这个16维向量即代表目标物体的关键点的坐标(x,y),共8个点。
计算物体的6d姿态估计阶段的具体步骤如下:
(1)将增强自编码器预测到的物体的三维包围盒的8个关键点在感兴趣区域的投影输入给epnp算法;
(2)提取linemod数据集自带点云模型中的世界坐标系下的特征点,此特征点是三维坐标,表示为(x,y,z);
(3)提取linemod数据集自带的相机内参矩阵,相机参数是固定的;
(3)相机的畸变参数矩阵设为1个8维全0的矩阵;
(4)将三维坐标点、8个关键点、相机内参矩阵和相机的畸变参数矩阵输入给opencv的solvepnp求解出三维旋转矩阵r和三维平移矩阵t,从而求得目标物体的6d姿态。
对于概率期望、模型算法的网络损失函数设置、衡量算法优劣用到的评价策略和训练与测试数据集制作方法在权利要求书中已详细阐述,不再赘述。
使用linemod数据集训练后,本发明对于背景杂乱与物体存在遮挡的情况下具有很强的鲁棒性,对光照、颜色不敏感且不要求物体具有丰富的纹理特征。
- 还没有人留言评论。精彩留言会获得点赞!