基于EMD分解的EMD-XGBoost中长期风电电量预测方法与流程
基于emd分解的emd-xgboost中长期风电电量预测方法
技术领域
[0001]
本发明属于电力系统领域,具体涉及一种基于emd分解的emd-xgboost中长期风电电量预测方法。
背景技术:
[0002]
日益严重的全球能源危机,使可再生能源的开发得到迅猛发展,为风电的发展提供了重要机遇:2018年全球风电装机新增51.32吉瓦,作为全球最大的风电装机市场,2018年我国风电新增装机容量21.143吉瓦,截止2018年底,我国风电累计装机容量达到209.533吉瓦。风电大规模发展增加了电力系统运行的不确定性,电网稳定性也受到了较大的影响。影响风电接入容量的主要问题是电网的调峰容量,电网没有备用容量,风电则无法接入电网,通过增加水电和快速启停机解决风电接入问题会增加电网调度及发电计划制定的困难。因此,中长期风电发电量预测是风电发展的关键问题之一,风电的发展需以提高风电发电量的预测精度为基础。
[0003]
目前,关于中长期风电电量预测问题,国内外学者通常从物理模型、时间序列模型和智能模型对风电电量的预测进行研究。欧阳庭辉、查晓明、秦亮等人提出了一种基中长期风电功率的多气象变量模型组合预测方法(专利号:cn201711160876.2),利用数值天气预报提供的气象数据预测长期风电趋势,同时局部采用多变量模型改善预测精度,针对不同气象变量进行数据结构分析,并根据其动力学特性单独建立合适的预测模型。以数字气象预报作为预测基础预测方法在中长期风电发电量的预测中起着重要作用,但是,基于气象数据的物理模型还存在很多问题,同时风机的尾流效应也影响预测的精度,因此,目前较为普遍使用的风力发电量预测方法是学习法。候丰花提出一种基于向量机风电预测方法(专利号:cn201310434190.3)。黄跃辉、曲凯、李驰等人提出了一种基于k-means mcmc算法的中长期风电时间序列建模方法,首先,对历史风电功率数据进行聚类,并对聚类后的不同类别风电功率序列选取最优状态数,分别建立状态转移矩阵;其次,用拟合度较好的混合高斯分布拟合多时间尺度的风电最大波动率的概率分布特性;最后,采用基于类间转移概率矩阵的mcmc方法依次生成模拟风电出力时间序列。随着风电电量预测技术的发展,智能算法的改进与发展,组合预测方法将成为一种趋势。
技术实现要素:
[0004]
本发明正是基于上述问题,提出一种基于emd分解的风电电量组合预测算法emd-xgboost。将风电电量时间序列经emd分解为一系列分量,对各分量进行特征提取,以此为基础采用fcm聚类将分量聚类重构为表示风电电量不同信息的趋势项、周期项及随机项,采用xgboost分别对重构项进行预测,叠加得到风电电量的预测结果。发明分析了序列分解及不同算法对预测精度的影响。
[0005]
为了实现上述目的,本发明提供的技术方案如下:
[0006]
步骤1,将风电电量时间序列经emd分解为相互独立的imf序列以及一个res项;
[0007]
步骤2,构造各imf序列的特征向量;
[0008]
步骤3,采用fcm聚类将包含不同波动信息的imf聚类重构为电量的趋势项、周期性项及随机项;
[0009]
步骤4,针对不同序列项分别设置最优参数,将预处理后的驯良数据输入参数调整后的xgboost预测模型中,叠加各序列项预测结果为风电电量预测结果;
[0010]
步骤5,分析序列分解及不同算法对预测精度的影响。
[0011]
作为上述技术方案的补充,步骤1构建过程如下:
[0012]
emd依据数据自身的时间尺度特征进行分解,无需预先设定任何基函数,适用于非线性非平稳信号的分析。由于中长期风电电量序列具有非线性且非平稳的特征,因此,将emd分解应用于中长期风电电量时间序列的分析,emd分解可将复杂的时间序列中真实存在的不同时间尺度的波动或趋势分量通过筛选逐级分解出来,产生有限个反映内部特征且相互独立的分量,各分量保留了非平稳信号在不同时间尺度上的特点。分解后的序列与原始数据序列相比具有更强的规律性;
[0013]
作为上述技术方案的补充,步骤2构建过程如下:
[0014]
步骤2.1,基于特征提取构成向量表示imf及res分量,降低信息维度,减少计算复杂度;
[0015]
步骤2.2,从宏观及局部的角度考虑提取各分量的特征,构造特征值向量:以样本熵作为全局特征,以均值、方差及斜率作为局部特征,通过间隔特征提取得到各特征值。
[0016]
d
i
=[sampen
i
,me
i
,st
i
,sl
i
]
[0017]
me
i
=[me1,me2,...,me
n
]
[0018]
st
i
=[st1,st2,...,st
n
]
[0019]
sl
i
=[sl1,sl2,...,sl
n
]
[0020]
其中,d
i
为分量i对应的特征值向量;sampen
i
为分量i的样本熵;me
i
为分量i的均值矩阵,me
j
为间隔特征提取中第j段序列的均值;st
i
为分量i的方差矩阵,st
j
为间隔特征提取中第j段序列的方差;sl
i
为分量i的斜率矩阵,sl
j
为间隔特征提取中第j段序列的斜率;
[0021]
作为上述技术方案的补充,步骤3构建过程如下:
[0022]
以分量的特征值向量为基础,基于fcm根据包含信息类别的不同对imf及res分量进行分类,重构为表征风电电量发展的趋势项,中长期过程中的周期项及风电电量自身不确定性导致的随机项。
[0023]
作为上述技术方案的补充,步骤4构建过程如下:
[0024]
步骤4.1,中长期风力发电影响因素降维:
[0025]
风力发电受季节和天气因素的影响,选取风电场实际运行数据作为输入,当xgboost特征项存在相关性过高的冗余因素时,模型预测精度会降低。因此,使用spss软件检验所选特征项之间的相关性,筛除冗余项进行特征项降维。
[0026]
步骤4.2,计算pearson相关系数,相关系数的绝对值越大,相关性越强;
[0027]
步骤4.3,xgboost模型超参寻优:
[0028]
风电电量趋势项、周期项及随机项的主要影响因素存在差异,且模型训练时,不同序列的模型参数值也不同,因此,采用贝叶斯优化搜索和k折交叉验证分别进行各序列项的超参寻优;
[0029]
步骤4.4,将预处理后的数据输入各序列项的最优xgboost模型中进行预测。
[0030]
与现有的技术方案相比,本发明提出一种组合预测方法emd-xgboost预测中长期风电电量,算法结合emd分解与聚类算法将风电电量分解为趋势项、周期项及随机项,并分别进行预测,有益效果为:将较长时间尺度下风电电量时间序列中真实存在的不同波动量分解出来,将非线性非平稳的电量序列平稳化,产生不同特征的电量数据序列;针对各重构序列分别建立预测模型,选择各自最优相关参数,从而降低了风电电量数据分线性和非平稳性对电量预测结果的影响。
附图说明
[0031]
图1为emd-xgboost预测方法流程图;
[0032]
图2为emd分解结果图;
[0033]
图3为分解分量重构图;
[0034]
图4为特征项相关性图;
[0035]
图5为emd分解前后预测对比图;
[0036]
图6为emd-xgboost重构序列预测图;
[0037]
图7为基于emd分解的各类算法预测结果对比图。
具体实施方式
[0038]
下面结合附图,对本发明做进一步的详细说明,但本发明的实施方式不限于此。
[0039]
本发明针对中长期风电电量预测设计了一种结合特征提取与聚类算法的组合预测方法emd-xgboost,算法流程图如图1所示,包括以下具体步骤:
[0040]
步骤1,将风电电量时间序列经emd分解为相互独立的imf序列以及一个res项;
[0041]
如图2所示,青海省某风电场一年风电电量的历史数据序列经emd分解为5个imf分量及一个趋势分量res。
[0042]
步骤2,构造各imf序列的特征向量;
[0043]
步骤2.1,基于特征提取构成向量表示imf及res分量,降低信息维度,减少计算复杂度;
[0044]
步骤2.2,从宏观及局部的角度考虑提取各分量的特征,构造特征值向量:以样本熵作为全局特征,以均值、方差及斜率作为局部特征,通过间隔特征提取得到各特征值。
[0045]
d
i
=[sampen
i
,me
i
,st
i
,sl
i
]
[0046]
me
i
=[me1,me2,...,me
n
]
[0047]
st
i
=[st1,st2,...,st
n
]
[0048]
sl
i
=[sl1,sl2,...,sl
n
]
[0049]
其中,d
i
为分量i对应的特征值向量;sampen
i
为分量i的样本熵;me
i
为分量i的均值矩阵,me
j
为间隔特征提取中第j段序列的均值;st
i
为分量i的方差矩阵,st
j
为间隔特征提取中第j段序列的方差;sl
i
为分量i的斜率矩阵,sl
j
为间隔特征提取中第j段序列的斜率;
[0050]
步骤3,采用fcm聚类将包含不同波动信息的imf聚类重构为电量的趋势项、周期性项及随机项;
[0051]
以分量的特征值向量为基础,基于fcm根据包含信息类别的不同对imf及res分量
进行分类,重构为表征风电电量发展的趋势项,中长期过程中的周期项及风电电量自身不确定性导致的随机项。
[0052]
风电电量序列携带的不同波动信息,分别包含在不同分级分量中,为充分利用不同信息特征更合理的预测风电电量,将分解后的分量进行分类重构为趋势项、周期项及随机项。如图3所示,对于分解后所得5个imf及1个res分量,以各分量的特征向量为样本,经fcm聚类得到各样本对各类中心的隶属度,从而决定样本的类属达到对样本进行分类的目的,聚类结果为将风电电量序列分解分量重构为趋势项、周期项及随机项。
[0053]
步骤4,针对不同序列项分别设置最优参数,将预处理后的驯良数据输入参数调整后的xgboost预测模型中,叠加各序列项预测结果为风电电量预测结果;
[0054]
步骤4.1,中长期风力发电影响因素降维:
[0055]
风力发电受季节和天气因素的影响,选取风电场实际运行数据作为输入,当xgboost特征项存在相关性过高的冗余因素时,模型预测精度会降低。因此,使用spss软件检验所选特征项之间的相关性,筛除冗余项进行特征项降维。
[0056]
如图4所示,f1-f6为风电场输入数据,分别表示影响因素:气压、温度、湿度、风速、日照强度及日照时长,通过输入特征项的降维,提高xgboost预测精度。
[0057]
步骤4.2,计算pearson相关系数,相关系数的绝对值越大,相关性越强;
[0058]
通常,双尾检验概率值小于0.01%时,认为相关性显著;皮尔森相关系数值位于[0.8,1]时,可认为两个变量呈现极强相关。相关系数如图4所示,认为各特征项之间相关性较弱,所选特征因素中不存在冗余项,以此作为输入进行风电电量的xgboost预测。
[0059]
步骤4.3,xgboost模型超参寻优:
[0060]
风电电量趋势项、周期项及随机项的主要影响因素存在差异,且模型训练时,不同序列的模型参数值也不同,因此,采用贝叶斯优化搜索和k折交叉验证分别进行各序列项的超参寻优;
[0061]
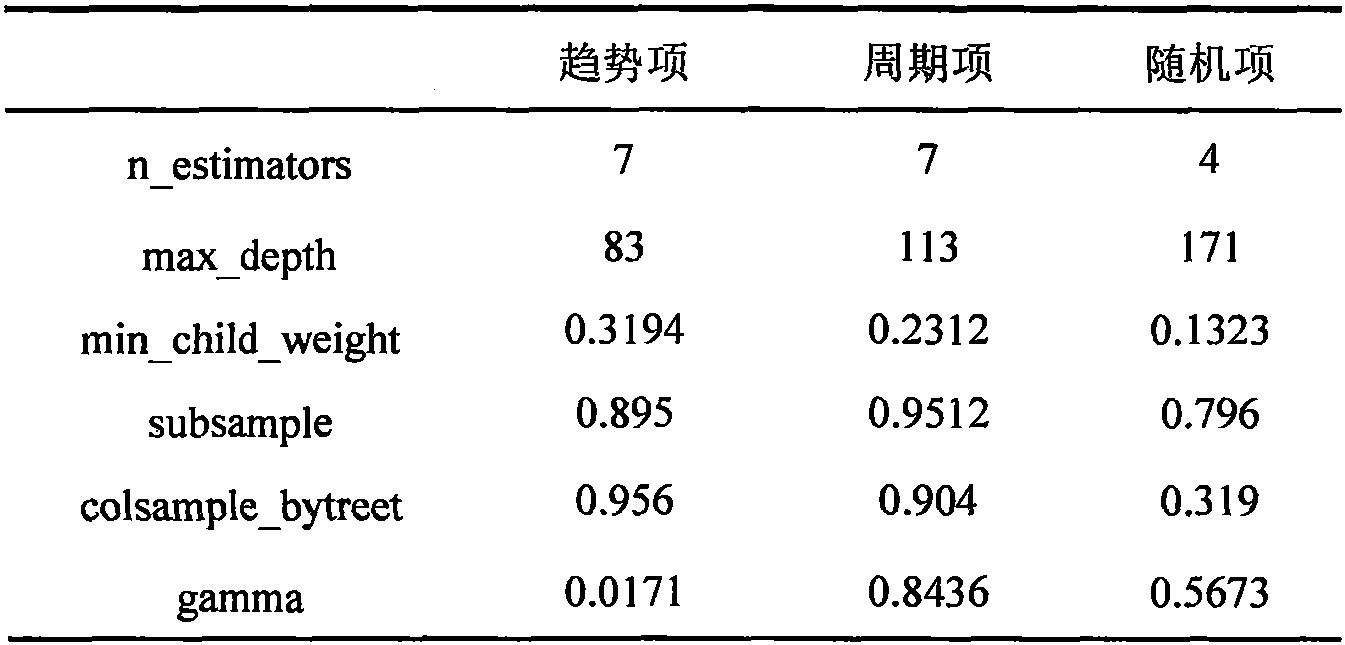
如表1所示,经参数寻优,风电电量趋势项、周期项及随机项构造的各xgboost模型最优超参结果不同。
[0062]
表1各重构序列xgboost最优超参值
[0063][0064]
其中,n_estimators表示决策数个数;max_depth、min_child_weight、gamma控制模型的复杂度;subsample及colsample_bytree为构造树时随机抽取样本及特征的抽取比例;
[0065]
步骤4.4,将预处理后的数据输入各序列项的最优xgboost模型中进行预测。
[0066]
步骤5,分析序列分解及不同算法对预测精度的影响,说明风电电量组合预测算法emd-xgboost的适用性。
[0067]
下面通过仿真实例对本发明所设计的方法进行验证。
[0068]
为对比分析,设计一下两种场景:
[0069]
场景1:未经emd分解的random forest、svm、gbr及xgboost算法的风电电量序列直接预测结果。
[0070]
场景2:基于emd分解的random forest、svm、gbr及xgboost算法预测,预测结果为趋势项、周期项及随机项预测结果叠加值;
[0071]
如表2-3所示,对比各算法分解前后的预测结果可得,场景2经emd分解的预测结果mape及rmse值普遍小于场景1对应方法直接预测结果,说明经分解后的预测结果与该地区风电场实际电量分布函数更接近,因此基于emd分解的预测方法优于对序列的直接预测,emd分解预测可以提高预测精度;
[0072]
表2未经emd分解的电量序列直接预测
[0073][0074]
表3基于emd分解的电量序列预测
[0075][0076]
各类电量预测方法预测曲线如图5所示。图形更直观的体现了经emd分解后的预测与风电场电量实际曲线更接近。emd分解将序列中真实存在的不同时间尺度的波动分量逐级分解出来,趋势项、周期项及随机项体现了原始信号在不同频率下的波动特点,经emd分解的预测模型结合了不同时间尺度下风电电量的特点,对于不同分量更具有针对性及良好的适应性,因此,提高了原始序列预测的准确性。
[0077]
图6为通过最优超参xgboost模型得到的各序列项预测结果。从测试集数据的预测情况可得,emd-xgboost所得各序列预测结果均较为理想。
[0078]
基于emd分解的各模型决定系数r2的结果如表4所示,可以得到,emd-xgboost方法预测结果的r2值大于其他方法。r2越接近于1说明模型拟合度越好,该表从数值方面证明了emd-xgboost法在中长期电量预测问题上的优越性。
[0079]
表4基于emd分解的各方法电量预测结果
[0080][0081]
基于emd分解的各方法的预测曲线如图7所示,直观地表示出emd-xgboost与实际序列之间较高的拟合度。因此,基于emd分解的xgboost模型在风电电量预测问题上具有良好的适用性,且具有较高的预测精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1