数据脱敏方法及装置与流程
本申请涉及数据安全技术领域,特别是涉及数据脱敏方法及装置。
背景技术:
数据库是比较常见的存储介质,用于存储数据,如存储与用户相关的数据记录。
数据库中存在具有一定安全性的安全系统,用以防止恶意用户的对数据库的攻击。但该系统容易被恶意用户通过非法手段绕过,进而将数据库中的数据记录进行窃取,如窃取某用户的姓名、银行卡账号等。导致与用户相关的数据记录被曝光,用户相关信息泄露。
为此,需要一种数据脱敏方法,以保证与用户相关的数据记录的安全。
技术实现要素:
有鉴于此,本申请提供了一种数据脱敏方法,以保证数据记录的安全。另外,本申请还提供了一种数据脱敏装置,用以保证所述方法在实际中的应用及实现。
为实现所述目的,本申请提供的技术方案如下:
第一方面,本申请提供了一种数据脱敏方法,包括:
获得目标数据集合,所述目标数据集合包含相同内容类型的若干条数据记录;
对所述数据记录进行分词处理,得到所述数据记录的若干个分词;
计算各个分词在所有数据记录的所有分词中的出现频率;
将出现频率达到预设频率阈值的分词确定为特征分词;
针对每条数据记录,将所述数据记录包含的特征分词之外的分词进行加密处理,以得到脱敏后的数据记录。
第二方面,本申请提供了一种数据脱敏装置,包括:
获取模块,用于获得目标数据集合,所述目标数据集合包含相同内容类型的若干条数据记录;
分词模块,用于对所述数据记录进行分词处理,得到所述数据记录的若干个分词;
计算模块,用于计算各个分词在所有数据记录的所有分词中的出现频率;
确定模块,用于将出现频率达到预设频率阈值的分词确定为特征分词;
加密模块,用于针对每条数据记录,将所述数据记录包含的特征分词之外的分词进行加密处理,以得到脱敏后的数据记录。
由上述技术方案可知,本申请提供了一种数据脱敏方法,该方法通过获取存储于数据库中的目标数据集合,该集合中包含多条数据记录;对数据记录进行分词处理,得到对应的若干个分词,计算每个分词所出现的频率,若某分词出现的频率大于预设频率阈值,则将该分词作为特征分词;针对某条数据记录,将该数据记录中除特征分词之外的其他分词进行加密处理,以得到脱敏后的数据记录。该方法从目标数据集合中提取出出现次数较多的分词作为特征分词,对特征分词之外的分词进行加密处理,以得到加密后的数据记录。若某条数据记录被恶意用于所窃取,该恶意用户也无法获取到该数据记录中除特征分词之外的其他数据信息,进而保障数据记录的安全。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本申请提供的一种数据脱敏方法的流程图;
图2为本申请提供的另一种数据脱敏方法的流程图;
图3为本申请提供的一种数据脱敏装置的结构框图;
图4为本申请提供的另一种数据脱敏装置的结构框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
数据库中存储有若干条数据记录,每条数据记录都包含若干个与用户信息相关的数据。
数据库中设置有安全系统,用以防止恶意用户对数据库的攻击。但是该安全系统可能会被恶意用户成功绕过,进而窃取存储在数据库中数据记录,导致用户的相关信息泄露。
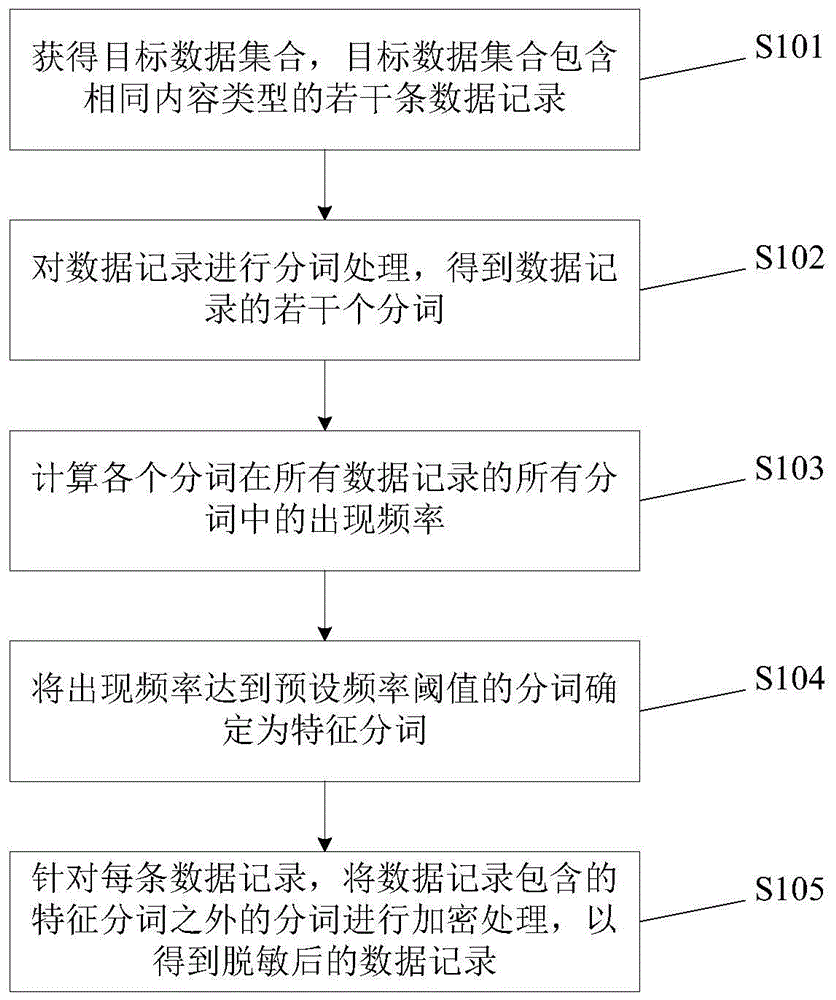
为此,本申请提供了一种数据脱敏方法。参见图1,该方法包括步骤s101-s105。其中:
s101:获得目标数据集合,目标数据集合包含相同内容类型的若干条数据记录。
需要说明的是,数据记录是以数据表的形式存储于数据库中的,数据表中存在若干条数据记录,而相同内容类型的数据记录为数据表中的某一列,如地址类所对应的列。而相同内容类型的数据记录所对应的列,称之为目标数据集合。
具体地,获取目标数据集合,并提取目标数据集合中的数据记录。如:获取地址类的目标数据集合,提取出地址类目标数据集合中所有的数据记录,如提取山东省菏泽市、山东省金口镇等其他地址的数据记录。
为实现对数据记录的加密操作,需要将目标数据集合中的所有数据记录进行加密。
s102:对数据记录进行分词处理,得到数据记录的若干个分词。
具体地,将上述步骤提取得到的数据记录进行分词处理,若数据记录为文字类型字符串,则获取前缀词典,根据前缀词典进行分词;若数据记录为数字类型字符串,则使用该数字类型字符串预先设定数据切分方式进行切分;经分词处理后,得到若干个切分后的分词。
需要说明的是,对数据记录进行分词的方式可以是多种,例如:通过前缀词典进行分词、通过数据切分方式进行分词,其分词方式还可以是其他形式,此处不再具体说明。
s103:计算各个分词在所有数据记录的所有分词中的出现频率。
具体地,将目标数据集合中所有的数据记录进行分词,以得到所有数据记录的分词,统计所有分词出现的次数,将某分词出现的次数除以所有分词出现的总次数,即可得到该分词对应的出现频率。如地址类的某个目标数据为山东省金口镇,其中,“山东省”在所有数据记录的分词中出现了100次,“金口镇”出现了10次,以统计的方式来计算出若干条数据记录的所有分词出现的总次数,再除以所有分词出现的总次数,以得到该分词的出现频率。
s104:将出现频率达到预设频率阈值的分词确定为特征分词。
需要说明的是,预设频率阈值是预先设置的具体数值,如地址类的数据记录,预设频率阈值为0.8;姓名类的预设频率阈值为0.6,除此之外,还有其他类的预设频率阈值。该预设频率阈值是预设某分词出现的总次数除以所有分词出现的总次数得到的。
具体地,经分词统计,并计算出各个分词的出现概率之后,若某个分词出现的频率达到预设频率阈值,则将出现频率达到预设频率阈值的分词作为特征分词,如地址类的数据记录,“山东省”出现的频率为0.9,预设频率阈值为0.8,则将分词“山东省”作为特征分词。
可以理解的是,特征分词具体指的是在目标数据集合中的不同数据记录中出现次数较多的分词,特征分词可以反映目标数据集合中的数据记录有哪些分词是相同的,确定这种特征分词的目的是,在防止数据记录被窃取的场景中,实现数据记录的重定向,提高数据记录的安全性。至于具体原理请见下述说明。
s105:针对每条数据记录,将数据记录包含的特征分词之外的分词进行加密处理,以得到脱敏后的数据记录。
需要说明的是,加密之前的数据记录是明文显示,加密后的数据记录是密文显示。例如:某电话号码为12345678901,属于明文,经确定特征分词等操作之后,对特征分词之外的电话号码进行加密,经加密后的电话号码则称为密文,如上述电话号码的特征分词为12345,则加密后的电话号码为12345******。
具体地,经过分词处理之后,目标数据集合中所有的数据记录包含特征分词以及特征分词之外的分词。其中,特征分词是多条数据记录的共同特征,不需要对其进行加密。对于某条数据记录来说,敏感数据是该数据记录较为特殊的数据,即特征分词之外的分词,即具有区别性的,所以敏感数据所对应的分词出现的次数较少。为此,针对特征分词之外的分词进行加密处理,以得到脱敏后的数据记录。例如,“山东省”为特征分词,“金口镇”不是特征分词,则根据上述加密规则,对“金口镇”进行加密,以使得加密后是数据显示不完整,如山东省***。
由上述技术方案可知,本申请提供了一种数据脱敏方法,该方法通过获取存储于数据库中的目标数据集合,该集合中包含多条数据记录;对数据记录进行分词处理,得到对应的若干个分词,计算每个分词所出现的频率,若某分词出现的频率大于预设频率阈值,则将该分词作为特征分词;针对某条数据记录,将该数据记录中除特征分词之外的其他分词进行加密处理,以得到脱敏后的数据记录。该方法从目标数据集合中提取出出现频率较多的分词作为特征分词,对特征分词之外的分词进行加密处理,以得到加密后的数据记录。若某条数据记录被恶意用于所窃取,该恶意用户也无法获取到该数据记录中除特征分词之外的其他数据信息,进而保障数据记录的安全。
为方便理解上述技术方案,本申请提供上述方案的一种防止数据记录被窃取的应用场景:目标数据集合中的数据记录可以认为是数据表中的字段,这些数据记录和其他字段具有关联关系,即目标数据集合中的字段和其他字段合并作为同一条数据记录。本申请提供的技术方案可以防止恶意用户通过目标数据集合中的字段,窃取同一条数据记录中的其他字段信息。
具体地,对于数据表而言,每一列表示一类目标数据集合,如地址类、姓名类以及身份证类等等。该数据表是用于记录用户的相关信息的,如包括两个员工信息:张三,山西省太原市,身份证号码为12345611111111;李四,山西省太原市,身份证为12345622222222。
如果上述数据表中的某一类字段的字段值不进行加密,恶意用户可能通过非法手段获取该数据表,恶意用户还可能通过其他方式获取到该字段的某个具体字段值,则可以通过该具体字段值,在数据表中准确定位到一条数据记录,进而窃取该数据记录的其他字段的字段值。
例如,上述数据表中的身份证这个字段并未加密,恶意用户从其他数据中获取到一个身份证号码为12345611111111,则恶意用户可以根据该身份证号码从数据表中准确定位到一个身份证号码,进而根据该身份证号码从数据表中窃取该身份证号码对应的其他字段信息,如窃取到该身份证号码对应的姓名为“张三”,地址为“山西省太原市”。
但是,本申请提供的方法可以对数据记录中的身份证号码这个字段进行加密,假设上述两条数据记录加密后为:张三,山西省太原市,身份证号码为:123456********;李四,山西省太原市,身份证为123456********。这样,虽然恶意用户窃取到的身份证号码为12345611111111,但其并不能定位到某一条具体的数据记录上,增强了数据的安全性。当然,也可以使用本申请提供的方法对其他字段进行加密处理。
具体来说,本申请可以将恶意用户所要窃取数据记录的链接关联到多个与该数据记录具有相同特征分词的数据记录上,例如:某恶意用户通过该链接窃取数据记录为1234567890123456的银行卡号,经本申请所提供的数据脱敏方法对该数据记录为1234567890123456进行处理之后,将关联出与该数据记录具有相同特征分词的所有数据记录,具体为:将若干个数据记录进行分词,统计所有分词出现的频率,若频率大于预设频率阈值,则列为特征分词,对特征分词之外的其他分词进行加密,生成加密的数据记录。通过本申请加密后的数据记录中,具有相同特征分词的数据记录,所显示出来的数据记录是一致的,若上述恶意用户所要窃取的银行卡号与存储于数据库中的某个银行卡号:1234567890987654具有相同的特征分词,即1234567890,则将特征分词之外的数据加密,即经加密后的两个数据记录均为1234567890******,当恶意用户使用链接窃取时,会关联到两条数据记录,且数据记录是加密的无法区分,进而保证数据记录的安全。
需要说明的是,数据记录的数据类型可以包括两种,一是文字类型字符串,二是数字类型字符串。针对不同数据类型的数据记录,分词处理的方式也不一样。为此:
在一个示例中,当数据记录为文字类型字符串时,对数据记录进行分词处理,得到与该数据记录对应的若干个分词,包括:
获得与数据记录的内容类型对应的前缀词典,前缀词典包括该内容类型的多个数据语料,且每个数据语料对应有若干种分词子结果;在前缀词典包括的数据语料中,确定数据记录包含的目标数据语料;分别从不同目标数据语料的分词子结果中获取一种分词子结果并依次进行组合,得到数据记录的分词总结果;在数据记录的分词总结果中,确定目标分词总结果,其中目标分词总结果用于表示数据记录的若干个分词。
需要说明的是,前缀词典的生成方式:利用爬虫技术从网络新闻、报纸电子书籍等相关文本中获取数据语料,对获取到的数据语料进行去重、删除错误数据语料等操作后,建立数据语料库;根据预先设置的分类规则,将数据语料库进行分类,如地址类的数据语料,姓名类的数据语料;再对分类之后的数据语料进行分词,如地址类的数据语料中,“山西省”这一数据语料,经分词之后,得到若干个分词子结果,如“山西省”、“山西/省”以及“山/西/省”分词子结果,经分词操作之后的数据语料库,称为前缀词典。
具体地,前缀词典与数据记录的内容类型是对应的,根据数据记录的内容类型获取前缀词典。例如,数据记录的内容类型为地址,则获取地址类数据记录所对应的前缀词典;又如数据记录的内容类型为姓名,获取姓名对应的前缀词典。然后,根据前缀词典对数据记录进行分词,分词的具体过程如下。
首先,从前缀词典的多个内容类型的数据语料中,确定出与数据记录相关的数据语料,称为目标数据语料,如一条数据记录为“山西省太原市”,则从前缀词典中确定的目标数据语料为“山西省”以及“太原市”。
然后,从前缀词典中,确定目标数据语料所对应的所有分词子结果,如:“山西省”这一目标数据语料,对应的分词子结果包括:“山/西/省”、“山西/省”以及“山西省”;“太原市”这一目标数据语料,所对应的分词子结果为“太/原/市”、“太原/市”以及“太原市”。
接着,将每个目标数据语料的一种分词子结果与其他目标数据语料的一种分词子结果按照所对应的目标数据语料在数据记录中的排列顺序进行组合,生成分词总结果,如“山西省/太原市”、“山西省/太原/市”、“山西省/太/原/市”以及“山/西/省/太原市”等多个分词总结果。
最后,从多个分词总结果中,确定一种目标分词总结果。
在一个示例中,从多个分词总结果中,确定目标分词总结果的具体实施方式为:
前缀词典中的每种分词子结果具有对应的出现概率值,针对数据记录的每一种分词总结果,从前缀词典中获得用于组合得到分词总结果的分词子结果的出现概率值;将用于组合得到分词总结果的分词子结果的出现概率值进行相乘,得到分词总结果的出现概率总值;将出现概率总值最大的分词总结果确定为目标分词总结果。
具体地,经分词后的目标数据语料对应的每一种分词子结果,都对应着一个概率值,如“山西省”这一目标数据语料,分词子结果有“山/西/省”、“山西/省”以及“山西省”,其中“山/西/省”这一分词子结果所对应的概率为a;“山西/省”这一分词子结果所对应的概率为b;“山西省”这一分词子结果所对应的概率为c;需要说明的是,a、b以及c都是具体数值,每个分词子结果的概率值可以由其包括的分词的出现概率得到的,如将各个分词的出现概率值相乘后得到分词子结果的概率值。
分词总结果是从每个目标数据语料所对应的多个分词子结果中,分别提取出一种分词子结果进行组合得到的,所以分词总结果也会对应有一个概率值,该概率值是由组成该分词总结果的所有分词子结果的概率值的乘积。例如:“山西省”这一分词子结果对应的概率值为0.3,“太原市”这一分词子结果对应的概率值为0.4,则“山西省太原市”分词为:{“山西省”,“太原市”}这一分词总结果的概率值为0.12,即概率值0.3乘以概率值0.4得到的。计算所有分词总结果的概率值,选取概率值最大的分词总结果作为目标分词总结果。
在一个示例中,当数据记录为数字类型字符串时,对数据记录进行分词处理,得到数据记录的若干个分词,包括:
确定与数据记录的内容类型对应的数据切分方式;按照数据切分方式,对数据记录进行分词处理,得到数据记录的若干个分词。
具体地,将数据记录进行数据切分方式可以分为两种方式:
第一种:数据切分方式与数据记录的内容类型是相对应,针对不同内容类型的数据记录,所切分的方式有所不同,例如:身份证号码类的数据记录,该数据记录对应的数据切分方式是预先设计好的,如某个区域的身份证号码的前3位的字符串都是相同的,则针对此种情况,将该身份证号码的数据记录切分为两部分,一部分是前3位的字符串,另外一部分是剩余的字符串。
第二种,遍历相同内容类型的数据记录,如果若干个数据记录中存在相同预设长度的子字符串,则将相同的子字符串作为数据切分方式,即将该子字符串作为切分的一部分,剩余其他字符串作为另外一部分。例如:手机号码类的数据记录,例如:存在电话号码为12345678901、12312345678,根据上述方法,遍历两个电话号码后,根据相同子字符串进行切分,其切分结果为123/45678901,123/12345678。
需要说明的是,针对数字类型字符串、且不同的内容类型的数据记录,所使用的数据切分方式并不是固定的,不同内容类型的数据记录,所对应的数据切分方式可以是相同的,但也可以是不同的。如上述中身份证号码这一类数据记录,所使用的数据切分方式是根据身份证号码前6位数字所对应的区域来切分的。又如上述中的电话号码,是通过遍历多个号码,进而确定多个号码之间存在的相同子字符串来进行数据切分的。
为了保证脱敏后是数据记录不被恶意用户结合其他信息,将该数据记录推算出来,需要对该数据记录的特征分词进行编码处理。
在一个示例中,上述数据脱敏方法实施例除了包括步骤s101-s105之外,参见图2,该方法还包括s106。
s106:针对每个脱敏后的数据记录,将脱敏后的数据记录包括的特征分词进行编码处理,以得到的目标脱敏数据记录。
具体地,将每个脱敏后的数据记录进行编码处理,以得到目标脱敏数据记录。例如:经脱敏后的数据记录为123456************,该数据记录为身份证号码,根据身份证号码的特征分词,即身份证号码的前几位便可以推算出该身份证号码所对应的区域,进而得到该身份证号码的部分信息。为进步一提高数据记录的安全性,将特征分词进行编码,例如上述的身份证号码,经编码后为:456123************。该编码过程可以是任一一种编码方式,此处不再具体说明。
本申请提供了一种数据脱敏装置。参见图3,该装置包括:获取模块301、分词模块302、计算模块303、确定模块304以及加密模块305。其中:
获取模块301,用于获得目标数据集合,目标数据集合包含相同内容类型的若干条数据记录。
分词模块302,用于对数据记录进行分词处理,得到数据记录的若干个分词。
计算模块303,用于计算各个分词在所有数据记录的所有分词中的出现频率。
确定模块304,用于将出现频率达到预设频率阈值的分词确定为特征分词。
加密模块305,用于针对每条数据记录,将数据记录包含的特征分词之外的分词进行加密处理,以得到脱敏后的数据记录。
由上述技术方案可知,本申请提供了一种数据脱敏装置,该装置通过获取存储于数据库中的目标数据集合,该集合中包含多条数据记录;对数据记录进行分词处理,得到对应的若干个分词,计算每个分词所出现的频率,若某分词出现的频率大于预设频率阈值,则将该分词作为特征分词;针对某条数据记录,将该数据记录中除特征分词之外的其他分词进行加密处理,以得到脱敏后的数据记录。该装置从目标数据集合中提取出出现频率较多的分词作为特征分词,对特征分词之外的分词进行加密处理,以得到加密后的数据记录。若某条数据记录被恶意用于所窃取,该恶意用户也无法获取到该数据记录中除特征分词之外的其他数据信息,进而保障数据记录的安全。
在一个示例中,当数据记录的数据类型为文字类型字符串时,分词模块在对数据记录进行分词处理,得到数据记录的若干个分词时,具体用于:
获得与数据记录的内容类型对应的前缀词典,前缀词典包括内容类型的多个数据语料,且每个数据语料对应有若干种分词子结果;在前缀词典包括的数据语料中,确定数据记录包含的目标数据语料;分别从不同目标数据语料的分词子结果中获取一种分词子结果并依次进行组合,得到数据记录的分词总结果;在数据记录的分词总结果中,确定目标分词总结果,其中目标分词总结果用于表示数据记录的若干个分词。
在一个示例中,前缀词典中的每种分词子结果具有对应的出现概率值,则分词模块在数据记录的分词总结果中,确定目标分词总结果时,具体用于:
针对数据记录的每一种分词总结果,从前缀词典中获得用于组合得到分词总结果的分词子结果的出现概率值;将用于组合得到分词总结果的分词子结果的出现概率值进行相乘,得到分词总结果的出现概率总值;将出现概率总值最大的分词总结果确定为目标分词总结果。
在一个示例中,当数据记录的数据类型为数字类型字符串时,则分词模块在对数据记录进行分词处理,得到数据记录的若干个分词时,具体用于:
确定与数据记录的内容类型对应的数据切分方式;按照数据切分方式,对数据记录进行分词处理,得到数据记录的若干个分词。
在一个示例中,参见图4,数据脱敏装置在包括上述图3所述结构的基础上,还可以包括:
编码模块306,用于针对每个脱敏后的数据记录,将脱敏后的数据记录包括的特征分词进行编码处理,以得到的目标脱敏数据记录。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括上述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!