基于数据分析的风险案件筛选方法及相关设备与流程
本发明涉及大数据技术领域,尤其涉及一种基于数据分析的风险案件筛选方法及相关设备。
背景技术:
理赔案件的赔案品质审计,也叫理赔品质审计,是对理赔工作质量的检查、审核、评价等业务监督活动。通过对大量的理赔案件进行抽检,来识别风险案件,检查理赔制度落实的有效性,为改善理赔赔付质量,优化理赔流程起到举足轻重的作用。
在理赔系统中,存储有大量的理赔案件,需要人工对理赔案件进行筛选,筛选出风险案件后,需要对风险案件进行归类,将归类后的风险案件进行风险分析。现有的在对风险案件进行归类时,只能采用人工方式进行归类,归类量大,人工方式效率低、强度大,不适合大量理赔案件的风险分析处理。
技术实现要素:
有鉴于此,有必要针对风险案件进行归类时,人工归类方式效率低下、强度大的问题,提供一种基于数据分析的风险案件筛选方法及相关设备。
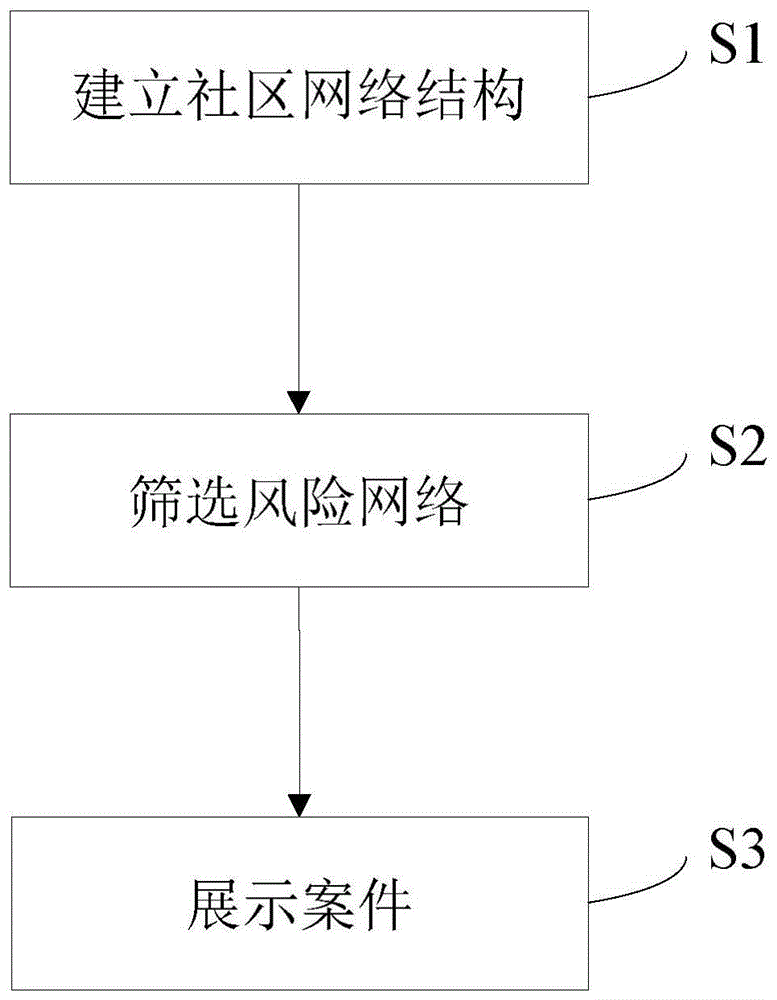
一种基于数据分析的风险案件筛选方法,包括:
获取分包案件组,将所述分包案件组中案件的多项主体设置为多个实体,将所述主体间的社交关系设置为关系;
根据所述实体和所述关系,建立社区网络结构;
将所述社区网络结构划分为多个社区网络,计算所述社区网络中每个实体的风险值;
若所述风险值大于预设的风险阈值,则所述实体为风险实体,所述实体所在的社区网络为风险网络;
将所述风险网络和所述风险网络中所有实体对应的案件进行展示。
一种可能的设计中,所述获取分包案件组,将所述分包案件组中案件的多项主体设置为多个实体,将所述主体间的社交关系设置为关系,根据所述实体和所述关系,建立社区网络结构前,包括:
接收专业审计请求,展示维度筛选界面,通过所述维度筛选界面获取用户选择的维度数据;
根据所述维度数据,在预设的案件数据库中筛选出符合所述维度数据的案件;
将所有筛选出的所述案件为一组分包案件组进行存储。
一种可能的设计中,所述将所有筛选出的所述案件为一组分包案件组进行存储前,还包括:
接收案件筛选请求,展示案件筛选界面,所述案件筛选界面包括车筛选选项和人伤筛选选项;
若接收到用户触发所述车筛选选项,则展示车筛选界面,通过所述车筛选界面获取车筛选选项及车筛选因子字段,根据所述车筛选选项及车筛选因子字段对所述分包案件组内的案件进行筛选,得到筛选后的一组分包案件组;
若接收到用户触发人伤筛选选项,则展示人伤筛选界面,通过所述人伤筛选界面获取人伤筛选选项及人伤筛选因子字段,根据所述人伤筛选选项及人伤筛选因子字段对所述分包案件组内的案件进行筛选,得到筛选后的一组分包案件组。
一种可能的设计中,所述将所述社区网络结构划分为多个社区网络,包括:
将所述社区网络结构中每个实体设为一个节点,将每个所述节点均设为一个独立的社区;
对第i个节点分配到其每个邻居节点所在的社区,计算分配前与分配后的模块度变化δq,并记录δq最大的邻居节点,如果最大的模块度变化maxδq>0,则把节点i分配δq最大的所述邻居节点所在的社区,否则保持不变,重复本步骤,直到所有节点的所属社区不再变化;
将所有在同一个社区的节点设为一个节点集,不同所述社区间的边权重设为所述节点集之间的边权重,重复上一步,直到所述节点集的所属社区不再变化;
将每个所述社区及其中的节点集确认为一个社区网络,每个所述社区网络中含有一个或多个节点集。
一种可能的设计中,所述计算分配前与分配后的模块度变化δq,包括:
计算分配前的模块度q和分配后的模块度q,所述模块度变化δq为:
δq=|qi-qij|
其中,qi为第i个节点分配到第j个邻居节点前的模块度q的值,qij为第i个节点分配到第j个邻居节点后的模块度q的值;
所述模块度q的计算公式如下:
其中,aij表示节点i和节点j之间边的权重,当两个节点直接相连时,aij=1,否则aij=0;ki=∑jaij表示所有与节点i相连的边的权重之和;ci表示节点i所属的社区;
一种可能的设计中,所述计算所述社区网络中每个实体的风险值,包括:
分别对所述社区网络中每个实体计算集中度,其中,所述实体为所述社区网络中的节点,所述实体的集中度即为所述实体的风险值;
所述集中度的计算公式如下:
其中,ci为所述社区网络中第i个节点的集中度,n为所述社区网络中节点的个数,j为除第i个节点外的其他节点,d(i,j)为从第i个节点出发到第j个节点的最短路径长度。
一种可能的设计中,所述将所述风险网络和所述风险网络中所有实体对应的案件进行展示,包括:
将所述风险网络通过图谱的形式进行展示,将所述风险网络中的所有实体对应的所有案件通过表格的形式进行展示;
在展示时,对所述风险网络中大于所述风险阈值的实体及对应的案件进行突出标注。
一种基于数据分析的风险案件筛选装置,包括:
建立社区网络结构模块,用于获取分包案件组,将所述分包案件组中案件的多项主体设置为多个实体,将所述主体间的社交关系设置为关系,根据所述实体和所述关系,建立社区网络结构;
筛选风险网络模块,用于将所述社区网络结构划分为多个社区网络,计算所述社区网络中每个实体的风险值,若所述风险值大于预设的风险阈值,则所述实体为风险实体,所述实体所在的社区网络为风险网络;
展示模块,用于将所述风险网络和所述风险网络中所有实体对应的案件进行展示。
一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述基于数据分析的风险案件筛选方法的步骤。
一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述基于数据分析的风险案件筛选方法的步骤。
上述基于数据分析的风险案件筛选方法及相关设备,包括获取分包案件组,将所述分包案件组中案件的多项主体设置为多个实体,将所述主体间的社交关系设置为关系,根据所述实体和所述关系,建立社区网络结构;将所述社区网络结构划分为多个社区网络,计算所述社区网络中每个实体的风险值,若所述风险值大于预设的风险阈值,则所述实体为风险实体,所述实体所在的社区网络为风险网络;将所述风险网络和所述风险网络中所有实体对应的案件进行展示。本发明分别通过维度筛选、车筛选因子、人伤筛选因子等方式,对大量的理赔案件自动进行筛选分包出共性案件,无需人工筛选;对分包后的共性案件通过社区网络结构进一步筛选定位风险案件供审计抽检,定位风险案件精确且效率高。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。
图1为本发明一个实施例中的基于数据分析的风险案件筛选方法的流程图;
图2为本发明一个实施例中社区网络结构的一种结构图;
图3为本发明一个实施例中步骤s1的流程图;
图4为本发明一个实施例中步骤s2的流程图;
图5为本发明一个实施例中基于数据分析的风险案件筛选装置的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
图1为本发明一个实施例中的基于数据分析的风险案件筛选方法的流程图,如图1所示,一种基于数据分析的风险案件筛选方法,包括以下步骤:
步骤s1,建立社区网络结构:获取分包案件组,将分包案件组中案件的多项主体设置为多个实体,将主体间的社交关系设置为关系,根据实体和关系,建立社区网络结构。
本步骤中根据实体和关系建立的社区网络结构是一种以实体及实体之间的关系来描述的知识图谱,将实体与实体之间通过共同的关系来进行关联,且以图谱形式存储在图数据库中。本步骤的案件中包含有多项主体,可以是主导事故行为或从事理赔服务的主体,比如被保险人、驾驶员、事故车辆、修理厂、理赔人员等,关系包括:车主、事故方、报案来电等,因此实体也包括被保险人、驾驶员、事故车辆、修理厂、理赔人员等,案件中主体间的关系包括:车主、事故方、报案来电等。因此实体间的关系也包括车主、事故方、报案来电等。在建立社区网络结构时,可以将所有的实体采用编号的方式进行标示,关系采用颜色的方式进行标示,具有相同关系的实体之间采用虚线连接,得到如图2所示的社区网络结构。
在一个实施例中,步骤s1在建立社区网络结构前,如图3所示,包括:
步骤s101,按维度数据筛选案件:接收专业审计请求,展示维度筛选界面,通过维度筛选界面获取用户选择的维度数据,根据维度数据在预设的案件数据库中筛选出符合维度数据的案件,将所有筛选出的案件为一组分包案件组进行存储。
本步骤中的维度数据可以包括案件号、同一修理厂、同一出险车、同一查勘员、同一定损员、批次号、同一车物查勘员、同一人伤查勘员、同一车物定损员、同一人伤定损员、同一ifd网络、同一审计人员等。通过维度筛选界面获取上述用于筛选的维度数据,得到一组符合维度数据的分包案件组。
步骤s102,按车筛选因子筛选:接收案件筛选请求,展示案件筛选界面,案件筛选界面包括车筛选选项和人伤筛选选项;若接收到用户触发车筛选选项,则展示车筛选界面,通过车筛选界面获取车筛选选项及车筛选因子字段,根据车筛选选项及车筛选因子字段对分包案件组内的案件进行筛选,得到筛选后的一组分包案件组。
通过步骤s101筛选案件后,可能存在一组分包案件组内的案件数量依然非常巨大的情况,因此本步骤还对一组分包案件组内的案件再次进行筛选。本步骤的车筛选选项包括报案人、出险时间、出险地点、报案驾驶员、事故类型、损失类型、车牌号、勘探员、赔付险种、定损员、修理厂名称、车龄、油漆幅数、车组名称、报案来电、车架号、被保险人、车主、审阅结论记录、定损金额、修理厂类型、报价人和指导人等。车筛选因子字段为车筛选选项对应的输入字段。
步骤s103,按人伤筛选因子筛选:若接收到用户触发人伤筛选选项,则展示人伤筛选界面,通过人伤筛选界面获取人伤筛选选项及人伤筛选因子字段,根据人伤筛选选项及人伤筛选因子字段对分包案件组内的案件进行筛选,得到筛选后的一组分包案件组。
本步骤的人伤筛选选项包括报案人、出险时间、出险地点、报案驾驶员、事故类型、损失类型、伤者姓名、伤者电话、伤者联系人电话、伤者身份证号码、伤者工作单位、责任系数、是否协议调解、人伤赔付金额、治疗情况、报案来电、车架号、一审律所名称、二审律所名称、被保险人、车主、伤者年龄范围、临床诊断、评残条款、鉴定机构、医院名称、鉴定人、经办交警队、伤者代理人或律师姓名、代理人或律师分类、一审法院、二审法院和审阅结论记录等。人伤筛选因子字段为人伤筛选选项对应的输入字段。
本实施例通过不同维度将大量的理赔案件自动进行分类到多组分包案件组中,并将分类后的分包案件组再次通过车、物、人等多因子再次筛选出审计需求的分包案件组,本实施例自动筛选出共性案件,无需人工筛选,筛选效率高。
步骤s2,筛选风险网络:将社区网络结构划分为多个社区网络,计算社区网络中每个实体的风险值,若风险值大于预设的风险阈值,则实体为风险实体,实体所在的社区网络为风险网络。
本步骤在计算风险值时,是对多个社区网络分包计算风险值,任一社区网络中的任一实体的风险值大于预设的风险阈值,则将此实体定义为风险实体,将与此实体所在的社区网络作为风险网络。在计算风险值前,还可以先对社区网络中节点的个数进行判断,若社区网络中节点的总个数不大于预设的个数阈值,则认为此社区网络不存在风险网络的嫌疑,继续对其他社区网络进行判断和计算风险值。若任一社区网络中节点的总个数大于预设的个数阈值,则认为此社区网络存在风险网络的嫌疑,再对此社区网络中的每个实体计算风险值。
在一个实施例中,步骤s2中,将社区网络结构划分为多个社区网络,如图4所示,包括:
步骤s201,定义节点:将社区网络结构中每个实体设为一个节点,将每个节点均设为一个独立的社区。
本步骤通过上述定义后,此时社区网络结构中,社区的数目与节点的个数相同。
步骤s202,挖掘社区:对第i个节点分配到其每个邻居节点所在的社区,计算分配前与分配后的模块度变化δq,并记录δq最大的邻居节点,如果最大的模块度变化maxδq>0,则把节点i分配δq最大的邻居节点所在的社区,否则保持不变,重复本步骤,直到所有节点的所属社区不再变化。
本步骤中先计算分配前的模块度q和分配后的模块度q,再计算模块度变化δq,模块度变化δq为:
δq=|qi-qij|
其中,qi为第i个节点分配到第j个邻居节点前的模块度q的值,qij为第i个节点分配到第j个邻居节点后的模块度q的值。
模块度q是评估一个社区网络划分好坏的度量方法,其物理含义是社区内节点的连边数与随机情况下的边数之差,取值范围是[-1/2,1)。模块度q的计算公式如下:
其中,aij表示节点i和节点j之间边的权重,当两个节点直接相连时,aij=1,否则aij=0;ki=∑jaij表示所有与节点i相连的边的权重之和;ci表示节点i所属的社区;
公式中
其中,∑in表示社区c内的边的权重之和,∑tot表示与社区c内的节点相连的边的权重之和。
步骤s203,划分社区:将所有在同一个社区的节点设为一个节点集,不同社区间的边权重设为节点集之间的边权重,重复上一步,直到节点集的所属社区不再变化,将每个社区及其中的节点集确认为一个社区网络,每个社区网络中含有一个或多个节点集。
本步骤将在同一社区的节点进行压缩成一个节点集,社区内节点之间的边的权重转化为节点集的环的权重,社区间的边的权重转化为节点集之间边的权重,将每个节点集均定义为一个独立的社区,重复步骤s202,挖掘社区,直到整个社区网络结构的模块度不再发生变化。
本实施例通过基于模块度的社区网络划分方法,能产生层次性的社区网络,挖掘和划分社区计算速度快,划分出的社区网络较为理想。
在一个实施例中,步骤s2中,计算社区网络中每个实体的风险值,包括:
分别对社区网络中每个实体计算集中度,其中,实体为社区网络中的节点,实体的集中度即为实体的风险值;
集中度的计算公式如下:
其中,ci为社区网络中第i个节点的集中度,n为社区网络中节点的个数,j为除第i个节点外的其他节点,d(i,j)为从第i个节点出发到第j个节点的最短路径长度。
本实施例中将社区网络的实体作为节点,将实体与其他实体之间的关系作为边,计算每个节点的集中度,此集中度即为风险阈值。如图2所示的社区网络结构中,a、b、c节点,则a的集中度为
本实施例通过计算集中度来确定风险值,能很好的表达一个社区网络中实体的紧密程度,紧密程度高的实体具有较高的风险嫌疑。因此通过上述计算方式可以从大量理赔案件中,快速高效的确定风险网络及风险案件。
步骤s3,展示案件:将风险网络和风险网络中所有实体对应的案件进行展示。
本步骤在进行展示前,将社区网络结构中的实体与案件进行关联后展示,若审计人员单击任一实体,则触发关联关系,展示被触发的实体对应的案件,供审计人员查看。
本步骤在进行展示时,将风险网络通过图谱的形式进行展示,将风险网络中的所有实体对应的所有案件通过表格的形式进行展示,对风险网络中大于风险阈值的实体及对应的案件进行突出标注。比如显示颜色为红色,供审计人员定位最终的风险案件及共性案件。
本实施例基于数据分析的风险案件筛选方法,将大量理赔案件可以根据不同的风险场景和审计需求,通过不同维度进行分类得到多组分包案件组,无需人工筛选,分类速度快,分类效率高。对单个分包案件组通过社区网络结构的划分及风险值的计算,筛选及定位风险案件供审计,定位风险案件精确且效率高,整个筛选过程,无需人工逐个筛选案件,聚焦高风险网络及案件进行展示,从而发现和打击车险欺诈问题。
在一个实施例中,提出了一种基于数据分析的风险案件筛选装置,如图5所示,包括如下模块:
建立社区网络结构模块,用于获取分包案件组,将分包案件组中案件的多项主体设置为多个实体,将主体间的社交关系设置为关系,根据实体和关系,建立社区网络结构;
筛选风险网络模块,用于将社区网络结构划分为多个社区网络,计算社区网络中每个实体的风险值,若风险值大于预设的风险阈值,则实体为风险实体,实体所在的社区网络为风险网络;
展示模块,用于将风险网络和风险网络中所有实体对应的案件进行展示。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行计算机可读指令时实现上述各实施例的基于数据分析的风险案件筛选方法中的步骤。
在一个实施例中,提出了一种存储有计算机可读指令的存储介质,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例的基于数据分析的风险案件筛选方法中的步骤。其中,存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明一些示例性实施例,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!