一种实时的语义视频分割方法与流程
本发明属于计算机视觉领域,特别地涉及一种实时的语义视频分割方法。
背景技术:
语义视频分割,是将视频每一帧的每一个像素指定一个语义类别的计算机视觉任务。实时的语义视频分割,则对分割的速度提出一定的要求,一般是24帧每秒以上。当前先进的语义视频分割方法都是基于卷积神经网络(cnn)的机器学习方法,它们大体上又可以分为基于连续图像帧和直接基于视频的两类。第一类方法将视频看成图像帧的序列,它们通过缩小输入数据的尺度或者裁剪网络的方式,牺牲一点分割准确率换取实时的语义分割性能。这类方法没有挖掘视频所蕴含的帧间连贯性。第二类方法在视频上通过光流、3dcnn、rnn等技术提取帧间连贯特征,但是这些技术本身比较耗时,它们本身会成为语义视频分割的瓶颈。
实际上,现有的压缩视频本身就已经包含了帧间连贯信息,即运动向量(mv)和残差信息(res)。这个信息的获取是非常快速的,利用它们可以大大加快语义视频分割的速度。然而,压缩视频提供的帧间连贯信息与光流等技术相比噪声较大,如何利用压缩信息的同时,又保证分割准确,就成了本方法解决的关键问题。
技术实现要素:
为解决上述问题,本发明的目的在于提供一种实时的语义视频分割方法。该方法基于深度神经网络,以图像语义分割模型为基础,进一步利用了视频中相邻图片帧之间的强相关性,利用视频压缩域中的多模态运动信息进行快速推断,从而实现实时的语义视频分割效果。
为实现上述目的,本发明的技术方案为:
一种实时的语义视频分割方法,其包括以下步骤:
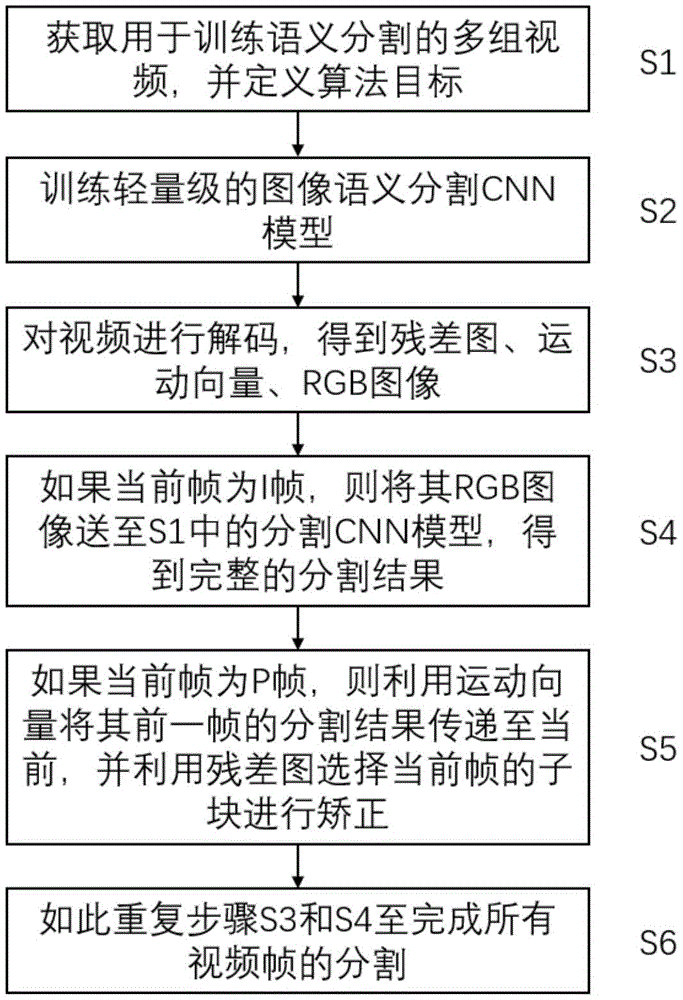
s1.获取用于训练语义分割的多组视频,并定义算法目标;
s2.训练轻量级的图像语义分割cnn模型;
s3.对视频进行解码,得到残差图、运动向量、rgb图像;
s4.对于视频中的当前帧,如果当前帧为i帧,则将其rgb图像送至s2中经过训练后的图像语义分割cnn模型,得到完整的分割结果;
s5.对于视频中的当前帧,如果当前帧为p帧,则利用运动向量将其前一帧的分割结果传递至当前,并利用残差图选择当前帧的子块进行矫正;
s6.针对视频中的所有帧重复步骤s3和s4,至完成所有视频帧的分割。
进一步的,步骤s1中,对于所述的用于视频语义分割的每一个视频v,定义算法目标为:检测视频v中每一帧图像的所有像素的分类。
进一步的,步骤s2中,训练轻量级的图像语义分割cnn模型具体包括:
s21.利用单张图片的卷积神经网络φ对图像中每一个像素进行分类提取,经其处理后的图像i的分类预测结果为φ(i);
s22.根据预测和给定的分类标签计算交叉熵损失,来优化网络φ中参数。
进一步的,步骤s3中,使用mpeg-4视频编解码标准对视频进行编解码,设定图片组gop参数g、b帧比率β;当前帧时刻为t,则解码过程如下:
s31.若当前第t帧为i帧,则直接解码得到其rgb图像i(t);
s32.若当前第t帧为p帧,则首先部分解码得到其运动向量mv(t)与残差向量res(t),再依据像素域的平移及补偿变换进一步解码得到rgb图像i(t)。
进一步的,步骤s4中,如果当前第t帧为i帧,则按照如下算法对其进行语义分割:
s41.将当前rgb图像i(t)送入s2中训练完毕的图像语义分割cnn模型进行预测,得到其语义分割结果f(t)=φ(i(t))。
进一步的,步骤s5中,如果当前第t帧为p帧,则按照如下算法对其进行语义分割:
s51.使用当前帧的运动向量mv(t)对前一帧的分割结果f(t-1)进行像素域的平移,得到当前帧的分割结果:
f(t)[p]=f(t-1)[p-mv(t)[p]]
其中:f(t)[p]表示经过平移后得到当前第t帧的分割结果f(t)中像素位置p处的值;p为像素坐标;mv(t)[p]指当前第t帧的运动向量图mv(t)中像素位置p处的值;
s52.利用当前帧的残差图res(t),从当前帧的所有子区域ri中选出残差值大于阈值的像素点最多的子区域,作为待重分割子区域r(t):
其中ri表示第i个候选子区域;res(t)[p]表示残差图res(t)中像素位置p处的残差值;thr是人为设定的阈值;indicator表示指示函数,若|res(t)[p]|>thr成立则其值为1,否则为0;
s53.对s52中得到r(t)子区域送入s2中训练完毕的图像语义分割cnn模型进行重分割,得到该子区域新的语义分割结果fr(t):
fr(t)=φ(i(t)[r(t)])
其中i(t)[r(t)]表示r(t)子区域的rgb图像;
s54.根据s53得到的子区域分割结果更新当前帧中r(t)子区域的分割结果:
f(t)[r(t)]=fr(t)
其中f(t)[r(t)]表示当前第t帧中r(t)子区域的分割结果。
基于s5步骤的非关键帧分割算法效率比逐帧通过cnn进行分割处理的方法高很多,通过避免对相似图像进行冗余的特征提取,方法对p帧的处理速度比逐帧处理高数十倍。
本发明充分利用了视频中相邻帧的相关性,基于压缩域信息的加速处理能够在快速完成复杂分割任务的同时保持较高的准确率,效率比常见分割方法提高十数倍。
附图说明
图1为本发明的的流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
如图1所示,一种实时的语义视频分割方法,该方法的步骤如下:
s1.获取用于训练语义分割的多组视频,并定义算法目标。在本步骤中,对于用于视频语义分割的每一个视频v,定义算法目标为:检测视频v中每一帧图像的所有像素的分类。
s2.训练轻量级的图像语义分割cnn模型。在本步骤中,训练轻量级的图像语义分割cnn模型具体包括:
s21.利用单张图片的卷积神经网络φ对图像中每一个像素进行分类提取,经其处理后的图像i的分类预测结果为φ(i);
s22.根据预测和给定的分类标签计算交叉熵损失,来优化网络φ中参数。
s3.对视频进行解码,得到残差图、运动向量、rgb图像。本步骤中,使用mpeg-4视频编解码标准对视频进行编解码,设定图片组gop参数g、b帧比率β;当前帧时刻为t,则解码过程需要区分当前帧为i帧还是p帧,各自的解码过程如下:
s31.若当前第t帧为i帧,则直接解码得到其rgb图像i(t);
s32.若当前第t帧为p帧,则首先部分解码得到其运动向量mv(t)与残差向量res(t),再依据像素域的平移及补偿变换进一步解码得到rgb图像i(t)。
s4.对于视频中的当前帧,如果当前帧为i帧,则将其rgb图像送至s2中经过训练后的图像语义分割cnn模型,得到完整的分割结果。
本步骤中,如果当前第t帧为i帧,则按照如下算法对其进行语义分割:
s41.将当前rgb图像i(t)送入s2中训练完毕的图像语义分割cnn模型进行预测,得到其语义分割结果f(t)=φ(i(t))。
s5.对于视频中的当前帧,如果当前帧为p帧,则利用运动向量将其前一帧的分割结果传递至当前,并利用残差图选择当前帧的子块进行矫正。
本步骤中,如果当前第t帧为p帧,则按照如下算法对其进行语义分割:
s51.使用当前帧的运动向量mv(t)对前一帧的分割结果f(t-1)进行像素域的平移,得到当前帧的分割结果:
f(t)[p]=f(t-1)[p-mv(t)[p]]
其中:f(t)[p]表示经过平移后得到当前第t帧的分割结果f(t)中像素位置p处的值;p为像素坐标;mv(t)[p]指当前第t帧的运动向量图mv(t)中像素位置p处的值;
s52.当前帧图像可以通过网格化处理,对图片的长和宽分别等分,形成若干子块,即子区域。利用当前帧的残差图res(t),从当前帧的所有子区域ri中选出残差值大于阈值的像素点最多的子区域,作为待重分割子区域r(t):
其中ri表示第i个候选子区域;res(t)[p]表示残差图res(t)中像素位置p处的残差值;thr是人为设定的阈值;indicator表示指示函数,若|res(t)[p]|>thr成立则其值为1,否则为0;
s53.对s52中得到r(t)子区域,我们认为其相较前一帧变化较大,且难以通过运动向量描述这种变化,因此对其进行重分割。因此将该子区域的rgb图像送入s2中训练完毕的图像语义分割cnn模型进行重分割,得到该子区域新的语义分割结果fr(t):
fr(t)=φ(i(t)[r(t)])
其中i(t)[r(t)]表示r(t)子区域的rgb图像;
s54.根据s53得到的子区域分割结果更新当前帧中r(t)子区域的分割结果:
f(t)[r(t)]=fr(t)
其中f(t)[r(t)]表示当前第t帧中r(t)子区域的分割结果。除了r(t)子区域之外,其余的子区域分割结果保持不变。
基于上述步骤的非关键帧分割算法效率比逐帧通过cnn进行分割处理的方法高很多,通过避免对相似图像进行冗余的特征提取,方法对p帧的处理速度比逐帧处理高数十倍。
s6.针对视频中的所有帧重复步骤s3和s4,直至视频流处理结束即可完成对所有视频帧的语义分割。
上述实施例中,本发明的语义视频分割方法首先训练了一个静态图片的语义分割的卷积神经网络模型,在此基础上,利用视频前后帧之间的强相关性,充分探索了视频压缩域的运动信息,把特征提取及分类问题转化为相邻视频帧之间的像素移动问题,并基于压缩模型的原理对可能产生较大错误的子区域进行了精细分割,在达到高模型运行速度的同时维持了较高的准确率。
本方法具有非常强的泛化能力,其框架可以被应用于其他更多视频的像素域识别任务中,包括视频目标检测、视频实例分割、视频全景分割等。且该模型的速度不依赖于具体的cnn网络结构,对于高精度模型和轻量级模型均有数倍至数十倍的速度提升。
实施例
下面基于上述方法进行仿真实验,本实施例的实现方法如前所述,不再详细阐述具体的步骤,下面仅展示实验结果。
本实施例使用icnet作为轻量级图像语义分割cnn模型。并在语义分割公开数据集cityscapes上实施多次实验,其包含5000段视频短片段,证明了本方法可以明显地提升语义视频分割的效率,并保证准确性。算法中,设定图片组gop参数g为12、b帧比率β设置为0。
将本发明的方法与传统逐帧通过cnn进行分割处理的方法进行了对比,从算法流程可见其区别主要在是否进行s3~s5的压缩域操作。两种方法的实施效果如表1所示。
表1本发明在cityscapes数据集上的实施效果
由此可见,通过以上技术方案,本发明实施例基于深度学习技术发展了一种实时的语义视频分割方法。本发明可以充分利用视频压缩域中的运动信息,对视频中相邻帧的相关关系进行建模,进而将这种相关性用于减少冗余计算、从而大幅度加快视频语义分割的模型速度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!