一种基于LSTM模型的电动阀门故障检测方法与流程
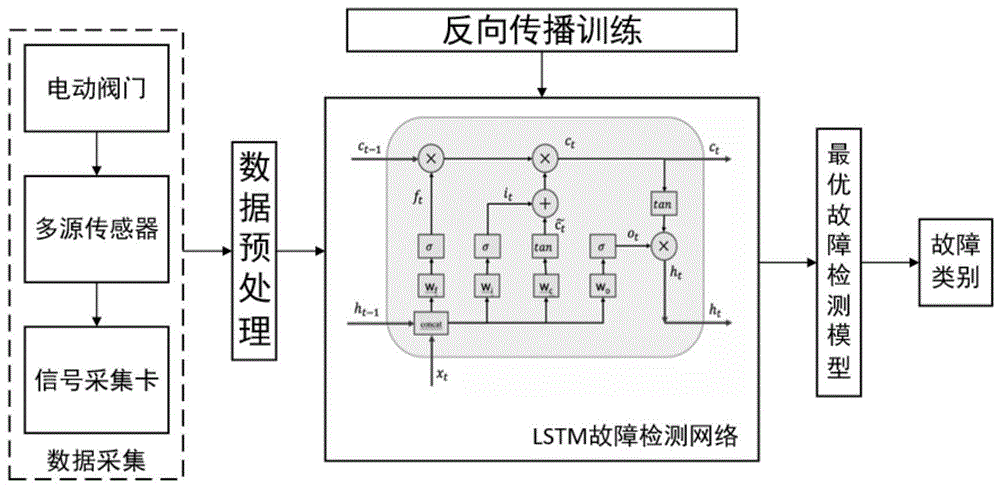
本发明涉及电动阀门技术领域,尤其涉及到一种基于lstm模型的电动阀门故障检测方法。
背景技术:
在大多数工业领域,阀门是必不可少的元件之一。现今,电动阀门由于其具有力矩大、能够用在高温高压的介质控制中的优点,在化工、石油、天然气等行业受到广泛青睐。然而在真实工业环境里,有相当一部分的阀门因长期使用、磨损、腐蚀或其他原因会出现内外渗漏或泄漏故障。若不及时发现和处理,将会导致介质泄漏、环境污染甚至造成起火爆炸等灾难性的事故发生。传统的阀门故障诊断机理,是以检修工人以一定周期地去巡检与查验,这种方法费时费力,而且庞大的工业系统中阀门的使用数量是数以百计甚至是数以千计的。随着工业技术的不断发展,经常拆卸阀门的诊断方法已经远远不能适应要求,故障检测效果往往不够理想,并且增加了维修成本和检修周期。基于数据驱动的方法是解决电动阀门故障检测问题的一种主流方法,这得益于深度学习理论惊人的非线性拟合能力和出色的抽象挖掘能力。循环神经网络(rnn)将时序的概念引入到网络结构设计中,隐藏层之间的互连结构反映出时间序列之间的相互影响关系,但是rnn存在着梯度消失、梯度爆炸和长期记忆能力不足等问题。长短期记忆(lstm)模型是rnn的一种变体,它通过在网络中加入细胞结构(cell)弥补rnn的不足,从而对时序数据具有更强地适用性,能够抓住长远的上下文信息。
技术实现要素:
针对上述技术问题,本发明的目的在于提供一种基于lstm模型的电动阀门故障检测方法,能依靠可观测的数据解析并得出故障类别,突破仅能在单一时刻观测得出故障的限制,抓住传感器检测数据的上下文信息,降低故障误检率,显著提高阀门的智能化水平,使得精确实时地检测出电动阀门是否处于故障状态并得出故障类别。
为实现上述目的,本发明是根据以下技术方案实现的:
一种基于lstm模型的电动阀门故障检测方法,包括如下步骤:
步骤s1:实时检测阀门工作时的特征数据,并通过8通道高精度vga信号采集卡将特征数据采集到故障诊断处理器中;
步骤s2:设定动态时窗,提取等长的时序数据作为数据集的样本,制作诊断数据训练集;
步骤s3:建立lstm故障检测网络模型,并根据建立的电动阀门lstm故障检测模型采取反向传播算法进行训练;
步骤s4:电动阀门故障实时检测,并将输出向量元素最大值对应的故障类别作为电动阀门的故障检测结果并将故障检测结果显示在液晶显示屏上,如果检测出某一电动阀门有故障,同时触发蜂鸣警报器和故障信号灯以示监控人员提醒。
上述技术方案中,所述特征参数包括电机电流i、电压u、工作功率p、输出扭矩t、线圈温度γ、行程百分比α、振动加速度a、声压τ。
上述技术方案中,所述特征数据行归一化处理,采用的归一化处理方式为最大最小归一化方法,使得所有的输入向量元素取值都在0-1之间,计算公式为
上述技术方案中,步骤s2中将电动阀门的故障类别分为正常、早期故障、磨损故障和卡阀故障四个类别,定义数据集格式为[data,label],其中data为某种电动阀门运行状态下的采集数据,label为人工标注的该种data所属的故障类别,样本数据采用“one-hot”方式编码,其中[1,0,0,0]对应正常状态,[0,1,0,0]对应早期故障状态,[0,0,1,0]对应磨损故障状态,[0,0,0,1]对应卡阀故障状态。
上述技术方案中,所述lstm故障检测模型的神经元细胞中每个时刻不同门的更新公式如下:
遗忘门:ft=sigmoid(wf*[ht-1,xt]+bf);
输入门:it=sigmoid(wi*[ht-1,xt]+bi);
输入的候选状态:
记忆细胞的输出:ct=ft*ct-1+it*ct%;
输出门:ot=sigmoid(wo*[ht-1,xt]+bo);
单元输出:ht=ot*tanh(ct);
其中,wi、wf、wo、wc分别为输入门、遗忘门、输出门以及细胞状态的权值矩阵;bi、bf、bo、bc为对应的偏置项;ht-1为t-1时刻的隐藏层状态;xt为t时刻的输入向量;tanh为双曲正切激活函数,将最后一个时刻的单元输出值作为lstm网络的输出值。
上述技术方案中,步骤s3的训练过程包括如下步骤:
步骤s301:对lstm网络模型随机初始化种子;
步骤s302:选取每批训练大小t为50,即每个epoch选取50个样本;弃权系数选取0.2;
步骤s303:损失函数选取分类交叉熵函数作为误差计算公式:
其中,t为一次训练用故障检测的样本数;
步骤304:选取学习率为0.2,选取隐藏层特征维度为28,选取整体样本迭代次数epoch设为100,以最小化损失函数为目标,计算误差函数对权值矩阵的梯度,并应用adam优化算法不断迭代更新网络中各门的权值矩阵,进而得到最优的电动阀门lstm故障检测网络模型。
本发明与现有技术相比,具有如下优点:
本发明的电动阀门故障实时诊断方法提高了电动阀门的智能化水平,减免了人工检测的大量工作,实时性高能够满足工业要求。
本发明不仅能检测出阀门是否有故障,还能得出在存在故障时给出故障类型,方便了后期的维修与整改,实用性高;
本发明所建立的电动阀门故障检测lstm网络,能依靠可观测的数据解析并得出故障类别,突破仅能在单一时刻观测得出故障的限制,抓住传感器检测数据的上下文信息,降低故障误检率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明实施例的基于lstm模型的电动阀门故障检测方法整体框架示意图;
图2为电动阀门故障检测lstm网络训练检测正确率变化示意图;
图3为电动阀门故障检测lstm网络loss变化示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
如图1所示,本发明的一种基于lstm模型的电动阀门故障检测方法,包括如下步骤:
步骤s1:实时检测阀门工作时的特征数据,并通过8通道高精度vga信号采集卡将特征数据采集到故障诊断处理器中,其中采集步长为0.2s。
其中,特征参数包括电机电流i、电压u、工作功率p、输出扭矩t、线圈温度γ、行程百分比α、振动加速度a、声压τ。
在对电动阀门故障检测模型进行训练之前,由于各传感器采集的特征数据在数值上差异性大,故需要进行归一化处理。所述特征数据行归一化处理,采用的归一化处理方式为最大最小归一化方法,使得所有的输入向量元素取值都在0-1之间,计算公式为
步骤s2:设定动态时窗,提取等长的时序数据作为数据集的样本,制作诊断数据训练集;由于传感器采集数据是动态的过程,以动态时窗的方法,提取等长的时序数据作为数据集的样本,每组样本序列长度为20,则动态时窗为4s。根据本发明的一个具体实施例,本发明采集1000组数据,将电动阀门的故障类别分为正常、早期故障、磨损故障和卡阀故障四个类别,每个类别各250组,定义数据集格式为[data,label],其中其中data为某种电动阀门运行状态下的采集数据,data为一个20*8的数组,其中20对应采集的特征序列长度为20时步,8对应有8个采集的电动阀门输入特征,形式为x=(x1,x2,l,x8);label为人工标注的该种data所属的故障类别,样本数据采用“one-hot”方式编码,其中[1,0,0,0]对应正常状态,[0,1,0,0]对应早期故障状态,[0,0,1,0]对应磨损故障状态,[0,0,0,1]对应卡阀故障状态,如下表1所示。
表1
步骤s3:建立lstm故障检测网络模型,并根据建立的电动阀门lstm故障检测模型采取反向传播算法进行训练;
所述的lstm模型由四个部分组成,分别为输入门(决定让多少新信息加入到细胞状态中),遗忘门(决定从细胞状态中丢弃什么信息)、输出门(决定最终输出什么信息)和细胞状态(在整个循环周期内定义和维护一个内部记忆单元状态),所述lstm故障检测模型的神经元细胞中每个时刻不同门的更新公式如下:
遗忘门:ft=sigmoid(wf*[ht-1,xt]+bf);
输入门:it=sigmoid(wi*[ht-1,xt]+bi);
输入的候选状态:
记忆细胞的输出:ct=ft*ct-1+it*ct%;
输出门:ot=sigmoid(wo*[ht-1,xt]+bo);
单元输出:ht=ot*tanh(ct);
其中,wi、wf、wo、wc分别为输入门、遗忘门、输出门以及细胞状态的权值矩阵;bi、bf、bo、bc为对应的偏置项;ht-1为t-1时刻的隐藏层状态;xt为t时刻的输入向量;tanh为双曲正切激活函数,由于电动阀门故障检测属于nvs1分类问题,则将电动阀门lstm故障检测模型的最后一个时刻单元输出值h20(由于序列长度为20)作为lstm网络的输出值y=(y1,y2,y3,y4)。
训练过程包括如下步骤:
步骤s301:对lstm网络模型随机初始化种子;
步骤s302:选取每批训练大小t为50,即每个epoch选取50个样本;弃权系数选取0.2;
步骤s303:损失函数选取分类交叉熵函数作为误差计算公式:
其中,t为一次训练用故障检测的样本数;
步骤304:选取学习率为0.2,选取隐藏层特征维度为28,选取整体样本迭代次数epoch设为100,以最小化损失函数为目标,计算误差函数对权值矩阵的梯度,并应用adam优化算法不断迭代更新网络中各门的权值矩阵,进而得到最优的电动阀门lstm故障检测网络模型。
步骤s4:电动阀门故障实时检测,并将输出向量元素最大值对应的故障类别作为电动阀门的故障检测结果并将故障检测结果显示在液晶显示屏上,如果检测出某一电动阀门有故障,同时触发蜂鸣警报器和故障信号灯以示监控人员提醒。
具体地,根据之前设定,本发明以20个时步为动态时窗提取时序数据,经过数据归一化后,获得输入向量
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!