基于深度学习的地表水质预测方法与流程
本发明涉及的是一种神经网络应用领域的技术,具体是一种基于深度学习的地表水质预测方法。
背景技术:
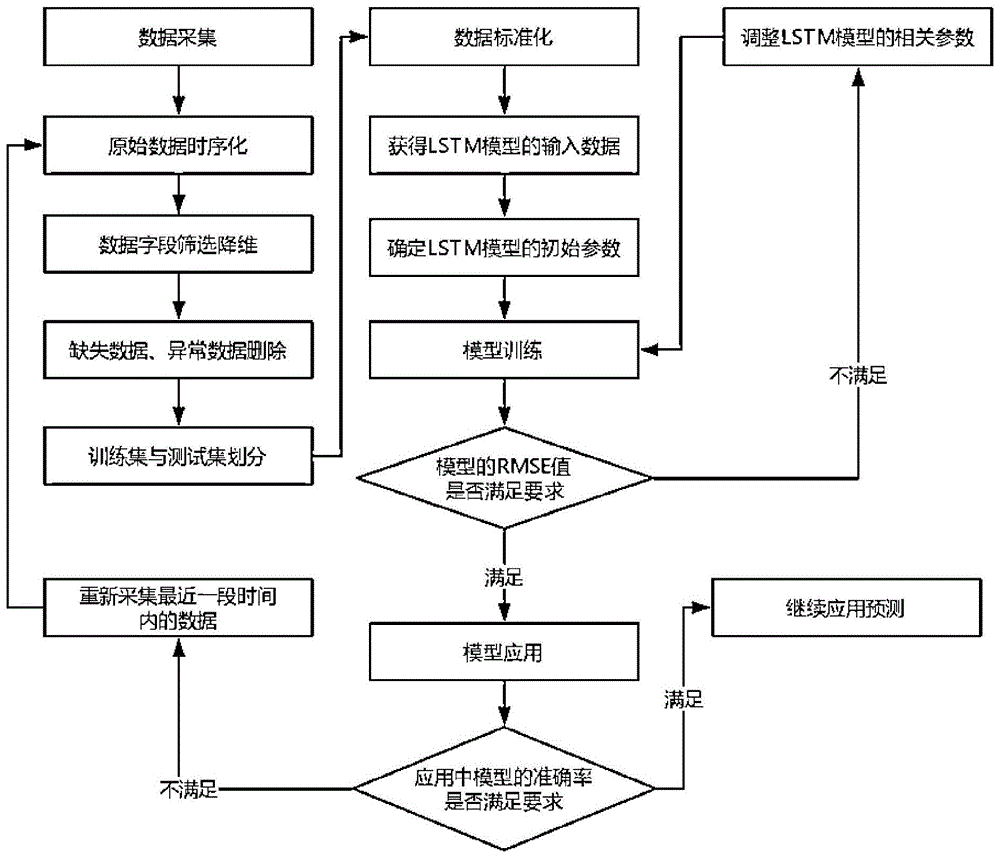
:现有的水质预测方法主要是基于传统的机器学习理论,例如灰色预测方法,回归分析方法等。这类方法的问题在于,一方面,它们往往只考虑单个水质指标数据,将水质相关的数据割裂开来,另一方面,它们对于水质数据在时间序列上的依赖性和关联性处理还不够完善,因此预测精度普遍不高。实际上,水质情况的关联因子很多,不仅受到自身历史值的影响,甚至不同的水质指标数值之间也会互相影响,为了达到较为准确的预测效果,这些因素都需要综合考虑进去。技术实现要素:本发明针对现有技术存在的上述不足,提出一种基于深度学习的地表水质预测方法,利用深度学习中的lstm神经网络模型在处理复杂多因子输入方面的优势,及其对数据历史依赖关系的良好记忆性,来对水质时间序列数据进行预测。将水质相关的多个因子作为输入,经过模型训练后,再分别输出各个因子的预测值,这样不仅可以考虑到每个因子各自的历史值的影响,还能够综合考虑到各个因子之间的互相影响。本发明是通过以下技术方案实现的:本发明通过采集数据,并进行预处理,制成训练样本后用于训练神经网络模型,当模型经过调优准确率达标之后,再将实时水质监测数据输入训练后的神经网络,得到未来一段时间内的地表水质预测数据。所述的采集数据是指:水质相关的数据主要通过地表水质监测站采集而来,每隔4小时采集一次。其中包括水温、ph值、浊度、电导率、总磷、溶解氧、氨氮、高锰酸盐、化学需氧量、汞、铅、铬等水质参数的监测值,对应的监测值以文件的形式记录或者实时传输存储到对应的数据库中,再进行解析处理。所述的训练样本,通过对采集到的数据进行时序化、降维处理、异常数据剔除和标准化处理后得到。所述的时序化是指:将数据按照时间顺序进行排列所述的降维处理是指:筛选出需要考虑的水质参数指标字段,该水质参数指标字段包括:水温、ph值、电导率、总磷、溶解氧、氨氮、高锰酸盐、化学需氧量。所述的异常数据剔除是指:将无用数据和缺失数据删除,通过人为设定每个水质监测指标的阈值,筛选出原始数据中的异常值,异常值对应的原始数据样本作为异常样本删除。所述的标准化处理是指:将原始样本数据分为训练集和测试集两部分,70%作为训练集,30%作为测试集,对所有数据进行标准化,采用最大最小标准化进行处理:其中:xmax和xmin分别为同一水质监测指标数据的最大值和最小值,x为原始数据,x’为标准化后的数据。所述的训练是指:基于lstm长短期记忆神经网络进行训练,构建多因子的水质预测模型,将水质参数指标字段作为输入参数,同时将水质参数指标字段作为输出参数,不断地对lstm网络参数进行尝试,该lstm网络参数包括:对时间序列数据的划分步长time_step、批量大小batch_size、学习率learningrate、激活函数activation、网络的隐藏层数量k等。优选地,所述的训练采用adam算法对训练过程进行优化,基于训练数据迭代地更新lstm网络的权重,直到模型收敛。优选地,所述的训练采用均方根误差rmse指标来对训练好的模型性能进行评估,其含义是指模型在测试集上的预测值与真实值的差平方的期望值的平方根,即:其中:n为数据的个数,xi为真实值,pi为预测值,rmse值越小,为模型的预测值与真实值越接近,模型的精度就越高,性能就越好。所述的地表水质预测数据,通过将实际预测场景中前一个月的监测数据值输入训练好的模型,得到接下来一周的各个水质指标的值,并将预测值进行反标准化得到实际值,为管理人员提供辅助决策支持。所述的反标准化具体是指:y′=xmin+y(xmax-xmin),其中:y’为还原后的实际值,y为模型的输出值,xmax和xmin分别为模型输入数据中的最大值和最小值。优选地,不断将地表水质预测数据与地表水质真实值进行对比,计算对应的误差率,并在误差超过设定的阈值时结合最近的历史数据,重新进行模型的训练以保证预测的准确度。本发明涉及一种实现上述方法的系统,包括:数据采集模块、数据预处理模块、训练样本生成模块、网络训练模块、网络更新模块以及识别预测模块。其中:数据采集模块与数据预处理模块相连并传输采集到的各类原始水质参数信息,数据预处理模块与训练样本生成模块相连并传输经过初步筛选处理后的样本数据,训练样本生成模块与网络训练模块相连并传输网络模型的输入参数信息,网络更新模块与网络训练模块相连并传输最近一段时间内的历史水质监测数据以便更新模型的训练数据,识别预测模块与网络更新模块相连并传输最新的实时水质监测数据以便判断模型的预测准确率。技术效果与现有技术相比,本发明在时间和空间维度上综合利用了水质监测相关数据,相比现有技术的单一预测模型,准确率更高,并且能够根据最新的实时数据及对应预测数据的差距,不断动态更新优化预测模型。附图说明图1为本发明流程图;图2为实施例效果示意图。具体实施方式如图1所示,为本实施例涉及一种基于深度学习进行地表水质预测方法,包括以下步骤:步骤一:收集黄冈市水质自动监测站提供的相关水质监测原始数据,原始数据每间隔4小时采集一次,包含2010年至2016年的所有数据。步骤二:原始数据的存储形式多样,有些是pdf格式,有些是doc格式,有些存储在数据库中,将各种形式的原始数据通过不同方式抽取出来,按照时间顺序进行排列。步骤三:对时序化后的数据进行降维,选定其中的某个监测站,对相关数据进行筛选,留下水温、ph值、电导率、总磷、溶解氧、氨氮、高锰酸盐、化学需氧量等8个指标字段。步骤四:将存在缺失数据的样本剔除,异常数据使用同一站点前后两次监测的平均值代替,处理后得到如下数据:datephdocodnh3-n…2010-138.796.643.20.06…2010-148.86.92.70.03…2010-158.447.332.50.04…2010-167.767.392.10.04…2010-178.328.81.90.04..步骤五:采用如下公式对数据进行标准化:其中:xmax和xmin分别为同一水质监测指标数据的最大值和最小值,x为原始数据,x’为标准化后的数据。将量纲及量级均不相同的各个指标字段的原始数据按比例缩小到0和1之间,提升各个指标字段之间的可比性,提高模型训练的准确度。步骤六:采用留出法,按照7:3的比例对处理后的全部样本数据进行划分,70%作为训练集,剩下的30%作为测试集。步骤七:进行lstm神经网络模型训练。lstm模型的初始参数设定如下:时间步长time_step为2,批量大小batch_size为30,学习率learningrate为0.001,激活函数activation使用relu函数,网络的隐藏层数量k为20,每次训练轮次为260,采用adam算法对训练过程进行优化,直到网络收敛。步骤八:在训练过程中,采用均方根误差rmse指标来对训练好的模型性能进行评估,其含义是指模型在测试集上的预测值与真实值的差平方的期望值的平方根,即其中:n代表数据的个数,xi代表真实值,pi代表预测值,rmse值越小,代表模型的预测值与真实值越接近,模型的精度就越高,性能就越好。不断调整模型的参数直到最终训练完成的模型的rmse值达到要求为止。步骤九:将模型应用在实际的水质预测场景中。水质监测站实时采集到的水质数据经过数据预处理后,作为模型的输入,将模型的输出经过反标准化后得到下一时刻的水质预测结果。反标准化是指:y′=xmin+y(xmax-xmin),其中:y’是还原后的实际值,y是模型的输出值,xmax和xmin分别是模型输入数据中的最大值和最小值。模型的预测值与实际值的对比如图2所示,除去少数几个异常数据点,图2表明本发明所提出的方法能够达到良好的地表水质预测效果。步骤十:随时观察模型的预测值与实际值的误差,如果误差超过阈值,需要重新采集最近一段时间的历史数据,重复之前的步骤对模型进行更新,保证预测的准确度。上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1