一种基于卷积神经网络的人脸识别提醒系统的制作方法
本发明涉及卷积神经网络和人脸识别技术领域,具体涉及一种基于卷积神经网络的人脸识别提醒系统。
背景技术:
近年来,随着图像处理和机器学习技术的快速发展以及计算机硬件设备的不断更新,基于卷积神经网络的深度学习在计算机视觉以及图像分类、语音识别、自然语言处理等领域的取得显著进展,而这也使得将基于卷积网络的人脸识别技术应用于提醒系统成为可能。同时,这样的设计会将卷积神经网络的鲁棒性、准确性和灵活性等优点带入提醒系统中,使系统在面对复杂的环境时也能稳定地运行。
在近似的技术方案中,现有的提醒系统多采用基于传感器技术的设计方案,例如红外线感应和电磁感应技术等,目前暂无使用卷积神经网络技术与嵌入式提醒系统相结合的方案设计。而在传统的人脸识别技术中,有采用特征值匹配的识别方法,但是这对人脸图像的形变、明暗、遮挡等条件有较高的要求,在抗干扰能力方面比卷积神经网络差,因此传统的人脸识别技术较难设计出一种适用于各种情况下的提醒系统。
另外,现有的提醒系统灵活性较差,无论人员还是进入是出门,或者是其它生物或物体经过,只要满足了触发条件,该系统都会进行提醒,在某些场合容易造成困扰。除此之外,现有的识别提醒系统例如红外线感应提醒系统等都使用电池有源式进行供电,一旦电量耗尽将会导致不可预估的后果。
因此,针对上述传统识别提醒系统的缺陷,为了更好地对人员的行为进行区分以及减少错误触发的情况,提高系统的灵活性和鲁棒性,需要应用新的技术设计提醒系统来解决该问题。
技术实现要素:
本发明的目的是为了解决现有技术方案在鲁棒性和灵活性方面的不足,提出了一种基于卷积神经网络的提醒系统,所述方案将卷积神经网络与嵌入式设备相结合,能够实现对不同背景、特定尺度人脸的快速识别,进而发出提醒语音。
本发明至少通过如下技术方案之一实现。
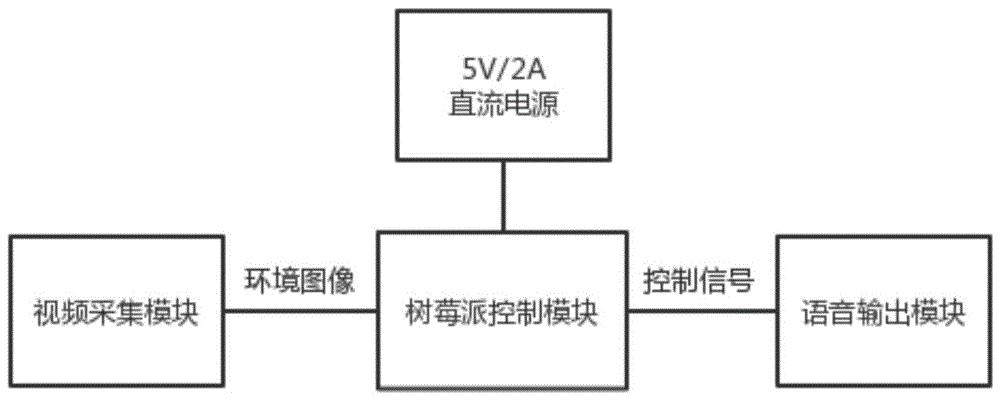
一种基于卷积神经网络的人脸识别提醒系统,该系统包括树莓派控制模块、语音输出模块和视频采集模块;
所述树莓派控制模块通过csi端口与视频采集模块的摄像头相连,摄像头的启动与工作由csi端口控制;
所述树莓派控制模块通过gpio的语音输出控制信号端口和供电端口分别与语音输出模块的控制引脚和供电脚相连。
进一步的,所述视频采集模块包括彩色摄像头,用于实现环境图像数据的采集。
进一步的,所述树莓派控制模块采用raspberrypi3b控制板。
进一步的,所述语音输出模块包括语音芯片sc50x0、喇叭以及若干电容,用于实现提醒语音的播放。
进一步的,所述语音输出模块中的语音芯片通过pwm口与喇叭连接,所述语音芯片的供电脚与接地脚之间接有电容,用于电源滤波。
进一步的,gpio的语音输出控制信号端口pin设置为数据输出模式,并设置为高电平。
进一步的,树莓派控制模块的usbtype-b接口与降压转换器连接,将220v交流电转化为5v/2a直流电,由该直流电对树莓派控制模块进行供电。
与现有的技术相比,本发明产生的技术效果为:
(1)本发明提供的一种基于卷积神经网络的提醒系统,采用卷积神经网络进行人脸识别并进行提醒,其优势是使用大量标注数据进行泛化训练,使模型具备一定程度的识别能力,与传统的基于特征的人脸识别算法相比具备更好的抗噪声、畸变、明暗能力,同时在检测人脸时不受其所在位置的影响,识别的准确性较好。
(2)本发明提供的一种基于卷积神经网络的提醒系统,不需要第三方服务器的支持,在树莓派上就可以完成全部的工作,系统的可移植性高。由于采用了轻量级的深度学习模型,保证了响应时间在一秒以内,同时占用内存未到总量的一半,实时性满足应用的要求。采用外接电源供电的形式,保证了电子器件工作在良好的状态,同时也免除了需要经常换电池的烦恼。
(3)本发明提供的一种基于卷积神经网络的提醒系统,该系统只对满足一定尺寸条件的正面人脸产生响应,可以应用于人员出门的提醒等场合,解决了可能被其它生物或物体错误触发的问题,与传统的提醒方式相比,其灵活性和鲁棒性有所提高。
附图说明
图1为本实施例一种基于卷积神经网络的人脸识别提醒系统的框架图;
图2为本实施例树莓派控制模块的gpio的接线图;
图3为本实施例一种基于卷积神经网络的人脸识别提醒系统控制信号流程图;
图4为本实施例一种基于卷积神经网络的人脸识别提醒系统逻辑控制流程图;
图5为本实施例一种基于卷积神经网络的人脸识别提醒系统识别提醒的流程图;
图6为本实施例的yolov3-tiny模型结构图;
图7为本实施例conv模块的结构图。
具体实施方式
下面结合附图对本发明的目的、技术方案及优点进一步说明。应当理解,此处所描述的具体实施方式不仅仅用以解释本发明,并不限定本发明的保护范围。
如图1所示的一种基于卷积神经网络的人脸识别提醒系统,包括树莓派控制模块、语音输出模块和视频采集模块;树莓派控制模块将视频采集模块采集的图像进行识别和判断,并将判断结果通过语音输出模块发出提醒。
所述树莓派控制模块包括gpio(通用输入/输出口)、预处理模块、识别判断模块和语音控制模块,用于图像预处理、人脸识别与判断、发送控制信号给语音输出模块等;图像预处理将从视频采集模块输入的原始图像每个像素值除以255,并交换图像rbg三通道中第1通道和第三通道的顺序;识别判断模块使用yolov3-tiny模型进行人脸识别与判断。
所述视频采集模块包括摄像头ov5647,用于视频采集;
所述语音输出模块包括语音芯片sc50x0、喇叭以及若干电容,用于实现提醒语音的播放。所述语音输出模块中的语音芯片通过pwm口与喇叭连接,所述语音芯片的供电脚与接地脚之间接有电容,用于电源滤波。
语音输出模块负责发出提醒语音,视频采集模块负责监测环境并将环境图像传送给树莓派控制模块。
在树莓派控制模块中,发送控制信号由gpio控制,详细配置接线如图2所示。
所述树莓派控制模块通过csi端口与视频采集模块的摄像头连接;树莓派控制模块gpio中的语音输出控制端口(pin12)与语音输出模块的控制引脚相连;语音输出供电端口(pin02)与语音输出模块的供电脚相连;语音输出接地端口(pin06和pin09)与语音输出模块的接地脚相连;摄像头的启动与工作由csi端口控制;
选择与树莓派控制模块配套的ov5647摄像头,使用排线将树莓派控制模块与视频采集模块通过csi端口相连接。
如图3所示,摄像头视频采集模块的视频输入信号输入预处理模块进行图像预处理,预处理好的图像输入识别判断模块进行识别和判断,将判断的结果输入语音控制模块,语音控制模块再通过低电平触发信号控制语音输出模块,使语音输出模块的喇叭发出提醒语音。
如图4所示,树莓派控制模块进行识别、判断与控制的流程包括:先进行状态初始化,将与语音输出模块控制脚连接的语言输出控制信号端口pin设置为数据输出模式,并设置pin为高电平,然后初始化yolov3-tiny模型参数,包括置信度阈值confthreshold、非极大抑制阈值nmsthreshold、输入图像宽度inwidth、输入图像高度inheight、检测人脸标志flag等。初始化完成后,将训练好的模型通过opencv库提供的dnn模块读取到树莓派控制模块的内存中,并进行人脸识别。
为了提高模型的泛化能力,一般要求训练的样本丰富、背景复杂,而wider人脸数据集规模较大,包含32203张图片,其中50%的图片作为训练样本集、10%的图片作为验证样本集,该数据集中的人脸在姿态、光照、遮挡、尺度上变化较大,满足上述的要求。在yolov3-tiny模型的训练过程中,其图像在输入模型前,先通过角度angle、饱和度saturation、曝光度exposure、色调hue等属性进行调整,同时设置random开启多尺度训练、设置jitter开启数据抖动,以进一步增加样本的多样性。另外,在yolov3-tiny模型的基础上进行调整,为了满足本发明系统实时性的要求,在实际测试时将模型的输入设置为128*128尺寸、rgb三色三通道。
具体对yolov3-tiny模型中的yolov3-tiny.cfg配置文件的修改如下:
(1)修改模型预处理部分:
设置批数量batch为128、细分数subdivision为8、角度angle为5、饱和度saturation为1.5、曝光度exposure为1.5、色调hue为0.1,另外设置多尺度训练random为1、数据抖动jitter为0.3,以进一步增加样本的多样性。
(2)修改模型学习率相关部分:
另外设置初始学习率learning_rate为0.001,这个变量决定了yolov3-tiny模型的收敛速度以及识别效果,考虑到使用的是规模较大的wider人脸数据集,所以选取了较大学习率值,上升过程burn_in为1000,衰减时机steps为30000,60000,衰减大小scales为0.1,0.1,表示在30000次和60000次迭代时均衰减10倍,最大迭代次数max_batches为80000。
(3)修改模型结构部分:
设置识别类数classes为1,最后一层卷积层的卷积核数filters为18。
之后进行yolov3-tiny模型的训练,使用的命令为./darknetdetectortrain./cfg/voc-face.data./cfg/yolov3-tiny-face.cfg./yolov3-tiny.conv.15。另外,可以对训练好的模型进行测试,使用的命令为./darknetdetectorrecall./cfg/voc-face.data./cfg/yolov3-tiny-face.cfgbackup/yolov3-tiny-face_final.weights。
其中前者加载模型的结构和参数,并使用训练样本集进行多轮训练并完整保存模型的结构和参数;后者使用验证样本集来检测每步训练得到的模型对训练数据集之外图片的识别准确度,其输出直接反映了模型的泛化能力和识别效果。训练步骤:每次迭代从样本集中取出batch/subdivision=16张图片样本,经过角度变换、饱和度变换、曝光度变换、色调变换、数据抖动和多尺度变换等处理产生增强数据,然后将数据输入模型进行前向传播得到输出数据,输出数据代入误差函数得到误差值,根据误差值使用反向传播算法进行参数更新,这样完成了一次迭代,如此循环直到最大迭代次数。在模型训练完成后,设置输入高height为416、宽width为416,阈值thresh为0.25,得到对验证样本集的测试结果:召回率64.29%,准确率92.11%。
yolov3-tiny的网络结构如图6和图7所示,该模型为卷积神经网络结构,卷积神经网络主要由卷积层(con2dlayer)、批标准化层(bnlayer)、激活层(leakyrelulayer)和最大池化层(maxpool)组成;该模型中的卷积层、批标准化层和激活层依次连接构成卷积模块(conv模块),conv模块和pool模块即最大池化层(maxpool)交替相连;由于篇幅所限在图6中只标出了模型中的conv模块,因此conv*5代表5个conv模块和4个pool模块的交替连接。
在第五个conv模块之后,将输出数据分别输入到一个pool模块和一个conv模块,因此延伸出两条路径,分别为pool模块延伸出的路径和conv模块延伸出的路径;
延伸的两条路径具体为:在pool模块延伸出的路径中第三个conv模块将输出的数据分别输出到两个conv模块,其中一个conv模块是作为上采样(upsample),并与conv模块延伸出的路径中第二个conv模块的输出的数据进行拼接concat操作。concat操作之后的数据输入到2个conv模块后再将数据输出。另一个conv模块后面连接2个conv模块。最后两条输出路径分别为:output1和output2。
两条路径中,一条有10层con2dlayer,另一条有9层con2dlayer,所述模型分别两条输出路径进行人脸识别;由于包含的con2dlayer层数不同,两条输出路径分别代表了在大尺度与小尺度上进行人脸检测的结果,在训练阶段由mse代价函数对两者进行统一计算,在测试阶段遍历这两个输出的结果,取置信度最大的网格作为检测到人脸的网格,这样可以使模型识别出不同大小的人脸。
输入数据经过这两条路径处理得到的输出数据的形式为:s2×(b×(4+1+c)),其中s2表示将图片均匀切割成了s2个网格,该值由输入数据的尺寸所决定;b=3为每个网格中预测人脸位置的边界框的个数;c=1为检测的类别数,代表人脸类别;4和1分别代表边界框的位置和置信度。
在将预处理后的数据输入yolov3-tiny模型进行前向处理forward之后,通过后处理postprocess遍历输出数据的每一个维度,将模型输出结果中最大的数值作为检测到人脸的置信度,当置信度超过设置的阈值并且人脸的尺寸大于设置的阈值时,即判断为识别到了人脸。
所述yolov3-tiny模型的损失函数为:
其中,s2表示将输入图像均匀切割出的网格数,该值由输入图像的尺寸所决定;b=3为每个网格中预测人脸位置的边界框的个数;classes为检测的类别数,由于只检测人脸,因此该值为1;
在第i个网格中,pi(c)表示预测类别,当值为0时预测没有物体,当值为1时预测有人脸,(xi,yi)表示预测的边界框的左上角坐标,wi,hi分别表示预测的边界框的宽和高,ci表示预测置信度;相应的,
模型通过反向传播算法进行训练,使用sgd优化器和mse代价函数计算图像数据经过模型后输出的值与对应的类别概率、置信度、方框位置、方框大小之间的loss值,根据梯度下降的负方向对模型的各类参数进行迭代更新,使得loss值逐渐下降至基本不变(在测试中该值约为2,这是由模型的深度与样本的规模共同决定的),经过80000次迭代得到最终的模型。
模型的训练依托于黑暗网络深度学习框架(darknet),这是一个轻量级的基于c语言和cuda(computeunifieddevicearchitecture)的开源深度学习框架,提供了cpu和gpu(graphicsprocessingunit)两种计算类型,容易安装、没有依赖项、具有较好的移植性,因此可以将yolov3-tiny模型的训练与运行分别部署在有强大gpu的分布式计算机和只有低端cpu的嵌入式模块(树莓派控制模块)上,本例采取的就是利用darknet框架训练yolov3-tiny模型,将训练好之后的yolov3-tiny模型转入识别判断模块进行判断识别。
判断识别过程中,先通过配置文件和参数文件加载该模型与相关参数,再获取视频帧进行预处理:将从视频采集模块输入的原始图像每个像素值除以255,并交换图像rbg三通道中第1通道和第三通道的顺序。将预处理后的图像输入yolov3-tiny模型进行判断识别,得到模型的输出结果,根据结果中最大的数值作为检测到人脸的置信度,当置信度超过设置的阈值并且人脸的尺寸大于设置的阈值时,即认为检测到了人脸,否则视为没有人脸。如果检测到了人脸,则树莓派控制模块控制发出控制信号给语音输出模块,随后由语音输出模块发出提醒,否则不作响应,进入下一次判断。
如图5所示的识别提醒流程图,在每次识别循环中,树莓派控制模块需要预先设置gpio口的pin12为高电平,csi端口启动摄像头获得视频帧,对视频采集模块输入的视频帧进行预处理:将原始图像每个像素值除以255,并交换图像rbg三通道中第1通道和第三通道的顺序形成输入数据,然后将输入数据通过yolov3-tiny模型进行前向forward处理得到输出数据,再由后处理postprocess函数遍历输出数据的每一个维度,将模型输出结果中最大的数值作为检测到人脸的置信度,当置信度超过设置的阈值并且人脸的尺寸大于设置的阈值时,即判断为识别到了人脸,否则视为没有人脸。若检测到人脸,根据结果控制pin12输出语音控制信号给语音输出模块发出语音,否则不发出语音。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!