一种基于神经网络和模糊推理的中文分词方法、系统及介质与流程
本发明属于机器学习、神经网络、人工智能技术领域,自然语言处理领域,尤其是自然语言处理领域的中文分词方法。
背景技术:
当今社会计算机的应用日益广泛,己经渗透到各种传统行业;实现人与计算机之间高效和准确的信息交互,是当前计算机工作者的重要任务。据统计,在信息领域中80%以上的信息是以语言文字为载体的。这些语言信息的自动输入和输出、校对、分类和文摘、信息的检索和提取、语言翻译等技术都是国民经济信息化的重要基础。
自然语言处理是一门语言学和计算机科学的交叉学科,着重处理人类语言的可计算的特性。它属于认知科学,并和人工智能的一些领域有一些交迭。现在的计算机不懂人类的语言,而人在理解计算机的语言方面也有困难,因为计算机的语言并不符合人的思考方式。
近年来,自动分词己经引起多方面的关注,成为中文信息处理的一个前沿课题。中文自动分词研究是中文信息处理技术的基础工程,具有以下重要意义:(1)自动分词是语言学研究和中文信息处理应用进行资源共享的必要手段;(2)自动分词是对汉语进行定量分析的基础;(3)词是语法功能的载体,自动分词是句法分析的基础;(4)词是语义功能的载体,自动分词是语义研究的基础;(5)―以词定字”和―以词定音”等方法是进行文本校对、简繁转换、语音合成等的主要手段。中文自动分词是中文信息处理的一项重要的基础性工作,许多中文信息处理项目中都涉及到分词问题,如机器翻译、中文文献、自动文摘、自动分类、中文文献库。,现有的中文分词可以运用bp神经网络实现中文分词,但是精确度不够高,bp神经网络结合模糊推理来实现提高对中文分词的精确度,是模糊数学领域在nlp(自然语言处理)的一次创新的结合。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种训练速度快,计算量小,预测速度快、提高精度的基于神经网络和模糊推理的中文分词方法。本发明的技术方案如下:
一种基于神经网络和模糊推理的中文分词方法,用于计算机自然语言处理,其包括以下步骤:
101、计算机对语料库进行包括划分训练数据集、验证数据集、整理语料库格式、读取测试数据集、验证数据集在内的预处理操作;
102、计算机读取语料库中的训练集和测试集,并训练文本语料库(icwb2-data)得到中文词向量,将训练集和验证集中所有的中文词都转换为词向量;
103、计算机建立bp反向传播神经网络学习模型,将步骤102训练之后得到的学习结果对未分词的语句进行初步分词预测,得到模糊词组;
104、计算机将预测产生的模糊词组,使用《知网hownet》得到模糊词之间的关系;
105、计算机基于模糊词关系表示,采用模糊推理计算是否需要分词;
106、通过建立bp-模糊推理-交叉验证模型,计算机对输入的语句进行分词预测。
进一步的,所述步骤101对语料库进行预处理操作,主要操作如下:
1)将icwb2-data语料库中,pku_training.txt作为训练集,pku_test.txt作为验证集
2)整理训练集、验证集的数据格式,设置标签0(不需要分词),1(需要分词),即逢1进行分词,由0和最近的1所代表的字组合成一个词语按照字为单位,如果需要分割,则设置为1,不需要分割,设置为0。(例:今天天气不错–>[010101])。
3)将训练集以及验证集的数据,按照2)的数据格式,计算机读取到内存中。
进一步的,所述步骤102读取语料库中的训练集和测试集,并训练语料库(测试集、验证集)得到中文词向量,具体包括:
对icwb2-data语料库训练集以及测试集所有语料进行读取,并训练词向量,具体操作如下:
1)使用gensim工具包的word2vec,训练步骤2中读取到的中词组,得到中文词向量库。
2)将训练集、验证集转换为中文词向量组成的矩阵,每一列代表一个中文词向量。
进一步的,所述步骤103建立bp神经网络学习模型,进行初步数据预测,包括步骤:
1)将训练集中每个中文词作为一种分词方案;
2)按照语句长度,设置标签0(不需要分词),1(需要分词),即逢1进行分词,由0和最近的1所代表的字组合成一个词语;
3)缺失值填充:将语料库最长的语句作为标准长度,长度不够的句子,右侧填充全0的词向量;
4)待bp网络训练结束后,读取测试语料,输入模型,得到初步分词结果。
5、根据权利要求4所述的一种基于神经网络和模糊推理的中文分词方法,其特征在于,所述步骤104将预测产生的模糊词组,使用《知网hownet》得到模糊词之间的关系,具体包括:
1)经由bp网络初步预测的结果,输出值大于0.7为1,小于0.3为0,在0.3~0.7之间的,使用《知网hownet》计算两词之间的关系。
2)《知网hownet》义原之间的关系
上下位:h;
对义:c;
反义:a;
相关:#;
部件:%;
属于:&;
宾语:$;
主语:*;
隐性:+;
很可能的:~;
时空:@;
材料:?;
典型属性:!;
表示否定:^;
3)输入:
概念1:id1,def1;
概念2:id2,def2;
关联度r=0;
首义原关联度权重mr=0;
非首义原关联度权重or=0;
4)如果两词def1=def2则goto(5)
5)处理两词首义原:
如果ms1(概念1首义原)和ms2(概念2首义原),如果相同则mr=1;
如果不同,考查ms1和ms2是否相关,如相关,关联符号mark;
ifmark='a'||mark=='^'thenmr=1;
ifmark=='h'||mark=='#'||mark=='~'||mark=='!'thenmr=0.6;
elsemr=0.2;
如ms1和ms2无关,mr=0;
6)处理非首义原:
考查非首义原的关系,参数ol=1/义原总数;
result1中任意非首义原s1和result2中任意非首义原s2,如果相同,or+=ol;
如果不相同但是具有某种关系:
ifmark='a'||mark=='^'thenor+=ol;
ifmark=='h'||mark=='#'||mark=='~'||mark=='!'thenor+=ol*0.6;
elseor+=ol*0.2;如果or>1,or-=ol;
7)r=0.5*mr+0.5*or;mr(首义原关联度权重)、or(非首义原关联度权重)
8)改变哈希表中id1和id2的关系序列,添加关联度r,id1(知网中词语1的编号)和id2(知网中词语2的编号)。
进一步的,所述步骤105基于模糊词关系表示,建立bp-模糊推理-交叉验证模型,采用模糊推理计算是否需要分词,具体步骤如下:
1)定义:
初始化r=0;
r1r2分别表示模糊词和确定词,初始化为r1=0,r2=0;
vagword表示每个模糊词与分词方案之间的隶属度关系,初始化为vagword=0;每个确定词权重
每个分词方案权重
1)r1:
遍历分割方案中的每个模糊词,并研究模糊词与分割方案中每个确定词的关系,通过《知网hownet》得到两个相关词的相关性r,改变模糊词的隶属度;
vagword=vagword+surword*r
r1=r1+vagword*surword
2)r2
遍历分割方案中的每个模糊词,得到模糊场的相关度,改变模糊词的隶属度。
vagword=2*vagword*r
r2=r2+vagword*vagword
3)r
ifneitherr1norr2is0,
ifr1=0,r=r2
ifr2=0,r=r1
如果隶属度关系大于神经网络的输出值,不进行分割。
如果隶属度关系小于神经网络的输出值,则进行分割。
一种介质,该介质内部存储计算机程序,所述计算机程序被处理器读取时,执行上述任一项的方法。
一种基于神经网络和模糊推理的中文分词系统,其包括
预处理模块:用于对语料库进行包括划分训练数据集、验证数据集、整理语料库格式、读取测试数据集、验证数据集在内的预处理操作;
中文词向量训练模块:读取语料库中的训练集和验证集,并训练文本语料库(icwb2-data)得到中文词向量;
模糊词组预测模块:计算机建立bp(反向传播神经网络)神经网络学习模型,(将步骤102训练之后得到的学习结果)对未分词的语句进行初步分词预测,得到模糊词组;
模糊推理模块:将预测产生的模糊词组,使用《知网hownet》得到模糊词之间的关系;基于模糊词关系表示,采用模糊推理计算是否需要分词;
预测模块:通过建立bp-模糊推理-交叉验证模型,对输入的语句进行分词预测。
本发明的优点及有益效果如下:
本发明训练速度快,计算量小,预测速度快,以上这些特征是通过引入模糊推理机制实现的,所需语料库可以很小,采用模糊推理,将神经网络的预测结果进行二次复核,在神经网络的预测结果基础上提高预测精度。
本发明针对自然语言处理领域中文分词问题,提出了基于模糊推理的中文分词方法,通过从模糊域中计算分割方案的隶属度关系,充分全面的预测分割方案。本发明的创新点是模糊推理第一次用在中文分词领域,提升了单独使用神经网络算法提升的精确度。
附图说明
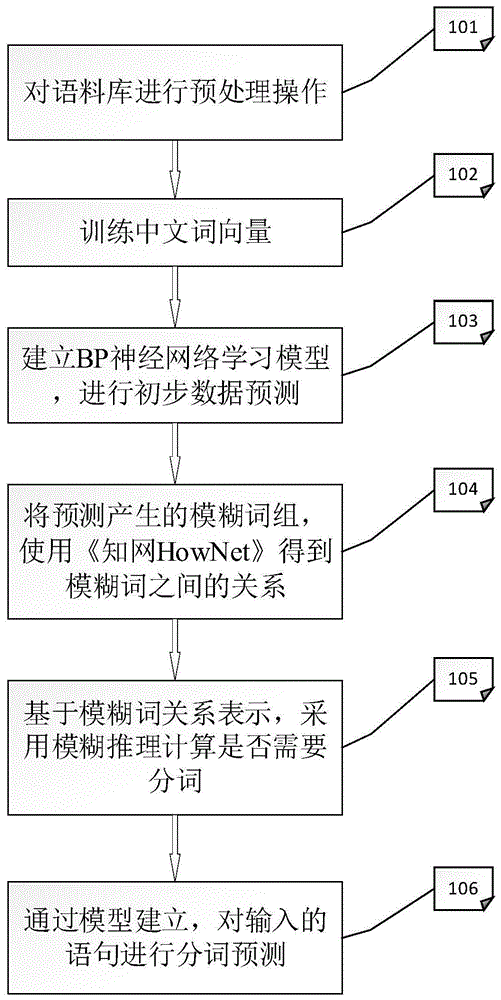
图1是本发明提供优选实施例提供一种基于神经网络和模糊推理的中文分词方法流程图。
图2为本发明实施例提供一种基于神经网络和模糊推理的中文分词方法数据计算逻辑图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
参考图1,图1为本发明实施例一提供一种基于神经网络和模糊推理的中文分词方法流程图,具体包括:
101对语料库进行预处理操作,主要操作如下:
1)将icwb2-data语料库中,pku_training.txt作为训练集,pku_test.txt作为验证集
2)整理训练集、验证集的数据格式,设置标签0(不需要分词),1(需要分词),即逢1进行分词,由0和最近的1所代表的字组合成一个词语按照字为单位,如果需要分割,则设置为1,不需要分割,设置为0。(例:今天天气不错–>[010101])。
3)将训练集以及验证集的数据,按照2)的数据格式,计算机读取到内存中。
102读取语料库中的训练集和测试集,并训练语料库(测试集、验证集)得到中文词向量,具体包括:
对icwb2-data语料库训练集以及测试集所有语料进行读取,并训练词向量,具体操作如下:
1)使用gensim工具包的word2vec,训练步骤2中读取到的中词组,得到中文词向量库。
2)将训练集、验证集转换为中文词向量组成的矩阵,每一列代表一个中文词向量。
103建立bp神经网络学习模型,进行初步数据预测。主要操作如下:
1)将训练集中每个中文词作为一种分词方案
2)按照语句长度,设置标签0(不需要分词),1(需要分词),即逢1进行分词,由0和最近的1所代表的字组合成一个词语。
例:迈向充满希望的新世纪——一九九八年新年讲话;
标签为:(01010111011000010101)
3)缺失值填充:将语料库最长的语句作为标准长度,长度不够的句子,右侧填充全0的词向量
4)待bp网络训练结束后,读取测试语料,输入模型,得到初步分词结果(分词预测输出值在0.001~1.000之间)
104将预测产生的模糊词组,使用《知网hownet》得到模糊词之间的关系。
具体描述如下。
1)经由bp网络初步预测的结果,输出值大于0.7为1,小于0.3为0,在0.3~0.7之间的,使用《知网hownet》计算两词之间的关系。
2)《知网hownet》义原(义原是知网中最基本的、不易于再分割的意义的最小单位。所有的中文词都可以用义原来进行解释。例如:“人”虽然是一个非常复杂的概念,它可以是多种属性的集合体,但我们也可以把它看作为一个义原。)之间的关系
上下位:h;
对义:c;
反义:a;
相关:#;
部件:%;
属于:&;
宾语:$;
主语:*;
隐性:+;
很可能的:~;
时空:@;
材料:?;
典型属性:!;
表示否定:^;
3)输入:
概念1:id1,def1;
概念2:id2,def2;
关联度r=0;
首义原关联度权重mr=0;
非首义原关联度权重or=0;
4)如果两词def1=def2则goto(5)
5)处理两词首义原:
如果ms1和ms2,如果相同,mr=1;
如果不同,考查ms1和ms2是否相关。如相关,关联符号mark:
ifmark='a'||mark=='^'thenmr=1;
ifmark=='h'||mark=='#'||mark=='~'||mark=='!'thenmr=0.6;
elsemr=0.2;
如ms1和ms2无关,mr=0;
6)处理非首义原:
考查非首义原的关系。参数ol=1/义原总数。
result1中任意非首义原s1和result2中任意非首义原s2,如果相同,or+=ol;
如果不相同但是具有某种关系:
ifmark='a'||mark=='^'thenor+=ol;
ifmark=='h'||mark=='#'||mark=='~'||mark=='!'thenor+=ol*0.6;
elseor+=ol*0.2;如果or>1,or-=ol;
7)r=0.5*mr+0.5*or;
改变哈希表中id1和id2的关系序列,添加关联度r。
105基于模糊词关系表示,采用模糊推理计算是否需要分词,具体步骤如下:
1)定义:
初始化r=0;
r1r2分别表示模糊词和确定词,初始化为r1=0,r2=0;
vagword表示每个模糊词与分词方案之间的隶属度关系,初始化为vagword=0;每个确定词权重
每个分词方案权重
1)r1:
遍历分割方案中的每个模糊词,并研究模糊词与分割方案中每个确定词的关系,通过《知网hownet》得到两个相关词的相关性r,改变模糊词的隶属度;
vagword=vagword+surword*r
r1=r1+vagword*surword
2)r2
遍历分割方案中的每个模糊词,得到模糊场的相关度,改变模糊词的隶属度。
vagword=2*vagword*r
r2=r2+vagword*vagword
3)r
ifneitherr1norr2is0,
ifr1=0,r=r2
ifr2=0,r=r1
如果隶属度关系大于神经网络的输出值,不进行分割。
如果隶属度关系小于神经网络的输出值,则进行分割。
需要指出的是,以上步骤101对语料库进行预处理操作;102训练中文词向量;103建立bp神经网络学习模型,进行初步数据预测;104将预测产生的模糊词组,使用《知网hownet》得到模糊词之间的关系;105基于模糊词关系表示,采用模糊推理计算是否需要分词;106通过建立bp-模糊推理-交叉验证模型,对输入的语句进行分词预测等步骤均是计算机来执行完成的,其是具备工业运用或者产业运用的方法,并不是需要人全程参与的步骤,其是利用了自然规律来完成的技术方案,对现有的计算机信息处理过程中的文景转换中的耗时以及不准确的缺陷进行的技术改变,因此属于技术方案,因此其并不属于专利法第二条第二款规定的情形,也不属于专利法25条第一款智力活动规则的范畴。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!