一种用于行为识别的虚拟视频数据生成方法与流程
本发明属于计算机图形学技术领域,特别涉及一种用于行为识别的虚拟视频数据生成方法。
背景技术:
虚拟合成数据因其效率高、成本低,在物体检测、语义分割等很多计算机视觉任务中都有着很大的作用。在行为识别领域里,视频数据的收集和制作行为标签的成本都是相当昂贵的,因此生成用于行为识别的虚拟视频数据是一个非常迫切的需求。
目前,虚拟视频数据的生成存在两方面的难点:(1)生成动态虚拟视频比生成静态图像更具有挑战性,虚拟视频的制作需要对人体骨架进行建模,而且需要每一帧骨架的姿态数据来驱动虚拟人体模型来运动。静态图像生成仅仅需要得到骨架关节点的位置信息即可。(2)需要解决虚拟数据与真实数据在特征域上的迁移问题,即领域变换问题,使得虚拟数据在特征域上尽可能地接近真实数据。
将虚拟视频数据用于行为识别任务还处于如何制作虚拟数据的阶段,目前已有的虚拟视频数据生成方法都是利用代价昂贵的动作捕捉文件来对行为进行建模,需要特定的设备和环境;目前的虚拟视频数据生成方法生成的数据虚拟性较强,与真实数据中的行为信息相关联很少,很难提升行为识别算法精度。
综上,亟需一种新的用于行为识别的虚拟视频数据生成方法。
技术实现要素:
本发明的目的在于提供一种用于行为识别的虚拟视频数据生成方法,以解决上述存在的一个或多个技术问题。本发明的方法不依赖于代价昂贵的动作捕捉数据,而是利用易获得的3d姿态数据在3d建模软件构建的虚拟环境中生成关键帧信息,合成虚拟视频数据;本发明生成的虚拟动作视频数据和真实数据有一定的相似性,可提升行为识别算法精度。
为达到上述目的,本发明采用以下技术方案:
本发明的一种用于行为识别的虚拟视频数据生成方法,包括:
步骤1,使用建模软件构造虚拟人体的外观模型和骨架模型,进行蒙皮和着色处理,获得人体模型;
步骤2,在3d建模软件虚拟场景下进行行为建模;所述行为建模包括:读取3d姿态数据,计算3d姿态数据中不同帧之间相同骨骼节点的欧拉角,通过欧拉角驱动人体模型执行3d姿态数据的相应行为,获得预设数量的关键帧,完成基于3d姿态数据的行为建模;
步骤3,将步骤2获得的关键帧进行渲染,渲染时采用领域随机化策略,生成用于行为识别的虚拟视频数据。
本发明的进一步改进在于,步骤1中人体模型的构建具体包括以下步骤:
基于人类属性对虚拟人体进行外观建模;对虚拟人体进行骨架建模;
利用烘焙贴图技术制作贴图为外观模型着色以及蒙皮处理,获得人体模型;
其中,人体模型的运动由骨架模型驱动。
本发明的进一步改进在于,步骤1中,人类属性包括:性别、种族、年龄、身高、体重和服饰;根据kinect深度相机的人体关节点信息来建立骨架模型。
本发明的进一步改进在于,步骤2具体包括:
1)读取3d姿态数据并进行解析;其中,3d姿态数据用3d深度相机kinect采集;kinect对人体定义了25个关节点的3d坐标信息,将25个关节点的3d坐标信息提取出来;
2)以hip为原点,右手方向为x轴正方向,头上方为y轴正方向,人背对为z轴正方向,构建惯性坐标系;计算出每个关节点在所述惯性坐标系下的位置;
3)构建父-子节点局部坐标系,以父节点作为原点、y轴正向指向子节点的方向;将每个关节点在世界坐标系中的3d坐标位置pglobal转化成局部坐标系中的位置plocal;
4)从hip关节点开始,按照kinect定义的节点结构迭代计算当前帧每个关节点的旋转欧拉角;其中,欧拉角的计算过程中,先根据罗德里格斯公式计算从初始帧到当前帧关节点的旋转矩阵r,然后根据旋转矩阵r求出zxy顺序的欧拉角rotz,rotx,roty;
5)重复步骤4),计算出每一帧25个关节点基于第一帧的旋转欧拉角,在blender虚拟环境中,将每一帧都作为关键帧插入到时间线中,完成基于3d姿态数据的行为建模。
5、根据权利要求4所述的一种用于行为识别的虚拟视频数据生成方法,其特征在于,步骤3)构建父-子节点局部坐标系的步骤具体包括:
将每个关节点在世界坐标系中的3d坐标位置pglobal转化成局部坐标系中的位置plocal,计算公式为,
plocal=t*pglobal;
坐标变化矩阵t的计算公式为,
其中,
coordp为父级节点的局部坐标系基向量矩阵,表达式为,
coordp=coordp+∑rδfk,
式中,∑rδfk为fk约束的增量。
本发明的进一步改进在于,步骤4)中具体包括:
根据罗德里格斯公式计算从初始帧到当前帧关节点的旋转矩阵r,表达式为,
式中,参数m,n,v分别为,
其中,v为骨头向量的旋转轴,θ为boneinit和bonecurrent的夹角;
根据旋转矩阵r求出zxy顺序的欧拉角rotz,rotx,roty,表达式为,
其中,rij为旋转矩阵r的第i行第j列元素。
本发明的进一步改进在于,步骤3中具体包括:
通过设置不同的渲染帧数、视频背景、人体模型、渲染的相机视角、光照强度对视频帧进行渲染,获得的虚拟视频数据。
本发明的进一步改进在于,
渲染帧数设置包括:渲染视频的所有帧;或者,按照atw-cnns的输入方式,利用时域分割采样方法选取随机帧进行渲染;
视频背景设置包括:在一定预设区域内任意设置人体模型在3d背景里的位置;在lsun和coco数据集中随机选择作为2d背景;
渲染的相机视角设置包括:相机的视角选取为前、后、左、右4个主视角;在渲染视频时,从4个主视角中随机选择一个进行渲染。
本发明的进一步改进在于,步骤1中建模软件采用开源的makehuman建模软件;步骤2中3d建模软件采用blender。
与现有技术相比,本发明具有以下有益效果:
本发明的方法,是一种全新的虚拟行为视频数据生成方法,与目前的基于动作捕捉文件合成虚拟视频的方法不同,本发明的方法直接利用廉价易得的3d姿态数据来生成虚拟视频,实现了高效灵活地生成虚拟行为视频数据;另外,将领域随机化策略应用在生成虚拟视频数据中,缓解了领域变换问题;本发明生成的虚拟动作视频数据和真实数据有一定的相似性,在一定程度上替代真实数据,或在真实数据稀缺时填补数据空缺,进一步完善用于行为识别的数据集,可提升行为识别算法精度。
进一步地,本发明利用易获得的3d姿态数据在3d建模软件blender构建的虚拟环境中生成关键帧信息,合成虚拟视频。
进一步地,本发明为了缓解领域变换问题,使用领域随机化机制对虚拟环境中的光照、相机、背景以及渲染参数随机化,能够高效地生成任意视角下的任意人体模型的行为视频。
进一步地,本发明为了简化建模的成本,选择使用开源的makehuman建模软件,它能够快速生成自带骨架模型并自动进行蒙皮的不同外观的人体模型,并且这种模型能够完美适应blender虚拟环境。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面对实施例或现有技术描述中所需要使用的附图做简单的介绍;显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
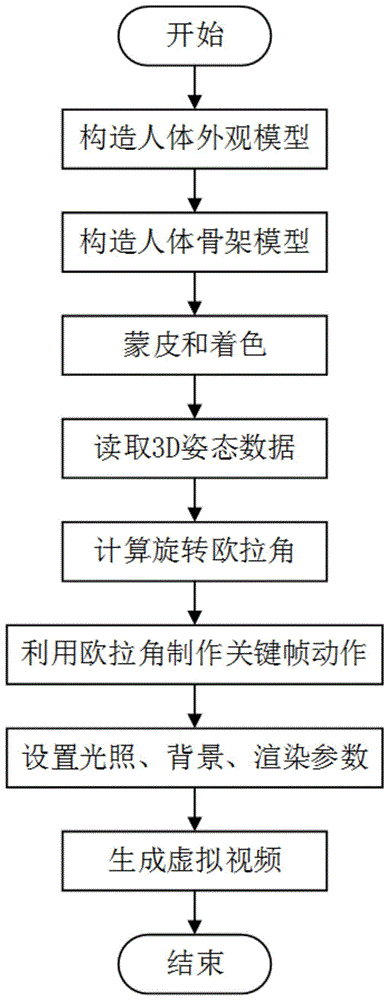
图1为本发明实施例的一种用于行为识别的虚拟视频数据生成方法的流程示意框图;
图2为本发明实施例中,虚拟人体模型的建模示意图;其中,图2(a)为外观建模示意图,图2(b)为骨架建模示意图,图2(c)为蒙皮和着色示意图,图2(d)为渲染示意图;
图3为本发明实施例中,虚拟人体模型示意图;
图4为本发明实施例中,nturgb+d数据集的部分示例示意图;
图5为本发明实施例中,人体关节点树结构以及t-pose的示意图;其中图5(a)为人体关节点树结构示意图,图5(b)为t-pose示意图;
图6为本发明实施例中,父-子关节点的局部坐标系下骨头向量的旋转变换示意图;
图7为本发明实施例中,生成的部分虚拟动作视频数据示例和真实数据示例的对比示意图。
具体实施方式
为使本发明实施例的目的、技术效果及技术方案更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述;显然,所描述的实施例是本发明一部分实施例。基于本发明公开的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的其它实施例,都应属于本发明保护的范围。
本发明的一种用于行为识别的虚拟视频数据生成方法,该方法使用3d建模软件blender来构建虚拟环境,生成虚拟视频数据。首先进行人体建模,使用建模软件makehuman来构造虚拟人体的外观模型和骨架模型,并进行蒙皮和着色处理,获得人体模型;
然后在3d建模软件blender虚拟场景下进行行为建模:获取3d姿态数据,计算3d姿态数据中不同帧之间相同骨骼节点的欧拉角,来驱动人体模型执行3d姿态数据的相应行为,获得预设数量关键帧;其中,3d姿态数据为用于驱动骨架运动的数据,也就是实施例中人体25个节点在的坐标信息;
最后将关键帧进行渲染,渲染的时候采用领域随机化策略,生成了虚拟视频数据进行渲染,渲染时采用领域随机化策略,通过设置不同光照、相机、背景参数缓解领域变换问题,最终生成多种场景下不同人体各种行为的虚拟视频数据。
本发明实施例提供一种用于行为识别的虚拟视频数据生成方法,通过利用易获得的3d姿态数据在3d建模软件blender构建的虚拟环境中生成关键帧信息,合成虚拟视频,另外,使用领域随机化机制对虚拟环境中的光照、相机、背景以及渲染参数随机化,缓解领域变换问题,高效地生成任意视角下的任意人体模型的行为视频。
请参阅图1,本发明实施例的一种用于行为识别的虚拟视频数据生成方法,步骤如下:
请参阅图2,步骤1:建立人体模型。
1)基于人类属性,比如性别、种族、年龄、身高体重、服饰等对视频的主体进行外观建模,如图2(a)外观建模为人体模型外观建模示意图。
2)对视频的主体进行骨架建模,类似于真实情况下的人类运动,人体模型的运动由骨架模型驱动,根据kinect深度相机的人体关节点信息来建立骨架模型,如图2(b)骨架建模为人体模型骨架建模示意图。
3)利用烘焙贴图技术制作贴图为模型着色以及蒙皮处理,如图2(c)蒙皮和着色为人体模型蒙皮和着色示意图。
请参阅图3,为了简化建模的成本,选择使用开源的makehuman建模软件,它能够快速生成自带骨架模型并自动进行蒙皮的不同外观的人体模型,并且这种模型能够完美适应blender虚拟环境,如图3为生成的部分虚拟人体模型示例图。
步骤2:利用3d姿态数据集进行行为建模。
1)对3d姿态数据进行解析,大多数3d行为识别数据集都是用3d深度相机kinect采集,kinect对人体定义了25个关节点的3d坐标信息。这25个关节点如图5所示,分别为:1-臀部(hip)、2-脊椎(spine)、21-胸部(shouldercenter)、3-脖子(neck)、4-头部(head)、5-左肩膀(leftshoulder)、9-右肩膀(rightshoulder)、6-左肘部(leftelbow)、10-右肘部(rightelbow)、7-左腕部(leftwrist)、11-右腕部(rightwrist)、8-左手部(lefthand)、12-右手部(righthand)、22-左指尖(lefthand-tip)、24-右指尖(righthand-tip)、23-左拇指(leftthumb)、25-右拇指(rightthumb)、13-左臀部(lefthip)、17-右臀部(righthip)、14-左膝盖(leftknee)、18-右膝盖(rightknee)、15-左脚踝(leftankle)、19-右脚踝(rightankle)、16-左脚(leftfoot)、17-右脚(rightfoot)。
本发明实施例中,使用nturgb+d数据集中的姿态数据生成虚拟视频,图4为nturgb+d数据集的部分示例,其中数据集标签里包含大量3d骨架信息,比如关节点未知信息、长度信息等等,需要将25个关节点的3d坐标信息提取出来。
2)根据1)中kinect定义的关节点的结构,构建惯性坐标系,即以hip为原点,右手方向为x轴正方向、头上方为y轴正方向、人背对为z轴正方向的坐标系,计算出每个关节点在该坐标系下的位置。
3)构建父-子节点局部坐标系,即以父节点作为原点、y轴正向指向子节点的方向。用如下公式将每个关节点在世界坐标系中的3d坐标位置pglobal转化成局部坐标系中的位置plocal,如图6所示为父-子关节点的局部坐标系下骨头向量的旋转变换。
plocal=t*pglobal
上述式中的坐标变化矩阵t可以根据如下公式得到:
其中,
4)从hip关节点开始,按照2)中定义的节点结构迭代计算当前帧每个关节点的旋转欧拉角。欧拉角的计算需要先根据罗德里格斯公式计算从初始帧到当前帧关节点的旋转矩阵r,
式中,3个参数m,n,v分别为:
m=1-cosθ
n=sintheta
其中,v为骨头向量的旋转轴,θ为boneinit和bonecurrent的夹角;然后根据旋转矩阵利用下式求出zxy顺序的欧拉角rotz,rotx,oty:
rotx=arcsin(-r12)
其中,rij为旋转矩阵r中第i行第j列的元素。
5)重复4)中的方法计算出每一帧25个关节点基于第一帧的旋转欧拉角,在blender虚拟环境中,将每一帧都作为关键帧插入到时间线中,完成基于3d姿态数据的行为建模。
步骤3:渲染制作动画。
通过设置不同的渲染帧数、视频背景、人体模型、渲染的相机视角、光照强度对视频帧进行渲染,以下是关于这5种渲染策略的详细介绍:
1)渲染帧数:渲染视频可以渲染视频的所有帧,或者可以和行为识别模型对输入的方法相对应,比如按照atw-cnns的输入方式,利用时域分割采样方法选取随机帧来进行渲染以节省制作虚拟视频的时间;
2)视频背景:对于3d背景,在一定区域内任意设置人体模型在3d背景里的位置,而2d背景图两个大型图像数据集lsun和coco数据集中随机选择作为2d背景,这两个数据集包含大量真实室内和室外场景的图片;
3)人体模型:为了丰富视频数据中执行行为的主体,即人体模型的多样性,使用makehuman软件创建了20个人体模型,按照不同的人体属性,比如年龄、性别、身材、服饰等,使得这些模型外观区别度较大,生成视频时随机选择一个人体模型;
4)渲染的相机视角:因为虚拟环境允许将摄像机放置在任何位置,将相机的视角选取了4个主视角前、后、左、右,并且相机不会运动,那么在渲染视频时从4个视角中随机选择一个进行渲染;
5)光照强度:在渲染过程中,光线会直接影响不同材质的纹理效果,由于真实视频中的光线相对稳定,使用灯光类型的光照模型来模拟室内光照效果,光照强度从0到10随机选取。
在渲染完成后,得到最终的用于行为识别的虚拟视频数据,图7显示了该方法生成的部分虚拟视频数据和真实数据。可以看到,生成的虚拟动作视频数据和真实数据有一定的相似性,在一定程度上替代真实数据,或在真实数据稀缺时填补数据空缺,进一步完善用于行为识别的数据集。
虚拟视频数据用于预训练:
在实验中,用与训练阶段的真实数据相同数量的虚拟视频数据用于预训练网络模型,在nturgb+d数据集上的识别精度结果如表1所示。其中syndaily(dr)表示通过领域随机化方法渲染得到虚拟视频数据用于预训练。从实验结果可以看出,对于2d卷积神经网络模型,与用imagenet数据集的预训练方法相比,用虚拟视频数据进行预训练后,网络模型的性能得到进一步提高。对于3d卷积神经网络模型,性能有更大程度上的提升,表明虚拟视频数据有助于提高行为识别模型在时域中学习的能力。
表1.识别精度对比
综上所述,针对目前生成方法的难点以及不足,本发明提出了一种全新的用于行为识别的虚拟视频数据生成方法,这种方法不依赖于代价昂贵的动作捕捉数据,而是利用易获得的3d姿态数据在3d建模软件blender构建的虚拟环境中生成关键帧信息,合成虚拟视频,另外,为了缓解领域变换问题,使用领域随机化机制对虚拟环境中的光照、相机、背景以及渲染参数随机化,高效地生成任意视角下的任意人体模型的行为视频。本发明是一种全新的虚拟行为视频数据生成方法,与目前的基于动作捕捉文件合成虚拟视频的方法不同,该方法直接利用廉价易得的3d姿态数据来生成虚拟视频,实现了高效灵活地生成虚拟行为视频数据;另外,将领域随机化策略应用在生成虚拟视频数据中,缓解了领域变换问题。生成的虚拟动作视频数据和真实数据有一定的相似性,在一定程度上替代真实数据,或在真实数据稀缺时填补数据空缺,进一步完善用于行为识别的数据集,进而可提升识别算法精度。
以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员依然可以对本发明的具体实施方式进行修改或者等同替换,这些未脱离本发明精神和范围的任何修改或者等同替换,均在申请待批的本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!