一种基于深度学习多特征融合的驾驶员疲劳检测方法与流程
本发明涉及驾驶员疲劳检测领域,尤其涉及一种基于深度学习多特征融合的驾驶员疲劳检测方法。
背景技术:
近几十年来,随着人们生活水平的不断提高,汽车的数量也在逐步增加。随着汽车的增加,给人们生活带来快捷与方便的同时,频繁的交通事故也带来了惨重的经济损失,人民的生命也受到了威胁。因此驾驶员疲劳检测技术的研究对于预防交通事故有着重要的意义。
检测驾驶员疲劳主要是从三个方面来进行检测监控,包括:
基于车辆状态的方法:通过方向盘转角程度、方向盘转向握力,车速、车辆偏移、制动踏板力和加速踏板力等检测疲劳;
生理信号测量:当驾驶员处于疲劳状态时,驾驶员的生理指标,例如脑电波[脑电信号],电活动心脏[心电信号],与肌肉相关的电活动[肌电信号]偏离正常值;
计算机视觉检测:当驾驶员比较困倦时,其面部特征与清醒状态的面部特征不同。
但是,基于车辆状态的方法的分析结果容易受到个人驾驶习惯、天气、车辆特性及道路状况等外界环境因素的影响,鲁棒性不强,且只有在驾驶员即将发生交通事故时才能检测到异常,不能提前预警,同时大多数机载生理传感器是复杂的并且必须附着在人体皮肤表面,这会引起驾驶员的不适,并且会因影响驾驶员的正常操作而引发交通安全事故。
而计算机视觉检测的方法是通过提取的特征参数主要有眼动特性(眨眼频率,perclos,眼睛睁闭程度,注视方向等),由于面部特征的变化比较明显,且深度学习(dl)在图像处理方面卓越的贡献,使得基于计算机视觉的疲劳检测易达到较好的性能。
然而,目前基于计算机视觉的疲劳检测方法仅仅用眼睛特征或嘴巴特征作为判断依据,默认相机能拍摄到驾驶员清晰正面的脸,目前存在一些难点:(1)有关疲劳检测的数据集相对匮乏;(2)抗干扰性不强:实际行车中可能由于各种因素的影响,使采集的图像出现光照分布不均匀等现象影响疲劳检测;(3)面部朝向以及头部姿态的变化会影响驾驶员脸部图像采集而影响疲劳检测;(4)现有检测系统实时性和准确率都不高。
技术实现要素:
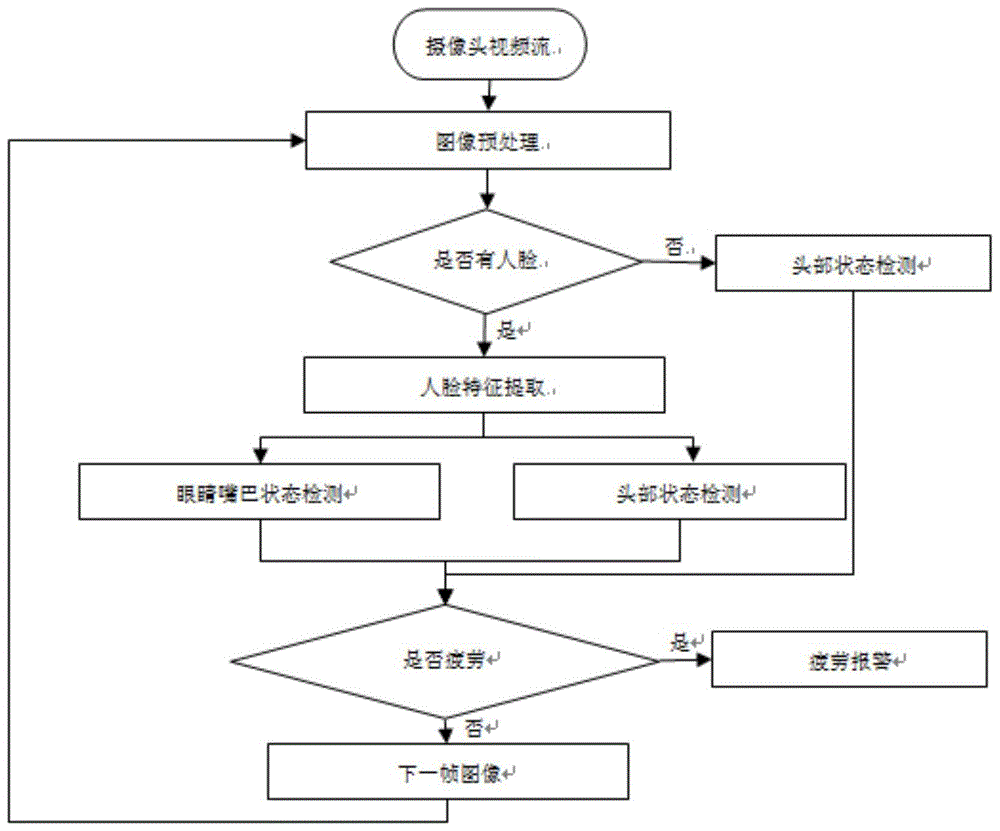
本发明的目的在于针对现有技术的不足之处,提供一种基于深度学习多特征融合的驾驶员疲劳检测方法,包括以下步骤:数据预处理:利用相机、摄像头等采集设备进行连续拍摄,并将得到的图像进行预处理;人脸识别及特征提取:通过多任务级卷积网络模型获得预处理后的图像上的人脸区域及眼睛、嘴巴区域;并行检测:分别进行头部姿态估计、眼睛姿态估计和嘴巴姿态估计;疲劳检测:根据perclos参数、打哈欠参数和点头参数判断是否疲劳,以解决现有技术中抗干扰性不强、面部朝向以及头部姿态的变化会影响驾驶员脸部图像采集而影响疲劳检测等问题。
一种基于深度学习多特征融合的驾驶员疲劳检测方法,包括以下步骤:
1)数据预处理:利用相机、摄像头等采集设备进行连续拍摄,并将得到的图像进行预处理;
2)人脸识别及特征提取:通过多任务级卷积网络模型获得预处理后的图像上的人脸区域及眼睛、嘴巴区域;
3)并行检测:分别进行头部姿态估计、眼睛姿态估计和嘴巴姿态估计;
4)疲劳检测:根据perclos参数、打哈欠参数和点头参数判断是否疲劳。
作为本发明进一步的方案,步骤1)中,所述预处理包括滤波去噪和图像直方图均衡。
作为本发明进一步的方案,步骤2)中,所述眼睛、嘴巴区域包括左眼、右眼、鼻子、左唇端和右唇端。
作为本发明进一步的方案,步骤3)中,所述头部状态估计是将人脸区域输入hopenet模型判断,所述眼睛姿态估计和嘴巴姿态估计是利用浅层卷积神经网络判定眼睛、嘴巴区域。
作为本发明进一步的方案,步骤4)中,所述perclos参数的计算公式为:fper=n/n×100%,其中n是闭眼的帧数,n是帧的总数。
作为本发明进一步的方案,步骤4)中,所述打哈欠参数的计算公式为:fm=n/n,其中,n为统计时间内嘴巴张开状态的总帧数,n为统计时间内的总帧数。
作为本发明进一步的方案,步骤4)中,所述点头参数的计算公式为fn=n/m,其中,n为统计时间内判定为点头状态的总帧数,n为统计时间内的总帧数。
综上所述,本发明与现有技术相比具有以下有益效果:
本发明在大量数据上训练神经网络,避免了实际应用时复杂的图像处理过程;并且在实时性、准确性及鲁棒性上有较好的效果,而且在自己的数据集上达到了99.05%,具有很好的检测性能;另外,对于在光线条件差的情况下,也能准确地提取眼部特征,相比于只检测眼睛的perclos标准的疲劳检测方法,检测点头姿态后,取得了更高的疲劳检测准确率,对于驾驶员疲劳驾驶有较好的检测结果。
附图说明
图1为基于深度学习多特征融合的驾驶员疲劳检测方法的检测流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
由图1所示,一种基于深度学习多特征融合的驾驶员疲劳检测方法,包括以下步骤:
1)数据预处理:利用相机、摄像头等采集设备进行连续拍摄,并将得到的图像进行预处理;
2)人脸识别及特征提取:通过多任务级卷积网络模型获得预处理后的图像上的人脸区域及眼睛、嘴巴区域;
3)并行检测:分别进行头部姿态估计、眼睛姿态估计和嘴巴姿态估计;
4)疲劳检测:根据perclos参数、打哈欠参数和点头参数判断是否疲劳。
进一步的,步骤1)中,所述预处理包括滤波去噪和图像直方图均衡。
在滤波去噪过程中,中值滤波用中心点邻域内的中值来替换中心点的像素值,像素值为0或255的孤立斑点很容易被消除掉,其原理如下所示:
f(x,y)=med(s(x,y))
其中s(x,y)为点(x,y)处的nxn模板(n一般为奇数)邻域内的像素点集,med()表示中值函数,将以像素点(x,y)为中心的邻域中的各个像素点的灰度值由大到小进行排列,输出处于中间位置的像素灰度值f(x,y)表示(x,y)处中值滤波处理后的新像素值。
在图像直方图均衡的过程中,将逐点改变图像的灰度值,尽量使各个灰度级别都具有相同的数量的像素点,使直方图趋于平衡,依照下面的公式进行直方图均衡:
其中n表示图像灰度级,m表示像素点个数,ha(n)是输入图像a(x,y)的直方图,图像b(x,y)是输入图像直方图均衡后的输出。
进一步的,步骤2)中,所述眼睛、嘴巴区域包括左眼、右眼、鼻子、左唇端和右唇端。
多任务级卷积网络模型(mtcnn)由3个网络结构组成(p-net,r-net,o-net):
proposalnetwork(p-net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制来合并高度重叠的候选框;
refinenetwork(r-net):该网络结构通过边界框回归和非极大值抑制来去掉假阳性区域,但是由于该网络结构和p-net网络结构有差异,多了一个全连接层,所以会取得更好的抑制假阳性的作用;
outputnetwork(o-net):该网络结构比r-net网络结构又多了一层卷积层,所以处理的结果会更加精细,作用和r-net网络结构作用相似,但是该网络结构对人脸区域进行了更多的监督,同时还会得到5个坐标,分别代表左眼、右眼、鼻子、左唇端和右唇端。
进一步的,步骤3)中,所述头部状态估计是将人脸区域输入hopenet模型判断,所述眼睛姿态估计和嘴巴姿态估计是利用浅层卷积神经网络判定眼睛、嘴巴区域。
浅层卷积神经网络直接以眼睛或嘴巴的二维图像作为输入,自动学习图像特征及数据内部的隐含关系,具有位移、缩放和扭曲不变性的优点。其结构包括卷积层,池化层、全连接层及softmax分类:
以眼睛状态训练为例,输入图像为rgb彩色,并且将其resize为48*48,在通过6个5*5的卷积核和relu层maxpooling层之后,输出大小为22×22×6,之后,继续通过5*5的卷积核(12个),此层的输出大小为18×18×12,然后,在通过relu层和最大池化之后,输出大小变为9×9×12。之后,将特征图转换为一维向量并馈送到完全连接层,在全连接层中,输入层的长度为972,隐藏层为3层,最后,通过softmax层,输出分为两类:睁开眼睛和闭合眼睛。
hopenet使用resnet50为骨架,后面接上三个全连接层(fc),每个层单独预测,分别预测人脸的欧拉角(yaw,pitch,roll),其中,fc层的全连接数是bin个,也就是将全部-90到+90一共180个数值每三个数分为一组,fc连接数就是60。
对全连接层的结果做softmax分类,把fc的值映射成概率值,所有映射结果相加为1,映射成概率就能很方便求出期望,即网络的输出又被映射到[0,60]这个区间范围内,然后乘以3减去90,这个区间范围就被映射到了[-90,+90]这个区间范围,也就是需要的回归,计算回归的损失值,用的是平方平均误差损失。
与前面分类的交叉损失函数按照一定权重加权求和,然后对最终的loss梯度反向,就完成了整个训练过程。
将人脸图片输入上述训练后的hopenet后,就可以得到人脸姿态方向的三个角度。
引入了lstm网络来抉择是否产生点头行为,通过将上述得到的三个角度作为特征输入网络,网络通过当前帧和当前帧之前的一系列视频帧序列(这里选择15帧)的三个角度值判定当前帧是否在点头过程中,使用的时间网络是具有2个隐藏单元的单个lstm层,接着是新的预测层(跨时间的权重共享)以预测每个帧的点头分数ytd(t=0,1),即判定当前帧是否属于瞌睡点头中的一帧。
进一步的,步骤4)中,所述perclos参数的计算公式为:fper=n/n×100%,其中n是闭眼的帧数,n是帧的总数。
perclos参数可用于量化驾驶员闭眼的程度。
进一步的,步骤4)中,所述打哈欠参数的计算公式为:fm=n/n,其中,n为统计时间内嘴巴张开状态的总帧数,n为统计时间内的总帧数。
当打哈欠的参数值越大,疲劳程度越大。
进一步的,步骤4)中,所述点头参数的计算公式为fn=n/m,其中,n为统计时间内判定为点头状态的总帧数,n为统计时间内的总帧数。
通过perclos参数、打哈欠参数和点头参数设置疲劳阈值,整个系统可用于疲劳检测。
综上所述,本发明的工作原理是:
首先利用采集设备连续拍摄司机,并将得到的图片进行预处理;其次,使用mtcnn获得预处理后的每帧图片的脸部和关键点来提取眼睛嘴巴区域;然后使用sc-net检测每帧眼睛状态和嘴巴状态,同时将人脸图片输入hopenet神经网络获得当前帧人脸姿态的三个角度,并将其输入lstm网络,判断当前帧是否处于瞌睡点头动作区间;最后,根据眼睛嘴巴状态和点头状态的时间序列值,计算瞌睡状态值,如果计算结果超过阈值,系统将提示并警告驾驶员已处于疲劳或瞌睡状态。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
-
 0134350... 来自[中国] 2023年12月18日 20:58找了好多资料,终于找到了合适的
0134350... 来自[中国] 2023年12月18日 20:58找了好多资料,终于找到了合适的