基于车载数字人的交互方法及装置、存储介质与流程
本公开涉及增强现实领域,尤其涉及一种基于车载数字人的交互方法及装置、存储介质。
背景技术:
目前,可以在车内放置机器人,在人员进入车内后,通过机器人与车内人员进行交互。但是机器人与车内人员的交互模式比较固定,缺少人性化。
技术实现要素:
本公开提供了一种基于车载数字人的交互方法及装置、存储介质。
根据本公开实施例的第一方面,提供一种基于车载数字人的交互方法,所述方法包括:
根据本公开实施例的第一方面,提供一种基于车载数字人的交互方法,所述方法包括:获取车载摄像头采集的车内人员的视频流;对所述视频流包括的至少一帧图像进行预定任务处理,得到任务处理结果;根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括以下至少之一:人脸检测、视线检测、注视区域检测、人脸识别、人体检测、手势检测、人脸属性检测、情绪状态检测、疲劳状态检测、分心状态检测、危险动作检测;和/或,
所述车内人员包括以下至少之一:驾驶员、乘客;和/或,
所述数字人输出的交互反馈信息包括以下至少之一:语音反馈信息、表情反馈信息、动作反馈信息。
在一些可选实施例中,所述根据所述任务处理结果,控制车载显示设备上显示的数字人输出交互反馈信息,包括:获取预定任务的任务处理结果和交互反馈指令之间的映射关系;根据所述映射关系确定与所述任务处理结果对应的交互反馈指令;控制所述数字人输出与确定的所述交互反馈指令对应的交互反馈信息。
在一些可选实施例中,所述预定任务包括人脸识别;所述任务处理结果包括人脸识别结果;所述根据所述任务处理结果,在车载显示设备上显示数字人,包括以下至少之一:响应于所述车载显示设备中存储有与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示所述第一数字人;响应于所述车载显示设备中未存储与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示第二数字人或输出用于生成与所述人脸识别结果对应的第一数字人的提示信息。
在一些可选实施例中,所述在所述车载显示设备上显示第二数字人或输出用于生成与所述人脸识别结果对应的第一数字人的提示信息,包括:在所述车载显示设备上输出人脸图像的图像采集提示信息;所述方法还包括:获取人脸图像;对所述人脸图像进行人脸属性分析,获得所述人脸图像所包括的目标人脸属性参数;根据预存的人脸属性参数和数字人形象模版之间的对应关系,确定与所述目标人脸属性参数对应的目标数字人形象模版;根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人,包括:将所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人,包括:获取所述目标数字人形象模版的调整信息;根据所述调整信息调整所述目标数字人形象模版;将调整后的所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述获取人脸图像,包括:获取所述车载摄像头采集的人脸图像;或获取上传的所述人脸图像。
在一些可选实施例中,所述预定任务包括视线检测;
所述任务处理结果包括视线方向检测结果;
所述根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息,包括以下至少之一:响应于所述视线方向检测结果表示所述车内人员的视线指向所述车载显示设备,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括注视区域检测;所述任务处理结果包括注视区域检测结果;所述根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息,包括以下至少之一:响应于所述注视区域检测结果表示所述车内人员的注视区域与所述车载显示设备的设置区域至少部分重叠,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述车内人员包括驾驶员;对所述视频流包括的至少一帧图像进行注视区域检测处理,得到所述注视区域检测结果,包括:根据所述视频包括的所述至少一帧位于驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,其中,每帧脸部图像的注视区域属于预先对车进行空间区域划分得到的多类定义注视区域之一。
在一些可选实施例中,所述预先对所述车进行空间区域划分得到的多类定义注视区域,包括以下二类或二类以上:左前挡风玻璃区域、右前挡风玻璃区域、仪表盘区域、车内后视镜区域、中控台区域、左后视镜区域、右后视镜区域、遮光板区域、换挡杆区域、方向盘下方区域、副驾驶区域、副驾驶前方的杂物箱区域、车载显示区域。
在一些可选实施例中,所述根据所述视频包括的所述至少一帧位于所述驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,包括:对所述视频包括的多帧位于所述驾驶区域的驾驶员的脸部图像进行视线和/或头部姿态检测;根据每帧脸部图像的视线和/或头部姿态的检测结果,确定每帧脸部图像中所述驾驶员的注视区域的类别。
在一些可选实施例中,所述根据所述视频包括的所述至少一帧位于所述驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,包括:将多帧所述脸部图像分别输入神经网络并经所述神经网络分别输出每帧脸部图像中所述驾驶员的注视区域的类别,其中:所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集预先训练完成,或者,所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集以及基于所述人脸图像集中各人脸图像截取的眼部图像预先训练完成;所述注视区域类别标注信息包括所述多类定义注视区域之一。
在一些可选实施例中,所述神经网络的训练方法包括:获取所述人脸图像集中包括有注视区域类别标注信息的人脸图像;截取所述人脸图像中的至少一眼的眼部图像,所述至少一眼包括左眼和/或右眼;分别提取所述人脸图像的第一特征和至少一眼的眼部图像的第二特征;融合所述第一特征和所述第二特征,得到第三特征;根据所述第三特征确定所述人脸图像的注视区域类别检测结果;根据所述注视区域类别检测结果和所述注视区域类别标注信息的差异,调整所述神经网络的网络参数。
在一些可选实施例中,所述方法还包括:生成与所述交互反馈信息对应的车辆控制指令;控制所述车辆控制指令对应的车载设备执行所述车辆控制指令所指示的操作。
在一些可选实施例中,所述交互反馈信息中包括用于缓解所述车内人员的疲劳或分心程度的信息内容;所述生成与所述交互反馈信息对应的车辆控制指令,包括:生成触发目标车载设备的所述车辆控制指令;其中,所述目标车载设备包括通过味觉、嗅觉和听觉中的至少一项缓解所述车内人员疲劳或分心程度的车载设备;和/或生成触发辅助驾驶的车辆控制指令。
在一些可选实施例中,所述交互反馈信息中包括对手势检测结果的确认内容;所述生成与所述交互反馈信息对应的车辆控制指令,包括:根据手势与车辆控制指令之间的映射关系,生成所述手势检测结果所指示的手势对应的所述车辆控制指令。
在一些可选实施例中,所述方法还包括:获取车载语音采集设备所采集的所述车内人员的音频信息;对所述音频信息进行语音识别,得到语音识别结果;根据所述语音识别结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
根据本公开实施例的第二方面,提供一种基于车载数字人的交互装置,所述装置包括:第一获取模块,用于获取车载摄像头采集的车内人员的视频流;任务处理模块,用于对所述视频流包括的至少一帧图像进行预定任务处理,得到任务处理结果;第一交互模块,用于根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括以下至少之一:人脸检测、视线检测、注视区域检测、人脸识别、人体检测、手势检测、人脸属性检测、情绪状态检测、疲劳状态检测、分心状态检测、危险动作检测;和/或,所述车内人员包括以下至少之一:驾驶员、乘客;和/或,所述数字人输出的交互反馈信息包括以下至少之一:语音反馈信息、表情反馈信息、动作反馈信息。
在一些可选实施例中,所述第一交互模块包括:第一获取子模块,用于获取预定任务的任务处理结果和交互反馈指令之间的映射关系;确定子模块,用于根据所述映射关系确定与所述任务处理结果对应的交互反馈指令;控制子模块,用于控制所述数字人输出与确定的所述交互反馈指令对应的交互反馈信息。
在一些可选实施例中,所述预定任务包括人脸识别;所述任务处理结果包括人脸识别结果;所述第一交互模块包括以下至少之一:第一显示子模块,用于响应于所述车载显示设备中存储有与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示所述第一数字人;第二显示子模块,用于响应于所述车载显示设备中未存储与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示第二数字人或输出用于生成与所述人脸识别结果对应的第一数字人的提示信息。
在一些可选实施例中,所述第二显示子模块包括:显示单元,用于在所述车载显示设备上输出人脸图像的图像采集提示信息;所述装置还包括:第二获取模块,用于获取人脸图像;人脸属性分析模块,用于对所述人脸图像进行人脸属性分析,获得所述人脸图像所包括的目标人脸属性参数;模板确定模块,用于根据预存的人脸属性参数和数字人形象模版之间的对应关系,确定与所述目标人脸属性参数对应的目标数字人形象模版;数字人生成模块,用于根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述数字人生成模块包括:第一存储子模块,用于将所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述数字人生成模块包括:第二获取子模块,用于获取所述目标数字人形象模版的调整信息;调整子模块,用于根据所述调整信息调整所述目标数字人形象模版;第二存储子模块,用于将调整后的所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述第二获取模块包括:第三获取子模块,用于获取所述车载摄像头采集的人脸图像;或第四获取子模块,用于获取上传的所述人脸图像。
在一些可选实施例中,所述预定任务包括视线检测;所述任务处理结果包括视线方向检测结果;所述第一交互模块包括以下至少之一:第三显示子模块,用于响应于所述视线方向检测结果表示所述车内人员的视线指向所述车载显示设备,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括注视区域检测;所述任务处理结果包括注视区域检测结果;所述第一交互模块包括以下至少之一:第四显示子模块,用于响应于所述注视区域检测结果表示所述车内人员的注视区域与所述车载显示设备的设置区域至少部分重叠,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述车内人员包括驾驶员;所述第一交互模块包括:类别确定子模块,用于根据所述视频包括的所述至少一帧位于驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,其中,每帧脸部图像的注视区域属于预先对车进行空间区域划分得到的多类定义注视区域之一。
在一些可选实施例中,所述预先对所述车进行空间区域划分得到的多类定义注视区域,包括以下二类或二类以上:左前挡风玻璃区域、右前挡风玻璃区域、仪表盘区域、车内后视镜区域、中控台区域、左后视镜区域、右后视镜区域、遮光板区域、换挡杆区域、方向盘下方区域、副驾驶区域、副驾驶前方的杂物箱区域、车载显示区域。
在一些可选实施例中,所述类别确定子模块包括:第一检测单元,用于对所述视频包括的多帧位于所述驾驶区域的驾驶员的脸部图像进行视线和/或头部姿态检测;类别确定单元,用于根据每帧脸部图像的视线和/或头部姿态的检测结果,确定每帧脸部图像中所述驾驶员的注视区域的类别。
在一些可选实施例中,所述类别确定子模块包括:输入单元,用于将多帧所述脸部图像分别输入神经网络并经所述神经网络分别输出每帧脸部图像中所述驾驶员的注视区域的类别,其中:所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集预先训练完成,或者,所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集以及基于所述人脸图像集中各人脸图像截取的眼部图像预先训练完成;所述注视区域类别标注信息包括所述多类定义注视区域之一。
在一些可选实施例中,所述装置还包括:第三获取模块,用于获取所述人脸图像集中包括有注视区域类别标注信息的人脸图像;截取模块,用于截取所述人脸图像中的至少一眼的眼部图像,所述至少一眼包括左眼和/或右眼;特征提取模块,用于分别提取所述人脸图像的第一特征和至少一眼的眼部图像的第二特征;融合模块,用于融合所述第一特征和所述第二特征,得到第三特征;检测结果确定模块,用于根据所述第三特征确定所述人脸图像的注视区域类别检测结果;参数调整模块,用于根据所述注视区域类别检测结果和所述注视区域类别标注信息的差异,调整所述神经网络的网络参数。
在一些可选实施例中,所述装置还包括:车辆控制指令生成模块,用于生成与所述交互反馈信息对应的车辆控制指令;控制模块,用于控制所述车辆控制指令对应的车载设备执行所述车辆控制指令所指示的操作。
在一些可选实施例中,所述交互反馈信息中包括用于缓解所述车内人员的疲劳或分心程度的信息内容;所述车辆控制指令生成模块包括:第一生成子模块,用于生成触发目标车载设备的所述车辆控制指令;其中,所述目标车载设备包括通过味觉、嗅觉和听觉中的至少一项缓解所述车内人员疲劳或分心程度的车载设备;和/或第二生成子模块,用于生成触发辅助驾驶的车辆控制指令。
在一些可选实施例中,所述交互反馈信息中包括对手势检测结果的确认内容;所述车辆控制指令生成模块包括:第三生成子模块,用于根据手势与车辆控制指令之间的映射关系,生成所述手势检测结果所指示的手势对应的所述车辆控制指令。
在一些可选实施例中,所述装置还包括:第四获取模块,用于获取车载语音采集设备所采集的所述车内人员的音频信息;语音识别模块,用于对所述音频信息进行语音识别,得到语音识别结果;第二交互模块,用于根据所述语音识别结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
根据本公开实施例的第三方面,提供一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序用于执行上述第一方面任一所述的基于车载数字人的交互方法。
根据本公开实施例的第四方面,提供一种基于车载数字人的交互装置,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为调用所述存储器中存储的可执行指令,实现第一方面中任一项所述的基于车载数字人的交互方法。
本公开的实施例提供的技术方案可以包括以下有益效果:
本公开实施例中,通过对车内人员的视频流的图像分析,获得视频流的预定任务处理的任务处理结果。根据任务处理结果,自动触发虚拟的数字人的显示或交互反馈,从而使得人机交互的方式更加符合人的交互习惯,交互过更加自然,让人感受到人机交互的温暖,提升乘车乐趣、舒适感和陪护感,有利于降低驾驶的安全风险。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1是本公开根据一示例性实施例示出的一种基于车载数字人的交互方法流程图;
图2是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图3是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图4是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图5a至5b是本公开根据一示例性实施例示出的调整目标数字人形象模版的场景示意图;
图6是本公开根据一示例性实施例示出的一种对车进行空间划分得到的多类定义注视区域示意图;
图7是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图8是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图9是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图10是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图11a至11b是本公开根据一示例性实施例示出的手势示意图;
图12a至12c是本公开根据一示例性实施例示出的基于车载数字人的交互场景示意图;
图13是本公开根据一示例性实施例示出的另一种基于车载数字人的交互方法流程图;
图14是本公开根据一示例性实施例示出的一种基于车载数字人的交互装置框图;
图15是本公开根据一示例性实施例示出的一种基于车载数字人的交互装置的硬件结构示意图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
在本公开运行的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开。在本公开和所附权利要求书中所运行的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中运行的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本公开可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本公开范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所运行的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
本公开实施例提供了一种设备控制方法,可以用于可驾驶的机器设备,例如智能车辆、模拟车辆驾驶的智能车舱等。
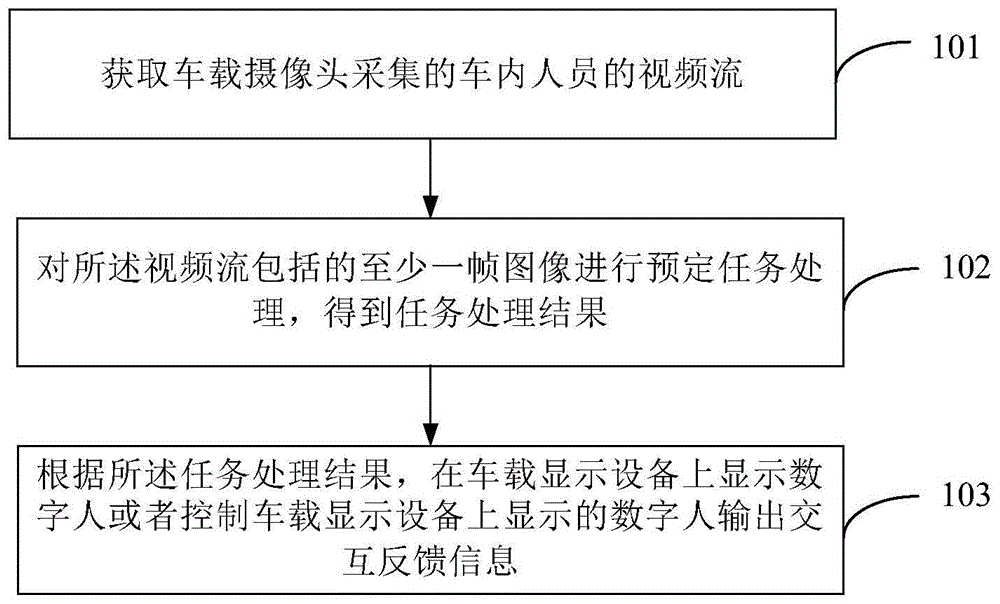
如图1所示,图1是根据一示例性实施例示出的一种基于车载数字人的交互方法,包括以下步骤:
在步骤101中,获取车载摄像头采集的车内人员的视频流。
在本公开实施例中,车载摄像头可以设置在中控台上、前风挡玻璃上、或者其他可以拍摄到车内人员的任意位置。车内人员包括驾驶员和/或乘客。通过该车载摄像头可以实时采集车内人员的视频流。
在步骤102中,对所述视频流包括的至少一帧图像进行预定任务处理,得到任务处理结果。
在步骤103中,根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在本公开实施例中,所述数字人可以是通过软件生成的虚拟形象,且可以在车载显示设备,例如中控显示屏或车载平板设备上显示该数字人。数字人输出的交互反馈信息包括以下至少之一:语音反馈信息、表情反馈信息、动作反馈信息。
上述实施例中,通过对车内人员的视频流的图像分析,获得视频流的预定任务处理的任务处理结果。根据任务处理结果,自动触发虚拟的数字人的显示或交互反馈,从而使得人机交互的方式更加符合人的交互习惯,交互过更加自然,让人感受到人机交互的温暖,提升乘车乐趣、舒适感和陪护感,有利于降低驾驶的安全风险。
在一些可选实施例中,需对视频流进行处理的预定任务可以包括但不限于以下至少之一:人脸检测、视线检测、注视区域检测、人脸识别、人体检测、手势检测、人脸属性检测、情绪状态检测、疲劳状态检测、分心状态检测、危险动作检测。根据预定任务的任务处理结果来确定基于车载数字人的人机交互方式,例如,根据任务处理结果确定是否需要触发在车载显示设备上显示数字人,或者,根据任务处理结果确定是否需要控制车载显示设备上显示的数字人输出相应的交互反馈信息等。
一个示例中,对视频流包括的至少一帧图像进行人脸检测,检测车内是否包括人脸,获得该视频流包括的至少一帧图像是否包括人脸的人脸检测结果,后续可以根据人脸检测结果判断车内是否有人员进入或离开,进而确定是否显示数字人或者是否控制数字人做出相应的交互反馈信息。例如,当人脸检测结果表示刚刚检测到人脸时,可在车载显示设备上自动显示数字人,还可以控制数字人发出“你好”等问候的语言、表情或动作。
另一个示例中,对至少一帧图像进行视线检测或注视区域检测,从而获得车内人员的视线注视方向检测结果或注视区域检测结果。后续可以根据视线注视方向检测结果或注视区域检测结果,后续来确定是否显示数字人或控制数字人输出交互反馈信息。例如,当车内人员的视线注视方向指向车载显示设备时,可以显示数字人。当车内人员的注视区域与车载显示设备的设置区域至少部分重叠时,显示数字人。当车内人员的视线注视方向再次指向车载显示设备,或注视区域与车载显示设备的设置区域再次至少部分重叠时,可以让数字人发出“需要我做些什么”的语言、表情或动作。
另一个示例中,对至少一帧图像进行人脸识别,从而获得人脸识别结果,后续可以显示人脸识别结果对应的数字人。例如人脸识别结果与预存的张三的人脸匹配,则可以在车载显示设备上显示张三对应的数字人,人脸识别结果与预存的李四的人脸匹配,则可以在车载显示设备上显示李四对应的数字人,张三和李四各自对应的数字人可以不同,从而丰富数字人的形象,提升乘车乐趣、舒适感和陪护感,让人感受到人机交互的温暖。。
再例如,数字人可以通过输出语音反馈信息,“你好,张三或李四”,或者输出张三预设的一些表情或动作等。
另一个示例中,对视频流包括的至少一帧图像进行人体检测,包括但不限于坐姿、手部和/或腿部动作、头部位置等等,获得人体检测结果。后续可以根据人体检测结果显示数字人或控制数字人输出交互反馈信息。例如,人体检测结果为坐姿适宜开车,则可以显示数字人,如果人体检测结果为坐姿不适宜开车,可以控制数字人输出“放松点,坐的舒服点”的语音、表情或动作。
另一个示例中,对至少一帧图像进行手势检测,获得手势识别结果,从而可以根据手势识别结果确定车内人员输入了何种手势。例如车内人员输入了ok的手势或者棒的手势等,后续可以根据输入的手势显示数字人或控制数字人输出与手势对应的交互反馈信息。例如,手势检测结果为车内人员输入了问好的手势,则可以显示数字人。或者手势检测结果为车内人员输入了棒的手势,则可以控制数字人输出“谢谢夸奖”的语音、表情或动作。
另一个示例中,对至少一帧图像进行人脸属性检测,人脸属性包括但不限于是否是双眼皮、是否戴眼镜、是否有胡子,胡子的位置、耳朵形状、嘴唇形状、脸型、发型等等,获得车内人员的人脸属性检测结果。后续可以根据人脸属性检测结果显示数字人或控制数字人输出与人脸属性检测结果对应的交互反馈信息,例如人脸属性检测结果指示佩戴了墨镜,数字人可以输出“这墨镜挺好看”、“今天的发型不错”、“你今天真漂亮”等交互反馈信息的语音、表情或动作。
另一个示例中,通过对视频流包括的至少一帧图像进行情绪状态检测,获得情绪状态检测结果,该情绪状态检测结果直接反映了车内人员的情绪,例如高兴、愤怒、伤心等等。后续可以根据车内人员的情绪显示数字人,例如车内人员微笑时,显示数字人,或者可以根据车内人员情绪控制数字人输出对应的缓解情绪的交互反馈信息,例如车内人员的情绪为愤怒,则可以让数字人输出“别生气,我给你讲个笑话”、“今天有什么高兴或不开心的事情吗?”的语音、表情或动作。
另一个示例中,对至少一帧图像进行疲劳状态分析,获得疲劳程度检测结果,例如不疲劳、轻微疲劳还是重度疲劳等。根据疲劳程度可以让数字人输出相应的交互反馈信息。例如,疲劳程度为轻微疲劳,则数字人可以输出“我给你唱歌吧”、“需不需要休息一下”的语音、表情或动作来缓解疲劳。
另一个示例中,在对至少一帧图像进行分心状态检测时,可以获得分析状态检测结果,例如通过对至少一帧图像上车内人员的视线是否注视前方,来确定目前是否分心。根据分心状态检测结果,可以控制数字人输出“专心点”、“做得好,继续保持”等语音、表情或动作。
另一个示例中,还可以对至少一帧图像进行危险动作检测,获得车内人员当前是否进行危险动作的检测结果。例如驾驶员双手均未处于方向盘上、驾驶员未注视前方、乘客身体的部分置于车窗外等均属于危险动作。根据危险动作检测,可以控制数字人输出“请不要将身体伸出车窗”、“请注视前方”等语音、表情或动作。
在本公开实施例中,数字人可以通过语音与车内人员进行聊天交互,或者通过表情与车内人员互动,或者还可以通过一些预设的动作为车内人员提供陪伴。
上述实施例中,通过对车内人员的视频流的图像分析,获得视频流的预定任务处理的任务处理结果。根据任务处理结果,自动触发虚拟的数字人的显示或交互反馈,从而使得人机交互的方式更加符合人的交互习惯,交互过更加自然,让人感受到人机交互的温暖,提升乘车乐趣、舒适感和陪护感,有利于降低驾驶的安全风险。
在一些可选实施例中,上述步骤103例如图2所示,包括:
在步骤103-1中,获取预定任务的任务处理结果和交互反馈指令之间的映射关系。
在本公开实施例中,数字人可以获取车辆处理器中预存的预定任务的任务处理结果和交互反馈指令之间的映射关系。
在步骤103-2中,根据所述映射关系确定与所述任务处理结果对应的交互反馈指令。
数字人可以根据上述映射关系,来确定与不同任务处理结果对应的交互反馈指令。
在步骤103-3中,控制所述数字人输出与确定的所述交互反馈指令对应的交互反馈信息。
在一示例中,人脸检测结果对应的交互反馈指令为欢迎指令,相应地交互反馈信息为欢迎的语音、表情或动作。
在另一示例中,视线注视检测结果或注视区域检测结果对应的交互反馈指令为显示数字人指令或输出问好的指令。相应地,交互反馈信息可以为“你好”的语音、表情或动作。
在另一示例中,人体检测结果对应的交互反馈指令可以是提示调整坐姿、调整身体方向的提示指令。交互反馈信息为“可以调整一下坐姿,做的舒服点”的语音、表情或动作。
上述实施例中,数字人可以根据获取到的预定任务的任务处理结果和交互反馈指令之间的映射关系,输出所述交互反馈指令对应的交互反馈信息,在车内封闭的空间中,提供更加人性化的沟通和交互模式,提高了沟通的互动性,增加了车主对车机信任感,从而提升了驾驶乐趣与效率,降低安全风险,使得行车过程不再缺少孤独感,提高了车载数字人的人工智能化程度。
在一些可选实施例中,预定任务包括人脸识别,则相应地,任务处理结果包括人脸识别结果。
步骤103可以包括以下至少之一:
在步骤103-4中,响应于所述车载显示设备中存储有与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示所述第一数字人。
在本公开实施例中,人脸识别结果已经识别出该车内人员的身份,例如为张三,车载显示设备中如果存储了张三对应的第一数字人,那么可以直接在车载显示设备上显示这个第一数字人。例如张三对应的第一数字人是阿凡达,则可以显示阿凡达。
在步骤103-5中,响应于所述车载显示设备中未存储与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示第二数字人或输出用于生成与所述人脸识别结果对应的第一数字人的提示信息。
在本公开实施例中,车载显示设备中如果未存储与所述人脸识别结果对应的第一数字人,那么车载显示设备可以显示默认设置的第二数字人,例如美颜设置过第一数字人的人员,车载显示设备均显示默认的第二数字人,假设为机器猫。
或者可以输出用于生成与所述人脸识别结果对应的第一数字人的提示信息。通过提示信息提示车内人员设置第一数字人。
上述实施例中,可以根据人脸识别结果,显示与人脸识别结果对应的第一数字人,或第二数字人,或者让车内人员设置第一数字人。使得数字人的形象更丰富,在行车过程中由车内人员设置的数字人陪伴,减少孤独感,提高了驾驶乐趣。
在一些可选实施例中,步骤103-5包括:
在所述车载显示设备上输出人脸图像的图像采集提示信息。
相应地,上述步骤如图3所示,还可以包括:
在步骤104中,获取人脸图像。
在本公开实施例中,可以车载摄像头实时采集的车内人员的人脸图像。或者可以由车内人员通过自身携带的终端上传一张人脸图像。
在步骤105中,对所述人脸图像进行人脸属性分析,获得所述人脸图像所包括的目标人脸属性参数。
在本公开实施例中,可以预先建立人脸属性分析模型,该人脸属性分析模型可以采用但不限于神经网络中的resnet(residualnetwork,残差网络)。该神经网络可以包括至少一个卷积层、bn(batchnormalization,批量归一化)层、分类输出层等。
将带标签的样本图片库输入神经网络,获得分类器输出的人脸属性分析结果。其中,人脸属性包括但不限于五官、发型、眼镜、服饰、是否带帽子等。人脸属性分析结果可以包括多个人脸属性参数,例如是否有胡子、胡子所在位置、是否带眼镜、眼镜种类、镜框类型、镜片形状、镜框粗细、发型、以及眼皮的类型(例如,单眼皮、内双还是外双眼皮等)、服饰类型、是否有衣领等。根据该神经网络输出的人脸属性分析结果调整该神经网络的参数,例如卷积层、bn层、分类输出层的参数,或者整个神经网络的学习率等,使得最终输出的人脸属性分析结果与样本图片库中标签内容符合预设容错差异甚至一致,最终完成对神经网络的训练,从而得到人脸属性分析模型。
在本公开实施例中,可以将至少一帧图像直接输入上述人脸属性分析模型,获得该人脸属性分析模型输出的目标人脸属性参数。
在步骤106中,根据预存的人脸属性参数和数字人形象模版之间的对应关系,确定与所述目标人脸属性参数对应的目标数字人形象模版。
在本公开实施例中,预存了人脸属性擦书和虚拟头像模板之间的对应关系,因此可以根据目标人脸属性参数确定对应的目标虚拟头像模板。
在步骤107中,根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人。
在本公开实施例中,可以根据确定出的目标数字人形象模板,生成车内人员匹配的第一数字人。可以直接将目标数字人形象模板作为第一数字人,还可以由车内人员对目标数字人形象模板进行调整,将调整后的形象作为第一数字人。
在上述实施例中,可以基于车载显示设备输出的图像采集提示信息,获取人脸图像,进而对人脸图像进行人脸属性分析,确定目标数字人形象模板,从而生成与所述车内人员匹配的所述第一数字人,通过上述过程,可以让车内用户自己设置匹配的第一数字人,在行车过程中可以由用户自己diy的第一数字人始终陪伴,减少行车过程的孤独感,丰富了第一数字人的形象。
在一些可选实施例中,上述步骤107可以包括:
在步骤107-1中,将所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在本公开实施例中,可以直接将目标数字人形象模板存储为与车内人员匹配的所述第一数字人。
上述实施例中,可以直接将目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人,实现了车内人员自己diy喜欢的第一数字人的目的。
在一些可选实施例中,上述步骤107例如图4所示,可以包括:
在步骤107-2中,获取所述目标数字人形象模版的调整信息。
在本公开实施例中,确定了目标数字人形象模板之后,还可以获取车内人员输入的调整信息,例如目标数字人形象模板上的发型为短发,调整信息为长卷发。或者目标数字人形象模板上没有眼镜,调整信息为添加墨镜。
在步骤107-3中,根据所述调整信息调整所述目标数字人形象模版。
例如,图5a所示,通过车载摄像头采集人脸图像,然后车内人员可以根据生成的目标数字人形象模板自己diy发型、脸型、五官等,例如图5b所示在步骤107-4中,将调整后的所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在本公开实施例中,可以将调整后的目标数字人形象模版存储为该车内人员匹配的第一数字人,下次再检测到该车内人员后,可以输出调整后的目标数字人形象模版。
上述实施例中,可以对目标数字人形象模板根据车内人员喜好进行调整,最终得到车内人员喜欢的调整后的第一数字人,丰富了第一数字人的形象,实现了车内人员自己diy第一数字人的目的。
在一些可选实施例中,上述步骤104可以包括以下任一项:
在步骤104-1中,获取所述车载摄像头采集的人脸图像。
在本公开实施例中,可以通过车载摄像头直接实时采集人脸图像。
在步骤104-2中,获取上传的所述人脸图像。
在本公开实施例中,可以由车内人员上传自己喜欢的一张人脸图像,这张人脸图像可以是车内人员自己人脸对应的人脸图像,也可以是车内人员喜欢的人、动物、卡通形象对应的人脸图像。
上述实施例中,可以获取车载摄像头采集的人脸图像,也可以获取上传的人脸图像,从而在后续根据人脸图像生成对应的第一数字人,实现简便,可用性高,提升了用户体验。
在一些可选实施例中,预定任务包括视线检测,那么相应地,任务处理结果包括视线方向检测结果。
上述步骤103可以包括以下至少之一:
在步骤103-6中,响应于所述视线方向检测结果表示所述车内人员的视线指向所述车载显示设备,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在本公开实施例中,预先建立了视线方向检测模型,该视线方向检测模型可以采用神经网络,例如resnet(residualnetwork,残差网络)、googlenet、vgg(visualgeometrygroupnetwork,视觉几何群网络)等。该神经网络可以包括至少一个卷积层、bn(batchnormalization,批量归一化)层、分类输出层等。
可以将带标签的样本图片库输入神经网络,获得分类器输出的视线方向分析结果。其中,视线方向分析结果包括但不限于视线注视的任一车载设备所在的方向。
在本公开实施例中,可以将至少一帧图像输入预先建立的上述视线方向检测模型,由该视线方向检测模型输出结果。如果视线方向检测结果表示所述车内人员的视线指向所述车载显示设备,那么可以在车载显示设备上显示数字人。
例如,人员进入车内后,可以通过视线注视召唤对应的数字人,如图6所示,该数字人是之前根据该人员的人脸图像设置的。
或者视线方向检测结果表示所述车内人员的视线指向所述车载显示设备时,还可以控制车载显示设备上显示的数字人输出交互反馈信息。
例如,控制数字人通过语音、表情和动作中的至少一项向车内人员打招呼等。
在一些可选实施例中,预定任务包括注视区域检测,相应地,任务处理结果包括注视区域检测结果。
上述步骤103包括以下至少之一:
在步骤103-7中,响应于所述注视区域检测结果表示所述车内人员的注视区域与所述车载显示设备的设置区域至少部分重叠,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在本公开实施例中,可以预先建立的神经网络,该神经网络可以对注视区域进行分析,获得注视区域检测结果,响应于所述注视区域检测结果表示所述车内人员的注视区域与所述车载显示设备的设置区域至少部分重叠,那么可以在车载显示设备上显示数字人。即通过对车内人员的注视区域的检测,可以起到数字人。
或者还可以控制车载显示设备上显示的数字人输出交互反馈信息。例如,控制数字人通过语音、表情和动作中的至少一项向车内人员打招呼等。
上述实施例中,车内人员可以通过将视线转向车载显示设备,通过检测视线方向或注视区域来启动数字人,或让数字人输出交互反馈信息,提高了车载数字人的人工智能化程度。
在一些可选实施例中,车内人员包括了驾驶员,那么步骤103可以为:对所述视频流包括的至少一帧图像进行注视区域检测处理,得到所述注视区域检测结果,包括:
在步骤103-8中,根据所述视频包括的所述至少一帧位于驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,其中,每帧脸部图像的注视区域属于预先对车进行空间区域划分得到的多类定义注视区域之一。
在本公开实施例中,驾驶员的脸部图像可以包括驾驶员的整个头部,也可以是包括驾驶员的脸部轮廓以及五官;可以将视频中的任意帧图像作为驾驶员的脸部图像,也可以从视频中任意帧图像中检测出驾驶员的脸部区域图像,并将该脸部区域图像作为驾驶员的脸部图像,上述检测驾驶员脸部区域图像的方式可以是任意人脸检测算法,本公开对此不做具体限定。
在本公开实施例中,通过将车辆室内空间和/或车辆的室外空间划分得到的多个不同的区域,得到不同类别的注视区域,举例来说,图6为本公开提供的一种注视区域的类别的划分方式,如图6所示,预先对车辆进行空间区域划分得到多类注视区域,包括以下二类或二类以上:左前挡风玻璃区域(1号注视区域)、右前挡风玻璃区域(2号注视区域)、仪表盘区域(3号注视区域)、车内后视镜区域(4号注视区域)、中控台区域(5号注视区域)、左后视镜区域(6号注视区域)、右后视镜区域(7号注视区域)、遮光板区域(8号注视区域)、换挡杆区域(9号注视区域)、方向盘下方区域(10号注视区域)、副驾驶区域(11号注视区域)、副驾驶前方的杂物箱区域(12号注视区域)。其中,车载显示区域可以复用中控台区域(5号注视区域)。
采用该方式进行车空间区域的划分,有利于针对性的进行驾驶员的注意力监测;上述方式充分考虑了驾驶员处于驾驶状态时注意力可能落到的各种区域,有利于实现对驾驶员车前向针对性或车前向全空间的注意力监测,由此提高驾驶员注意力监测的准确度和精度。
需要理解的是,由于不同车型的车的空间分布不一样,可根据车型对注视区域的类别进行划分,例如:图6中的驾驶室在车的左侧,正常驾驶时,驾驶员的视线大部分时间在左前挡风玻璃区域,而对于驾驶室在车的右侧的车型,正常驾驶时,驾驶员的视线大部分时间在右前挡风玻璃区域,显然,注视区域的类别的划分应不同于图6中注视区域的类别的划分;此外,还可根据用户的个人喜好对注视区域的类别进行划分,例如:用户觉得中控台的屏幕面积太小,偏好通过屏幕面积更大的终端来控制空调、音响等舒适装置,此时,可根据终端的摆放位置调整注视区域中的中控台区域。还可根据具体情况以其他方式对注视区域的类别的进行划分,本公开对注视区域的类别的划分方式不做限定。
眼睛是驾驶员获取路况信息的主要感觉器官,而驾驶员的视线所在的区域在很大程度上反映了驾驶员的注意力状况,通过对视频包括的多帧位于驾驶区域的驾驶员的脸部图像进行处理,可确定每帧脸部图像中驾驶员的注视区域的类别,进而实现对驾驶员注意力的监测。在一些可能实现的方式中,对驾驶员的脸部图像进行处理,得到脸部图像中驾驶员的视线方向,并根据预先设定的视线方向与注视区域的类别的映射关系,确定脸部图像中驾驶员的注视区域的类别。在另一些可能实现的方式中,对驾驶员的脸部图像进行特征提取处理,根据提取出的特征确定脸部图像中驾驶员的注视区域的类别,一种可选示例中,得到的注视区域的类别为各注视区域对应的预定编号。
在一些可选实施例中,上述步骤103-8例如图7所示,可以包括:
在步骤103-81中,对所述视频包括的多帧位于所述驾驶区域的驾驶员的脸部图像进行视线和/或头部姿态检测。
在本公开实施例中,视线和/或头部姿态检测包括:视线检测、头部姿态检测、视线检测和头部姿态检测。
通过预先训练好的神经网络对驾驶员的脸部图像进行视线检测和头部姿态检测,可得到视线信息和/或头部姿态信息,其中,视线信息包括视线以及视线的起点位置,在一种可能实现的方式中,通过对驾驶员的脸部图像依次进行卷积处理、归一化处理、线性变换,得到视线信息和/或头部姿态信息。
还可以对驾驶员的脸部图像依次进行驾驶员脸部确认、确定眼部区域、确定虹膜中心,实现视线检测并确定视线信息。在一些可能实现的方式中,人在平视或者仰视时眼的轮廓比俯视时要大,因此首先根据预先测量的眼眶的大小,将俯视与平视和仰视区分开。然后利用向上看和平视时,上眼眶到眼睛中心的距离比值的不同,区分开向上看和平视;然后再处理向左、中、右看的问题。计算出所有瞳孔点到眼眶左边缘的距离的平方和及右边缘的距离的平方和的比值,根据该比值确定向左、中、右看时的视线信息。
还可以通过对驾驶员的脸部图像进行处理,确定驾驶员的头部姿态。在一些可能实现的方式中,对驾驶员的脸部图像进行面部特征点(如:嘴、鼻子、眼睛)提取,并基于提取出的面部特征点确定脸部图像中面部特征点的位置,再根据面部特征点与头部之间的相对位置,确定脸部图像中的驾驶员的头部姿态。
此外,还可同时对视线和头部姿态进行检测,提高检测精度。在一些可能实现的方式中,通过车辆上部署的摄像头采集眼部运动的序列图像,将该序列图像与其正视时的眼部图像进行比较,根据比较的差别得到眼球转过的角度,并基于眼球转过的角度确定视线向量。这里是假设头部不动的情况下得到的检测结果。当头部发生微小转动时,首先建立坐标补偿机制,将正视时的眼部图像进行调整。但是当头部发生较大偏转时,首先观察头部相对于空间某一固定坐标系的变化位置、方向,然后确定视线向量。
可理解,以上为本公开实施例提供的进行视线和/或头部姿态检测的示例,在具体实现中,本领域技术人员还可通过其他方法进行视线和/或头部姿态检测,本公开不做限定。
在步骤103-82中,根据每帧脸部图像的视线和/或头部姿态的检测结果,确定每帧脸部图像中所述驾驶员的注视区域的类别。
在本公开实施例中,视线检测结果包括每帧脸部图像中驾驶员的视线向量以及视线向量的起始位置,头部姿态检测结果包括每帧脸部图像中驾驶员的头部姿态,其中,视线向量可以理解为视线的方向,根据视线向量可确定脸部图像中驾驶员的视线相较于驾驶员正视时的视线的偏离角度;头部姿态可以是驾驶员头部在坐标系下的欧拉角,其中,上述坐标系可以为:世界坐标系、相机坐标系、图像坐标系等等。
通过包括有注视区域类别标注信息的视线和/或头部姿态检测结果为训练集对注视区域分类模型进行训练,使训练后的分类模型可根据视线和/或头部姿态的检测结果,确定驾驶员的注视区域的类别,其中,上述注视区域分类模型可以为:决策树分类模型、选择树分类模型、softmax分类模型等等。在一些可能实现的方式中,视线检测结果和头部姿态检测结果均为特征向量,将视线检测结果和头部姿态检测结果进行融合处理,注视区域分类模型再根据融合后的特征确定驾驶员的注视区域的类别,可选地,上述融合处理可以为特征拼接。在另一些可能实现的方式中,注视区域分类模型可基于视线检测结果或头部姿态检测结果确定驾驶员的注视区域的类别。
不同车型的车内环境以及注视区域的类别的划分方式可能也不相同,在本实施例中,通过与车型对应的训练集对用于对注视区域进行分类的分类器进行训练,可使训练后的分类器适用于不同车型,其中,与车型对应的训练集指包括有该车型注视区域类别标注信息的视线和/或头部姿态检测结果以及对应的新车型的注视区域类别的标注信息,基于训练集对需要在新车型中使用的分类器进行监督训练。分类器可基于神经网络、支持向量机等方式预先构建,本公开对分类器的具体结构不做限定。
例如,在一些可能实现的方式中,a车型相对驾驶员的前向空间划分为12个注视区域,b车型根据自身的车空间特点,想对驾驶员的前向空间需要相对a车型做不同的注视区域划分,如划分成10个注视区域。该情形下,基于本实施例构建的驾驶员注意力监控技术方案应用于a车型,在需要将该注意力监控技术方案应用于b车型之前,可以复用a车型中的视线和/或头部姿态检测技术,而只需针对b车型的空间特点重新划分注视区域,基于视线和/或头部姿态检测技术以及b车型对应的注视区域划分,构建训练集,该训练集包括的人脸图像包括有视线和/或头部姿态检测结果及其对应的b车型对应的注视区域的类别标注信息,这样基于构建的训练集对用于b车型的注视区域分类的分类器进行监督训练,而无需对用于视线和/或头部姿态检测的模型进行重复训练。训练完成后的分类器以及复用的视线和/或头部姿态检测技术,就构成了本公开实施例提供的驾驶员注意力监测方案。
本实施例将注视区域分类所需的特征信息检测(如视线和/或头部姿态检测)与基于上述特征信息进行注视区域分类,分为两个相对独立的阶段进行,提高了如视线和/或头部姿态等特征信息检测技术在不同车型的复用性,因注视区域划分有变化的新应用场景(如新车型等)仅需对应调整适配新的注视区域划分的分类器或分类方法,减少了因注视区域划分有变化的新应用场景下,驾驶员注意力检测技术方案调整的复杂性和运算量,提高了技术方案的普适性和泛化性,由此更好满足多样化的实际应用需求。
除了将注视区域分类所需的特征信息检测与基于上述特征信息进行注视区域分类,分为两个相对独立的阶段之外,本公开实施例还可基于神经网络实现注视区域类别的端到端的检测,即:向神经网络输入脸部图像,而经神经网络对脸部图像处理后输出注视区域类别的检测结果。其中,神经网络可以基于卷积层、非线性层、全连接层等网络单元按照一定方式堆叠或组成,也可以采用现有的神经网络结构,本公开对此并不限定。确定好待训练的神经网络结构之后,所述神经网络可以采用包括有注视区域类别标注信息的人脸图像集进行监督训练,或者,所述神经网络可以采用包括有注视区域类别标注信息的人脸图像集以及基于所述人脸图像集中各人脸图像截取的眼部图像进行监督训练;所述注视区域类别标注信息包括所述多类定义注视区域之一。基于带有上述标注信息的人脸图像集对神经网络进行监督训练,可使得该神经网络能同时学习到进行注视类别区域划分所需的特征提取能力以及注视区域的分类能力,由此实现输入图像输出注视区域类别检测结果的端到端检测。
在一些可选实施例中,例如图8所示,是本公开实施例提供的用于检测注视区域类别的神经网络的一种可能实现的训练方法的流程示意图。
在步骤201中,获取包括有所述注视区域类别标注信息的人脸图像集。
在本实施例中,人脸图像集中的每一帧图像都包含注视区域的类别,以图6的注视区域的类别的划分为例,每一帧图像包括的标注信息为1至12中任意一个数字。
在步骤202中,对所述人脸图像集中的图像进行特征提取处理,获得第四特征。
通过神经网络对人脸图像进行特征提取处理,获得第四特征,在一些可能实现的方式中,对人脸图像依次进行卷积处理、归一化处理、第一线性变换、第二线性变换实现特征提取处理,获得第四特征。
首先,通过神经网络中的多层卷积层对人脸图像进行卷积处理,获得第五特征,其中,每个卷积层提取出的特征内容及语义信息均不一样,具体表现为,通过多层卷积层的卷及处理一步步将图像特征抽象出来,同时也将逐步去除相对次要的特征,因此,越到后面提取出的特征尺寸越小,内容及语义信息就越浓缩。通过多层卷积层逐级对人脸图像进行卷积操作,并提取相应的中间特征,最终得到固定大小的特征数据,这样,可在获得人脸图像主要内容信息(即人脸图像的特征数据)的同时,将图像尺寸缩小,减小系统的计算量,提高运算速度。上述卷积处理的实现过程如下:卷积层对人脸图像做卷积处理,即利用卷积核在人脸图像上滑动,并将人脸图像点上的像素值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素值,最终滑动处理完人脸图像中的所有像素值,并提取出第五特征。需要理解的是,本公开对上述卷积层的数量不做具体限定。
在对人脸图像进行卷积处理时,数据经过每一层网络的处理后,其数据分布都会发生变化,这样会给下一层网络的提取带来困难。因此,在对卷积处理得到的第五特征进行后续处理之前,需要对第五特征进行归一化处理,即将第五特征归一化到均值为0且方差为1的正态分布。在一些可能实现的方式中,在卷积层后连接归一化处理(batchnorm,bn)层,bn层通过加入可训练的参数对特征进行归一化处理,能加快训练速度,并去除数据的相关性,突出特征之间的分布差异。在一个例子中,bn层对第五特征的处理过程可参见下文:
假设第五特征为β=x1→m,共m个数据,输出是yi=bn(x),bn层将对第五特征进行如下操作:
首先,求出上述第五特征β=x1→m的平均值,即
根据上述平均值μβ,确定上述第五特征的方差,即
根据上述平均值μβ和方差
最后,基于缩放变量γ和平移变量δ,得到归一化的结果,即
由于卷积处理以及归一化处理从数据中学习复杂映射的能力较小,无法学习和处理复杂类型的数据,例如图像、视频、音频、语音等等。因此,需要通过对归一化处理后的数据进行线性变换,来解决诸如图像处理、视频处理等复杂问题。在bn层后连接线性激活函数,通过激活函数对归一化处理后的数据进行线性变换,可处理复杂的映射,在一些可能实现的方式中,将归一化处理后的数据代入线性整流函数(rectifiedlinearunit,relu)函数,实现对归一化处理后的数据的第一线性变换,得到第六特征。
在激活函数层后连接的是全连接(fullyconnectedlayers,fc)层,通过全连接层对第六特征进行处理,可将第六特征映射到样本(即注视区域)标记空间。在一些可能实现的方式中,通过全连接层对第六特征进行第二线性变换。全连接层包含输入层(即激活函数层)以及输出层,输出层的任何一个神经元与输入层的每一个神经元都有连接,其中,输出层中的每一个神经元都有相应的权重和偏置,因此,全连接层所有的参数就是每个神经元的权重以及偏置,该权重和偏置的具体大小是通过对全连接层进行训练得到的。
将第六特征输入至全连接层时,获取全连接层的权重和偏置(即第二特征数据的权重),再根据权重和偏置对上述第六特征进行加权求和,获得上述第四特征,在一些可能实现的方式中,全连接层的权重和偏置分别为:wi和bi,其中i为神经元的数量,第六特征为x,则全连接层对第三特征数据进行第二线性变换后得到的第一特征数据为:
在步骤203中,对第一特征数据进行第一非线性变换,获得注视区域类别检测结果。
在全连接层后连接softmax层,通过softmax层内置的softmax函数将输入的不同特征数据映射成0至1之间的值,且映射后的所有值的和为1,映射后的值与输入的特征一一对应,这样,就相当于对每个特征数据完成了预测,并以数值的形式给出相应的概率。在一种可能实现的方式中,将第四特征输入至softmax层,并将第四特征代入softmax函数进行第一非线性变换,获得驾驶员的视线在不同注视区域的概率。
在步骤204中,根据所述注视区域类别检测结果和所述注视区域类别标注信息的差异,调整所述神经网络的网络参数。
在本实施例中,神经网络包括损失函数,损失函数可以为:交叉熵损失函数、均方差损失函数、平方损失函数等等,本公开对损失函数的具体形式不做限定。
人脸图像集中的每一张图像都有相应的标注信息,即每张人脸图像都会对应一个注视区域类别,将步骤202得到的不同注视区域的概率以及标注信息代入损失函数,得到损失函数值。通过调整神经网络的网络参数,使损失函数值小于或等于第二阈值,即可完成神经网络的训练,其中,上述网络参数包括步骤201与202中各网络层的权重以及偏置。
本实施例根据包括有所述注视区域类别标注信息的人脸图像集对神经网络进行训练,使训练后的神经网络可基于提取出的人脸图像的特征确定注视区域的类别,基于本实施例提供的训练方法只需输入人脸图像集,即可得到训练后的神经网络,训练方式简单,训练时间短。
在一些可选实施例中,例如图9所示,图9是本公开实施例提供的上述神经网络的另一种可能实现的训练方法的流程示意图。
在步骤301中,获取所述人脸图像集中包括有注视区域类别标注信息的人脸图像。
在本实施例中,人脸图像集中的每一张图像都包含注视区域的类别,以图6的注视区域的类别的划分为例,每一帧图像包括的标注信息为1至12中任意一个数字。
通过对不同尺度的特征进行融合,丰富特征信息,可提高注视区域的类别的检测精度,上述丰富特征信息的实现过程可参见步骤302~305。
在步骤302中,截取所述人脸图像中的至少一眼的眼部图像,所述至少一眼包括左眼和/或右眼。
在本实施例中,通过识别人脸图像中的眼部区域图像,并通过截图软件从人脸图像中截取出眼部区域图像,也可以通过画图软件从人脸图像中截取出眼部区域图像等等,本公开对如何识别人脸图像中的眼部区域图像以及如何从人脸图像中截取出眼部区域图像的具体实现方式不做限定。
在步骤303中,分别提取所述人脸图像的第一特征和至少一眼的眼部图像的第二特征。
在本实施例中,被训练的神经网络包含多个特征提取分支,通过不同的特征提取分支对人脸图像以及眼部图像进行第二特征提取处理,获得人脸图像的第一特征和眼部图像的第二特征,丰富提取出的图像特征尺度,在一些可能实现的方式中,通过不同的特征提取分支分别对人脸图像依次进行卷积处理、归一化处理、第三线性变换、第四线性变换,获得人脸图像特征以及眼部图像特征,其中,视线向量信息包括视线向量以及视线向量的起点位置。应理解,上述眼部图像中可以只包括一只眼睛(左眼或右眼),也可以包括两只眼睛,本公开对此不做限定。
上述卷积处理、归一化处理、第三线性变换、第四线性变换的具体实现过程可参见步骤202中的卷积处理、归一化处理、第一线性变换、第二线性变换,此处将不再赘述。
在步骤304中,融合所述第一特征和所述第二特征,得到第三特征。
由于同一物体(本实施例中指驾驶员)的不同尺度的特征包含的场景信息均不一样,通过将不同尺度的特征进行融合,可得到信息更丰富的特征。
在一些可能实现的方式中,通过对第一特征和第二特征进行融合处理,实现将多个特征中的特征信息融合于一个特征中,有利于提高驾驶员注视区域的类别的检测精度。
在步骤305中,根据所述第三特征确定所述人脸图像的注视区域类别检测结果。
在本实施例中,注视区域类别检测结果为驾驶员的视线在不同注视区域的概率,取值范围为0至1。在一些可能实现的方式中,将第三特征输入至softmax层,并将第三特征代入softmax函数进行第二非线性变换,获得驾驶员的视线在不同注视区域的概率。
在步骤306中,根据所述注视区域类别检测结果和所述注视区域类别标注信息的差异,调整所述神经网络的网络参数。
在本实施例中,神经网络包括损失函数,损失函数可以为:交叉熵损失函数、均方差损失函数、平方损失函数等等,本公开对损失函数的具体形式不做限定。
将步骤305得到的不同注视区域的概率以及标注信息代入损失函数,得到损失函数值。通过调整神经网络的网络参数,使损失函数值小于或等于第三阈值,即可完成神经网络的训练,其中,上述网络参数包括步骤303至305中各网络层的权重以及偏置。
通过本实施例提供的训练方式训练得到的神经网络,可对同一帧图像中提取出的不同尺度的特征进行融合,丰富特征信息,进而基于融合后的特征识别驾驶员的注视区域的类别以提高识别精度。
本领域技术人员需理解,本公开提供的两种神经网络的训练方法(步骤201~204以及步骤301~306),可在本地终端(如:电脑或手机)上实现,也可通过云端实现,本公开对此不做限定。
在一些可选实施例中,例如图10所示,上述方法还可以包括:
在步骤108中,生成与所述交互反馈信息对应的车辆控制指令。
在本公开实施例中,可以生成与数字人输出的交互反馈信息对应的车辆控制指令。
例如,数字人输出的交互反馈信息为“给你放首歌吧”,则车辆控制指令可以是控制车载音频播放设备播放音频。
在步骤109中,控制所述车辆控制指令对应的车载设备执行所述车辆控制指令所指示的操作。
在本公开实施例中,可以控制对应的车载设备执行车辆控制指令所指示的操作。
例如,车辆控制指令为开启车窗,则可以控制车窗降低。再例如,车辆控制指令为关闭收音机,则可以控制收音机关闭。
上述实施例中,除了可以让数字人输出交互反馈信息之外,还可以生成与交互反馈信息对应的车辆控制指令,从而控制相应的车载设备执行对应操作,让数字人成为车内人员与车的温情链接。
在一些可选实施例中,所述交互反馈信息中包括用于缓解所述车内人员的疲劳或分心程度的信息内容,则步骤108可以包括以下至少一项:
在步骤108-1中,生成触发目标车载设备的所述车辆控制指令。
其中,所述目标车载设备包括通过味觉、嗅觉和听觉中的至少一项缓解所述车内人员疲劳或分心程度的车载设备。
例如,交互反馈信息中包括以下内容“我看你很累了,我给你放松一下吧”,此时确定车内人员疲劳等级为最疲劳,可以生成启动座椅按摩的车辆控制指令,或者交互反馈信息中包括“不要分心啊”,此时确定车内人员疲劳程度为最轻,可以生成启动音频播放的车辆控制指令,或者交互反馈信息中包括“有些分心了,我看你有些累了”,可以确定疲劳等级为中度,此时可以生成开启香氛系统的车辆控制指令。
在步骤108-2中,生成触发辅助驾驶的车辆控制指令。
在本公开实施例中,还可以生成辅助驾驶的车辆控制指令,例如启动自动驾驶来辅助驾驶员驾驶。
上述实施例中,还可以生成触发目标车载设备的车辆控制指令和/或触发辅助驾驶的车辆控制指令,提升驾驶安全性。
在一些可选实施例中,所述交互反馈信息中包括对手势检测结果的确认内容,例如车内人员输入了竖起拇指的手势,或者竖起拇指和中指的手势,如图11a和图11b所示,数字人输出“好的”“没问题”等交互反馈信息,则步骤108可以包括:
在步骤108-3中,根据手势与车辆控制指令之间的映射关系,生成所述手势检测结果所指示的手势对应的所述车辆控制指令。
在本公开实施例中,可以预存手势与车辆控制指令之间的映射关系,确定相应的车辆控制指令。例如根据映射关系,竖起拇指和中指的手势对应的车辆控制指令为车载处理器通过蓝牙接收图像。或者只竖起目前的手势对应的车辆控制指令为车载摄像头拍摄图像。
上述实施例中,可以根据手势与车辆控制指令之间的映射关系,生成所述手势检测结果所指示的手势对应的所述车辆控制指令,车内人员可以更灵活地对车辆进行控制,使得数字人可以更好地成为车内人员与车的温情链接。
在一些可选实施例中,还可以根据数字人输出的交互信息,控制其他车载设备启动或关闭。
例如,数字人输出的交互信息包括“我给你打开车窗或空调吧”,控制车窗打开或控制空调启动。再例如,数字人为乘客输出的交互信息包括“给你游戏玩吧”,控制车载显示设备显示游戏界面。
本公开实施例中,可以将数字人作为车辆与车内人员的温情链接,陪伴车内人员的行车过程,使得数字人更加人性化,成为更加智能的行车伴侣。
在上述实施例中,可以通过车载摄像头采集视频流,对视频流包括的至少一帧图像进行预定任务处理,得到任务处理结果。例如可以进行人脸检测,检测到人脸后,再进行视线检测或注视区域检测,检测到实现方向指向车载显示设备或注视区域与车载设备的设置区域至少部分重叠时,可以在车载显示设备上显示数字人。可选地,可以对至少一帧图像进行人脸识别,如果预确定车内有人,则可以在车载显示设备上显示数字人,例如图12a所示。
或者对至少一帧图像进行视线检测或注视区域检测,实现通过视线注视启动数字人的过程,例如图12b所示。
如果未预存人脸识别结果对应的第一数字人,则可以在车载显示设备上显示第二数字人,或者输出提示信息,让车内人员进行第一数字人的设置。
第一数字人可以在整个行程过程中陪伴车内人员,如图12c所示,与车内人员进行交互,输出语音反馈信息、表情反馈信息和动作反馈信息中的至少一项。
通过上述过程,实现了视线启动数字人或控制数字人输出交互反馈信息,与车内人员进行交互的目的,在本公开实施例中,除了可以采用视线实现上述过程之外,还可以通过多种模式启动数字人或控制数字人输出交互反馈信息。
如图13所示,上述方法还可以包括:
在步骤110中,获取车载语音采集设备所采集的所述车内人员的音频信息。
在本公开实施例中,还可以通过车载语音采集设备,例如麦克风采集车内人员的音频信息。
在步骤111中,对所述音频信息进行语音识别,得到语音识别结果。
在本公开实施例中,可以对音频信息进行语音识别,获得语音识别结果,该语音识别结果对应不同的指令。
在步骤112中,根据所述语音识别结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在本公开实施例中,还可以由车内人员通过语音启动数字人,即根据根据所述语音识别结果,在车载显示设备上显示数字人,或者还可以根据车内人员的语音控制数字人输出交互反馈信息,该交互反馈信息同样可以包括语音反馈信息、表情反馈信息、动作反馈信息中至少一个。
例如,车内人员进入车舱后,语音输入“启动数字人”,则根据该语音信息在车载显示设备上显示数字人,这个数字人可以是之前车内人员以及设置好的第一数字人,或者默认的第二数字人,或者还可以语音输出提示信息,让车内人员设置第一数字人。
再例如,控制车载显示设备上显示的数字人与车内人员聊天,车内人员语音输入“今天好热”,数字人通过语音、表情或动作中的至少一项输出到的“需不需要给你打开空调”的交互反馈信息。
上述实施例中,除了可以通过视线启动数字人或控制数字人输出交互反馈信息之外,车内人员还可以通过语音启动数字人或控制数字人输出交互反馈信息,使得数字人与车内人员的交互更加多模式化,提升了数字人的智能化程度。
与前述方法实施例相对应,本公开还提供了装置的实施例。
如图14所示,图14是本公开根据一示例性实施例示出的一种基于车载数字人的交互装置框图,装置包括:第一获取模块410,用于获取车载摄像头采集的车内人员的视频流;任务处理模块420,用于对所述视频流包括的至少一帧图像进行预定任务处理,得到任务处理结果;第一交互模块430,用于根据所述任务处理结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括以下至少之一:人脸检测、视线检测、注视区域检测、人脸识别、人体检测、手势检测、人脸属性检测、情绪状态检测、疲劳状态检测、分心状态检测、危险动作检测;和/或,所述车内人员包括以下至少之一:驾驶员、乘客;和/或,所述数字人输出的交互反馈信息包括以下至少之一:语音反馈信息、表情反馈信息、动作反馈信息。
在一些可选实施例中,所述第一交互模块包括:第一获取子模块,用于获取预定任务的任务处理结果和交互反馈指令之间的映射关系;确定子模块,用于根据所述映射关系确定与所述任务处理结果对应的交互反馈指令;控制子模块,用于控制所述数字人输出与确定的所述交互反馈指令对应的交互反馈信息。
在一些可选实施例中,所述预定任务包括人脸识别;所述任务处理结果包括人脸识别结果;所述第一交互模块包括以下至少之一:第一显示子模块,用于响应于所述车载显示设备中存储有与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示所述第一数字人;第二显示子模块,用于响应于所述车载显示设备中未存储与所述人脸识别结果对应的第一数字人,在所述车载显示设备上显示第二数字人或输出用于生成与所述人脸识别结果对应的第一数字人的提示信息。
在一些可选实施例中,所述第二显示子模块包括:显示单元,用于在所述车载显示设备上输出人脸图像的图像采集提示信息;所述装置还包括:第二获取模块,用于获取人脸图像;人脸属性分析模块,用于对所述人脸图像进行人脸属性分析,获得所述人脸图像所包括的目标人脸属性参数;模板确定模块,用于根据预存的人脸属性参数和数字人形象模版之间的对应关系,确定与所述目标人脸属性参数对应的目标数字人形象模版;数字人生成模块,用于根据所述目标数字人形象模版,生成与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述数字人生成模块包括:第一存储子模块,用于将所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述数字人生成模块包括:第二获取子模块,用于获取所述目标数字人形象模版的调整信息;调整子模块,用于根据所述调整信息调整所述目标数字人形象模版;第二存储子模块,用于将调整后的所述目标数字人形象模版存储为与所述车内人员匹配的所述第一数字人。
在一些可选实施例中,所述第二获取模块包括:第三获取子模块,用于获取所述车载摄像头采集的人脸图像;或第四获取子模块,用于获取上传的所述人脸图像。
在一些可选实施例中,所述预定任务包括视线检测;所述任务处理结果包括视线方向检测结果;所述第一交互模块包括以下至少之一:第三显示子模块,用于响应于所述视线方向检测结果表示所述车内人员的视线指向所述车载显示设备,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述预定任务包括注视区域检测;所述任务处理结果包括注视区域检测结果;所述第一交互模块包括以下至少之一:第四显示子模块,用于响应于所述注视区域检测结果表示所述车内人员的注视区域与所述车载显示设备的设置区域至少部分重叠,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
在一些可选实施例中,所述车内人员包括驾驶员;所述第一交互模块包括:类别确定子模块,用于根据所述视频包括的所述至少一帧位于驾驶区域的驾驶员的脸部图像,分别确定每帧脸部图像中所述驾驶员的注视区域的类别,其中,每帧脸部图像的注视区域属于预先对车进行空间区域划分得到的多类定义注视区域之一。
在一些可选实施例中,所述预先对所述车进行空间区域划分得到的多类定义注视区域,包括以下二类或二类以上:左前挡风玻璃区域、右前挡风玻璃区域、仪表盘区域、车内后视镜区域、中控台区域、左后视镜区域、右后视镜区域、遮光板区域、换挡杆区域、方向盘下方区域、副驾驶区域、副驾驶前方的杂物箱区域、车载显示区域。
在一些可选实施例中,所述类别确定子模块包括:第一检测单元,用于对所述视频包括的多帧位于所述驾驶区域的驾驶员的脸部图像进行视线和/或头部姿态检测;类别确定单元,用于根据每帧脸部图像的视线和/或头部姿态的检测结果,确定每帧脸部图像中所述驾驶员的注视区域的类别。
在一些可选实施例中,所述类别确定子模块包括:输入单元,用于将多帧所述脸部图像分别输入神经网络并经所述神经网络分别输出每帧脸部图像中所述驾驶员的注视区域的类别,其中:所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集预先训练完成,或者,所述神经网络预先采用包括有注视区域类别标注信息的人脸图像集以及基于所述人脸图像集中各人脸图像截取的眼部图像预先训练完成;所述注视区域类别标注信息包括所述多类定义注视区域之一。
在一些可选实施例中,所述装置还包括:第三获取模块,用于获取所述人脸图像集中包括有注视区域类别标注信息的人脸图像;截取模块,用于截取所述人脸图像中的至少一眼的眼部图像,所述至少一眼包括左眼和/或右眼;特征提取模块,用于分别提取所述人脸图像的第一特征和至少一眼的眼部图像的第二特征;融合模块,用于融合所述第一特征和所述第二特征,得到第三特征;检测结果确定模块,用于根据所述第三特征确定所述人脸图像的注视区域类别检测结果;参数调整模块,用于根据所述注视区域类别检测结果和所述注视区域类别标注信息的差异,调整所述神经网络的网络参数。
在一些可选实施例中,所述装置还包括:车辆控制指令生成模块,用于生成与所述交互反馈信息对应的车辆控制指令;控制模块,用于控制所述车辆控制指令对应的车载设备执行所述车辆控制指令所指示的操作。
在一些可选实施例中,所述交互反馈信息中包括用于缓解所述车内人员的疲劳或分心程度的信息内容;所述车辆控制指令生成模块包括:第一生成子模块,用于生成触发目标车载设备的所述车辆控制指令;其中,所述目标车载设备包括通过味觉、嗅觉和听觉中的至少一项缓解所述车内人员疲劳或分心程度的车载设备;和/或第二生成子模块,用于生成触发辅助驾驶的车辆控制指令。
在一些可选实施例中,所述交互反馈信息中包括对手势检测结果的确认内容;所述车辆控制指令生成模块包括:第三生成子模块,用于根据手势与车辆控制指令之间的映射关系,生成所述手势检测结果所指示的手势对应的所述车辆控制指令。
在一些可选实施例中,所述装置还包括:第四获取模块,用于获取车载语音采集设备所采集的所述车内人员的音频信息;语音识别模块,用于对所述音频信息进行语音识别,得到语音识别结果;第二交互模块,用于根据所述语音识别结果,在车载显示设备上显示数字人或者控制车载显示设备上显示的数字人输出交互反馈信息。
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本公开方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
本公开实施例还提供了一种计算机可读存储介质,存储介质存储有计算机程序,计算机程序用于执行上述任一的设备控制方法。
在一些可选实施例中,本公开实施例提供了一种计算机程序产品,包括计算机可读代码,当计算机可读代码在设备上运行时,设备中的处理器执行用于实现如上任一实施例提供的设备控制方法的指令。
在一些可选实施例中,本公开实施例还提供了另一种计算机程序产品,用于存储计算机可读指令,指令被执行时使得计算机执行上述任一实施例提供的设备控制方法的操作。
该计算机程序产品可以具体通过硬件、软件或其结合的方式实现。在一个可选实施例中,所述计算机程序产品具体体现为计算机存储介质,在另一个可选实施例中,计算机程序产品具体体现为软件产品,例如软件开发包(softwaredevelopmentkit,sdk)等等。
本公开实施例还提供了一种设备控制装置,包括:处理器;用于存储处理器可执行指令的存储器;其中,处理器被配置为调用所述存储器中存储的可执行指令,实现上述任一项所述的设备控制方法。
图15为本申请实施例提供的一种基于车载数字人的交互装置的硬件结构示意图。该基于车载数字人的交互装置510包括处理器511,还可以包括输入装置512、输出装置513和存储器514。该输入装置512、输出装置513、存储器514和处理器511之间通过总线相互连接。
存储器包括但不限于是随机存储记忆体(randomaccessmemory,ram)、只读存储器(read-onlymemory,rom)、可擦除可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、或便携式只读存储器(compactdiscread-onlymemory,cd-rom),该存储器用于相关指令及数据。
输入装置用于输入数据和/或信号,以及输出装置用于输出数据和/或信号。输出装置和输入装置可以是独立的器件,也可以是一个整体的器件。
处理器可以包括是一个或多个处理器,例如包括一个或多个中央处理器(centralprocessingunit,cpu),在处理器是一个cpu的情况下,该cpu可以是单核cpu,也可以是多核cpu。
存储器用于存储网络设备的程序代码和数据。
处理器用于调用该存储器中的程序代码和数据,执行上述方法实施例中的步骤。具体可参见方法实施例中的描述,在此不再赘述。
可以理解的是,图15仅仅示出了一种基于车载数字人的交互装置的简化设计。在实际应用中,驾驶员注意力监测装置还可以分别包含必要的其他元件,包含但不限于任意数量的输入/输出装置、处理器、控制器、存储器等,而所有可以实现本申请实施例的驾驶员注意力监测装置都在本申请的保护范围之内。
在一些实施例中,本公开实施例提供的装置具有的功能或包含的模块可以用于执行上文方法实施例描述的方法,其具体实现可以参照上文方法实施例的描述,为了简洁,这里不再赘述。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或者惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
以上所述仅为本公开的较佳实施例而已,并不用以限制本公开,凡在本公开的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本公开保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!