一种短文本分类方法及系统与流程
本发明涉及文本挖掘和文本分类领域,具体涉及一种短文本分类方法及系统。
背景技术:
随着售电侧改革的不断深化,数据已经成为电网公司长期发展的重要资源之一。在电网公司的运营活动中,每天都会产生大量内部数据,例如工单数据,这些数据对于电网公司运营和发展策略的决议都会有十分重要的作用和意义。
如果对企业级系统数据处理类工单进行数据修改原因进行分析,以统计各类修改数据原因的数量分布与占比,可作为数据质量评估与数据质量考核的辅助手段。目前,针对企业内部运营工单进行分析还没有一套形成规范的工单分类体系,并未搭建起一套企业运营工单分析系统。目前,针对企业级信息系统数据处理申请工单,归纳出12类问题标签,分别为:是否用户误操作或录入错误、因业务考核要求进行数据处理、数据质量考核要求、属于特殊业务需求目前功能不支持、接口类问题,是否旧系统历史数据问题或存量数据清理、属于对系统操作不熟悉咨询类问题、系统功能缺陷问题、前台是否有功能修改但用户不通过前台维护、组织调整导致的数据处理、数据治理工具是否有功能支持与工单属于批量处理。由于存在上述多类问题,目前采取少量的、基于人工判断的工单分类办法,且借助excel工具进行手工汇总分析。
此外,现有短文本分类技术基本上是基于词来进行特征提取的,必然会出现特征矩阵稀疏问题,影响分类器的性能。
技术实现要素:
本发明提供一种短文本分类方法及系统,旨在解决现有基于词特征的短文本分类技术所存在的问题,将文本中的高贡献词特征和对应的词性特征结合起来,大大降低了特征空间维度,提高了分类的准确率。
根据本发明的短文本分类方法,包括以下步骤:
s101、获取训练文本的特征,所述特征包括词特征和对应的词性特征;
s102、基于词特征和词性特征,应用改进的互信息评估函数进行特征选择,过滤对分类贡献低的词特征;计算所选择的词特征的tf-idf矩阵和其对应的词性特征值,结合词性特征值形成训练样本的tf-idf-pos矩阵;
s103、根据训练样本的tf-idf-pos矩阵,基于预设好参数的分类器模型,构建文本分类器;
s104、基于所构建的文本分类器,计算待分类文本的tf-idf-pos矩阵,对待分类文本进行分类。
在优选的实施例中,步骤s101在特征获取的过程中,将训练文本切分成词语串;提取每个词语串的词性以及词性特征值,所述词性特征值为某文本中各词性词语出现次数除以总分词数。
在优选的实施例中,步骤s102应用改进的互信息评估函数进行特征选择的过程为:使用改进的互信息评估函数计算词语对文本的互信息值,基于阈值筛选对分类贡献度高的词特征,并与词性特征值合并以构造tf-idf-pos矩阵。
根据本发明的短文本分类系统,包括:
分词模块,用于获取训练文本的特征,所述特征包括词特征和对应的词性特征;
降维模块,用于对词特征和词性特征进行选择,计算所选择的词特征的tf-idf矩阵,结合其对应的词性特征值形成训练样本的tf-idf-pos矩阵;
分类器构建模块,用于根据训练样本的tf-idf-pos矩阵和基于预设好参数的分类器模型构建文本分类器;
分类模块,用于根据所述tf-idf-pos矩阵,基于所构建的文本分类器对待分类文本进行分类。
在优选的实施例中,所述中文分词模块包括:切分子模块,用于将文本切分成词语串;词性提取模块,用于提取每个词语串的词性;计算子模块,计算词特征tf-idf矩阵和词性特征值,所述词性特征值为某文本中各词性词语出现次数除以总分词数。
在优选的实施例中,所述降维模块包括:计算子模块,用于计算每个词语的改进互信息值mi,所述改进互信息值mi通过改进的互信息函数计算;筛选子模块,用于判断特征选取阈值,并根据改进互信息值mi筛选大于阈值的特征;特征构造模块,用于将降维后的词特征与对应词性特征构造为tf-idf-pos矩阵;
所述改进的互信息评估函数对互信息值的计算公式为:
p(w|cj)表示词条w在类别cj出现的概率,p(w)表示词条w在整个训练集中出现的概率,mi(cj,w)表示词条w和类别cj之间的相关程度,tf(w,cj)表示词条w在类别cj出现的频率。
由以上技术方案可知,本发明可基于词典知识库对训练语料进行特征获取,包括词特征和词性特征;基于所述词特征和词性特征应用改进的互信息平湖函数进行特征选择,即对特征空间压缩;根据压缩后的特征空间进行分类器构建,并对待分类文本进行分类。与现有技术相比,本发明取得的有益效果包括:
1、本发明将短文本进行分词与词性提取,使用改进的互信息评估函数进行特征空间压缩,构建文本分类器,并训练分类器以对待分类文本进行分类,搭建起短文本(例如电网内部工单数据)分类体系,减少业务人员工作量,降低了人工成本,提高了分类的准确率。
2、本发明将文本中的高贡献词特征和对应的词性特征结合起来,大大降低了特征空间维度,提高计算效率,节省服务器资源。
附图说明
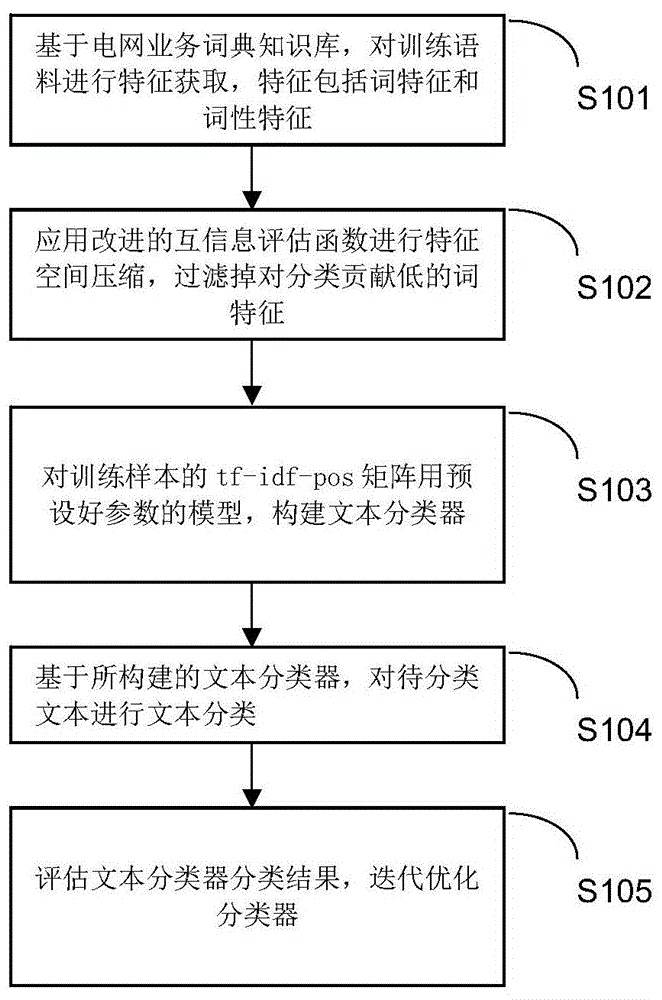
图1是本发明实施例提供的文本分类方法的实现流程图;
图2是本发明实施例提供的文本分类系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明作进一步详细说明,但本发明的实施方式不限于此。
图1示出了本发明实施例提供的文本分类方法实现流程,本实施例以电网工单短文本为例,详述如下:
s101、基于业务词典知识库,对训练语料(即训练文本)进行特征获取,所述特征包括词特征和对应的词性特征。
在本实施例中,将待分类的电网工单短文本进行中文分词处理,同时调用分词工具词性获取模块获取词特征的词性作为词性特征。例如,待分类文本(也叫目标文本)为“经核查,附件明细表中的用户在系统基本档案中,线路电源性质分类和电源容量不正确,请更正”,进行分词处理后可得到<核查,附件,系统,档案,线路电源性质分类,电源容量,不正确…>等词语,且获取这些词语的词性分别为<动词,名词,名词,名词,专有词,专有词,形容词…>,则目标文本携带<动词,名词,专有词,形容词>的词性特征,其特征值为某词性词语在文本中出现的次数除以分词总数,如动词出现1次,名词出现3次,专有词出现2次,形容词出现1次,总词数为7,其特征值为<1/7,3/7,2/7,1/7>。
也就是说,在特征获取的过程中,将训练文本切分成词语串;提取每个词语串的词性以及词性特征值,所述词性特征值指某文本中各词性词语出现次数除以总分词数。
s102、基于步骤s101获取的词特征和词性特征,应用改进的互信息评估函数进行特征选择,过滤掉对分类贡献低的词特征。从而可以对庞大的特征群做降维处理,筛选用于建模的特征子集,进一步缩小特征空间。
即,基于所述词特征和词性特征,应用改进的互信息评估函数进行特征选择,压缩特征空间。其中,改进的互信息评估函数,与原互信息评估函数相比,能减少有用信息的损失。原互信息评估函数对于某个类别cj与特定词条w的互信息值计算公式为:
式中,p(w|cj)表示词条w在类别cj出现的概率,p(w)表示词条w在整个训练集中出现的概率,mi(cj,w)表示词条w和类别cj之间的相关程度。mi值越大,表示特征的出现越依赖于文本类别,mi值为0则表示特征与文本相互独立,mi为负数则表示特征与文本负相关。由上述计算公式可看出,特征出现概率越小,log(p(w))较log(p(w|cj))变化快,mi值越大,故低概率特征有更大的互信息值。原互信息评估函数的计算公式没有考虑到词在文档中出现的频率,如,a词在训练文档中出现20次,在类别1中出现10次,b词在训练文档中出现8词,在类别a中出现4次,由上述公式计算结果mia与mib相同,但是明显a词对判断类别1贡献程度要比b词大。
基于此,本发明对原互信息评估函数进行改进,方法为:在原互信息评估函数基础上增加词对类别的贡献程度影响因素,即词在类别中出现的频率tf,改进的互信息评估函数对互信息值的计算公式为:
tf(w,cj)表示词条w在类别cj出现的频率。
采用改进的互信息评估函数进行特征选择的方法为:使用改进的互信息评估函数计算词语对文本的互信息值,基于阈值筛选对分类贡献度高(即频率高)的词特征,并与词性特征值合并以构造tf-idf-pos矩阵。基于所构造的tf-idf-pos矩阵,构建文本分类器,并对待分类文本进行文本分类。
本实施例中,针对每个词对每个文本的互信息值,取全局平均值作为每个词的全局互信息阈值,选择大于阈值的词语作为词特征。计算所选择的词特征的tf-idf矩阵(词频-逆向文本频率矩阵)和其对应的词性特征值,结合其对应的词性特征值形成训练样本的tf-idf-pos矩阵(词频-逆向文本频率-词性矩阵),用于分类器构建。
s103、根据步骤s102得到的训练样本的tf-idf-pos矩阵,基于预设好参数的分类器模型(例如预设好参数的svm算法),构建文本分类器。
本实施例中,以70%样本数据训练文本分类器,30%样本数据作为模型效果评估数据;在测试语料上构造准确率、覆盖率、召回率等指标评估分类器性能。
s104、基于所构建的文本分类器,计算待分类文本的tf-idf-pos矩阵,对待分类文本进行分类。
s105、评估文本分类器分类效果,迭代优化svm分类器模型参数,更新预设分类器模型,使文本分类器性能达到最优水平;存储svm分类器模型结构和参数,给后续待分类文本进行分类时调用。
由上述过程可知,本发明将文本中的高贡献词特征和对应的词性特征结合起来,大大降低了特征空间维度,提高计算效率,节省服务器资源,释放了大量人工审单工作量。
图2示出了本发明实施例提供的文本分类系统的结构。该文本分类系统运行于电网公司大数据平台中,具体包括:
中文分词模块21,用于获取训练文本的特征,所述特征包括词特征和对应词性特征;具体的,中文分词模块21包括:切分子模块211,用于将中文文本切分成词语串;词性提取模块212,用于提取每个词语串的词性;计算子模块213,计算词特征tf-idf矩阵和词性特征值,所述词性特征值指某文本中各词性词语出现次数除以总分词数。
降维模块22,用于对词特征和词性特征进行选择,过滤对分类贡献低的词特征,即压缩词特征和词性特征的特征空间,计算所选择的词特征的tf-idf矩阵,结合其对应的词性特征值形成训练样本的tf-idf-pos矩阵以构建文本分类器;降维模块22包括:计算子模块221,用于计算每个词语的改进互信息值mi,所述改进互信息值mi通过改进的互信息函数计算,改进的互信息函数在原互信息函数基础上增加词频对文档类别的影响因素;筛选子模块222,用于判断特征选取阈值,并根据mi值筛选大于阈值的特征;特征构造模块223,用于将降维后的词特征与对应词性特征构造为tf-idf-pos矩阵。
分类器构建模块23,用于根据训练样本的tf-idf-pos矩阵和基于预设好参数的分类器模型构建文本分类器,迭代优化模型参数、保存模型结构和参数文件;分类器构建模块23包括:预设模型训练模块231,用于以预设分类器模型参数构建文本分类器;参数更新模块232,用于评估分类器分类效果,迭代优化分类器模型参数,使分类器性能达到最优水平;模型存储模块233,用于存储分类器模型结构和参数,方便后续调用。
分类模块24,用于根据所述tf-idf-pos矩阵,基于所构建的文本分类器对待分类文本进行分类;分类模块24包括:计算子模块241,用于构建待分类文本的tf-idf-pos矩阵;分类子模块242,用于对待分类文本进行分类。
统计与展示模块25,用于汇总文本分类结果并进行可视化展示;统计与展示模块25包括:汇总计数模块251,用于计算各问题工单数量,分析工单来源、负责人等;可视化模块252,用于将分析结果可视化,方便业务人员查看与分析。
本发明实施例将文本中的高贡献词特征和对应的词性特征结合起来,大大降低特征空间维度,提高计算效率,节省服务器资源,释放了大量人工审单工作量。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!