一种高效多核RISC-V处理器的Cache系统验证方法与流程
本发明涉及仿真验证算法领域,更具体地说,涉及一种高效多核risc-v处理器的cache系统验证方法。
背景技术:
以通用cpu为核心的多核处理器对于现代信息社会的重要性不言而喻,而当下新兴的ai、5g和iot等热门应用对通用计算处理核心又提出了新的要求,不仅要求能提供高性能的计算能力,而且还要求产品能够快速升级。而传统通用cpu的设计和研发目前是已分别被国外的intel和arm架构垄断,这两个通用核架构的优点是经过了多年的发展,已经具备了成熟的软硬开发生态,但其缺点也很明显——这两者都是商业公司的作品,成熟的ip资源并不对外免费释放,要想获取并在其基础上进行定制和升级,需要支付昂贵的授权费。在上述背景下加州大学伯克利分校在2011年提出了新一代开放risc-v指令集。risc-v最大的特点是简洁、开放和可扩展,用户可在其精简的基础指令集上根据应用需求自定义扩展。在当下火热的基于risc-v国产化处理器进程中,目前学术界和产业界绝大多数工作都集中在基于risc-v的扩展和异构集成等设计领域,而很少有工作关注面向risc-v的高效处理器验证。其实随着处理器芯片设计规模不断增大,缩短研发周期的要求不断提高,对于高效处理器验证技术的需求也越来越强烈。
具体为了降低访存延迟,现在的多核处理器系统中都采用层次化的存储组织方式,即每个处理器核中都有各自私有的cache,用于缓存主存中的数据。故在多核系统中,即使共享内存空间,但每个处理器核在进行访存操作时,都只在各自的cache中完成,此时如果没有专门的一致性维护模块,那就会出现数据一致性的问题。为了实现多核访存的一致性,目前业内普遍的解决方案是在多核系统中再引入专门的cache一致性维护模块。传统多核cache系统的功能验证主要基于随机激励,虽然随机激励很多时候能够帮助发现一些设计缺陷。但由于随机的不可控性造成输入激励空间的冗余和不均匀覆盖,而且待验证设计规模越大,这种不均匀性越严重。因此对于多核cache系统的验证,如何在保证验证覆盖率的基础上实现激励空间无冗余均匀覆盖已经成为研究的热点与难点。
中国专利申请,申请号cn201811636603.5,公开日2019年5月1日,公开了一种激励空间无冗余均匀覆盖的多核互联总线验证方法,属于芯片仿真验证领域。针对现有技术中存在的处理器验证的输入激励空间的冗余和不均匀覆盖的问题,该发明提供了一种激励空间无冗余均匀覆盖的多核互联总线验证方法,首先建立基于有向二分图的多核互联总线模块抽象激励模型;然后采用ep等价类划分算法将原本扁平无序的激励空间转换成了3层的激励空间树;接着采用优化深度优先odft算法对激励空间树的叶子节点集进行遍历,得到包含高层次激励信息的无冗余全覆盖叶子节点序列;最后通过总线协议相关的bussti(leafnode)转换函数将每个叶子节点转换成实际总线互联的输入激励。它可以实现在保证验证覆盖率的基础上实现激励空间无冗余均匀覆盖。
技术实现要素:
1.要解决的技术问题
针对现有技术中存在的多核risc-v处理器中cache系统仿真验证随机激励中存在的cache验证难扩展、激励空间冗余和不均匀覆盖的问题,本发明提供了一种高效多核risc-v处理器的cache系统验证方法,它可以实现在保证验证覆盖率的基础上实现激励空间无冗余均匀覆盖。
2.技术方案
本发明的目的通过以下技术方案实现。
一种高效多核risc-v处理器的cache系统验证方法,包括下述步骤:
步骤1、建立基于有向二分图(directedbipartitegraph,dbg=<dvh,dvs,de>)的多核risc-v处理器cache系统抽象模型;其中主点集dvh中的点与能发起cache写操作的risc-v核一一对应;从点集dvs中的点与能发起cache读操作的risc-v核一一对应;dvh中顶点vwi到dvs中顶点vri之间存在有向边eij=<vwi,vrj>的充要条件是vri对应risc-v核发起的读操作结果来自vwi对应risc-v核发起的写操作。
步骤2、采用层次化等价类划分算法将原本无序的risc-v处理器cache激励空间转换成有序的4层树状空间。其中层次化等价类划分算法分为4个子步骤,其中第一步为对整个空间进行划分,得到的每个一级子空间内的具有相同的写操作risc-v核数;第二步为对一级子空间进一步划分,得到的每个二级子空间内具有相同的发起写操作的risc-v核集合;第三步为对二级子空间进一步划分,得到的每个三级子空间内具有相同的读操作risc-v核子集;第四步为对三级子空间进一步划分,得到的每个四级子空间内具有确定的各risc-v核间cache变量读写对应关系。
步骤3、采用广度优先算法对激励空间树的叶子节点集进行遍历,得到包含高层次激励信息的无冗余全覆盖叶子节点序列。
步骤4、采用risc-v核相关的riscv(leafnode)转换函数将每个叶子节点转换成实际risc-v核的测试指令包。
进一步的,步骤一中的多核risc-v处理器cache系统抽象模型为有向二分图模型dbg=<bvh,bvs,be>,其中主点集dvh中的点与能发起cache写操作的risc-v核一一对应;从点集dvs中的点与能发起cache读操作的risc-v核一一对应,de为有向边集。
更进一步的,有向边集de为主点集dvh中顶点vwi到从点集dvs中顶点vri的有向边eij=<vwi,vrj>的集合,有向边集de存在的充要条件是vri对应risc-v核发起的读操作结果来自vwi对应risc-v核发起的写操作。
更进一步的,步骤2的等价类划分算法分为以下四个步骤:
步骤2.1、对整个多核cache操作构成的激励空间进行划分,得到的每个一级子空间的发起cache写操作的risc-v核数相同;
步骤2.2、对一级子空间进行划分,得到的每一个二级子空间具有相同的写操作risc-v核;
步骤2.3、对二级子空间进行划分,得到的每一个三级子空间具有相同的读操作risc-v核;
步骤2.4、对三级子空间进行划分,得到的每一个四级子空间具有确定的risc-v核间cache变量读写对应关系。
更进一步的,步骤3中遍历激励空间树的算法为广度优先算法,具体包括以下步骤:
步骤3.1、首先对记录已被遍历节点信息的数据结构dead(root)函数、searched(ssi,j,k)函数、searched(ssi,j)函数、searched(ssi)函数、dead(ssi,j,k)函数、dead(ssi,j)函数和dead(ssi)函数进行初始化,初始值都为0;
步骤3.2、执行cycinc(i)函数,i从0开始递增,直到dead(ssi)函数返回0后判断searched(ssi)函数的值,如果为0,则将j、k、l都设为1,获取叶子节点ssi,j,k,l后跳到步骤3.5;如果为1,则跳到步骤3.3;
步骤3.3、执行cycinc(j)函数,j从0开始递增,直到dead(ssi,j)函数返回0后判断searched(ssi,j)函数的值,如果为0,则将k、l都设为1,获取叶子节点ssi,j,k,l后跳到步骤3.5;如果为1,则跳到步骤3.4;
步骤3.4、执行cycinc(k)函数,k从0开始递增,直到dead(ssi,j,k)函数返回0后判断searched(ssi,j,k)函数的值,如果为0,则将l设为1;如果为1,则l加1,获取叶子节点ssi,j,k,l后跳到步骤3.5;
步骤3.5、通过risc-v核相关的riscv()转换函数将叶子节点ssi,j,k,l转换成risc-v核的测试指令包后更新dead(root)函数、searched(ssi,j,k)函数、searched(ssi,j)函数、searched(ssi)函数、dead(ssi,j,k)函数、dead(ssi,j)函数和dead(ssi)函数的值;
步骤3.6、判断dead(root)函数的值,如果为0,则跳到步骤3.2;如果为1,则遍历完成。
更进一步的,步骤4中的riscv转换函数的实现步骤如下:
步骤4.1、初始cache变量地址a设为cache空间的首地址,初始锁变量地址sa设为uncache空间的首地址;
步骤4.2、从叶子节点leafnode的主点集中提取出一个主点vwi,生成一个对cache变量a的写操作单元wu,其中的地址a为步骤4.1中的cache变量地址,写数据d为随机数据,并从顶部将wu对应指令序列加入vwi对应risc-v核的测试指令包rctip队列中;
步骤4.3、通过cache系统有向二分图激励模型的有向边集获得每个主点vwi对应的从点集合
步骤4.4、对cache变量地址a加1,并判断叶子节点leafnode的主点集是否已被完全遍历,若没有则回到步骤4.2,否则进入下一步;
步骤4.5、生成一个同步单元su,从尾部将su对应指令序列加入所有risc-v核的测试指令包队列,且结束时对锁变量地址sa加1,生成新的同步变量sa。
更进一步的,测试指令包中包括写操作单元wu、读操作单元ru和同步单元su,写操作单元wu是对cache变量的写操作,读操作单元ru是对cache变量的读操作,同步单元su用于保证每个叶子节点对应的测试时间不重合。
3.有益效果
相比于现有技术,本发明的优点在于:
(1)本发明是一个独立于具体cache一致性协议的可扩展验证策略。该策略先将cache的激励抽象成数学模型,然后基于模型进行抽象激励生成,最后才通过处理器实现相关的转换函数生成实际的cache激励信息,解决了传统基于随机的多核risc-v处理器中cache验证难扩展的问题;
(2)本发明能够实现激励空间的无冗余均匀覆盖。由于该策略通过抽象和等价类划分的方法将原本扁平化的激励空间转换成了层次化树状激励空间,然后通过结构化的遍历算法确保特定覆盖率下激励空间的无冗余均匀覆盖,解决了传统基于随机的多核risc-v处理器的激励空间冗余和不均匀覆盖的问题,有着良好的实际应用价值。
附图说明
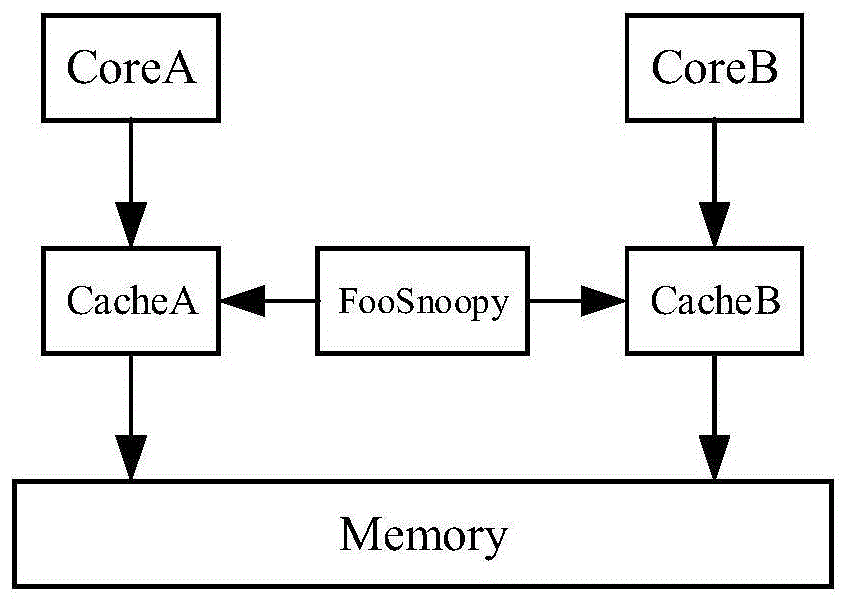
图1为两核risc-v处理器cache系统结构图;
图2为两核risc-v处理器cache激励的有向二分图;
图3为两核risc-v处理器cache系统的激励空间树状图;
图4为激励空间树cost的广度优先遍历算法流程图;
图5为传统随机激励和结构化激励方案下的覆盖率(coverage)与激励数(stinum)的关系图。
具体实施方式
本发明与对比文件专利cn201811636603.5的不同之处有以下几点:
1、验证目标不同:对比文件验证目标是解决多核处理器中的axi总线互联系统高效验证问题,而本发明验证目标是解决risc-v多核处理器中的cache访存系统高效验证问题,这两者是多核处理器中不同的功能模块;
2、验证激励的形式不同:对比文件中的总线互联系统验证激励是axi总线读写信号构成的总线请求,而本发明中的cache访存系统验证激励是risc-v指令构成的访存事务;
3、抽象图模型中点和边的含义不同:虽然两者解决验证问题的途径都是采用了图模型抽象建模,但是对比文件中图的点分别表示总线主设备和从设备,本发明中图的点分别表示发访存写操作的risc-v内核和发访存读操作的risc-v内核,对比文件中图的边表示总线主设备和从设备间的访问关系,本发明中图的边表示访存读操作和访存写操作间的依赖关系;
4、等价划分的过程不同:对比文件的三层树是因为axi总线上任意时刻任一主设备只能访问一个从设备,而本发明的四层树是因为cache访存系统中risc-v内核发起的访存写操作的结果可以被任意多个risc-v内核的访存读操作所获取,对比文件中的三层树不适用于cache访存系统的验证,本发明对验证方法进行了优化。
5、得到抽象图模型后的后续激励生成算法不同:对比文件的激励生成算法是调用axi总线的底层读写函数将图的叶子节点转换成axi总线的总线请求,本发明的激励生成算法是将图的叶子节点转换成risc-v指令构成的访存程序。
本发明与对比文件《cache一致性验证的结构化激励生成算法》(程开丰、罗汉青、梁利平,湖南大学学报自然科学版,2018,45(10):108-114)的区别有以下几点:
1、前提假设不同:论文中的方法假设“不同主核之间的从核互不冲突,即任意从核只响应一个主核的请求”,而本发明中取消了该项假设,即“不同主核之间的从核可以相同冲突,即任意从核可响应多个主核的请求”,这项不同造成虽然两者的激励空间树都是4层,但是本发明的节点数更多;
2、论文中的方法缺少针对具体cpu架构的访存指令生成算法的介绍,而本发明介绍了针对risc-v架构的访存指令生成算法。
下面结合说明书附图和具体的实施例,对本发明作详细描述。
实施例1
本方案提供了一种高效多核risc-v处理器的cache系统验证策略,包括下述步骤:
步骤一、建立基于有向二分图(directedbipartitegraph,dbg=<dvh,dvs,de>)的多核risc-v处理器cache系统抽象模型;其中主点集dvh中的点与能发起cache写操作的risc-v核一一对应;从点集dvs中的点与能发起cache读操作的risc-v核一一对应;dvh中顶点vwi到dvs中顶点vri之间存在有向边eij=<vwi,vrj>的充要条件是vri对应risc-v核发起的读操作结果来自vwi对应risc-v核发起的写操作;
步骤二、采用层次化等价类划分算法将原本无序的risc-v处理器cache激励空间转换成有序的4层激励空间树。其中层次化等价类划分算法分为4个子步骤,其中第一步为对整个空间进行划分,得到的每个一级子空间具有相同的写操作risc-v核数;第二步为对一级子空间进一步划分,得到的每个二级子空间具有相同的发起写操作的risc-v核集合;第三步为对二级子空间进一步划分,得到的每个三级子空间具有相同的读操作risc-v核子集;第四步为对三级子空间进一步划分,得到的每个四级子空间具有确定的各risc-v核间cache变量读写对应关系;
步骤三、采用广度优先算法对激励空间树的叶子节点集进行遍历,得到包含高层次激励信息的无冗余全覆盖叶子节点序列;
步骤四、采用risc-v核相关的riscv(leafnode)转换函数将每个叶子节点转换成实际risc-v核的测试指令包。
以下结合具体的实施例,进行阐述:
如图1所示,本实施例是一个foomc结构的最简单多核risc-v系统,foomc结构的risc-v处理器只有两个risc-v核,其中两个risc-v核分别记为corea和coreb,两核共享单一的主存memory,每个核都有各自缓存cachea和cacheb,采用了foosnoopy模块进行两个cache动作的监测,foosnoopy模块使用了mesi协议,维护了多核访存的一致性。
一、建立基于有向二分图的多核risc-v处理器cache系统抽象模型:
首先构建foomc的抽象模型dbg=<dvh,dvs,de>,具体抽象规则如下:
(1)主点集dvh:每个可发起cache变量写操作的risc-v核抽象成顶点后构成的集合;
(2)从点集dvs:每个可发起cache变量读操作的risc-v核抽象成顶点后构成的集合;
(3)有向边集de:dvh中顶点vwi到dvs中顶点vri之间存在有向边eij=<vwi,vrj>的充要条件是vri对应risc-v核发起的读操作结果来自vwi对应risc-v核发起的写操作。
按照上述规则,foomc的激励有向二分图模型如图2所示,其三元素分别为
dvh={corea,coreb}、dvs={corea,coreb}
和
de={<corea,corea>,<corea,coreb>,<coreb,corea>}
其中de中的元素表示该多核系统在某时刻存在两个cache变量的并发读写,这里记为v1和v2,其中一个是内核corea发起变量v1的写操作,然后内核corea和coreb后续发起了v1的读操作;另一个是内核coreb发起变量v2的写操作,然后内核corea后续发起了v2的读操作。
二、进行等价类划分:
基于前述多核risc-v处理器cache激励的有向二分图模型,采用等价类划分的方法对所有可能的多核cache操作构成的激励空间(cos,cacheoperationspace)进行等价类划分,以将原扁平化的cos转换成结构化的输入激励空间树(cost,cacheoperationspacetree)。在介绍具体的划分算法之前,先定义两个重要的参数。
1)nc(numberofcores):多核risc-v处理器系统中risc-v核总数;
2)nwc(numberofwritecores):当下发起cache写操作的risc-v核数。
显然有下面的关系:
nwc≤nc(1)
对cos进行4层的划分,每一层都是上一层的细化,具体流程如下:
第一层:对整个cos进行划分,划分的依据是每个子集的nwc相同。根据式(1),cos可被划分成nc个子集,即ep(cos)={ss1,ss2,ssnc},其中子集ssi的下标i表示写操作risc-v核数,取值范围为1≤i≤nc;
第二层:对于每个集合ssi进行划分,划分的依据是每个子集具有相同的写操作risc-v核。每个ssi可被划分成
第三层:对于每个集合ssi,j进行划分,划分的依据是每个子集具有相同的读操作risc-v核子集。多核cache变量读写操作中可存在单写多读swmr(singlewritemultipleread)的特点,swmr为多核cache变量读写操作存在的基本现象,即只有一个写,但参与的读操作risc-v核数没有要求。而该层就是要确定参与所有swmr操作的读操作risc-v核集,所以该问题本质上是集合dvs的子集问题。根据排列组合规律,该过程有2nc-1种可能性,即ep(ssi,j)={ssi,j,1,ssi,j,2…},其中子集ssi,j,k有三个下标:前两个i,j表示是对ssi,j的划分;第三个k是特征编号,其取值范围为1≤k≤2nc-1;
第四层:对于每个集合ssi,j,k进行划分,划分的依据是每个子集具有确定的各risc-v核间cache变量读写关系。由于不同变量的swmr间可以无约束并发,故该过程本质是对第三层中的读操作risc-v核集进行有序覆盖问题。先定义对集合ssi,j,k进行i阶集合覆盖,得到的所有覆盖构成的集合记为sc(k,i)(setcoverage),相应所有可能的覆盖数为|sc(k,i)|;然后对每个元素个数都为i的覆盖,进行“元素个数为i的写操作核集合”到“元素个数为i的读操作核集合”之间的双射对应,每次双射所有可能的对应数为排列数i!。所以ssi,j,k可被划分成个|sc(k,i)|*i!个子集,即ep(ssi,j,k)={ssi,j,k,1,ssi,j,k,2…},其中子集ssi,j,k,l有三个下标:前三个i,j,k表示是对ssi,j,k的划分;第四个l是特征编号,其取值范围为1≤l≤sc(k,i)*i!。
经过上述算法的划分,原来扁平化的cos就被转换成4层的cost,cost的每个叶子节点就代表了一个多核访存事务,因为其描述了有哪些核发起了cache变量的写操作,并给出了每个写操作所对应的读操作。对只包含两个risc-v核的最简单多核系统(foomc),其cos按照上述算法进行划分,得到相应的cost示意图如图3。其中每一层节点的含义如表1所示:
表1foomc的cost各层节点含义表
三、对cost进行遍历:
如图4所示,在得到激励空间树cost后,接下来就可以进行结构化的激励生成,这里采用广度优先算法对激励空间树cost进行遍历,得到包含高层次激励信息的无冗余全覆盖叶子节点序列。其中cycinc(x)函数是对索引变量x进行循环递增,当x超过最大值时,回归到最小值;searched(node)函数返回1时,表示以node为根节点的子树中有叶子节点已经被遍历,否则返回0;dead(node)返回1时表示以node为根节点的子树中所有叶子节点都已经被遍历,否则返回0。其中的6个数组searched(ssi,j,k)、searched(ssi,j)、searched(ssi)、dead(ssi,j,k)、dead(ssi,j)和dead(ssi)用于记录已被遍历节点的信息,root为激励空间树cost的根节点。
具体遍历算法流程分为以下几步:
(1)首先对记录已被遍历节点信息的数据结构dead(root)函数、searched(ssi,j,k)函数、searched(ssi,j)函数、searched(ssi)函数、dead(ssi,j,k)函数、dead(ssi,j)函数和dead(ssi)函数进行初始化,初始值都为0;
(2)执行cycinc(i)函数,i从0开始递增,直到dead(ssi)函数返回0后判断searched(ssi)函数的值,如果为0,则将j、k、l都设为1,获取叶子节点ssi,j,k,l后跳到第(5)步;如果为1,则跳到第(3)步;
(3)执行cycinc(j)函数,j从0开始递增,直到dead(ssi,j)函数返回0后判断searched(ssi,j)函数的值,如果为0,则将k、l都设为1,获取叶子节点ssi,j,k,l后跳到第(5)步;如果为1,则跳到第(4)步;
(4)执行cycinc(k)函数,k从0开始递增,直到dead(ssi,j,k)函数返回0后判断searched(ssi,j,k)函数的值,如果为0,则将l设为1;如果为1,则l加1,获取叶子节点ssi,j,k,l后跳到第(5)步;
(5)通过risc-v核相关的riscv()转换函数将叶子节点ssi,j,k,l转换成risc-v核的测试指令包后更新dead(root)函数、searched(ssi,j,k)函数、searched(ssi,j)函数、searched(ssi)函数、dead(ssi,j,k)函数、dead(ssi,j)函数和dead(ssi)函数的值;
(6)判断dead(root)函数的值,如果为0,则跳到第(2)步;如果为1,则遍历完成。
四、转换:
通过risc-v核相关的riscv(leafnode)转换函数将每个叶子节点转换成每个risc-v核的测试指令包(rctip,risc-vcoretestinstructionpackage)。这里的rctip中包含3类不同的子操作单元,写操作单元(wu,writeunit)、读操作单元(ru,readunit)和同步单元(su,synchronizationunit)。其中wu是为了完成对cache变量的写操作,ru是为了完成对cache变量的读操作,而su是通过同步等待机制来保证每个叶子节点对应的测试在时间轴上不重合。上述各操作单元与risc-v指令间的对应关系总结如表2所示:
表2测试操作单元与risc-v指令间的对应关系表
在上述结果的基础上,riscv(leafnode)转换函数的实现步骤如下:
(1)初始cache变量地址a设为cache空间的首地址;初始锁变量地址sa设为uncache空间的首地址;
(2)从叶子节点leafnode的主点集中提取出一个主点(假设为vwi),生成一个wu(a,d),其中的地址a为前述cache变量地址,d为随机数据,并从顶部push入vwi对应risc-v核的测试指令包rctip队列中;
(3)通过cache系统有向二分图激励模型的有向边集获得每个主点vwi对应的从点集合
(4)对cache变量地址a加1,并判断叶子节点leafnode的主点集是否已被完全遍历,若没有则回到第5步,否则进入下一步;
(5)生成一个su(sa),从尾部push入所有risc-v核的测试指令包rctip队列,且结束时对锁变量地址sa加1,产生一个。
如图5所示,为了评估本发明的有益效果,实验对比了传统随机激励和结构化激励两种方案下的覆盖率值与激励数的关系,在覆盖率收敛时,传统随机和结构化激励数目分别为9712和8747,所以相比传统随机激励,结构化的激励生成策略能使行覆盖率更快地收敛,且收敛时的激励数能减少9.9%。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 还没有人留言评论。精彩留言会获得点赞!