一种基于双流特征融合的语义分割方法与流程
本发明是一种基于全卷积神经网络的语义分割方法,特别是基于双流特征融合的语义分割方法。
背景技术:
:语义分割是许多计算机视觉应用的基本技术,如场景理解、无人驾驶。随着卷积神经网络特别是全卷积神经网络(fcn)的发展,在基准测试中取得了许多有前途的成果。fcn具有典型的编码器-解码器结构——语义信息首先通过编码器嵌入到特征图中,解码器负责生成分割结果。通常,编码器是预先训练的卷积模型来提取图像特征,解码器包含多个上采样组件来恢复分辨率。尽管编码器最重要的特征图可能具有高度的语义性,但由于分辨率不足,它在分割图中重建精确细节的能力有限,这在现代主干模型中非常常见。语义分割既需要丰富的空间信息,又需要相当大的感受野,因此,利用空洞卷积来扩大感受野成为了现代网络的主流思想。现代语义分割框架通常将预先训练的主干卷积模型的低级和高级特征结合起来,以提高性能,通常选择残差块和跳跃连接作为结合方式。除此之外,多尺度信息也为语义分割的精确性提供了有力支撑,金字塔池化通过获取不同尺度的特征图再将其融合这一方法,成为了语义分割最常用的模块之一。今年来,rgb-d的广泛使用为语义分割提供了丰富的辅助信息,将深度图作为第二输入流与原始的rgb输入流相融合,成为了现阶段室内场景分割的主流方法。技术实现要素:为了解决
背景技术:
中的问题,本发明提供了一种对于深度学习的卷积神经网络做一系列多尺度的对称跳跃式连接融合的室内场景语义分割方法,以提高近年来分割
技术领域:
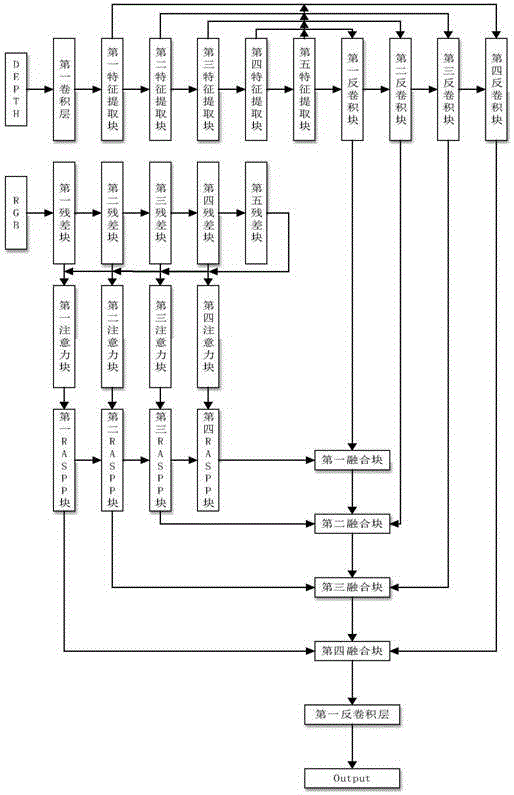
中的精确度和图像中各类标签的准确度。本发明采用的技术方案包括以下步骤:步骤1:选取n幅原始图像的rgb图、深度图以及原始图像对应的真实语义分割图,真实语义分割图为原始图像进行真实语义分割处理得到的图像,所有原始图像的rgb图、深度图以及原始图像对应的真实语义分割图构成训练集;步骤2:构建卷积神经网络;步骤3:将训练集中每幅原始图像的rgb图和深度图输入卷积神经网络进行训练输出对应的语义分割预测图,计算语义分割预测图与真实语义分割图之间的损失函数值,损失函数采用负对数似然损失函数negativelog-liklihood(nllloss)获得;步骤4:重复执行步骤3共v次,共得到n×v个损失函数值;将n×v个损失函数值中值最小的损失函数值对应的权值矢量和偏置项作为卷积神经网络的最优权值矢量和最优偏置项,完成卷积神经网络的训练;步骤5:将待语义分割图像输入步骤4训练好的卷积神经网络进行预测处理,输出得到待语义分割图像对应的预测语义分割图。所述步骤2具体为:卷积神经网络包括依次设置的输入层、隐藏层和输出层,输入层包括rgb图输入层和深度图输入层,隐藏层包括rgb图处理模块、深度图处理模块、融合模块和第一个反卷积层。深度图处理模块包括依次连接的第一卷积块、第一特征提取块、第二特征提取块、第三特征提取块、第四特征提取块、第五特征提取块、第一反卷积块、第二反卷积块、第三反卷积块和第四反卷积块,第一反卷积块输入端接收第五特征提取块和第四特征提取块的共同输出,第二反卷积块输入端接收第五特征提取块和第三特征提取块的共同输出,第三反卷积块输入端接收第五特征提取块和第二特征提取块的共同输出,第四反卷积块输入端接收第五特征提取块和第一特征提取块的共同输出。rgb图处理模块包括三个分支,第一个分支主要由依次连接的五个残差块组成,第二个分支主要由依次连接的四个注意力块组成,第三个分支主要由依次连接的四个残差aspp块组成;第一个注意力块的输入端接收第五个残差块和第一个残差块的共同输出,第二个注意力块的输入端接收第五个残差块和第二个残差块的共同输出,第三个注意力块的输入端接收第五个残差块和第三个残差块的共同输出,第四个注意力块的输入端接收第五个残差块和第四个残差块的共同输出;第一个注意力块、第二个注意力块、第三个注意力块和第四个注意力块的输出分别输入第一个残差aspp块、第二个残差aspp块、第三个残差aspp块和第四个残差aspp块。融合模块包括依次连接的四个融合块,第一个反卷积块和第四个残差aspp块的输出均输入第一个融合块,第二个反卷积块和第三个残差aspp块的输出均输入第二个融合块,第三个反卷积块和第二个残差aspp块的输出均输入第三个融合块,第四个反卷积块和第一个残差aspp块的输出均输入第四个融合块。第四个融合块的输出经第一个反卷积层从输出层输出。每个所述的特征提取块均由vgg16网络中的基本块组成,第一特征提取块、第二特征提取块、第三特征提取块、第四特征提取块、第五特征提取块分别由vgg16网络中第一个下采样块、第二个下采样块、第三个下采样块、第四个下采样块、第五个下采样块组成,每个下采样块均包括依次连接的多个卷积层和一个池化层,多个卷积层依次连接;第一个下采样块和第二个下采样块均包括依次连接的两个卷积层和一个池化层,第三个下采样块、第四个下采样块和第五个下采样块均包括依次连接三个卷积层和一个池化层。每个残差块均由resnet34网络中的基本块组成,第一个残差块主要由resnet34网络中依次连接的第一卷积层、第一批量归一化层和第一激活层组成,且第一个残差块中的第一卷积层步长为2;第二个残差块主要由resnet34网络中依次连接的第一池化层和第一下采样块layer1组成,第三个残差块由resnet34网络中的第二下采样块layer2组成;第四个残差块由resnet34网络中的第三下采样块layer3组成;第五个残差块由resnet34网络中的第四下采样块layer4组成。每个所述的注意力块将输入的第五个残差块尺寸转置为与对应输入的另一个残差块相匹配的尺寸,然后将输入的两个残差块相乘后的结果作为注意力块的输出。每个所述的反卷积块均包括依次连接的一个反卷积层和引入跳跃连接操作的三个卷积块,反卷积块中的三个卷积块依次连接,反卷积块中反卷积层的输出与三个卷积块的输出跳跃连接作为反卷积块的输出;且每个所述的反卷积块中的反卷积层步长均为2;每个融合块均由引入跳跃连接操作的三个依次设置的卷积块组成,融合块中融合块的输入与三个卷积块的输出跳跃连接作为融合块的输出。每个所述的残差aspp块均由并行设置的三个空洞卷积块串行一个卷积块组成,三个空洞卷积块并联的一端作为残差aspp块的输入端,并联的另一端经串联的卷积块后的输出作为残差aspp块的输出端。每个卷积块均由依次连接的卷积层、批量归一化层、激活层组成;所述rgb图输入层的输入为rgb图,rgb图输入层输出输入图像的r通道分量、g通道分量和b通道分量;所述深度图输入层的输入为深度图,深度图经过第一卷积块后处理后具有与rgb图一样的三通道。本发明的有益效果:1)本发明方法构建了全卷积神经网络,与其他方法相比,本方法用步长为2的卷积层取代了现阶段常用的池化层。由于池化层会对图像造成不可逆的特征损失,且语义分割对预测精度的要求很高,因此选择了步长为2的卷积层作为替代方法。该卷积层可以得到与池化层相同的效果,并能保证图片特征不会有过大损失。2)本发明方法采用空洞卷积块扩大网络感受野。池化层的优点不只是能有效缩减图像尺寸,还可有效扩大感受野以保证提取到更多的全局信息。因此在用步长为2的卷积层替代池化层时,感受野没有得到有效扩充,损失了部分全局信息。因此加入空洞卷积,以保证网络感受野不变甚至增大。空洞卷积与步长为2的卷积层相结合,可以保证网络提取到最多的局部特征与全局特征。3)本发明方法在搭建卷积网络时采用了跳跃连接作为主要的连接方式,以构成全残差网络。残差网络在语义分割方向上一直具有很优秀的表现,因此在本发明中加入跳跃连接,可以有效补偿图像在编码过程中的损失,以保证最后的预测精度。附图说明图1为本发明方法的总体实现框图;图2a为同一场景的第1幅原始的室内场景图像;图2b为利用本发明方法对图2a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图3a为同一场景的第2幅原始的室内场景图像;图3b为利用本发明方法对图3a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图4a为同一场景的第3幅原始的室内场景图像;图4b为利用本发明方法对图4a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图5a为同一场景的第4幅原始的室内场景图像;图5b为利用本发明方法对图5a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图6a为同一场景的第4幅原始的室内场景图像;图6b为利用本发明方法对图6a所示的原始的室内场景图像进行预测,得到的预测语义分割图像。具体实施方式以下结合附图和实施例对本发明作进一步详细描述。本发明提出的一种基于双流特征融合的语义分割方法,其总体实现框图如图1所示,其包括训练阶段和测试阶段两个过程;所述的训练阶段过程的具体步骤为:步骤1_1:选取n幅原始图像的rgb图和深度图构成训练集,将训练集中的第k幅原始图像的rgb图记为原始图像的深度图记为对应的真实语义分割图像记为{gk(x,y)};其中,k为正整数,1≤k≤n,1≤x≤w,1≤y≤h,w表示原始图像的宽度,h表示原始图像的高度,如取w=640、h=480,rk(x,y)表示中坐标位置为(x,y)的像素点的像素值,dk(x,y)表示{dk(x,y)}中坐标位置为(x,y)的像素点的像素值,gk(x,y)表示{gk(x,y)}中坐标位置为(x,y)的像素点的像素值;本实验中的数据集直接选用的是nyudv2中的1449幅图像。步骤1_2:构建卷积神经网络:卷积神经网络包括输入层、隐藏层和输出层;其中隐层包括依次设置的第1个卷积层、第1个批量归一化层、第1个激活层、第1个特征提取块、第2个特征提取块、第3个特征提取块、第4个特征提取块、第5个特征提取块、第1个反卷积块、第2个反卷积块、第3个反卷积块、第4个反卷积块、第1个残差块、第2个残差块、第3个残差块、第4个残差块、第5个残差块、第1个attention块、第2个attention块、第3个attention块、第4个attention块、第1个residualaspp(残差aspp)块、第2个residualaspp块、第3个residualaspp块、第4个residualaspp块、第1个融合块、第2个融合块、第3个融合块、第4个融合块、第1个反卷积层。其中,所有反卷积层的卷积核大小均为4x4、补零参数均为1、步长均为2。对于输入层,输入层的输入端接收原始图像的rgb图和深度图,输入层的输出端输出原始输入图像的r通道分量、g通道分量和b通道分量,输入层的输出量是隐层的输入量;其中,深度图与rgb图一样具有三通道,即经过第一卷积块后也被处理成三个分量,且输入的原始立体图像的宽度为w、高度为h。对于隐层:其中包含的特征提取块都是由vgg16中的基本下采样块构成,第1个特征提取块由vgg16网络的第一下采样块组成;第2个特征提取块由vgg16网络的第二下采样块组成;第3个特征提取块由vgg16网络的第三下采样块组成;第4个特征提取块由vgg16网络的第四下采样块组成;第5个特征提取块由vgg16网络的第五下采样块组成。残差块都是由resnet34中的基本块构成,第1个残差块由resnet34网络的第一卷积层、第一批量归一化层和第一激活层组成;第2个残差块由resnet34网络的第一池化层和layer1组成;第3个残差块由resnet34网络的layer2组成;第4个残差块由resnet34网络的layer3组成;第5个残差块由resnet34网络的layer4组成。第1个特征提取块的输入是单通道的深度图像,经过第1个卷积层的处理输出3幅特征图,第1个卷积层的卷积核大小(kernel_size)为1x1、卷积核个数(filters)为3、补零(padding)参数为1、步长(stride)为1,第一激活层的激活方式为“relu”。第1个特征提取块的输入是第1激活层的输出,经过第1个特征提取块处理输出64幅特征图,将64幅特征图构成的集合记为p1,并且p1中的每幅特征图的宽度为高度为第2个特征提取块的输入是第1个特征提取块的输出,经过第2个特征提取块的处理输出64幅特征图,将64幅特征图构成的集合记为p2,并且p2中的每幅特征图的宽度为高度为第3个特征提取块的输入是第2个特征提取块的输出,经过第3个特征提取块的处理输出408幅特征图,将408幅特征图构成的集合记为p3,并且p3中的每幅特征图的宽度为高度为第4个特征提取块的输入是第3个特征提取块的输出,经过第4个特征提取块的处理输出256幅特征图,将256幅特征图构成的集合记为p4,并且p4中的每幅特征图的宽度为高度为第5个特征提取块的输入是第4个特征提取块的输出,经过第5个特征提取块的处理输出540幅特征图,将540幅特征图构成的集合记为p5,并且p5中的每幅特征图的宽度为高度为第1个残差块的输入是三通道的原始图像,经过第1个残差块的处理输出64幅特征图,将64幅特征图构成的集合记为p1,并且p1中的每幅特征图的宽度为高度为第2个残差块的输入是第1个残差块的输出,经过第2个残差块的处理输出64幅特征图,将64幅特征图构成的集合记为p2,并且p2中的每幅特征图的宽度为高度为第3个残差块的输入是第2个残差块的输出,经过第3个残差块的处理输出408幅特征图,将408幅特征图构成的集合记为p3,并且p3中的每幅特征图的宽度为高度为第4个残差块的输入是第3个残差块的输出,经过第4个残差块的处理输出256幅特征图,将256幅特征图构成的集合记为p4,并且p4中的每幅特征图的宽度为高度为第5个残差块的输入是第4个残差块的输出,经过第5个残差块的处理输出540幅特征图,将540幅特征图构成的集合记为p5,并且p5中的每幅特征图的宽度为高度为第1个residualaspp块由并行设置的三个空洞卷积块串行一个卷积块组成。三个空洞卷积块包括第2卷积层、第2批量归一化层、第2激活层、第3卷积层、第3批量归一化层、第3激活层、第4卷积层、第4批量归一化层、第4激活层,串行的卷积块包括第5卷积层、第5批量归一化层、第5激活层。第1个residualaspp块的输入端接收第1个attention块、第5残差块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为q1。其中,第2卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率(dilaterate)为1;第3卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率为4;第4卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率为8;第5卷积层的卷积核大小为1x1、卷积核个数为64、补零参数为1、步长为1;第2、3、4、5激活层的激活方式为“relu”。q1中的每幅特征图的宽度为高度为第2个residualaspp块由并行设置的三个空洞卷积块串行一个卷积块组成。三个空洞卷积块包括第6卷积层、第6批量归一化层、第6激活层、第7卷积层、第7批量归一化层、第7激活层、第8卷积层、第8批量归一化层、第8激活层,串行的卷积块包括第9卷积层、第9批量归一化层、第9激活层。第2个residualaspp块的输入端接收第2个attention块、第5残差块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为q2。其中,第6卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率(dilaterate)为1;第7卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率为4;第8卷积层的卷积核大小为3x3、卷积核个数为64、补零参数为1、步长为1、空洞率为8;第9卷积层的卷积核大小为1x1、卷积核个数为64、补零参数为1、步长为1;第6、7、8、9激活层的激活方式为“relu”。q2中的每幅特征图的宽度为高度为第3个residualaspp块由并行设置的三个空洞卷积块串行一个卷积块组成。三个空洞卷积块包括第10卷积层、第10批量归一化层、第10激活层、第11卷积层、第11批量归一化层、第11激活层、第12卷积层、第12批量归一化层、第12激活层,串行的卷积块包括第13卷积层、第13批量归一化层、第13激活层。第3个residualaspp块的输入端接收第3个attention块、第5残差块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出128幅特征图,将128幅特征图构成的集合记为q3。其中,第10卷积层的卷积核大小为3x3、卷积核个数为128、补零参数为1、步长为1、空洞率(dilaterate)为1;第11卷积层的卷积核大小为3x3、卷积核个数为128、补零参数为1、步长为1、空洞率为4;第40卷积层的卷积核大小为3x3、卷积核个数为128、补零参数为1、步长为1、空洞率为8;第13卷积层的卷积核大小为1x1、卷积核个数为128、补零参数为1、步长为1;第10、11、40、13激活层的激活方式为“relu”。q3中的每幅特征图的宽度为高度为第4个residualaspp块由并行设置的三个空洞卷积块串行一个卷积块组成。三个空洞卷积块包括第14卷积层、第14批量归一化层、第14激活层、第15卷积层、第15批量归一化层、第15激活层、第16卷积层、第16批量归一化层、第16激活层,串行的卷积块包括第17卷积层、第17批量归一化层、第17激活层。第4个residualaspp块的输入端接收第4个attention块、第5残差块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出256幅特征图,将256幅特征图构成的集合记为q4。其中,第14卷积层的卷积核大小为3x3、卷积核个数为256、补零参数为1、步长为1、空洞率(dilaterate)为1;第15卷积层的卷积核大小为3x3、卷积核个数为256、补零参数为1、步长为1、空洞率为4;第16卷积层的卷积核大小为3x3、卷积核个数为256、补零参数为1、步长为1、空洞率为8;第17卷积层的卷积核大小为1x1、卷积核个数为256、补零参数为1、步长为1;第14、15、16、17激活层的激活方式为“relu”。q4中的每幅特征图的宽度为高度为第1个融合块由依次设置的引入跳跃连接操作的三个卷积块组成。包括第18卷积层、第18批量归一化层、第18激活层、第19卷积层、第19批量归一化层、第19激活层、第20卷积层、第20批量归一化层、第20激活层。第1个融合块的输入端接收第4个residualaspp块和第1反卷积块的输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出256幅特征图,将256幅特征图构成的集合记为b1。其中,第18、19、20卷积层的卷积核大小均为3x3、卷积核个数均为256、补零参数均为1、步长均为1;第18、19、20激活层的激活方式为“relu”。b1中的每幅特征图的宽度为高度为第2个融合块由依次设置的引入跳跃连接操作的三个卷积块组成。包括第21卷积层、第21批量归一化层、第21激活层、第22卷积层、第22批量归一化层、第22激活层、第23卷积层、第23批量归一化层、第23激活层。第2个融合块的输入端接收第3个residualaspp块、第1个融合块和第2个反卷积块的输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出128幅特征图,将128幅特征图构成的集合记为b2。其中,第21、22、23卷积层的卷积核大小均为3x3、卷积核个数均为128、补零参数均为1、步长均为1;第21、22、23激活层的激活方式为“relu”。b2中的每幅特征图的宽度为高度为第3个融合块由依次设置的引入跳跃连接操作的三个卷积块组成。包括第24卷积层、第24批量归一化层、第24激活层、第25卷积层、第25批量归一化层、第25激活层、第26卷积层、第26批量归一化层、第26激活层。第3个融合块的输入端接收第2个residualaspp块、第2个融合块和第3反卷积块的输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为b3。其中,第24、25、26卷积层的卷积核大小均为3x3、卷积核个数均为64、补零参数均为1、步长均为1;第24、25、26激活层的激活方式为“relu”。b3中的每幅特征图的宽度为高度为第4个融合块由依次设置的引入跳跃连接操作的三个卷积块组成。包括第27卷积层、第27批量归一化层、第27激活层、第28卷积层、第28批量归一化层、第28激活层、第29卷积层、第29批量归一化层、第29激活层。第4个融合块的输入端接收第1个residualaspp块、第3个融合块和第4反卷积层的输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为b4。其中,第27、28、29卷积层的卷积核大小均为3x3、卷积核个数均为64、补零参数均为1、步长均为1;第27、28、29激活层的激活方式为“relu”。b4中的每幅特征图的宽度为高度为第1反卷积层的输入端接收第4个融合块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出40幅特征图。第1反卷积块由依次设置的一个反卷积层和引入跳跃连接操作的三个卷积块组成。包括第2反卷积层、第30卷积层、第30批量归一化层、第30激活层、第31卷积层、第31批量归一化层、第31激活层、第32卷积层、第32批量归一化层、第32激活层。第1反卷积块的输入端接收第4个特征提取块和第5个特征提取块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出256幅特征图,将256幅特征图构成的集合记为u1。其中,第30、31、32卷积层的卷积核大小均为3x3、卷积核个数均为256、补零参数均为1、步长均为1;第30、31、32激活层的激活方式为“relu”。u1中的每幅特征图的宽度为高度为第2反卷积块由依次设置的一个反卷积层和引入跳跃连接操作的三个卷积块组成。包括第3反卷积层、第33卷积层、第33批量归一化层、第33激活层、第34卷积层、第34批量归一化层、第34激活层、第35卷积层、第35批量归一化层、第35激活层。第2反卷积块的输入端接收第3个特征提取块和第5个特征提取块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出128幅特征图,将128幅特征图构成的集合记为u2。其中,第33、34、35卷积层的卷积核大小均为3x3、卷积核个数均为128、补零参数均为1、步长均为1;第33、34、35激活层的激活方式为“relu”。u2中的每幅特征图的宽度为高度为第3反卷积块由依次设置的一个反卷积层和引入跳跃连接操作的三个卷积块组成。包括第4反卷积层、第36卷积层、第36批量归一化层、第36激活层、第37卷积层、第37批量归一化层、第37激活层、第38卷积层、第38批量归一化层、第38激活层。第3反卷积块的输入端接收第2个特征提取块、第5个特征提取块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为u3。其中,第36、37、38卷积层的卷积核大小均为3x3、卷积核个数均为64、补零参数均为1、步长均为1;第36、37、38激活层的激活方式为“relu”。u3中的每幅特征图的宽度为高度为第4反卷积块由依次设置的一个反卷积层和引入跳跃连接操作的三个卷积块组成。包括第5反卷积层、第39卷积层、第39批量归一化层、第39激活层、第40卷积层、第40批量归一化层、第40激活层、第41卷积层、第41批量归一化层、第41激活层。第4反卷积块的输入端接收第1个特征提取块、第5个特征提取块输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出64幅特征图,将64幅特征图构成的集合记为u4。其中,第39、40、41卷积层的卷积核大小均为3x3、卷积核个数均为64、补零参数均为1、步长均为1;第39、40、41激活层的激活方式为“relu”。u4中的每幅特征图的宽度为高度为对于输出层,输入端接收第一反卷积层输出端输出图像的r通道分量、g通道分量和b通道分量,输出端输出40幅特征图。步骤1_3:将训练集中每幅原始的室内场景图像作为原始输入图像,输入到卷积神经网络中进行训练,得到训练集中每幅原始的室内场景图像对应的40幅语义分割预测图,将{iq(i,j)}对应的40幅语义分割预测图构成的集合记为步骤1_4:计算训练集中的每幅原始的室内场景图像对应的40幅语义分割预测图构成的集合与对应的真实语义分割图像处理成的40幅独热编码图像构成的集合之间的损失函数值,将与之间的损失函数值记为采用negativelog-liklihood(nllloss)获得。步骤1_5:重复执行步骤1_3和步骤1_4共v次,得到卷积神经网络分类训练模型,并共得到n×v个损失函数值;然后从n×v个损失函数值中找出值最小的损失函数值;接着将值最小的损失函数值对应的权值矢量和偏置项对应作为卷积神经网络分类训练模型的最优权值矢量和最优偏置项,对应记为wbest和bbest;其中,v>1,在本实施例中取v=2000。所述的测试阶段过程的具体步骤为:步骤2_1:令表示待语义分割的室内场景图像;其中,1≤i'≤w',1≤j'≤h',w'表示的宽度,h'表示的高度,表示中坐标位置为(i,j)的像素点的像素值。步骤2_2:将的r通道分量、g通道分量和b通道分量输入到卷积神经网络分类训练模型中,并利用wbest和bbest进行预测,得到对应的预测语义分割图像,记为其中,表示中坐标位置为(i',j')的像素点的像素值。为了进一步验证本发明方法的可行性和有效性,进行实验。使用基于python的深度学习框架pytorch0.4.1搭建全残差空洞卷积神经网络的架构。采用室内场景图像数据库nyudv2测试集来分析利用本发明方法预测得到的室内场景图像(取654幅室内场景图像)的分割效果如何。这里,利用评估语义分割方法的3个常用客观参量作为评价指标,即类精确度(classacurracy)、平均像素准确率(meanpixelaccuracy,mpa)、分割图像与标签图像交集与并集的比值(meanintersectionoverunion,miou)来评价预测语义分割图像的分割性能。利用本发明方法对室内场景图像数据库nyudv2测试集中的每幅室内场景图像进行预测,得到每幅室内场景图像对应的预测语义分割图像,反映本发明方法的语义分割效果的类精确度ca、平均像素准确率mpa、分割图像与标签图像交集与并集的比值miou如表1所列。从表1所列的数据可知,按本发明方法得到的室内场景图像的分割结果是较好的,表明利用本发明方法来获取室内场景图像对应的预测语义分割图像是可行性且有效的。表1利用本发明方法在测试集上的评测结果mpa74.6%ca59.3%miou46.4%图2a给出了同一场景的第1幅原始的室内场景图像;图2b给出了利用本发明方法对图2a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图3a给出了同一场景的第2幅原始的室内场景图像;图3b给出了利用本发明方法对图3a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图4a给出了同一场景的第3幅原始的室内场景图像;图4b给出了利用本发明方法对图4a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图5a给出了同一场景的第4幅原始的室内场景图像;图5b给出了利用本发明方法对图5a所示的原始的室内场景图像进行预测,得到的预测语义分割图像;图6a给出了同一场景的第4幅原始的室内场景图像;图6b给出了利用本发明方法对图6a所示的原始的室内场景图像进行预测,得到的预测语义分割图像。对比图2a和图2b,对比图3a和图3b,对比图4a和图4b,对比图5a和图5b,对比图6a和图6b,可以看出利用本发明方法得到的预测语义分割图像的分割精度较高。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1