基于表示学习和多模态卷积神经网络的用户推荐方法与流程
本发明属于数据挖掘、社交网络分析技术领域,特别涉及一种基于表示学习和多模态卷积神经网络的用户推荐方法。
背景技术:
近年来,随着facebook、twitter、flickr、youtube、新浪微博等社交网络的兴起和迅速普及,在线社交网络已经逐渐发展成为全球化的超大网络,越来越多的用户使用社交网站分享生活、传播信息、交流互动。在这样的背景下,社交网络引起了越来越多的学者的关注,并对社交网络展开了一系列的研究,例如个性化推荐、信息传播、链接预测等。其中,链接预测可以帮助用户了解网络的演化机制、也可以通过社交网站发现感兴趣的社团或者用户,从而扩大用户的社交圈子。因此,链接预测对用户的推荐具有重要意义。
现阶段,针对链接预测的研究主流的方法有三类,包括基于节点相似度的分析、基于最大似然估计的分析和基于概率相关模型的分析。其中,基于节点相似度的分析是选取节点的某些重要特征,利用这些属性来定义节点的相似度,它基于这样一种逻辑,即节点相似度比较大的节点在未来产生链接的概率越高。用来衡量相似度的指标有很多,例如:liben-nowell等人在《thelink-predictionproblemforsocialnetworks》提出的公共邻域(cn)、jaccard系数、adamic/adar指标(aa)、优先链接(pa)、katz等;基于最大似然估计的分析,由于每次预测都要生成多个样本网络结构图,因此适用于规模不太大的层次结构网络,例如:clauset等人在《hierarchicalstructureandthepredictionofmissinglinksinnetworks》中认为链接是网络内在层次结构的反映,通过建立一个有明显层次组织的网络模型进行链接预测;基于概率模型的分析,利用社交网络中的节点和边构造一个统计模型来进行链接预测,它可以得到结构化数据的关系,因而比普通的没有考虑实体和边关系的模型效果好很多。例如:lise等人在《learningprobabilisticmodelsoflinkstructure》中将节点和边的属性结合在一起,构造了一种联合概率分布用来进行链接预测。
以上的研究主要关注于社交网络本身的结构,没有考虑到用户自身因素对链接产生的影响,比如用户属性和用户文本信息。
技术实现要素:
为了更好地为用户推荐相同兴趣的用户,为用户提供更好的社交体验,本发明提出一种基于表示学习和多模态卷积神经网络的用户推荐方法,如图2,包括以下步骤:
s1、从社交网络的公共平台下载用户数据,并对用户数据进行预处理,下载的用户数据包括网络结构信息和用户文本信息;
s2、基于表示学习分别根据网络结构信息和用户文本信息构建网络结构特征向量和用户文本特征向量;
s3、根据网络结构特征向量计算用户相似度,选择与当前待测用户最相似的k个作为最相关用户,利用注意力机制提取用户文本特征向量中的关键信息;
s4、构建卷积神经网络,并在卷积神经网络的卷积层之前建立一个融合层,将网络结构特征与用户文本特征的关键信息进行融合,得到网络节点矩阵;
s5、利用网络节点矩阵完成神经网络的训练,并提取待测用户当前时刻的用户数据;
s6、将当前时刻的待测用户的特征空间向量输入卷积神经网络,得到下一时刻待测用户可能产生的用户关系,并将预测的用户关系推送给待测用户。
进一步的,根据网络结构特征向量计算用户相似度包括:
对网络进行采样,并选取网络中任意一个节点进行随机游走,得到一个节点序列;
进行多次循环遍历网络,得到网络的全局节点序列集,得到网络中所有节点的d维全局特征向量。
进一步的,基于表示学习构建用户文本特征包括:
对获得的用户文本数据进行分词,并提取用户文本数据的关键词;
将每个用户文本数据中的每个关键词转换为l维向量,每个用户文本数据的长度统一设置为m,长度不足m的用0进行填充,使得用户文本数据的长度为m;
根据节点的相关性,选取k个与该节点最相似的节点作为该节点的最相关用户组;
根据统一长度的用户文本数据,创建所有用户的句子矩阵;
根据时间的变化对用户兴趣进行拟合,得到根据时间变化的用户兴趣;
基于所有用户的句子矩阵和拟合的用户兴趣,得到用户文本特征的特征向量空间。
本发明一方面针对网络结构空间的稀疏性和高维性以及文本信息的多样性和复杂性,引入不同的表示学习分别将多个模态转换成统一的表示形式,以识别用户之间的关系,另一方面在文本向量中引入时间衰减函数,量化用户的兴趣关注对链接预测形成的影响,并且为了简化模型的计算复杂度,每个用户选取其最相关的k个相关用户作为该用户的最相关用户组,避免全局运算。
附图说明
图1是本发明一种基于表示学习和多模态卷积神经网络的用户推荐方法的整体框图;
图2是本发明一种基于表示学习和多模态卷积神经网络的用户推荐方法的流程图;
图3是本发明一种基于表示学习和多模态卷积神经网络的用户推荐方法的多模态异构空间特征表示图;
图4是本发明一种基于表示学习和多模态卷积神经网络的用户推荐方法的神经网络结构。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种基于表示学习和多模态卷积神经网络的用户推荐方法,如图2,包括以下步骤:
s1、从社交网络的公共平台下载用户数据,并对用户数据进行预处理,下载的用户数据包括网络结构信息和用户文本信息;
s2、基于表示学习分别根据网络结构信息和用户文本信息构建网络结构和用户文本特征;
s3、利用注意力机制提取用户文本特征中的关键信息;
s4、构建卷积神经网络,并在卷积神经网络的卷积层之前建立一个融合层,将网络结构特征与用户文本特征的关键信息进行融合,得到网络节点矩阵;
s5、利用网络节点矩阵完成神经网络的训练,并提取待测用户当前时刻的用户数据;
s6、将当前时刻的待测用户的特征空间向量输入卷积神经网络,得到下一时刻待测用户可能产生的用户关系,并将预测的用户关系推送给待测用户。
本发明可以应用到各种社交网络平台,包括但不限于facebook、twitter、flickr、youtube、新浪微博等社交网络,为了更好理解,在本实施例中以应用到微博为例。
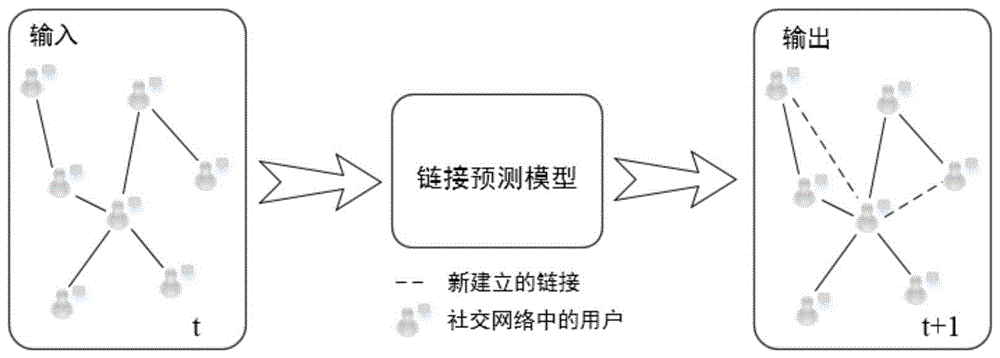
如图1,本发明输入是社交网络中的用户关系,经过模型预测后的输出是下一时刻新出现的关系,图1中实线表示第t时刻存在的用户关系,虚线表示经过本发明预测的第t+1时刻的可能存在的用户关系。
在本实施例中,将一个用户视为一个节点,用户数据可以直接从现有的基于web的研究社交网络系统下载或者利用成熟的社交平台的公共api获取,获取的用户数据分为网络结构信息和用户文本信息,一个用户的网络结构特征至少包括该用户关注的用户、关注该用户的用户,一个用户的用户文本特征至少包括该用户发布的历史文本信息。
在微博系统中,网络结构信息为用户之间的关系,一个微博用户的网络结构信息包括该微博用户关注的用户以及该微博用户的粉丝;用户文本信息为用户发布的历史文本信息,包括用户的原创微博和转发微博。
获取用户数据之后,为了使数据有利于后续分析,需要简单地对数据进行清洗,对数据的清洗包括但不限于删除冗余的数据、填充缺失的数据。
如图3,使用不同的表示学习算法对网络特征进行向量表达。其中,左边是使用word2vec算法对用户文本特征向量化的过程,右边是使用node2vec算法对网络结构特征向量化的过程。在图3中,wi表示单词的0-1向量,wi-n表示wi的上下文向量,实线箭头表示广度优先搜索(即bfs)的采样策略,虚线箭头表示深度优先搜索(即dfs)的采样策略。
网络结构特征表明了用户间的关系,即用户间的关注关系和跟随关系。为了挖掘用户之间潜在的关系,首先对网络结构进行向量表达。如图3,网络结构特征向量的构建包括:
使用具有灵活采样策略的网络表示学习算法,例如node2vec算法,对网络g=(u,e)进行采样,选取其中任一节点u1进行随机游走,得到一个节点序列{u1,u2,u3,…,un};
多次循环遍历网络,得到一个丰富的全局节点序列集;
输出网络g中所有节点的d维全局特征向量v(ui)∈rd;
其中,g表示一个社交网络,u表示社交网络中的用户的集合,e表示用户间的链接的集合,ui为网络中的一个用户。
经过特征表示,将节点间的相关性转化为节点向量间的语义相似性问题,相似性越高,相关性也就越强。针对任意两个节点ui和uj,选择向量之间的夹角余弦值来度量节点之间的相似性:
其中,sim(v(ui),v(uj))表示节点向量v(ui)与节点向量v(uj)之间的相似度,n表示网络中节点的总个数。
同时,由于相似度小的节点相关性较低,且选择网络中所有节点将增加模型的计算复杂度。因此,为了简化计算,选取每个节点的前k个相关性较强的节点,将其构成一个最相关用户组gp:{ua,ub,uc,…}。其中,每个用户组都是一个r(k+1)×d的二维矩阵,表示为:
vu=[v(u0)v(u1)…v(uk)]τ∈r(k+1)×d;
其中,vu的每一行代表的是社交网络中一个节点的向量表示。
为了得到与网络结构特征空间统一的表达形式,对用户文本特征也进行向量表示。用户的每条微博都是由一系列词组成。如图3,对获取到的用户文本进行分词,关键词提取等处理,然后从当前目标词对上下文的预测中学习到词向量的表达,具体包括:
针对每个节点的最相关用户组gp,将用户历史微博中的每个词转换为l维向量,规定每个微博长度为m(不足用0填充),创建k+1个用户的句子矩阵:
va=[v(p01)…v(p0m)…v(pk1)…v(pkm)]τ∈r((k+1)×m)×l;
在文本向量va之后加入一个时间衰减函数,使得这个特征可以更准确地拟合用户兴趣的变化;
用户文本向量矩阵经过与f(ui)的计算得到va_decay,仍然是一个r((k+1)×m)×l的二维矩阵,用户文本特征向量表示为:
va_decay=f(ui)×va;
其中,va_decay表示用户文本特征的特征向量空间;va为所有用户的句子矩阵;f(ui)表示用户节点ui根据时间变化的用户兴趣。
用户节点ui根据时间变化的用户兴趣表示为:
其中,i是一个值为0或1的指示函数,表明用户的兴趣是否会随时间衰减,λ是一个可调的权重增长指数。
本文基于网络结构和用户文本分别建立了不同模态的特征表示模型,即网络结构特征向量和用户文本特征向量,对社交网络中进行节点间相关性的挖掘。为了增强预测的准确性,对多特征空间进行特征融合,共同预测链接。
如图4是本发明整体预测的模型结构,本实施例选择的卷积神经网络包括两层卷积层和两层池化层,输入层(input)输入数据,在注意力机制层(attentionlayer)提取用户文本特征向量的关键信息,在融合层(fusionlayer)将关键信息与网络结构特征向量进行融合后依次输入第一个卷积层和池化层(conv.&pooling1)、第二卷积层和池化层(conv.&pooling2)、全连接层(fclayer),最后经过输出层(output)输出得到输出结果。
利用注意力机制提取网络结构特征和用户文本特征的关键信息,包括:
利用注意力机制为用户文本中的每个单词创建一个上下文向量,表示为:ci=∑j≠iμi,j·v(pr,j);
将得到的上下文向量与每个单词的原始词向量进行拼接构成上下文词向量,并将该上下文词向量还原为句子,得到用户文本特征的关键信息;
其中,μi,j为权重项,并使用softmax正则化使得μi,j≥0且∑jμi,j=1,μi,j的计算包括:
其中,score(v(pr,i),v(pr,j))为权重项的打分函数;wa表示权重矩阵;v(pr,i)表示表示第r个用户句子中的第j个单词。
由得到的上下文向量与原始词向量拼接构成新的词向量,之后将词向量还原为句子。
在模型融合层,将句子向量与网络结构向量进行拼接,得到一个二维的网络节点矩阵,作为卷积层的输入,网络节点矩阵表示为:
其中,v表示网络结构特征与用户文本特征的关键信息融合后得到的;vs表示attention注意力层输出的结果;
在卷积神经网络中,利用卷积和池化操作,对节点间的局部关联特征和整体特征进行学习,包括但不限于以下操作:
卷积层接收节点矩阵v,并选取不同尺寸的卷积核对输入的二维矩阵进行卷积操作,提取矩阵中的局部特征,得到一个特征图:yconv=f(w*v+bi);其中,f(w*v+bi)表示非线性激活函数relu,w为权重矩阵,v表示网络节点矩阵,bi为偏置值。
为了对特征图中的值作进一步聚合,减少参数的数量,对卷积后的特征图进行最大池化操作:ypool=max(yconv);其中,ypool表示最大池化操作的输出值,yconv表示卷积后的特征图。
整合池化后的信息,得到一个一维向量:yfc=flatten(ypool),经过全连接层,使用softmax函数进行归一化处理,得到链接预测的结果;yfg表示整合池化层后得到的一维向量,flatten()表示整合操作。
利用网络节点矩阵完成神经网络的训练,并提取待测用户当前时刻的用户数据;将当前时刻的待测用户的特征空间向量输入卷积神经网络,得到下一时刻待测用户可能产生的用户关系,并将预测的用户关系推送给待测用户。
应当指出上述具体的实施例,可以使本领域的技术人员和读者更全面地理解本发明创造的实施方法,应该被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。因此,尽管本发明说明书参照附图和实施例对本发明创造已进行了详细的说明,但是,本领域的技术人员应当理解,仍然可以对本发明创造进行修改或者等同替换,总之,一切不脱离本发明创造的精神和范围的技术方案及其改进,其均应涵盖在本发明创造专利的保护范围当中。
- 还没有人留言评论。精彩留言会获得点赞!