一种基于D-S证据理论的分布式文件系统数据读取方法与流程
本发明涉及云计算
技术领域:
,具体为一种基于d-s证据理论的分布式文件系统数据读取方法。
背景技术:
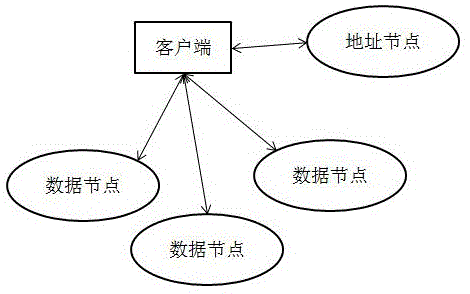
:现有的分布式文件系统中,通过客户端进行数据读取的时候,其过程如图1所示,首先客户端向地址节点提出请求,获取数据节点的地址;根据地址节点反馈的数据节点地址,客户端访问对应的数据节点获取数据;在这样的数据访问机制下,如果需要读取10次数据,就需要通过网络访问地址节点10次,然后再访问数据节点10次;在现有的访问机制下,当客户端需要反复多次访问有限的数据节点时,会在访问地址节点这个环节花费大量的时间,导致整个流程产生很多不必要的资源消耗。技术实现要素:为了解决现有技术中,当客户端需要反复多次访问有限的数据节点时,在访问地址节点这个环节耗费大量时间的问题,本发明提供一种基于d-s证据理论的分布式文件系统数据读取方法,其简化请求数据节点地址的过程,加快数据读取速度,进而降低整个系统流程的资源消耗。本发明的技术方案是这样的:一种基于d-s证据理论的分布式文件系统数据读取方法,其包括以下步骤:s1:客户端向地址节点请求需要读取数据节点的地址;s2:所述地址节点返回相应数据节点地址,客户端根据所述数据节点地址寻找数据节点读取数据;其特征在于,其还包括以下步骤:s3:存储每一个所述数据节点地址在本地;s4:预设阈值n,当步骤s2实施n次后,所述地址节点返回n个地址节点,客户端中的寻址模块将连续n次读取的数据节点地址作为一个计算组;所述计算组中每一个数据节点地址称之为待确认数据地址;s5:依次取出所述计算组中每一个所述待确认数据地址,计算该所述待确认数据地址在每组数据中的信度函数bel、似真度函数pls;s6:计算每个所述待确认数据地址在所述计算组中出现的概率p;s7:比较每一个所述待确认数据地址对应的所述信度函数bel和所述似真度函数pls;s8:查找所述信度函数bel和所述似真度函数pls差值最小的那个数据节点地址;如果所述信度函数bel和所述似真度函数pls差值最小的节点地址存在且唯一,则设该数据节点地址为待访问数据节点地址;否则,执行步骤s11;s9:获取所述待访问数据节点地址对应的所述概率p;当p≥0.5时,客户端直接读取所述待访问数据节点地址在所述数据节点中对应的数据,获取的数据为待确认数据,执行步骤s11;否则,执行步骤s11;s10:确认所述待确认数据是否是客户端期待数据;如果所述待确认数据是所述客户端期待数据,则本次数据读取结束,等待下次数据读取操作,重复步骤s5~s14;否则,放弃本次取得的数据,执行步骤s11;s11:客户端直接向所述地址节点请求需要读取数据节点的地址,获得相应的数据节点地址后去该数据节点按照地址读取数据;且将所述地址节点返回的数据节点地址设置为替换数据地址;s12:在所述计算组中,通过最小的所述概率p找到待删除地址;s13:在所述计算组中删除所述待删除地址,将所述替换数据地址添加到所述计算组中;s14:本次数据读取结束,等待下次数据读取操作,重复步骤s5~s14。其进一步特征在于:步骤s12中,通过所述概率p找到待删除地址,包括如下步骤:a1:在所述计算组中,找到最小的所述所述概率p;a2:确认最小的所述概率p对应的所述待确认数据地址的个数m;如果m=1,则设置该待确认数据地址为待删除地址;否则,在m个所述概率p相同的待确认数据地址中,找到出现时间最早的那个待确认数据地址设置为待删除地址;步骤s4中,计算所述待确认数据地址在每组数据中的信度函数bel、似真度函数pls的方法如下所示:b1:定义:基本概率值m,识别框架θ,函数2θ→[0,1];b2:根据m(φ)=0,信度函数bel、似真度函数pls计算公式如下:式中,bel(a)bel(a)是识别框架θ上的信任函数,表示对命题a的所有子集的可能性度量之和,也是对命题a的总信任,pls(a)表示不能否认命题a的程度;φ表示空、也就是不可能出现的事件,所以其可信度为0;步骤s5中,每个所述待确认数据地址在所述计算组中出现的所述概率p的计算方法如下:式中:n为正整数。本发明提供的一种基于d-s证据理论的分布式文件系统数据读取方法,客户端存储常访问的数据节点地址在本地,当存储的常访问的数据节点地址到达阈值n之后,再次需要向数据节点读取数据的时候,则先不向地址节点确认数据节点地址,而是基于d-s证据理论预测需要访问的数据节点地址;当满足条件:信度函数bel、似真度函数pls差值最小、且概率p最大,该地址即判定为待访问数据节点地址,客户端访问数据节点中的待访问数据节点地址获取数据;也即是说,当本地存储的常访问地址足够多之后,通过客户端本地的寻址模块基于d-s证据理论预测需要访问的数据节点地址,而无需每次都通过网络访问地址节点获取数据节点的地址了;降低了请求数据节点的系统开销,且整个过程降低了对网络速度的依赖,提高了数据读取的速度。附图说明图1为现有方法中分布式文件系统的结构示意图;图2为本发明中数据读取方法的流程示意图。具体实施方式如图2所示,本发明一种基于d-s证据理论的分布式文件系统数据读取方法,其包括以下步骤。s1:客户端(包括:移动端app、pc端的应用程序)通过无线、有线网络向分布式文件系统中的地址节点请求需要读取数据节点的地址。s2:地址节点返回相应数据节点地址,客户端根据数据节点地址寻找数据节点读取数据。s3:存储每一个数据节点地址在客户端本地。s4:在客户端设置一个寻址模块,寻址模块中包括基于d-s证据理论的深度学习模型;预设阈值n,当步骤s2实施n次后,地址节点返回n个地址节点,客户端中的寻址模块将连续n次读取的数据节点地址作为一个计算组;通过计算组中的地址节点数据对深度学习模型进行训练;计算组中每一个数据节点地址称之为待确认数据地址;计算待确认数据地址在每组数据中的信度函数bel、似真度函数pls的方法如下所示:b1:定义:基本概率值m,识别框架θ,函数2θ→[0,1];b2:根据m(φ)=0,信度函数bel、似真度函数pls计算公式如下:式中,bel(a)bel(a)是识别框架θ上的信任函数,表示对命题a的所有子集的可能性度量之和,也是对命题a的总信任,pls(a)表示不能否认命题a的程度;φ表示空、也就是不可能出现的事件,所以其可信度为0。s5:依次取出计算组中每一个待确认数据地址,计算该待确认数据地址在每组数据中的信度函数bel、似真度函数pls。s6:计算每个待确认数据地址在计算组中出现的概率p;概率p的计算方法如下:式中:n为正整数,根据系统特点进行预先选择;当证据间的冲突很小时,经典d-s证据理论能很好地预测出正确的结果,可是当证据完全冲突的时候会得到与客观结果完全不符的结果,假设有辨识框架θ={a、b、c},融合结果如下表1:表1:实施例融合结果abc可信度分配10.990.010可信度分配200.010.99可信度分配融合结果010参照上面表1中的数据,根据表1中记载的地址a和地址c的可信度分配数据,可知:地址a和c出现的次数较多,但读取的数据量较小,地址b出现的次数很少,甚至于只有1次,但该次读取数据量较大,甚至大于该组其余数据节点读取数据量的总和;在这种证据完全冲突的情况下,如果只采用信度函数bel、似真度函数pls进行判断,会产生误判,即,尽管对a和c的可信度高达0.99,最终融合结果却为可信度为0.01的b,错误的预测下次读取的地址仍为b。所以,在本发明的技术方案中,设置每个数据节点在该组中出现的概率p,用地址出现的概率解决出现次数较少而读取数据量较大导致的误判情况。s7:比较每一个待确认数据地址对应的信度函数bel和似真度函数pls。s8:查找信度函数bel和似真度函数pls差值最小的那个数据节点地址;如果信度函数bel和似真度函数pls差值最小的节点地址存在且唯一,则设该数据节点地址为待访问数据节点地址;否则,执行步骤s11;如图2所示,先计算每一个待确认数据地址对应的信度函数bel和似真度函数pls的差值,然后在所有的差值里面找到最小的那个差值;在实施例中通过设置一个中间值d代表找到的最小差值的个数,如果d=1,则代表信度函数bel和似真度函数pls差值最小的节点地址只有一个,设置该节点地址为待访问数据节点地址后,执行步骤s9;否则,当d≠1,代表差值最小的节点地址超过一个,此时代表网络模型的精度还不足够,本次预测结果无效,放弃此次预测,执行步骤s11。s9:获取待访问数据节点地址对应的概率p;当p≥0.5时,客户端直接读取待访问数据节点地址在数据节点中对应的数据,获取的数据为待确认数据,执行步骤s11;否则,执行步骤s11。根据表1中的数据,可知:该识别框架中a的概率p为0.6、b的概率p为0.1、c的概率p为0.3,基于概率p,可以算出上面表格的数据最终预测的下次读取的地址为a。通过设置概率p解决因为地址多次出现但是读取数据量较少而导致的误判问题,得出符合事实的预测结果。s10:确认待确认数据是否是客户端期待数据;如果待确认数据是客户端期待数据,则本次数据读取结束,等待下次数据读取操作,重复步骤s5~s14;否则,放弃本次取得的数据,执行步骤s11。s11:客户端直接向地址节点请求需要读取数据节点的地址,获得相应的数据节点地址后去该数据节点按照地址读取数据;且将地址节点返回的数据节点地址设置为替换数据地址。s12:在计算组中,通过最小的概率p找到待删除地址;通过概率p找到待删除地址,包括如下步骤:a1:在计算组中,找到最小的概率p;a2:确认最小的概率p对应的待确认数据地址的个数m;如果m=1,则设置该待确认数据地址为待删除地址;否则,在m个概率p相同的待确认数据地址中,找到出现时间最早的那个待确认数据地址设置为待删除地址。s13:在计算组中删除待删除地址,将替换数据地址添加到计算组中。s14:本次数据读取结束,等待下次数据读取操作,重复步骤s5~s14。通过寻址模块基于d-s证据理论模型预测的数据节点地址如果是错误的,则在数据节点取回的数据就不是客户端所需的数据,比如客户端需要取回图片x,实际取回的图片y,则在步骤s10中通过对取回的图片进行确认,来判断寻址模块预测的数据节点地址是否正确。如果寻址模块预测数据节点是错误的,则放弃取回的数据,客户端直接向地址节点请求需要读取数据节点的地址,获取正确的图片数据;并且客户端在获得正确的图片数据后,把请求的正确的地址替换到计算组中;删除计算组中概率p最小的那个地址,添加从地址节点请求回来的正确地址。反复多次之后,在寻址模块的计算组中的地址的准确率会越来越高,经过反复的训练学习过程,寻址模块的预测准确率也会越来越高。使用本发明的技术方案后,当系统中的客户端当需要反复多次访问有限的数据节点时,通过存储在客户端本地的寻址模块进行地址预测,而不必通过网络反复访问地址节点进行数据节点地址的请求;降低了系统对网络环境的依赖,且提高了数据读取的速度,降低了整个系统的资源消耗。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1