基于LOGSTASH的批量数据导入方法与流程
本发明涉及大数据技术领域,尤其涉及基于logstash的批量数据导入方法。
背景技术:
目前越来越多的系统需要实现快速检索功能,如何在大量数据的基础上快速检索出所要信息,是一个难题。数据量可能是几十亿级别,单单靠传统的数据库或者文档检索,根本解决不了该问题。elasticsearch是一个基于lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于restfulweb接口。它可以方便、快速的匹配检索的关键词,特点为检索速度快、数据量大、匹配度高。logstash主要就是解决如何将数据库中已有的数据导入到elasticsearch系统中,它的特点主要体现在,导入速度快、可以自定义连接数据库、自定义索引表结构等。logstash缺点是没有提供java或者c的开放接口,只能人工操作,而且对机器的性能要求较高,机器性能影响elasticsearch数据的导入速度。
技术实现要素:
本发明的目的在于提供基于logstash的批量数据导入方法。
本发明采用的技术方案是:
基于logstash的批量数据导入方法,其包括以下步骤:
步骤1、根据项目要求确定表结构并创建elasticsearch索引表,同时下载mysql数据连接驱动包;
步骤2、创建并更新logstash的配置文件s,其具体步骤为:
步骤2-1、根据需求确定需从mysql数据库导入的数据;
步骤2-2、基于elasticsearch索引表结构创建查询导入数据的mysql查询语句,且查询语句的字段名和字段个数与elasticsearch索引表结构一样;
步骤2-3、为查询到不同类型的数据分别关联映射至对应类型的elasticsearch索引表;
步骤2-4、基于步骤2-1至2-3的操作同步更新配置文件s;
步骤3、根据机器性能调整logstash的内存参数;
步骤4、logstash调用配置文件s进行数据的批量导入;
步骤5、导入结束后快读检索elasticsearch的数据完成批量导入。
进一步地,步骤2-1中确定需导入的数据前先连接mysql并引用驱动包。
进一步地,步骤2中将配置文件s的任务设为定时任务。
本发明采用以上技术方案,以mysql数据库为准,实现数据从mysql导入到elasticsearch系统中。logstash要处理的是,加载mysql数据库的连接驱动包,然后根据创建好的elasticsearch的索引表结构,拼写需要查询的mysql数据的sql语句,该sql语句中的字段名称必须与elasticsearch的索引表的字段一样,否则会出现问题。这里导入的数据量以sql语句查询的结果为准。根据机器性能调整内存参数,由于本身mysql数据查询完成后放在内存中,所以内存参数关系到一次性导入数据的数据量,运行logstash实现数据的导入。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
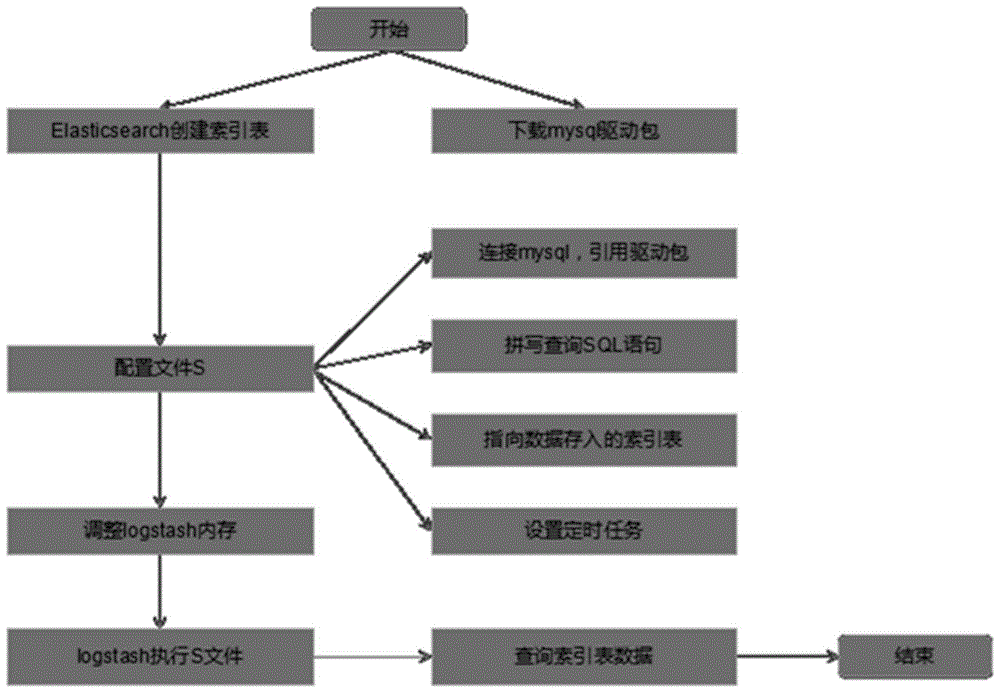
图1为本发明基于logstash的批量数据导入方法的流程示意图。
具体实施方式
如图1所示,本发明公开了基于logstash的批量数据导入方法,其包括以下步骤:
步骤1、根据项目要求确定表结构并创建elasticsearch索引表,同时下载mysql数据连接驱动包;
步骤2、创建并更新logstash的配置文件s,其具体步骤为:
步骤2-1、根据需求确定需从mysql数据库导入的数据;
步骤2-2、基于elasticsearch索引表结构创建查询导入数据的mysql查询语句,且查询语句的字段名和字段个数与elasticsearch索引表结构一样;
步骤2-3、为查询到不同类型的数据分别关联映射至对应类型的elasticsearch索引表;
步骤2-4、基于步骤2-1至2-3的操作同步更新配置文件s;
步骤3、根据机器性能调整logstash的内存参数;
步骤4、logstash调用配置文件s进行数据的批量导入;
步骤5、导入结束后快读检索elasticsearch的数据完成批量导入。
进一步地,步骤2-1中确定需导入的数据前先连接mysql并引用驱动包。
进一步地,步骤2中将配置文件s的任务设为定时任务。
本发明采用以上技术方案,以mysql数据库为准,实现数据从mysql导入到elasticsearch系统中。logstash要处理的是,加载mysql数据库的连接驱动包,然后根据创建好的elasticsearch的索引表结构,拼写需要查询的mysql数据的sql语句,该sql语句中的字段名称必须与elasticsearch的索引表的字段一样,否则会出现问题。这里导入的数据量以sql语句查询的结果为准。根据机器性能调整内存参数,由于本身mysql数据查询完成后放在内存中,所以内存参数关系到一次性导入数据的数据量,运行logstash实现数据的导入。本发明由于logstash导入速度快,查询语句自由,一次性导入的数据量根据机器性能可以达到几千万条,解决了elasticsearch数据的初始化已经需要频繁导入删除大批量数据的问题。
- 还没有人留言评论。精彩留言会获得点赞!