基于混合狼群算法的软件可靠性模型参数估计方法与流程
本发明涉及软件可靠性模型评估技术领域,具体地说,是一种基于混合狼群算法的软件可靠性模型参数评估方法。
背景技术:
软件可靠性是衡量软件质量的定性指标,具有重要的研究意义,因此越来越受到研究者的重视。迄今为止,研究者们已经发表了近百种软件可靠性模型,比如g-o模型、m-o模型和j-m模型等。然而这些模型都是非线性函数模型,很难直接估计它们的参数,所以一种新的思路是将智能优化算法应用到模型参数估计中。
狼群算法(wpa)是一种典型的群体智能算法,和其他群体生物具有类似的群体行为,但是狼群在捕食及其猎物的分配更具有严格的机制,核心思想是通过各个狼之间的协作和信息互享,对最优解进行搜索,如今已经被应用于多个领域。wpa作为群体智能优化算法的一种,是由吴虎胜等学者系统地提出。该算法具有较好的全局收敛性和较高的精度值,种群的多样性较高,寻优策略也较高。粒子群算法(pso)由eberhart和kennedy于1995年提出,它是参考鸟群觅食的行为。pso算法的优点是设置的参数少,比较容易实现,前期的收敛速度较快,但是在搜索过程中容易陷入局优,导致求解的准确度不高。
技术实现要素:
为了解决上述技术问题,本发明将两种算法各自的特点进行混合,提出混合狼群算法(wpa-pso),并用wpa、pso和wpa-pso这三种算法分别对软件可靠性模型的参数进行估计。结果表明,混合狼群算法估计结果的误差率一直保持最优性和稳定性,即使在减少数据量或改变算法迭代次数时,情况亦是如此,其可更大发挥狼群算法的优势,进一步提高参数估计的准确性和稳定性,特别是在较少数据量的情况下仍然具有较好的适应性。
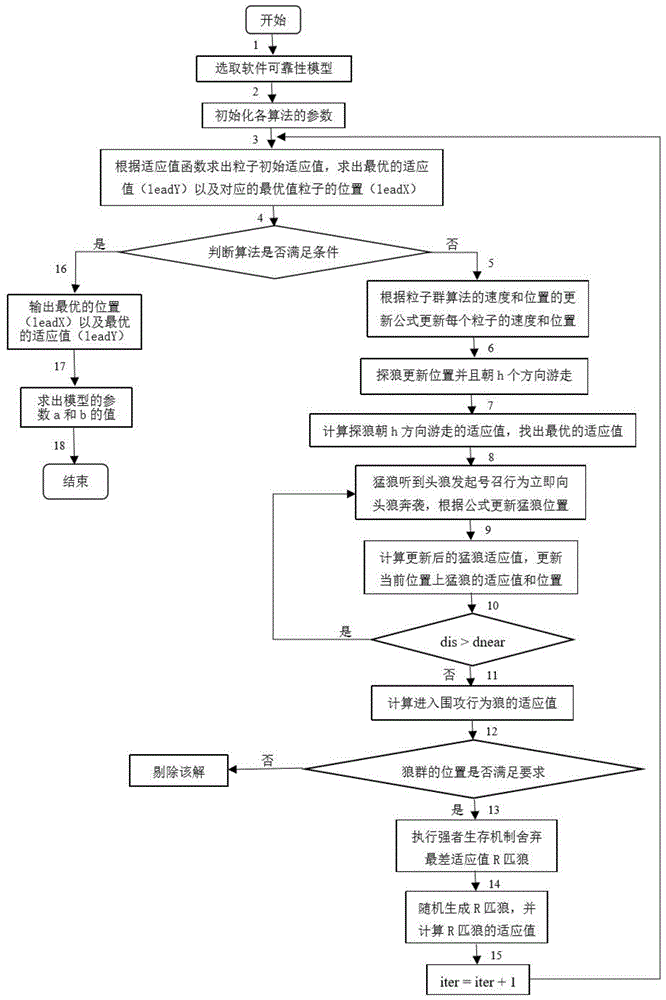
本发明提供如下技术方案:基于混合狼群算法的软件可靠性参数估计方法,包括如下步骤:
(1):选取软件可靠性模型,以g-o模型为例,g-o模型对软件系统中累积失效数的估计函数如式(1)所示:
m(t)=a(1-e-bt)(1)
上式中:m(t)表示到时刻t为止的累积失效数的期望函数;a表示测试结束后软件期望被检测出来的失效总数;b代表剩余失效被发现的概率,即在时刻t产生的失效检出率,是一个比例常数,范围为(0,1)。g-o模型的参数就是a和b,它们的选取会影响到模型预测的准确性;
(2)初始化所有的参数:人工狼的总数wolfnum=m=60(粒子数),探狼比例因子α=4,距离判定因在因子w=100,步长因子s=100,更新比例因子β=10,最大游走次数tmax=30最大迭代次数gmax=500,待寻优的第d个变量的取值范围是[lb,ub],其中ub=π,lb=-π,游走步长stepa=(ub-lb)/s;奔袭步长stepb=(ub-lb)/s*2;攻击步长stepc=(ub-lb)/(s*2);随机生成游走方向h为[hmin,hmax]的随机数,其中设置hmin=2,hmax=15适应值精度要求k≤1e(-5)。每头狼的位置即g-o模型的参数x初始化为(0,1)之间的随机数(这里x就是代表b的值);惯性权重w=0.9,学习因子c1=c2=1.5,速度v为[-1,1]内的随机数;
(3)利用极大似然估计法构造适应值函数,下面是使用极大似然法估计出来的a、b的计算公式,如式(2)所示:
其中:n表示已知的失效数;ti为第i个失效发生的时刻;i=1,2,3,...n。
我们根据g-o模型参数a、b的极大似然估计公式来构造一种新的适应值函数,具体做法是将公式(2)中的第一项代入到第二项中并进行数学变换,构造成一个只与参数b相关的式子,如下式(3)所示:
将b分别代入适应值函数中,求出每个粒子当前初始适应值,最优的适应值赋值给leady,最优适应值的位置的值作为leadx;
(4)判断是否满足算法停止条件:iter=gmax或leday的精度达到k,如果精度达到k,则转至步骤(16),否则执行步骤(5);
(5)根据如下速度和位置的更新公式,更新每个粒子的速度和位置:
v′i=wvi+c1r1(pbest_bi)+c2r2(gbest_b-bi)
b′i=v′i+bi(4)
其中,i=1,2,…,60,代表60个粒子;r1、r2是介于[0,1]之间的随机数;
(6)探狼朝h个方向进行游走,根据游走公式(5)进行位置更新,并且求出更新后的位置上的适应值nexty;
公式(5)是表示沿着第p(p=1,2,3,…,h)个方向所前进后探狼i在第d维空间中的位置;
(7)求出更新后的头狼的最优适应值leady和最优的位置ledax;
(8)头狼发起召唤行为,猛狼根据奔袭公式(6)向头狼奔袭;
公式(6)是表示第j匹猛狼经历第k+1次迭代次数时,在第d维空间中的位置,式中,
(9)计算更新后的猛狼的适应值mnexty,更新当前位置上的猛狼的适应值y(j)以及x(j);
(10)判断dis是否大于dnear,如果大于则执行步骤(8),如果小于则执行步骤(11);
(11)计算进入围攻狼根据公式(7)更新位置,同时求出适应值gnexty,并更新当前位置的值;
第k代狼群中,设猎物在第i维空间中的位置为
(12)判断第i个狼更新后的位置xi的精度是否小于1e-5,若为是,则抛弃该粒子更新的位置,使用原来的位置代替;否则,保留更新的位置上的值,并执行步骤(13);
(13)根据狼群的更新机制,执行强者生存,舍弃最差的r匹狼;
(14)随机生成r匹狼,并计算r匹狼的适应值;
(15)iter=iter+1,转至步骤(4);
(16)满足算法结束条件,将最优适应值leady和最优的位置leadx输出;
(17)已知b的值,根据公式求解参数a的值。
本发明提出一种基于混合狼群算法的软件可靠性参数估计方法,具体的做法是:在进行pso算法粒子搜索粒子后,再将狼群算法中的狼群的搜索过程再精细地搜索一遍,以确定最终的新位置。此种混合狼群算法的参数估计方法精确、稳定,不仅可以提高软件可靠性模型参数估计的准确性,比单个算法具有更优的参数估计结果,也能提高结果的稳定性,比单个算法的估计结果更稳定。即使在减少数据量或改变算法迭代次数时,情况亦是如此。
本发明的有益效果:与现有技术相比,本发明的有益效果是:
1)将狼群和粒子群混合算法用于软件可靠性模型参数的估计之中,与单个算法相比,狼群混合算法能提高了软件可靠性模型参数估计的准确度;
2)狼群混合算法不仅可以提高软件可靠性参数模型估计的准确性,也能使估计结果保持相对稳定,比单个算法的稳定性更高;
3)即使在数据量偏少的情况下,相比于单个算法而言,狼群混合算法也具有更优的参数估计结果和更好的稳定性,有很强的算法适应性;
4)在改变每个算法的迭代次数时,混合狼群算法的估计结果依然是比单个算法更准确和更稳定。
5)不仅仅局限于g-o模型,对其他的软件可靠性模型也适用。
附图说明
图1是本发明的运算流程示意图。
具体实施方式
为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
如图1所示,是本发明的运算流程示意图。
本发明实施例中,选用的实验数据来源于实际工业项目中得到的5组软件失效间隔时间数据集sys1、ss3、csr1、csr2、csr3,数据下载地址为http://www.cse.cuhk.edu.hk/lyu/book/reliability/data.html。sys1、ss3、csr1、csr2、csr3的实际失效数分别为136、278、397、129、104。
(1)使用sys1、ss3、csr1、csr2、csr3这5个数据集合的所有数据。选取软件可靠性模型,以g-o模型为例,g-o模型对软件系统中累积失效数的估计函数如式(1)所示:
m(t)=a(1-e-bt)(1)
上式中:m(t)表示到时刻t为止的累积失效数的期望函数;a表示测试结束后软件期望被检测出来的失效总数;b代表剩余失效被发现的概率,即在时刻t产生的失效检出率,是一个比例常数,范围为(0,1)。g-o模型的参数就是a和b,它们的选取会影响到模型预测的准确性;
(2)初始化所有的参数:人工狼的总数wolfnum=m=60(粒子数),探狼比例因子α=4,距离判定因在因子w=100,步长因子s=100,更新比例因子β=10,最大游走次数tmax=30最大迭代次数gmax=500,待寻优的第d个变量的取值范围是[lb,ub],其中ub=π,lb=-π,游走步长stepa=(ub-lb)/s;奔袭步长stepb=(ub-lb)/s*2;攻击步长stepc=(ub-lb)/(s*2);随机生成游走方向h为[hmin,hmax]的随机数,其中设置hmin=2,hmax=15适应值精度要求k≤1e(-5)。每头狼的位置即g-o模型的参数x初始化为(0,1)之间的随机数(这里x就是代表b的值);惯性权重w=0.9,学习因子c1=c2=1.5,速度v为[-1,1]内的随机数;
(3)利用极大似然估计法构造适应值函数,下面是使用极大似然法估计出来的a、b的计算公式,如式(2)所示:
其中:n表示已知的失效数;ti为第i个失效发生的时刻;i=1,2,3,...n。
我们根据g-o模型参数a、b的极大似然估计公式来构造一种新的适应值函数,具体做法是将公式(2)中的第一项代入到第二项中并进行数学变换,构造成一个只与参数b相关的式子,如下式(3)所示:
将b分别代入适应值函数中,求出每个粒子当前初始适应值,最优的适应值赋值给leady,最优适应值的位置的值作为leadx;
(4)判断是否满足算法停止条件:iter=gmax或leday的精度达到k,如果精度达到k,则转至步骤(16),否则执行步骤(5);
(5)根据如下速度和位置的更新公式,更新每个粒子的速度和位置:
v′i=wvi+c1r1(pbest_bi)+c2r2(gbest_b-bi)
b′i=v′i+bi(4)
其中,i=1,2,…,60,代表60个粒子;r1、r2是介于[0,1]之间的随机数;
(6)探狼朝h个方向进行游走,根据游走公式(5)进行位置更新,并且求出更新后的位置上的适应值nexty;
公式(5)是表示沿着第p(p=1,2,3,…,h)个方向所前进后探狼i在第d维空间中的位置;
(7)求出更新后的头狼的最优适应值leady和最优的位置ledax;
(8)头狼发起召唤行为,猛狼根据奔袭公式(6)向头狼奔袭;
公式(6)是表示第j匹猛狼经历第k+1次迭代次数时,在第d维空间中的位置,式中,
(9)计算更新后的猛狼的适应值mnexty,更新当前位置上的猛狼的适应值y(j)以及x(j);
(10)判断dis是否大于dnear,如果大于则执行步骤(8),如果小于则执行步骤(11);
(11)计算进入围攻狼根据公式(7)更新位置,同时求出适应值gnexty,并更新当前位置的值;
第k代狼群中,设猎物在第i维空间中的位置为
(12)判断第i个狼更新后的位置xi的精度是否小于1e-5,若为是,则抛弃该粒子更新的位置,使用原来的位置代替;否则,保留更新的位置上的值,并执行步骤(13);
(13)根据狼群的更新机制,执行强者生存,舍弃最差的r匹狼;
(14)随机生成r匹狼,并计算r匹狼的适应值;
(15)iter=iter+1,转至步骤(3);
(16)满足算法结束条件,将最优适应值leady和最优的位置leadx输出;
(17)已知b的值,根据公式求解参数a的值。
通过以上步骤,得到混合狼群算法(wpa-pso)的参数a的估计结果,同时单独使用狼群算法(wpa)和粒子群算法(pso)进行参数估计,每个算法运行20次,选取最好的结果进行误差比较,具体的结果如表1所示:
表1三种算法误差率(全部失效数据)
从表1可以看出,三种算法在同样运行20次的情况下,wpa-pso混合算法在5组数据集的误差率上都是最小,并且在csr3这个有限数据集的算法误差率仍然是最优的,同时没有出现pso和wpa在csr3这个数据集中出现的误差率突然放大的情况,说明了wpa-pso混合算法在有限数据的情况下比单个算法具有明显的算法准确性和稳定性。
将三种算法运行20次的结果进行统计,计算平均值的误差率,如表2所示:
表2三种算法的平均值误差率(全部失效数据)
由表1可以看出本发明提出的混合狼群算法估计所得的累积失效数a相较于单个算法而言,估计出的准确度更高,而且由表2可知在20次内的稳定更好,由此有力地说明了本发明提出方法的有效性。
s18、使用sys1、ss3、csr1、csr2、csr3中的一半失效数据,采用混合狼群算法来进行参数估计,并通过估计的参数得到sys1、ss3、csr1、csr2、csr3的实际失效数。
通过以上步骤,在仅仅使用一半失效数据的情况下,得到混合狼群算法的参数a的估计结果,同时单独使用狼群和粒子群算法进行参数估计,每个算法运行20次,选取最好的结果进行误差比较,具体的结果如表3所示:
表3三种算法误差率(一半失效数据)
从表3可以看出,三种算法在一半的失效数情况下估计参数时,wpa-pso混合算法在5组数据集的误差率上都是最小,并且在csr3这个有限数据集的算法误差率仍然是最优的,同时没有出现pso和wpa在csr3这个数据集中出现的误差率突然放大的情况,进一步说明了wpa-pso混合算法在有限数据的情况下比单个算法具有明显的算法准确性和稳定性。
将三种算法运行20次的结果进行统计,计算平均值的误差率,如表4所示:
表4三种算法的平均值误差率(一半失效数据)
在数据集只有一半失效数的情况下,由表3可以看出,用wpa-pso混合算法估计出的准确度比单个算法更高。而且由4可知,混合算法在20次内的稳定更好,由此有力地说明了本发明提出的方法的有效性。
s19、使用sys1、ss3、csr1、csr2、csr3这5个数据集合的所有数据,采用混合狼群算法来进行参数估计,将算法的迭代次数分别设置为50,100,200,300,400,500,并通过估计的参数得到sys1、ss3、csr1、csr2、csr3的实际失效数。
通过以上步骤,得到混合狼群算法的参数a的估计结果,同时单独使用狼群和粒子群算法进行参数估计,将每种算法的迭代次数分别设置为50,100,200,300,400,500,并将每种算法运行10次后选取最好的结果进行误差比较,具体的结果如表5~9所示:
表5不同迭代次数的误差率(sys1)
表6不同迭代次数的误差率(ss3)
表7不同迭代次数的误差率(csr1)
表8不同迭代次数的误差率(csr2)
表9不同迭代次数的误差率(csr3)
由表5~9可以发现,在不同迭代次数中,wpa-pso混合算法的误差率一直保持最优性和稳定性。而且在csr3的有限数据集上仍然表现出最优结果和稳定性。这说明wpa-pso混合算法不仅提高了参数估计和预测准确性,也提高了结果的稳定性。
综合上述,本发明提出一种混合狼群算法软件可靠性参数估计方法,基于极大似然估计构造的适应值函数来估计g-o模型的参数。混合狼群算法的软件可靠性模型参数估计方法,关键在于进行pso算法粒子搜索粒子后,再使用狼群算法搜索一遍,这样可以进一步发挥狼群算法的优势。本发明精确、稳定,不仅可以提高软件可靠性模型参数估计的准确性,比单个算法具有更优的参数估计结果,也能提高结果的稳定性,比单个算法的估计结果更稳定。即使在减少数据量或改变算法迭代次数时,情况亦是如此。
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!