基于嵌套LSTM的水军评论检测方法及系统与流程
本发明涉及情感分析和观点挖掘领域,特别是一种基于嵌套lstm的水军评论检测系统及方法。
背景技术:
当前,有很多技术方法可用于水军评论检测。传统的检测方法单纯从文本分类的角度出发,很难确定评论上下文语义的不同。区别于传统的文本分类方法,如何学习长期的依赖关系,进行针对水军评论的文本分类,是水军评论检测的问题关键。传统的研究工作主要是基于传统神经网络的方法,该方法通过不断地提取特征,从局部的特征到总体的特征,使用支持向量机(svm)分类器进行分类。这一类基于特征工程与浅层线性模型的方法虽然取得了一定的成效,但是耗时较长,需要回传的残差会指数下降,导致网络权重更新缓慢,无法体现出长期记忆的效果。
当前,随着深度学习的快速发展,基于多层神经网络的表示学习模型在语义表示与情感分析运用方面更具优势。许多研究者们也将这些模型用于水军评论的分类。在嵌套lstm中,lstm的记忆单元可以访问内部记忆,使用标准的lstm门选择性地进行读取、编写。相比于传统的堆栈lstm,这一关键特征使得模型能实现更有效的时间层级。在嵌套lstm中,(外部)记忆单元可自由选择读取、编写的相关长期信息到内部单元。相比之下,在堆栈lstm中,高层级的激活(类似内部记忆)直接生成输出,因此必须包含所有的与当前预测相关的短期信息。换言之,堆栈lstm与嵌套lstm之间的主要不同是,嵌套lstm可以选择性地访问内部记忆。这使得内部记忆免于记住、处理更长时间规模上的事件,即使这些事件与当前事件不相关。
当前,水军评论方法未充分利用文本中的长期时间规模的信息,无法有效地挖掘出潜在的观点信息。近年来,得到了国内外许多学者和研究机构的高度重视,水军评论检测分类利用了文本中不同信息,进行文本分类,能够站在数据使用者的角度进行分析,提供更加细粒度的信息,有效提高水军评论检测的分析结果的准确程度,有助于研判人员更加了解人们对热点话题、组织、产品等各种实体的真实观点和看法,为研判人员提供更加有效而准确的信息。这就对水军评论检测技术提出了一个挑战:如何构建一个有效的水军评论检测系统来满足其需要。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于嵌套lstm的水军评论检测方法及系统,能够自动抽取出有效特征,并对特征进行抽象和组合,最终识别出文本空间特征。
为实现上述目的,本发明采用如下技术方案:
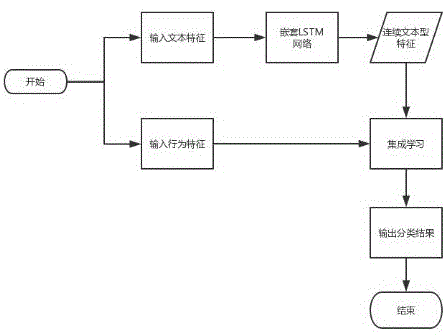
一种基于嵌套lstm的水军评论检测方法,包括以下步骤:
步骤s1:将输入的数据分为文本信息与行为信息;
步骤s2:对行为信息进行特征抽取获得行为特征,并将文本信息送入所述文本特征提取模块,得到包含上下文信息的文本特征;
步骤s3:将得到的包含上下文信息的文本特征送入所述嵌套lstm模块,并提取该文本特征的空间结构信息,得到包含整体与部分关系的文本特征;
步骤s4:将包含整体与部分关系的文本特征与行为特征输入至集成学习模块中,得到评论最终的分类结果。
进一步的,所述文本特征提取模块利用开源的glove工具事先在大语料里训练得到词向量表,将输入的数据的文本信息用向量表示。
进一步的,所述嵌套lstm模块将向量表示的文本特征进行文本上下文相关的特征抽取及注意力构建。
进一步的,所述集成学习模块采用多层分类模型对输入进行分类。
一种基于嵌套lstm的水军评论检测系统,包括
一个文本特征提取模块,用于根据输入的数据的文本信息得到包含上下文信息的文本特征;
一个嵌套lstm模块,将所述文本特征提取模块的输出作为输入,提取该文本特征的空间结构信息,得到包含整体与部分关系的文本特征;
一个集成学习模块,将数据的行为特征以及包含整体与部分关系的文本特征共同作为输入,用多个分类函数得到评论最终的分类结果。
本发明与现有技术相比具有以下有益效果:
本发明能够自动抽取出有效特征,并对特征进行抽象和组合,最终识别出文本空间特征。
附图说明
图1是本发明一实施例中方法流程图
图2是本发明一实施例中嵌套lstm模块。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于嵌套lstm的水军评论检测方法,提供一个检测系统包括文本特征提取模块、嵌套lstm模块和集成学习模块,
在本实施例中,文本提取模块利用glove模型对评论文本进行词的向量化表示,使得文本特征向量之间尽可能多地蕴含语义和语法的信息。
参考图2,本实施例中嵌套lstm模块:
将文本提取模块所获得的向量表示输入到模型中,输入向量经过embedding层转化为降维后的词向量分别输入到嵌套lstm单元中。nlstm是通过嵌套的方式增加lstm的深度,即nlstm中记忆单元的值ci是由lstm单元计算的,其中,lstm单元具有自身内在的记忆单元。内部结构图如下所示:
其中,单元状态的更新与门控机制过程为:
it=σi(xtwxt+ht-1whi+bi)
ft=σf(xtwxf+ht-1whf+bf)
ct=ft⊙ct-1+it⊙σc(xtwxc+ht-1whc+bc)
ot=σo(xtwxo+ht-1who+bo)
ht=ot⊙σh(ct)
nlstm使用了已学习的状态函数代替lstm中计算ct的加运算:
ct=mt(ft⊙ct-1,it⊙gt)
其中函数的状态表示m在时间t的内部记忆,调用该函数计算ct和mt+1,可以使用另一个lstm单元或者nlstm来实现这个记忆函数。基于综上所述的架构特性,nlstm中记忆函数的输入和隐藏状态:
在nlstm中,使用lstm作为记忆函数,而内部lstm的更新过程为:
外部lstm的单位状态更新方式为:
因此,嵌套式lstm通过门控结构实现了对内部内存的选择性访问。使得嵌套式lstm外部记忆单元能自由选择性地将相关的长期信息读写到内部单元,能够获得更加具有空间结构信息的文本特征向量。
在本实施例中,集成学习模块:将上述所获得的文本特征向量以及数据的行为特征输入到该模块中,该模块构造了一个多分类模型,该分类模型由2层组成,第一层由3个基分类器组成,第二层由一个最终分类器组成。首先将训练集用第一层的3个基分类器进行学习和拟合,然后预测结果映射成新的数据集,最后利用最终分类器预测。通过增加基分类器ft,采用贪婪的原则优化目标函数,令其每次增加,都能使得损失变小。因此,可得到评价当前基分类器性能的目标函数:
l是评价模型的损失函数,用于表示样本x的训练误差。ω是由yt和l2正则项两项组成。
模型训练总体损失函数采用xgboost的均方差(mse)评价标准,mse指预测数据和原始数据对应点误差的平方和的均值。独立样本只对应分类器的一个损失函数值,因此总体目标函数为:
公式中,gi为均方差一阶泰勒展开,hi为二阶泰勒展开,t为样本总数。
在本实施例中,具体方法包括以下步骤:
步骤s1:将输入的数据分为文本信息与行为信息;
步骤s2:对行为信息进行特征抽取获得行为特征,并将文本信息送入所述文本特征提取模块,得到包含上下文信息的文本特征;
步骤s3:将得到的包含上下文信息的文本特征送入所述嵌套lstm模块,并提取该文本特征的空间结构信息,得到包含整体与部分关系的文本特征;
步骤s4:将包含整体与部分关系的文本特征与行为特征输入至集成学习模块中,得到评论最终的分类结果。
在本实施例中,所述文本特征提取模块利用开源的glove工具事先在大语料里训练得到词向量表,将输入的数据的文本信息用向量表示。
在本实施例中,所述嵌套lstm模块将向量表示的文本特征进行文本上下文相关的特征抽取及注意力构建。所述嵌套lstm模块是lstm模型的一个扩展,它通过嵌套而不是通过堆栈来增加深度。嵌套lstm的内部记忆单元形成内部记忆,只有通过外部记忆单元才能被其他计算元件所访问,从而实现时间层次的形式。
在本实施例中,所述集成学习模块采用多层分类模型对输入进行分类。将前面得到的文本特征与行为特征输入所述集成学习模块,集成学习模块构造多分类器模型。在训练阶段,需要将预测值与目标值求误差,并利用随机梯度下降法和后向传播对整个系统的参数进行迭代更新;否则,只需将得到的预测值输出即可。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!