包括算术电路的存储器器件和包括该器件的神经网络系统的制作方法
相关申请的交叉引用
本专利申请要求于2018年11月16日向韩国知识产权局提交的第10-2018-0141950号韩国专利申请的权益和优先权,该申请的公开内容通过引用整体并入本文。
本发明构思涉及一种存储器器件和神经网络系统,并且更具体地,涉及一种包括算术电路的存储器器件和包括该存储器器件的神经网络系统。
背景技术:
半导体存储器器件可以分类为需要功率来维持所存储信息的易失性存储器器件和即使当其电源中断时也维持所存储信息的非易失性存储器器件。易失性存储器器件具有高读取/写入速度。另一方面,非易失性存储器器件具有低于易失性存储器器件的读取/写入速度。
神经网络是指模仿生物大脑的计算架构。近来,随着神经网络技术的发展,已经积极地开展研究,以通过使用该使用一个或多个神经网络模型的神经网络设备来在各种类型的电子系统中分析输入数据并提取有效信息。
技术实现要素:
本发明构思的至少一个实施例提供了一种用于在存储器器件中减少数据传输所需时间并提高系统的功率效率的方法和装置以及包括该存储器器件的神经网络系统。
根据本发明构思的示例性实施例,提供了一种存储器器件,包括:存储体,包括被排列在多个字线和多个位线彼此交叉的区域中的多个存储单元;读出放大器,被配置为放大通过多个位线当中的所选位线而发送的信号;以及算术电路,被配置为从读出放大器接收第一操作数(operand),从存储器器件外部接收第二操作数,以及基于在存储器器件中生成的内部算术控制信号,通过使用第一操作数和第二操作数来执行算术运算。
根据本发明构思的示例性实施例,提供了一种存储器器件,包括:至少一个存储体,包括多个存储单元;控制逻辑,被配置为基于从位于存储器器件外部的处理器接收的算术控制信号来生成包括内部读取信号的内部算术控制信号;以及算术电路,被配置为基于由控制逻辑提供的内部算术控制信号来对输入特征数据和内核数据执行处理器的多个卷积运算中的全部或一些。基于由控制逻辑生成的内部读取信号,输入特征数据和内核数据中的至少一个通过包括读出放大器的路径而从至少一个存储体输入到算术电路。
根据本发明构思的示例性实施例,提供了一种用于执行神经网络操作的神经网络系统,该神经网络系统包括:神经网络处理器,被配置为生成用于控制存储器器件的算术运算的算术控制信号;以及存储器器件,被配置为基于从神经网络处理器提供的算术控制信号来生成包括内部读取信号的内部算术控制信号,当内部读取信号被生成时,从存储体内部地读取输入特征数据和内核数据中的至少一个,通过使用输入特征数据和内核数据执行神经网络处理器的多个卷积运算中的全部或一些来生成计算的数据,以及将计算的数据提供给神经网络处理器。
附图说明
从以下结合附图的详细描述中,将更清楚地理解本发明构思的示例性实施例,其中:
图1示出了根据本发明构思的示例性实施例的数据处理系统;
图2示出了根据本发明构思的示例实施例的神经网络系统;
图3示出了卷积神经网络的结构作为神经网络结构的示例;
图4a和图4b是示出神经网络的卷积运算的示图;
图5示出了根据本发明构思的示例性实施例的存储器器件;
图6示出了根据本发明构思的示例性实施例的存储器器件;
图7示出了根据本发明构思的示例性实施例的算术电路;
图8示出了根据本发明构思的示例性实施例的乘法和累加电路;
图9示出了根据本发明构思的示例性实施例的算术电路;
图10示出了根据本发明构思的示例性实施例的算术电路;
图11示出了根据本发明构思的示例性实施例的算术电路和内部算术控制信号;
图12示出了根据本发明构思的示例性实施例的用于描述内部读取操作的存储器器件的配置;
图13示出了根据本发明构思的示例性实施例的用于描述内部写入操作的存储器器件的配置;
图14示出了根据本发明构思的示例性实施例的内部算术控制信号;
图15示出了根据本发明构思的示例性实施例的存储器器件;
图16示出了根据本发明构思的示例性实施例的存储器器件的结构;并且
图17示出了根据本发明构思的示例性实施例的电子系统。
具体实施方式
在下文中,将参考附图详细描述本发明构思的示例性实施例。
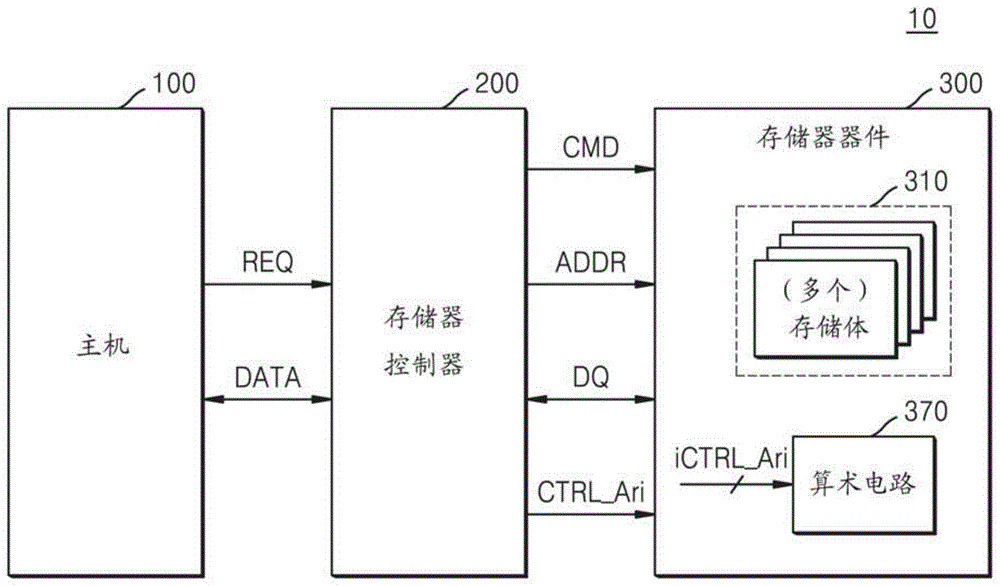
图1示出了根据本发明构思的示例性实施例的数据处理系统10。数据处理系统10包括主机100(例如,主机设备)、存储器控制器200(例如,控制电路)和存储器器件300。数据处理系统10可以应用于需要存储器的各种电子设备,诸如服务器、台式计算机、笔记本计算机、智能电话、平板个人计算机(personalcomputer,pc)、打印机、扫描仪、监视器、数码相机、数字音乐播放器、数字媒体记录器和便携式游戏机,但不限于此。
主机100可以向存储器控制器200提供数据data和请求req。例如,主机100可以向存储器控制器200提供请求req,诸如对数据data的读取请求或写入请求。另外,主机100可以向存储器控制器200提供命令、地址、优先级信息等,但不限于此。主机100和存储器控制器200可以基于各种接口协议(诸如通用串行总线(universalserialbus,usb)协议、多媒体卡(multimediacard,mmc)协议、串行ata协议、并行ata协议、小型计算机小型接口(smallcomputersmallinterface,scsi)协议、增强型小型磁盘接口(enhancedsmalldiskinterface,esdi)协议和集成驱动电路(integrateddriveelectronic,ide)协议)中的至少一种来彼此交换数据和信号。主机100可以被实施为片上系统(systemonchip,soc)或应用处理器,包括与存储器控制器200一起的中央处理单元(centralprocessingunit,cpu)和/或图形处理单元(graphicprocessingunit,gpu)。
存储器控制器200可以响应于主机100的请求req而控制存储器器件300。例如,存储器控制器200可以控制存储器器件300,使得存储器器件300响应于从主机100接收的写入请求而写入数据data,或者响应于从主机100接收的读取请求而读取数据data。为此,存储器控制器200可以向存储器器件300提供命令cmd和地址addr,并且要写入的数据dq和要读取的数据dq可以在存储器控制器200和存储器器件300之间交换。在实施例中,存储器控制器200向存储器器件300提供算术控制信号ctrl_ari,以便存储器器件300执行算术运算。在实施例中,存储器控制器200向存储器器件300提供用于控制写入操作和/或读取操作的控制信号,并且存储器控制器200通过控制信号通过其被发送的线(例如,导电信号线)向存储器器件300提供算术控制信号ctrl_ari。
存储器器件300包括至少一个存储体310和算术电路370。至少一个存储体310可以包括存储单元阵列,并且可以包括多个存储单元。例如,至少一个存储体310可以包括被排列在多个字线和多个位线彼此交叉的区域中的多个存储单元。被包括在存储体310中的多个存储单元可以由地址addr寻址,并且地址addr可以包括用于寻址多个存储单元的多个位。
在实施例中,存储器器件300可以被实施为易失性存储器器件。易失性存储器器件可以被实施为随机存取存储器(randomaccessmemory,ram)、动态ram(dynamicdram)或静态ram(staticsram),但不限于此。例如,存储器器件300可以对应于双数据速率同步动态随机存取存储器(doubledataratesynchronousdynamicrandomaccessmemory,ddrsdram)、低功率双数据速率(lowpowerdoubledatarate,lpddr)sdram、图形双数据速率(graphicsdoubledatarate,gddr)sdram或存储器总线式动态随机存取存储器(rambusdynamicrandomaccessmemory,rdram)。可选地,存储器器件300可以被实施为高带宽存储器(highbandwidthmemory,hbm)。另一方面,在实施例中,存储器器件300可以被实施为非易失性存储器器件。作为示例,存储器器件300可以被实施为电阻存储器,诸如相变ram(phasechangeram,pram)、磁ram(magneticram,mram)或电阻ram(resistiveram,rram)。
根据本发明构思的示例性实施例,存储器器件300包括算术电路370。算术电路370可以通过使用多个操作数来执行算术运算。在实施例中,算术电路370基于在存储器器件300中生成的内部算术控制信号ictrl_ari来执行算术运算。在实施例中,多个操作数中的至少一些是存储在至少一个存储体310中的数据。例如,算术电路370可以通过使用第一操作数和第二操作数来执行算术运算,并且第一操作数和第二操作数中的至少一个可以是存储在存储体310中的数据。算术电路370可以通过使用多个操作数执行算术运算来生成计算的数据。由算术电路370生成的计算的数据可以通过包括数据输入/输出缓冲器的路径而提供给存储器控制器200。
在实施例中,内部算术控制信号ictrl_ari包括内部读取信号和内部写入信号。在示例性实施例中,当内部读取信号被生成时,存储器器件300通过包括读出放大器的路径将操作数从存储体310发送到算术电路370。因此,用于将操作数从存储体310发送到算术电路370的一系列过程可以被称为内部读取操作。在示例性实施例中,当内部写入信号被生成时,存储器器件300通过包括数据输入/输出缓冲器的路径将从存储器设备300外部(例如,从存储器控制器200)提供的操作数发送到算术电路370。因此,用于将操作数从存储器器件300外部发送到算术电路370的一系列过程可以被称为内部写入操作。此外,在实施例中,内部算术控制信号ictrl_ari还包括用于起动算术电路370的算术运算的算术运算起动信号(startsignal)、用于初始化算术电路370的算术初始化信号和用于控制算术电路370以输出计算的数据的输出信号中的至少一个。将参考图11更详细地描述内部算术控制信号ictrl_ari。
在实施例中,算术电路370执行全部或一些卷积运算。例如,存储器控制器200可以被配置为执行卷积运算,但是也可以将这些卷积运算中的一些或全部卸载(offload)到算术电路370。如参考图2至图4b所述,神经网络系统可以执行卷积运算,并且被包括在存储器器件300中的算术电路370可以执行卷积运算中的全部或一些。为此,算术电路370可以包括用于执行乘法运算和加法运算的乘法和累加电路,这将参考图7和图8更详细地描述。此外,在实施例中,算术电路370包括以环状形式连接的乘法和累加电路,这将参考图9更详细地描述。此外,在本发明构思的示例性实施例中,算术电路370还包括非线性函数处理器和量化器,这将参考图10更详细地描述。
在实施例中,算术电路370被排列在排列了输入/输出读出放大器的区域中。换句话说,算术电路370可以从输入/输出读出放大器接收由输入/输出读出放大器放大的信号作为操作数。将参考图6更详细地描述其中算术电路370被排列在排列了输入/输出读出放大器的区域中的实施例。然而,本发明构思不限于此,并且算术电路370可以被排列在排列了位线读出放大器的区域中。换句话说,算术电路370可以从位线读出放大器接收由位线读出放大器放大的信号作为操作数。将参考图16更详细地描述其中算术电路370被排列在位线读出放大器位于的区域中的实施例。
在根据本发明构思的示例性实施例的数据处理系统10中,由于存储器器件300的算术电路370基于在存储器器件300中生成的内部算术控制信号ictrl_ari来对操作数执行算术运算,并将计算的数据发送到存储器控制器200,因此可以减少在存储器控制器200和存储器器件300之间交换的数据量。因此,也可以减少将数据从存储器器件300发送到存储器控制器200的时间,并且因此可以减少数据处理系统10的数据传输开销。此外,由于减少了在存储器控制器200和存储器器件300之间交换的数据量,所以可以提高数据处理系统10的功率效率。
图2示出了根据本发明构思的示例性实施例的神经网络系统20。神经网络系统20包括神经网络处理器400和存储器器件300,并且神经网络处理器400包括处理器100和存储器控制器200。在实施例中,神经网络处理器400或处理器100是专门加速诸如人工神经网络的机器学习算法的微处理器。参考图2,与图1相比,图2的处理器100可以对应于图1的主机100,并且图2的存储器控制器200和存储器器件300可以对应于图1的存储器控制器200和存储器器件300。为了简明起见,将省略关于图2相对于图1的冗余描述。
神经网络处理器400可以生成神经网络,训练或学习神经网络,或者基于所接收的输入数据来执行算术运算,并且可以基于执行算术运算的结果来生成信息信号或重新训练神经网络。神经网络的模型可以包括各种类型的模型,诸如卷积神经网络(convolutionneuralnetwork,cnn)、具有卷积神经网络的区域(regionwithconvolutionneuralnetwork,rnn)、区域建议网络(regionproposalnetwork,rpn)、递归神经网络(recurrentneuralnetwork,rnn)、基于堆叠的深度神经网络(stacking-baseddeepneuralnetwork,s-dnn)、状态空间动态神经网络(state-spacedynamicneuralnetwork,s-sdnn)、去卷积网络、深度置信网络(deepbeliefnetwork,dbn)、受限玻尔兹曼机器(restrictedboltzmannmachine,rbm)、完全卷积网络、长期短期记忆(longshort-termmemory,lstm)网络和分类网络(诸如googlenet、alexnet和vgg网络),但不限于此。处理器100可以根据神经网络的模型来执行操作。此外,神经网络处理器400可以包括用于存储与神经网络的模型相对应的程序的单独的存储器。神经网络处理器400可以另外地被称为神经网络处理设备或神经网络处理单元(neuralnetworkprocessingunit,npu)。
神经网络处理器400可以通过使用输入特征图和内核来执行卷积运算,如参考图3至图4b所描述的。被包括在输入特征图中的数据将被称为输入特征数据,并且被包括在内核中的数据将被称为内核数据。
当执行卷积运算时,一般的神经网络系统从存储器器件接收输入特征数据和内核数据两者。因此,在一般的神经网络系统中,随着卷积运算的数量和/或数据量增加,在神经网络处理器和存储器器件之间交换的数据量也可能增加。因此,一般的神经网络系统在数据传输开销增加和功耗增加方面具有限制。
在根据本发明构思的示例性实施例的神经网络系统20中,由于存储器器件300的算术电路370基于在存储器器件300中生成的内部算术控制信号ictrl_ari通过使用输入特征数据和内核数据来执行卷积运算中的全部或一些,并且将计算的数据发送到存储器控制器200,因此可以减少在存储器控制器200和存储器器件300之间交换的数据量。例如,代替将输入特征数据和/或内核数据从存储器器件300发送到神经网络处理器400以用于由神经网络处理器400处理,将以其他方式由神经网络处理器400执行的卷积运算中的一些或全部可以被卸载到存储器器件300的算术电路370。因此,也可以减少将数据从存储器器件300发送到存储器控制器200的时间,并且因此可以减少神经网络系统20的数据传输开销。此外,由于减少了在神经网络处理器400和存储器器件300之间交换的数据量,所以可以提高神经网络系统20的功率效率。
图3示出了卷积神经网络的结构作为神经网络结构的示例。神经网络nn(neuralnetwork)可以包括多个层l1至ln。多个层l1至ln中的每一个可以是线性层或非线性层。在实施例中,至少一个线性层和至少一个非线性层被组合并被称为一个层。例如,线性层可以包括卷积层和完全连接层,并且非线性层可以包括池化层(poolinglayer)和激活层。
例如,第一层l1可以是卷积层,第二层l2可以是池化层,并且第n层ln可以是作为输出层的完全连接层。神经网络nn还可以包括激活层,并且还可以包括用于执行其他类型的操作的层。
多个层l1至ln中的每一个可以接收输入数据(例如,图像帧或显示面板的帧的图像数据)或在前一层中生成的作为输入特征图的特征图,并且通过对输入特征图进行操作来生成输出特征图或识别信号rec。在这种情况下,特征图可以意味着表示输入数据的各种特征的数据。特征图fm1、fm2和fmn可以具有例如二维(two-dimensional,2d)矩阵或三维(three-dimensional,3d)矩阵(或张量)的形式。特征图fm1、fm2和fmn可以具有宽度w(或列)、高度h(或行)和深度d,它们可以分别对应于坐标上的x轴、y轴和z轴。在这种情况下,深度d可以被称为通道(channel)的数量。
第一层l1可以通过将第一特征图fm1与权重图wm进行卷积(缠绕(convolve))来生成第二特征图fm2。权重图wm可以过滤第一特征图fm1,并且也可以被称为过滤器或内核。在实施例中,权重图wm的深度,即通道的数量,等于第一特征图fm1的深度,即通道的数量,并且权重图wm和第一特征图fm1的相同通道彼此卷积(缠绕)。权重图wm可以作为滑动窗口以第一特征图fm1被遍历的这样的方式而移动。移动量可以被称为“步幅长度”或“步幅”。在示例性实施例中,在每次移动期间,被包括在权重图wm中的权重值中的每一个和与第一特征图fm1的重叠区域中的全部特征数据相乘并相加。被包括在权重图wm中的权重值中的每一个与第一特征图fm1重叠的区域中的、第一特征图fm1的数据可以被称为提取数据。由于第一特征图fm1和权重图wm被卷积在一起,所以第二特征图fm2的一个通道被生成。尽管在图3中示出了一个权重图wm,但是可以将多个权重图与第一特征图fm1进行卷积,以生成第二特征图fm2的多个通道。换句话说,第二特征图fm2的通道数量可以对应于权重图的数量。
在示例性实施例中,第二层l2通过池化改变第二特征图fm2的空间大小来生成第三特征图fm3。池化可以被称为采样或下采样。可以以池化窗口pw(poolingwindow)的大小为单位在第二特征图fm2上移动2d池化窗口pw,并且可以选择与池化窗口pw重叠的区域中的特征数据的最大值(或者特征数据的平均值)。因此,具有改变后的空间大小的第三特征图fm3可以从第二特征图fm2生成。在示例性实施例中,第三特征图fm3的通道数量和第二特征图fm2的通道数量彼此相等。
第n层ln可以通过组合第n特征图fmn的特征来分类输入数据的类别cl。此外,第n层ln可以生成对应于类别cl的识别信号rec。在实施例中,输入数据对应于被包括在视频流中的帧数据,并且通过基于从前一层提供的第n特征图fmn来提取与被包括在由帧数据表示的图像中的对象相对应的类别cl,第n层ln可以识别对象并生成对应于所识别对象的识别信号rec。
图4a和图4b是示出神经网络的卷积运算的示图。
参考图4a,输入特征图401可以包括d个通道,并且每个通道的输入特征图可以具有h行和w列的大小(d、h和w是自然数)。内核402中的每一个可以具有r行和s列的大小,并且内核402可以包括与输入特征图401的通道数量(或深度)d相对应的多个通道(r和s是自然数)。输出特征图403可以通过输入特征图401和内核402之间的3d卷积运算而生成,并且可以根据卷积运算包括y个通道。
可以参考图4b描述通过一个输入特征图和一个内核之间的卷积运算来生成输出特征图的过程,并且可以通过执行全部通道的输入特征图401和全部通道的内核402之间的、图4b所示的2d卷积运算来生成全部通道的输出特征图403。
参考图4b,为了方便描述,假设输入特征图410具有6x6的大小,原始内核420具有3x3的大小,并且输出特征图430具有4x4的大小;然而,本发明构思不限于此,并且神经网络可以通过各种大小的特征图和内核来实施。此外,在输入特征图410、原始内核420和输出特征图430中定义的值仅仅是示例值,并且根据本发明构思的实施例不限于此。
原始内核420可以执行卷积运算,同时以3x3窗口为单位在输入特征图410中滑动。卷积运算可以表示用于通过对通过输入特征图410的窗口的每个特征数据和原始内核420中的对应位置的权重值中的每一个相乘而获得的全部值求和来获得输出特征图430的每个特征数据的运算。被包括在输入特征图410的窗口中的数据可以被称为从输入特征图410提取的提取数据。具体地,原始内核420可以首先执行与输入特征图410的第一提取数据411的卷积运算。也就是说,第一提取数据411的各个特征数据1、2、3、4、5、6、7、8和9可以分别乘以原始内核420的对应权重值-1、-3、4、7、-2、-1、-5、3和1,并且可以获得-1、-6、12、28、-10、-6、-35、24和9作为其结果。接下来,可以获得“15”作为将全部获得的值-1、-6、12、28、-10、-6、-35、24和9相加的结果,并且输出特征图430的第一行和第一列的特征数据431可以被确定为“15”。这里,输出特征图430的第一行和第一列中的特征数据431可以对应于第一提取数据411。同样,通过执行原始内核420和输入特征图410的第二提取数据412之间的卷积运算,输出特征图430的第一行和第二列的特征数据432可以被确定为“4”。最后,通过执行原始内核420和输入特征图410的第16提取数据413(即,最后提取数据)之间的卷积运算,输出特征图430的第四行和第四列的特征数据433可以被确定为“11”。
换句话说,可以通过重复执行输入特征图410的提取数据和原始内核420的对应权重值的相乘以及对相乘结果的求和来处理一个输入特征图410和一个原始内核420之间的卷积运算,并且可以生成输出特征图430作为卷积运算的结果。
图5示出了根据本发明构思的示例性实施例的存储器器件300。存储器器件300包括存储体310、行解码器320(例如,解码器电路)、列解码器330(例如,解码器电路)和外围电路340。外围电路340包括输入/输出读出放大器350、控制逻辑360(例如,逻辑电路)和算术电路370。为了便于描述,图5示出了存储器器件300包括一个存储体310的情况;然而,存储体的数量不限于此。例如,存储器器件300可以包括多个存储体。为了简明起见,将省略关于图5相对于图1的存储器器件300的冗余描述。
存储体310可以包括被排列在多个字线wl和多个位线bl彼此交叉的区域中的多个存储单元。在实施例中,多个存储单元中的每一个是包括一个晶体管和一个电容器的dram单元。存储体310可以由行解码器320和列解码器330驱动。
行解码器320可以在外围电路340的控制下在字线wl当中选择至少一个字线。行解码器320可以从外围电路340接收行解码器控制信号row_ctrl和行地址row_addr的输入。行解码器控制信号row_ctrl和行地址row_addr可以由外围电路340基于由图1的位于存储器器件300外部的存储器控制器200提供的命令cmd和地址addr生成。例如,当激活命令和要被激活的字线地址被输入到存储器器件300时,外围电路340可以激活行解码器控制信号row_ctrl并生成行地址row_addr。行解码器320可以基于行解码器控制信号row_ctrl和行地址row_addr来选择至少一个字线。连接到所选字线的一组存储单元可以被认为是所选页面。
列解码器330可以在外围电路340的控制下在位线bl当中选择至少一个位线。由列解码器330选择的位线可以连接到全局输入/输出线gio。列解码器330可以从外围电路340接收列解码器控制信号col_ctrl和列地址col_addr的输入。例如,在激活命令之后,写入命令或读取命令可以被输入到存储器器件300,以将数据存储在所选页面中或者从所选页面读取数据。外围电路340可以激活列解码器控制信号col_ctrl并生成列地址col_addr。
外围电路340可以从位于存储器器件300外部的存储器控制器200接收命令cmd和地址addr的输入。外围电路340可以基于命令cmd和地址addr来生成行解码器控制信号row_ctrl、行地址row_addr、列解码器控制信号col_ctrl和列地址col_addr。外围电路340可以向行解码器320提供行解码器控制信号row_ctrl和行地址row_addr,并且向列解码器330提供列解码器控制信号col_ctrl和列地址col_addr。外围电路340可以与存储器器件300的外部交换数据dq。例如,外围电路340可以通过存储器器件300的数据输入/输出焊盘与外部交换数据dq。
外围电路340可以包括输入/输出读出放大器350、控制逻辑360和算术电路370。
输入/输出读出放大器350可以连接到全局输入/输出线gio,其中该全局输入/输出线gio连接到由列解码器330选择的位线bl。输入/输出读出放大器350可以放大通过全局输入/输出线gio从存储体310发送的信号。
控制逻辑360可以控制存储器器件300的整体操作。在实施例中,控制逻辑360包括命令解码器(例如,解码器电路),并且可以通过解码命令(cmd)相关的信号(诸如芯片选择信号/cs、行地址选通信号/ras、列地址选通信号/cas、写入使能信号/we和时钟使能信号cke)来内部地生成经解码的命令信号。在实施例中,控制逻辑360基于由位于存储器器件300外部的存储器控制器200提供的算术控制信号ctrl_ari来生成内部算术控制信号ictrl_ari。控制逻辑360可以向算术电路370提供内部算术控制信号ictrl_ari。
在实施例中,控制逻辑360在第一操作数op1和/或第二操作数op2存储在存储体310中的操作中控制存储器器件300。例如,假设第一操作数op1存储在存储体310中。控制逻辑360可以通过配置存储体310的地址以存储第一操作数op1使得第一操作数op1可以被顺序输入到算术电路370,控制第一操作数op1被存储在存储体310中。
算术电路370可以基于由控制逻辑360提供的内部算术控制信号ictrl_ari,通过使用第一操作数op1和第二操作数op2来执行算术运算。第一操作数op1和第二操作数op2中的至少一个可以通过包括输入/输出读出放大器350的路径而从存储体310获得。例如,算术电路370可以从存储体310获得第一操作数op1和第二操作数op2两者。此外,例如,算术电路370可以从存储体310获得第一操作数op1和第二操作数op2中的任何一个,并且从存储器器件300外部获得第一操作数op1和第二操作数op2中的另一个。算术电路370可以通过使用第一操作数op1和第二操作数op2执行算术运算来生成计算的数据data_cal,并且将计算的数据data_cal输出到存储器器件300的外部。例如,算术电路370可以将第一操作数op1乘以第二操作数op2以生成第一乘法数据,将第一乘法数据与第二乘法数据相加等。在实施例中,算术运算可以包括卷积运算中的全部或一些,其中第一操作数op1是被包括在输入特征图中的输入特征数据,并且第二操作数op2是被包括在内核中的内核数据。
根据实施例,算术电路370可以在存储器器件300中以各种形式实施,并且算术电路370可以以硬件形式或软件形式实施。例如,当算术电路370以硬件形式实施时,算术电路370可以包括用于执行算术运算的电路。此外,例如,当算术电路370以软件形式实施时,可以由存储器器件300中的控制逻辑360或至少一个处理器通过运行存储在存储器器件300中的随机输入/输出代码和/或程序(或指令)来执行算术运算。然而,本发明构思不限于上面的实施例,并且算术电路370可以实施为软件和硬件的组合,诸如固件。
图6示出了根据本发明构思的示例性实施例的存储器器件300。为了简明起见,将省略关于图6的存储器器件300相对于图5的冗余描述。
存储器器件300包括存储体310、行解码器320、列解码器330、输入/输出读出放大器350和算术电路370。
存储体310可以包括沿着多个字线wl和多个位线bl的方向以矩阵形式排列的多个子存储单元阵列。子存储单元阵列中的每一个可以包括多个存储单元。在多个字线wl当中,连接到子存储单元阵列的字线将被称为子字线swl,并且在多个位线bl当中,连接到子存储单元阵列的位线将被称为子位线sbl。存储体310在字线方向上可以包括n(n是自然数)个子存储单元阵列,并且在位线方向上可以包括m(m是自然数)个子存储单元阵列。
存储体310可以包括多个位线读出放大器(bitlinesenseamplifier,blsa)、多个子字线驱动器(subwordlinedriver,swd)和多个结(junction,cjt)。在实施例中,每个结包括用于用非接地电压来驱动位线读出放大器中的一个的功率驱动器和/或用于用接地电压来驱动一个位线读出放大器的接地驱动。多个子字线驱动器中的每一个可以驱动连接到子字线驱动器的子字线。多个位线读出放大器中的每一个可以放大子位线sbl和互补子位线sblb之间的电压差。换句话说,位线读出放大器可以放大通过子位线sbl发送的信号。多个子字线驱动器和多个位线读出放大器可以被重复地排列在多个子存储单元阵列之间。
存储在存储体310的存储单元中的数据可以通过位线bl和全局输入/输出线gio发送到输入/输出读出放大器350。
在实施例中,算术电路370被排列在排列了输入/输出读出放大器350的区域中。此外,算术电路370可以通过包括输入/输出读出放大器350的路径从存储体310获得第一操作数和第二操作数中的至少一个。为了便于描述,
图6示出了其中算术电路370的算术运算是卷积运算中的全部或一些的实施例,第一操作数是输入特征数据ifd,并且第二操作数是内核数据knd。换句话说,基于被包括在存储器器件300中生成的内部算术控制信号ictrl_ari中的内部读取信号,算术电路370通过包括输入/输出读出放大器350的路径从存储体310获得输入特征数据ifd和内核数据knd中的至少一个。算术电路370可以通过使用输入特征数据ifd和内核数据knd执行卷积运算中的全部或一些来生成计算的数据data_cal。算术电路370可以输出计算的数据data_cal。
图7示出了根据本发明构思的示例性实施例的算术电路370。为了简明起见,将省略关于图7的算术电路370相对于图1、图2、图5和图6的冗余描述。将参考图6描述图7。
图7示出了其中从存储器器件300外部输入该输入特征数据ifd并且从存储体310获得内核数据knd的情况。然而,这仅仅是为了便于描述,并且也可以从存储体310获得输入特征数据ifd。
算术电路370包括多个乘法和累加电路。例如,算术电路370可以包括第一乘法和累加电路372_1至第n乘法和累加电路372_n。这里,n可以等于图6的存储体310中在字线方向上的子存储单元阵列的数量。输入特征数据ifd可以包括第一输入特征数据ifd_1至第n输入特征数据ifd_n,并且内核数据knd可以包括第一内核数据knd_1至第n内核数据knd_n。第一输入特征数据ifd_1至第n输入特征数据ifd_n中的每一个可以是n比特数据(n是自然数),并且第一内核数据knd_1至第n内核数据knd_n可以是n比特数据。作为非限制性示例,第一输入特征数据ifd_1至第n输入特征数据ifd_n以及第一内核数据knd_1至第n内核数据knd_n可以是8比特数据。
第一乘法和累加电路372_1可以通过使用第一输入特征数据ifd_1和第一内核数据knd_1执行乘法运算和加法运算来生成第一计算的数据data_cal_1,并输出第一计算的数据data_cal_1。例如,第一乘法和累加电路372_1可以响应于被包括在内部算术控制信号ictrl_ari中的输出信号而输出第一计算的数据data_cal_1。作为非限制性示例,第一计算的数据data_cal_1可以是2n比特数据或(2n+1)比特数据。如参考图4a和图4b所述,在卷积运算的情况下,可以包括多次的将输入特征数据和内核数据相乘然后求和的过程。为此,第一乘法和累加电路372_1可以执行乘法运算和加法运算。
同样,第二乘法和累加电路372_2可以通过使用第二输入特征数据ifd_2和第二内核数据knd_2执行乘法运算和加法运算来生成第二计算的数据data_cal_2,并输出第二计算的数据data_cal_2。例如,第二乘法和累加电路372_2可以响应于被包括在内部算术控制信号ictrl_ari中的输出信号而输出第二计算的数据data_cal_2。
同样,第n乘法和累加电路372_n可以通过使用第n输入特征数据ifd_n和第n内核数据knd_n执行乘法运算和加法运算来生成第n计算的数据data_cal_n,并输出第n计算的数据data_cal_n。例如,第n乘法和累加电路372_n可以响应于被包括在内部算术控制信号ictrl_ari中的输出信号而输出第n计算的数据data_cal_n。
计算的数据可以包括第一计算的数据data_cal_1至第n计算的数据data_cal_n中的至少一个。
图8示出了根据本发明构思的示例性实施例的乘法和累加电路。为了便于描述,图8示出了图7的第一乘法和累加电路372_1。图7的第二乘法和累加电路372_2至第n乘法和累加电路372_n也可以包括图8所示的配置。为了简明起见,将省略关于第一乘法和累加电路372_1相对于图7的冗余描述。
第一乘法和累加电路372_1包括乘法器373(例如,乘法器电路)、加法器374(例如,加法器电路)和寄存器375。
乘法器373可以通过将第一输入特征数据ifd_1乘以第一内核数据knd_1来生成乘法数据data_mul,并且将乘法数据data_mul提供给加法器374。
寄存器375可以临时存储计算的数据。寄存器375可以将所存储的计算的数据提供给加法器374作为累加数据data_acc。
加法器374可以通过将乘法数据data_mul与从寄存器375提供的累加数据data_acc相加来生成更新后的数据data_upd。换句话说,加法器374可以通过将乘法数据data_mul与由寄存器375提供的计算的数据相加来更新计算的数据。寄存器375可以在特定时间输出计算的数据作为第一计算的数据data_cal_1。例如,当输出信号被输入到算术电路370时,寄存器375可以输出第一计算的数据data_cal_1。
这样,第一乘法和累加电路372_1可以通过使用乘法器373来执行乘法运算,并且可以通过使用加法器374和寄存器375来累加数据。
图9示出了根据本发明构思的示例性实施例的算术电路370。与图7相比,图9示出了其中多个乘法和累加电路以环状形式连接的实施例。在实施例中,尽管图9中未示出,但是第一乘法和累加电路372_1的加法器374_1也从第n乘法和累加电路372_n的寄存器375_n接收数据。
第一乘法和累加电路372_1的乘法器373_1可以将第一输入特征数据ifd_1乘以第一内核数据knd_1以生成第一乘法数据,第一乘法和累加电路372_1的加法器374_1可以将第一乘法数据与给定初始值或从第n乘法和累加电路372_n的寄存器375_n提供的数据相加以生成第一结果值,并且寄存器375_1可以临时存储第一结果值,然后将其提供给第二乘法和累加电路372_2的加法器374_2。
第二乘法和累加电路372_2的乘法器373_2可以将第二输入特征数据ifd_2乘以第二内核数据knd_2以生成第二乘法数据,第二乘法和累加电路372_2的加法器374_2可以将第二乘法数据与从第一乘法和累加电路372_1的寄存器375_1提供的数据相加以生成第二结果值,并且寄存器375_2可以临时存储第二结果值,然后将其提供给第三乘法和累加电路的加法器。
在卷积运算的情况下,它可以包括将多个输入特征数据和多个内核数据相乘然后求和的运算。因此,因为算术电路370具有多个乘法和累加电路以环状形式连接的结构,所以第二乘法和累加电路372_2可以使用由第一乘法和累加电路372_1计算的结果,并且第三乘法和累加电路可以使用由第二乘法和累加电路372_2计算的结果,以执行算术运算。
寄存器375_1至375_n可以在特定时间输出计算的数据data_cal。例如,当输出信号被输入到算术电路370时,寄存器375_1至375_n可以输出计算的数据data_cal。计算的数据data_cal可以包括第一计算的数据data_cal_1至第n计算的数据data_cal_n中的至少一个。
图10示出了根据本发明构思的示例性实施例的算术电路370。与图7相比,图10示出了其中算术电路370还包括多个非线性函数处理器376_1至376_n、多个量化器377_1至377_n和多个缓冲存储器378_1至378_n的实施例。
第一非线性函数处理器376_1对由第一乘法和累加电路372_1相乘和累加的数据运行非线性函数。例如,非线性函数可以包括诸如sigmoid函数、双曲正切函数和整流线性单位函数(rectifiedlinearunitfunction,relu)的函数。第一非线性函数处理器376_1可以通过对由第一乘法和累加电路372_1提供的数据运行非线性函数来向第一量化器377_1提供非线性函数处理后的数据。
输入到第一量化器377_1的数据可以是2n比特数据或(2n+1)比特数据。第一量化器377_1可以以n比特数据来量化2n比特数据。在示例性实施例中,第一量化器377_1对其接收的数据执行截断(truncation)或取整(rounding)运算。在示例性实施例中,第一量化器377_1使用截断或取整运算将2n比特数据转换为n比特数据。
由第一量化器377_1量化的数据可以临时存储在第一缓冲存储器378_1中,并且被顺序地输出作为第一计算数据data_cal_1。
第二非线性函数处理器376_2至第n非线性函数处理器376_n可以理解为与第一非线性函数处理器376_1类似地操作,第二量化器377_2至第n量化器377_n可以理解为与第一量化器377_1类似地操作,并且第二缓冲存储器378_2至第n缓冲存储器378_n可以理解为与第一缓冲存储器378_1类似地操作。
由算术电路370输出的计算的数据data_cal可以包括第一计算的数据data_cal_1至第n计算的数据data_cal_n中的至少一个。
图11示出了根据本发明构思的示例性实施例的算术电路370和内部算术控制信号ictrl_ari。将参考图5描述图11。
内部算术控制信号ictrl_ari可以在存储器器件300中生成。例如,内部算术控制信号ictrl_ari可以由存储器器件300的控制逻辑360生成。在实施例中,控制逻辑360基于由位于存储器器件300外部的存储器控制器200提供的算术控制信号ctrl_ari来生成内部算术控制信号ictrl_ari。
在示例性实施例中,内部算术控制信号ictrl_ari包括内部读取信号ird和内部写入信号iwr。在示例性实施例中,内部算术控制信号ictrl_ari包括算术运算起动信号iop、算术初始化信号irst和输出信号out中的至少一个。
在示例性实施例中,当由算术电路370接收到内部读取信号ird时,存储器器件300通过包括输入/输出读出放大器350的路径将在算术电路370的算术运算中使用的操作数从存储体310发送到算术电路370。换句话说,存储器器件300基于内部读取信号ird将操作数从存储体310读取到算术电路370。与其中存储在存储单元中的数据通过数据输入/输出缓冲器而发送到存储器器件300的外部的一般读取操作不同,在内部读取操作中,存储在存储单元中的数据仅被读取到算术电路370。
在示例性实施例中,当由算术电路370接收到内部写入信号iwr时,存储器器件300通过包括数据输入/输出缓冲器的路径将在算术电路370的算术运算中使用的操作数从存储器器件300外部发送到算术电路370。换句话说,存储器器件300基于内部写入信号iwr将操作数从存储器器件300外部写入算术电路370。与其中外部数据被发送到存储单元的一般写入操作不同,在内部写入操作中,外部数据仅被写入算术电路370。
在示例性实施例中,当由算术电路370接收到算术运算起动信号iop时,算术电路370通过使用多个操作数来起动算术运算的执行。例如,算术电路370可以基于算术运算起动信号iop来起动对输入特征数据和内核数据执行卷积运算中的全部或一些。
在示例性实施例中,当由算术电路370接收到算术初始化信号irst时,算术电路370被初始化。例如,基于算术初始化信号irst,存储在被包括在算术电路370中的寄存器中的临时数据可以被擦除。
在示例性实施例中,当由算术电路370接收到输出信号out时,算术电路370输出计算的数据data_cal。换句话说,输出信号out可以控制算术电路370输出计算的数据data_cal。
如上所述,为了算术电路370通过使用操作数来执行算术运算,存储器器件300可以生成内部算术控制信号ictrl_ari。
图12示出了根据本发明构思的示例性实施例的用于描述内部读取操作的存储器器件300的配置。存储器器件300包括存储体310、列解码器330、输入/输出读出放大器350和算术电路370。为了简明起见,将省略关于存储器器件300相对于参考图1至图12的描述的冗余描述。将参考图5描述图12。
控制逻辑360可以基于从外部接收的算术控制信号ctrl_ari来生成内部读取信号ird。
当算术电路370接收到内部读取信号ird时,存储器器件300通过包括输入/输出读出放大器350的路径将操作数op从存储体310读取到算术电路370。换句话说,操作数op的传输路径可以与第一路径301相同。换句话说,根据内部读取操作,数据不被发送到存储器器件300的外部。
图13示出了根据本发明构思的示例性实施例的用于描述内部写入操作的存储器器件300的配置。存储器器件300包括算术电路370、数据输入/输出缓冲器380和数据输入/输出焊盘390。为了简明起见,将省略关于存储器器件300相对于参考图1至图12的描述的冗余描述。将参考图5描述图13。
控制逻辑360基于从外部接收的算术控制信号ctrl_ari来生成内部写入信号iwr。
当算术电路370接收到内部写入信号iwr时,存储器器件300通过包括数据输入/输出焊盘390和数据输入/输出缓冲器380的路径将操作数op从存储器器件300外部发送到算术电路370。换句话说,操作数op的传输路径可以与第二路径302相同。换句话说,根据内部写入操作,数据不被发送到存储器器件300的存储单元。
图14示出了根据本发明构思的示例性实施例的内部算术控制信号ictrl_ari。内部算术控制信号ictrl_ari可以包括内部读取信号ird、内部写入信号iwr和算术运算起动信号iop。
在实施例中,同时生成内部读取信号ird、内部写入信号iwr和算术运算起动信号iop中的两个或更多个。
因为作为根据图12的内部读取信号ird的内部读取操作中的数据的传递路径的第一路径301和作为根据图13的内部写入信号iwr的内部写入操作中的数据的传递路径的第二路径302彼此不重叠,所以与一般的读取命令和写入命令不同,可以同时生成内部读取信号ird和内部写入信号iwr。
在实施例中,如图12中,当同时激活内部读取信号ird、内部写入信号iwr和算术运算起动信号iop时,算术电路可以在更短的时间内执行算术运算。
图15示出了根据本发明构思的示例性实施例的存储器器件300。为了简明起见,将省略关于图15的存储器器件300相对于图1、图2和图5的冗余描述。将主要针对与图6的差异来描述图15。
算术电路可以被排列在排列了位线读出放大器(blsa)的区域中。换句话说,存储器器件300可以包括多个算术电路,并且多个算术电路可以被包括在存储体310中,并且可以被重复地排列在多个子存储单元阵列之间。多个算术电路可以接收由位线读出放大器放大的信号作为操作数,并且通过使用操作数来执行算术运算。
当算术电路被排列在排列了位线读出放大器的区域中以执行算术运算时,存储器器件300的运算速度可以进一步提高。
图16示出了根据本发明构思的示例性实施例的存储器器件300的结构。在实施例中,图16可以表示实施为mram的存储器器件300的结构。存储器器件300包括第一存储体310_1至第四存储体310_4、第一行解码器320_1至第四行解码器320_4、第一列解码器330_1至第四列解码器330_4、以及算术电路370。此外,存储器器件300可以包括排列了外围电路的外围区域和数据输入/输出缓冲器所在的数据输入/输出缓冲器区域。存储体的数量、行解码器的数量、列解码器的数量及其详细排列配置仅仅是示例,并且不限于图16的结构。
在示例性实施例中,被包括在第一存储体310_1至第四存储体310_4中的存储单元中的至少一些被实施为mram。
算术电路370可以被排列在数据输入/输出缓冲器区域中。算术电路370可以电连接到第一列解码器330_1至第四列解码器330_4,以从第一存储体310_1至第四存储体310_4获得算术运算所需的操作数,并且可以通过使用操作数来执行算术运算。例如,算术电路370可以通过使用输入特征数据和内核数据来执行卷积运算中的全部或一些。为此,算术电路370可以包括多个乘法和累加电路。此外,在实施例中,被包括在算术电路370中的多个乘法和累加电路可以以矩阵形式排列。
因为算术电路370执行卷积运算中的全部或一些,所以可以减少由存储器器件300发送/接收的数据量。
图17示出了根据本发明构思的示例性实施例的电子系统1000。电子系统1000包括神经网络处理单元1100、随机存取存储器(ram)1200、处理器1300、存储器1400和传感器模块1500。神经网络处理单元1100可以对应于图2的神经网络处理器400,并且ram1200可以对应于图2的存储器器件300。
电子系统1000可以应用于无人机、机器人装置(诸如高级驾驶辅助系统(advanceddriverassistancesystem,adas))、智能tv、智能电话、医疗设备、移动设备、图像显示设备、测量设备或物联网(iot)设备,并且还可以安装在各种其他类型的电子设备中的一种上。
用于连接被包括在电子系统1000中的组件的技术可以包括基于系统总线的连接方法。例如,高级risc机器(advancedriscmachine,arm)公司的高级微控制器总线架构(advancedmicrocontrollerbusarchitecture,amba)协议可以应用为系统总线的标准。amba协议的总线类型可以包括高级高性能总线(advancedhigh-performancebus,ahb)、高级外围总线(advancedperipheralbus,apb)、高级可扩展接口(advancedextensibleinterface,axi)、axi4和axi一致性扩展(axicoherencyextensions,ace)。在上面的总线类型中,axi可以是ip之间的接口协议,并且可以提供多重未完成地址功能(multipleoutstandingaddressfunction)和数据交织功能。此外,诸如sonics公司的unetwork、ibm公司的coreconnect和ocp-ip的开放式核心协议(opencoreprotocol)的其他类型的协议也可以应用于系统总线。
ram1200可以临时存储程序、数据或命令(指令)。例如,存储在存储器1400中的程序和/或数据可以根据启动代码或处理器1300的控制而临时加载到ram1200中。ram1200可以通过使用诸如动态ram(dram)或静态ram(sram)的存储器而实施。
处理器1300可以控制电子系统1000的整体操作,并且作为示例,处理器1300可以是中央处理单元(cpu)。处理器1300可以包括处理器核心或者可以包括多个处理器核心(多核)。处理器1300可以处理或运行存储在ram1200和存储器1400中的程序和/或数据。例如,处理器1300可以通过运行存储在存储器1400中的程序来控制电子系统1000的功能。
存储器1400可以是用于存储数据的存储设备,并且可以存储例如操作系统(os)、各种程序和各种数据。存储器1400可以是dram,但不限于此。存储器1400可以包括易失性存储器或非易失性存储器中的至少一个。非易失性存储器可以包括例如只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)、闪存、相变ram(pram)、磁ram(mram)、电阻ram(rram)和/或铁电ram(ferroelectricram,fram)。易失性存储器可以包括例如动态ram(dram)、静态ram(sram)、同步dram(synchronousdram,sdram)、相变ram(pram)、磁ram(mram)、电阻ram(rram)和/或铁电ram(ferroelectricram,feram)。此外,在实施例中,存储器1400可以包括硬盘驱动器(harddiskdrive,hdd)、固态驱动器(solidstatedrive,ssd)、紧凑型闪存(compactflash,cf)、安全数字(securedigital,sd)、微安全数字(microsecuredigital,micro-sd)、迷你安全数字(minisecuredigital,mini-sd)、极限数字(extremedigital,xd)和记忆棒中的至少一个。
传感器模块1500可以收集关于电子系统1000的信息。传感器模块1500可以感测或接收来自电子系统1000外部的图像信号,并且可以将感测到或接收到的图像信号转换为图像数据,即图像帧。为此,传感器模块1500可以包括感测设备,例如,各种类型的感测设备(诸如照相机、成像设备、图像传感器、光检测和测距(lightdetectionandranging,lidar)传感器、超声波传感器和红外传感器)中的至少一种,或者可以从感测设备接收感测信号。在实施例中,传感器模块1500向神经网络处理单元1100提供图像帧。例如,传感器模块1500可以包括图像传感器,并且可以通过捕获电子系统1000的外部环境的图像来生成视频流,并且顺序地将视频流的连续图像帧提供给神经网络处理单元1100。
根据本发明构思的示例性实施例,ram1200包括算术电路1270。算术电路1270可以基于在ram1200中生成的内部算术控制信号来对操作数执行算术运算。例如,算术电路1270可以通过对操作数执行卷积运算中的全部或一些来向神经网络处理单元1100输出计算的数据data_cal。参考图1至图16描述的特征可以应用于算术电路1270上的特定运算。
上面已经参考附图描述了本发明构思的示例性实施例。尽管本文使用了特定术语来描述实施例,但是它们仅用于描述本发明构思的技术思想,并不旨在限制本发明构思的范围。因此,本领域的普通技术人员将理解,可以从中推导出各种修改和其他等同实施例。
- 还没有人留言评论。精彩留言会获得点赞!