基于CNN双向GRU注意力机制的短文本情感分析方法与流程
本发明属于自然语言处理领域,尤其涉及一种基于cnn双向gru注意力机制的短文本情感分析方法
背景技术:
随着互联网的高速发展,越来越多的用户通过社交媒体表达自己的观点抒发自己的情感评论,其中大多数评论以短文本的形式存在。热点事件会引起社会的广泛关注讨论,及时掌握舆情导向,获取用户情感倾向是一个极具挑战性任务。
情感分析通过对文本的预处理,分析,挖掘用户的情感倾向,可以了解到大众对热点事件的情感变化,也是自然语言处理的重要方向之一。情感分析研究方法主要分为基于词典的方法,基于机器学习的方法,基于深度学习的方法。基于词典的方法主要依赖于词典的构建与选择判断句子情感极性,不同的词语有着不用的情感得分,对句子情感分类的贡献度不同,但因其领域适应性较差,通常作为辅助方法。基于机器学习的方法依赖选取有效特征组合利用分类器进行情感分类,但这种方法需要大量人工标注数据集来训练模型,费时费力。基于深度学习的方法,可以挖掘深层的语义情感含义,应用广泛,但是有监督的深度学习仍需要大量标注,而无监督方法对于文本的语义关联要求较高,其中否定词、程度副词、转折词等的使用可能导致句子的情感极性偏移影响情感分析结果准确性,还需进一步发展改进。
技术实现要素:
本发明针对上述问题:本发明提供一种基于cnn双向gru注意力机制的短文本情感分析方法。充分利用情感词自身信息,根据情感词在数据集内不同极性的句子中出现的频率来计算情感得分得出情感特征向量矩阵融入卷积网络;对影响句子极性的否定词、转折词通过双向gru注意力机制深入获取句子表征,从而提高情感分析结果的准确性;减少人工标注环节极大节省工时。
为实现上述目的,提出本发明的技术方案:基于cnn双向gru注意力机制的短文本情感分析方法,根据情感词在数据集内不同极性的句子中出现的频率来计算情感得分,融入卷积神经网络,对影响句子极性的否定词转折词通过双向gru注意力机制深入获取句子表征,从而提高情感分析结果的准确性。
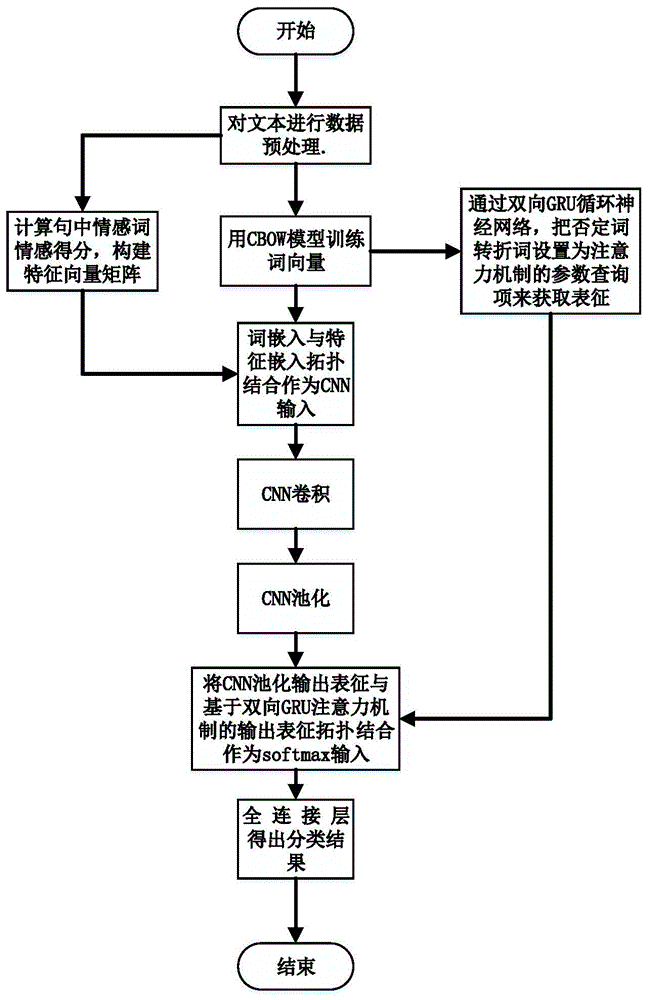
本发明的技术方案包括:对短文本预处理,除噪、分词、词性标注、去除停用词;通过连续词袋模型(cbow)将句子以词为单位通过负采样训练表示成一个词序列,并将其映射为一个多维向量来构造词向量集合;计算情感词在不同数据集文档出现频数计算情感分值继而转化成特征向量;词嵌入与特征嵌入拓扑作为卷积神经网络输入,卷积,池化得到句子表征;通过双向gru循环神经网络,把否定词转折词设置为注意力机制的参数查询项来获取表征;两种表征拓扑结合作为全连接层输入,输出情感分析结果。
具体步骤如下:
(1)对短文本预处理,除噪、分词、词性标注、去除停用词。用中科院分词系统(nlpir)对句子进行分词、词性标注,用哈工大停用词库去除停用词。
(2)通过连续词袋模型(cbow)将句子以词为单位通过负采样训练表示成一个词序列,并将其映射为一个多维向量来构造词向量集合。即每一个词wi都会由一个多维的向量qi表示。
(3)计算情感词在不同数据集文档出现频数计算情感分值继而转化成特征向量。
使用hownet情感词典,wi为情感词典的第i个情感词,
(4)词嵌入与特征嵌入拓扑作为卷积神经网络输入,卷积,池化得到句子表征。若wi词为情感词,词嵌入与特征嵌入拓扑得出为xi,cnn可接收句子的平行化输入,卷积窗口长度为h,通过卷积核对输入矩阵x1:n进行卷积操作可得到卷积后特征向量:c=[c1,c2,…,cn-h+1]。
(5)通过双向gru循环神经网络,把否定词转折词设置为注意力机制的参数查询项来获取表征。具体步骤如附图3所示。词嵌入表征经过双向gru网络输出句子的隐含层表征向量ε。门控循环单元(gru)如图2所示:
其中ωt,ξt分别表示t时刻bi-gru所对应的前向隐层状态
将否定词、转折词和程度副词作为参数化查询项va,由双向gru网络输出的句子表征和参数化查询项va得到m,由m和参数化查询项va得到权重αi,由αi和εi得到关于否定词、转折词和程度副词作为参数化查询项注意力机制的特征向量&。
m=tanh(wsεi+wtva)
其中ws为特性向量εi的可调节权重矩阵,wt为参数化查询项va的可调节权重矩阵,mt为权重矩阵m的转置矩阵。
(6)将cnn提取的到的特征向量
其中wp为权重矩阵,y为偏置项,softmax为cnn网络全连接层的回归函数,值域为[0,1]。
有益效果:
本发明提供一种基于cnn双向gru注意力机制的短文本情感分析方法。充分利用情感词自身信息,根据情感词在数据集内不同极性的句子中出现的频率来计算情感得分得出情感特征向量矩阵融入卷积网络;对影响句子极性的否定词、转折词通过双向gru注意力机制深入获取句子表征,从而提高情感分析结果的准确性;减少人工标注环节极大节省工时。
附图说明
图1本发明的方法流程图。
图2为本发明gru网络内部结构图;
图3本发明双向gru网络注意力机制模型。
具体实施方式
下面结合附图和具体实施方式对本发明进行描述。
其中,附图1描述了基于cnn双向gru注意力机制的短文本情感分析方法方法处理过程。
如图1所示,本发明具体的实现步骤:
(1)对短文本预处理,除噪、分词、词性标注、去除停用词。用中科院分词系统(nlpir)对句子进行分词、词性标注,用哈工大停用词库去除停用词。
(2)通过连续词袋模型(cbow)将句子以词为单位训练表示成一个词序列,并将其映射为一个多维向量来构造词向量集合。连续词袋模型是word2vec词嵌入的一种,基于某中心词在文本序列前后的背景词来生成该中心词,构建词向量矩阵。即每一个词wi都会由一个多维的向量qi表示。word2vec词嵌入的训练方法主要有二次采样和负采样,负采样即对于一对中心词和背景词随机采样k个噪声词来进行近似训练,通过考虑同时含有正类样本和负类样本的相互独立事件来构造损失函数。每次让一个训练样本只更新部分权重,其他权重全部固定;减少计算量。
(3)计算情感词在不同数据集文档出现频数计算情感分值继而转化成特征向量。
使用hownet情感词典,wi为情感词典的第i个情感词,
(4)词嵌入与特征嵌入拓扑作为卷积神经网络输入,卷积,池化得到句子表征。若wi词为情感词,词嵌入与特征嵌入拓扑得出为:
cnn可接收句子的平行化输入,卷积窗口长度为h,通过卷积核对输入矩阵x1:n进行卷积操作:
ci=f(w·xi:i+h+1+b)
其中,w∈rh×l为卷积核权重,l为xi的维度,b为偏置项,f为激活函数,xi:i+h+1为一个卷积窗口的词向量矩阵。长度为n的句子通过卷积操作可得到卷积后特征向量:c=[c1,c2,…,cn-h+1],其中c∈rn-h+1。
采取最大池化方法对卷积后的特征向量c进行池化操作,提取最重要信息,对于有m个卷积核的窗口池化后得到cnn提取的到的特征向量
(5)门控循环单元(gru)如图2所示,图中更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选隐藏状态
rt=σ(xtwxr+ht-1whr+br)
zt=σ(xtwxz+ht-1whz+bz)
其中wxr,wxz∈rd×h和,whr,whz∈rh×h是权重参数,br,bz∈r1×h是偏差参数。σ是sigmoid函数,值域为[0,1].时间步t的候选隐藏状态
其中wxh∈rd×h和whh∈rh×h是权重参数,bh∈r1×h是偏差参数;
时间步t的隐藏状态ht∈rn×h为:
通过双向gru循环神经网络,把否定词转折词设置为注意力机制的参数查询项来获取表征。具体步骤如附图3所示。词嵌入表征经过双向gru网络输出句子的隐含层表征向量ε。
其中ωt,ξt分别表示t时刻bi-gru所对应的前向隐层状态
将否定词、转折词和程度副词作为参数化查询项va注意力嵌入,由双向gru网络输出的句子表征和参数化查询项va得到m,由m和参数化查询项va得到特征权重αi,最终由特征权重αi和双向gru网络输出的表征εi得到关于否定词、转折词和程度副词作为参数化查询项注意力机制的特征向量&。
m=tanh(wsεi+wtva)
其中ws为特性向量εi的可调节权重矩阵,wt为参数化查询项va的可调节权重矩阵,mt为权重矩阵m的转置矩阵。
(6)将cnn提取的到的特征向量
其中wp为权重矩阵,y为偏置项,softmax为cnn网络全连接层的回归函数,值域为[0,1],因而每个短文本最后输出的概率结果p值域为[0,1],即转换为一个二分类问题,以0.5为预值,概率大于0.5的为一类,概率小于0.5的为另一类,与之对应的分类是消极和积极,示例如表1所示。
表1经典短文本分析
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,且应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!