一种基于数据去重的分布式数据挖掘与统计方法与流程
本发明属于网络流量分析技术领域,尤其涉及一种基于数据去重的分布式数据挖掘与统计方法。
背景技术:
随着计算机技术和互联网的发展,宽带速率的提高和费用的降低,使得人们的生活和工作与网络的联系愈发紧密,网络数据包数量呈几何级增长。对于目前的网络流量数据分析,即使是经验丰富的分析员,一天也最多只能分析约1700000个数据包。而据统计一个家庭一周所产生的数据包能够达到1亿级别,已然不是一个可以轻易分析的量级。若是采集一个公司、学校、政府等端点的流量,数据包将是一个天文级别。数据量级大、数据复杂程度高、数据处理慢等严重影响着数据挖掘与统计效率。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种基于数据去重的分布式数据挖掘与统计方法,包括如下步骤:
s1:系统获取网络流量数据包;
s2:中心服务器进行负载均衡后将数据包拆分发送至分布式服务器集群;
s3:用户配置数据聚合挖掘条件,分布式服务器集群中各个服务器节点分别根据数据聚合挖掘条件对数据进行匹配挖掘;
s4:中心服务器合并匹配挖掘到的数据;
s5:用户配置数据聚合挖掘条件,系统遍历所有数据会话,系统再次对数据进行匹配挖掘;
s6:输出聚合挖掘数据结果。
本发明的有益效果在于:本发明通过分布式处理原始数据,从而大大的降低数据包的数量级别,提高分析效率,且数据量越大效果越明显;通过数据去重的聚合条件配置与挖掘,再辅以后端服务器集群的多任务智能化调度与多路并发数据挖掘运算,大大降低了用户配置复杂挖掘条件的难度,强化了数据挖掘的针对性,通过智能化和多路并发加成大幅提升了数据挖掘的效率。
附图说明
图1是本发明的流程图;
图2是本发明的系统图。
具体实施方式
下面结合附图对本发明作进一步说明:
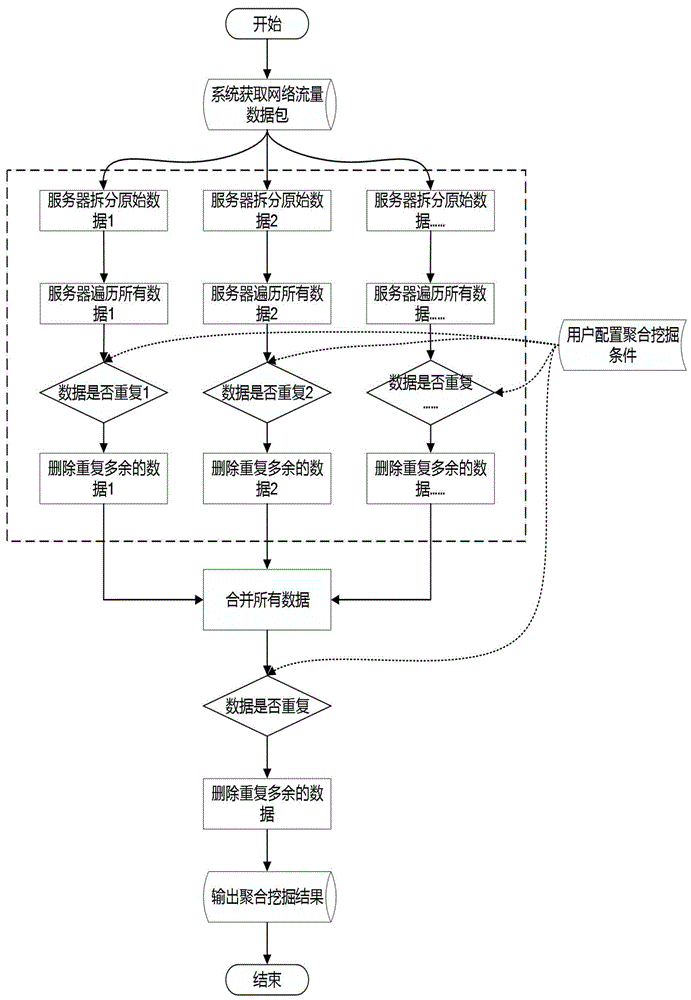
如图1所示,本发明一种基于数据去重的分布式数据挖掘与统计方法,包括如下步骤:
s1:系统获取网络流量数据包;
s2:中心服务器进行负载均衡后将数据包拆分发送至分布式服务器集群;
s3:分布式服务器集群遍历数据包所有数据,并根据用户配置的数据聚合挖掘条件,分布式服务器集群中各个服务器节点分别判断数据是否重复,若不重复则保留,否则删除重复多余的数据;
s4:中心服务器合并去重后的数据;
s5:中心服务器遍历去重后的数据,并根据用户配置数据聚合挖掘条件,判断数据是否重复,若不重复则保留,否则删除重复多余的数据;
s6:系统输出聚合挖掘数据结果。
进一步的,所述s2中负载均衡过程中心服务器是根据分布式服务器集群中各服务器节点的硬件配置性能和当前负载来分配任务量的。
进一步的,所述s3中的匹配挖掘过程是根据用户配置条件对数据流量包中七元组信息的匹配。
进一步的,所述s5中的中心服务器合并数据为异步操作,只要收到一个分布式节点中的结果返回便进行一次合并计算。
进一步的,所述s5具体包括:用户配置数据聚合挖掘条件,系统遍历所有数据会话,判断回话是否为系统第一次遇到的会话,若是则保留该会话,否则舍去该会话。
进一步的,所述用户配置数据挖掘条件为源地址与源端口的会话。
系统获取原始网络流量数据包,对数据包按比例进行拆分,这个拆分是根据服务器集群中各个服务器节点的状态来匹配的,主要有两个判断维度:硬件配置、当前负载。例如,一共有100万条数据源,共有三台用于分析的服务器a、b、c,其中服务器a和服务器c配置较好,但a的当前负载低于c的当前负载,那么a分配到50%的数据条数,c分配到40%的数据条数,服务器b配置稍差只分配20%的数据条数。
集群中的节点服务器对拆分后的数据进行数据匹配,匹配条件是作用于数据流量包中七元组数据,将符合匹配条件的会话数据提取出来,并只保留会话中max数据或者min数据,得到多组数值。例如,匹配条件为求和源ip为1.1.1.1会话的出流量总数,那么首先通过条件“源ip为1.1.1.1”匹配所有会话,得到所有源ip为1.1.1.1的会话,然后只取出会话中的出流量数据,得到匹配的最终结果。
中心服务器合并数据,只要收到一个分布式节点中的结果返回便进行一次合并计算。
例如共计一百万条会话,去重条件是源地址和源端口。首先系统将这100万条会话按照配置文件的配置进行负载均衡,自动拆分后分配给各个服务器(a、b和c);其次各个服务器自行遍历所有分配到的会话,使用源地址与源端口的条件进行去重,只保留第一次遇到的源地址与源端口不同的会话,后面相同源地址与源端口的会话都丢弃;然后服务器b、服务器c的去重结果汇总给服务器a,服务器a再进行一次遍历并保留第一次遇到的源地址与源端口会话,后面遇到的都丢弃;最后服务器a从得到的去重会话中只提取源地址和源端口的值形成一个新的列表,得到最终结果,并在用户终端进行显示,具有较强的直观性。
本发明通过分布式处理原始数据,从而大大的降低数据包的数量级别,提高分析效率,且数据量越大效果越明显;通过数据去重的聚合条件配置与挖掘,再辅以后端服务器集群的多任务智能化调度与多路并发数据挖掘运算,大大降低了用户配置复杂挖掘条件的难度,强化了数据挖掘的针对性,通过智能化和多路并发加成大幅提升了数据挖掘的效率。
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
技术特征:
1.一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,包括如下步骤:
s1:系统获取网络流量数据包;
s2:中心服务器进行负载均衡后将数据包拆分发送至分布式服务器集群;
s3:分布式服务器集群遍历数据包所有数据,并根据用户配置的数据聚合挖掘条件,分布式服务器集群中各个服务器节点分别判断数据是否重复,若不重复则保留,否则删除重复多余的数据;
s4:中心服务器合并去重后的数据;
s5:中心服务器遍历去重后的数据,并根据用户配置数据聚合挖掘条件,判断数据是否重复,若不重复则保留,否则删除重复多余的数据;
s6:系统输出聚合挖掘数据结果。
2.根据权利要求1所述一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,所述s2中负载均衡过程中心服务器是根据分布式服务器集群中各服务器节点的硬件配置性能和当前负载来分配任务量的。
3.根据权利要求1所述一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,所述s3中的匹配挖掘过程是根据用户配置条件对数据流量包中七元组信息的匹配。
4.根据权利要求1所述一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,所述s5中的中心服务器合并数据为异步操作,只要收到一个分布式节点中的结果返回便进行一次合并计算。
5.根据权利要求1所述一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,所述s5具体包括:用户配置数据聚合挖掘条件,系统遍历所有数据会话,判断回话是否为系统第一次遇到的会话,若是则保留该会话,否则舍去该会话。
6.根据权利要求1所述一种基于数据去重的分布式数据挖掘与统计方法,其特征在于,所述s5中用户配置数据挖掘条件为源地址与源端口的会话。
技术总结
本发明公开了一种基于数据去重的分布式数据挖掘与统计方法,分布式服务器集群遍历数据包所有数据,并根据用户配置的数据聚合挖掘条件,分布式服务器集群中各个服务器节点分别判断数据是否重复,若不重复则保留,否则删除重复多余的数据。本发明通过分布式处理原始数据,从而大大的降低数据包的数量级别,大大降低了用户配置复杂挖掘条件的难度,强化了数据挖掘的针对性,大幅提升了数据挖掘的效率。
技术研发人员:邓金祥;王炜;代先勇;谷峰;曾海刚;佘朝裕;刘洋
受保护的技术使用者:成都安思科技有限公司
技术研发日:2019.11.13
技术公布日:2020.04.24
- 还没有人留言评论。精彩留言会获得点赞!