基于潜在信息表征GAN的多模态MRI合成方法与流程
本发明属于图像处理技术领域,特别是涉及基于潜在信息表征gan的多模态mri合成方法。
背景技术:
磁共振成像(mri)作为一种无创性成像技术,已成为研究神经解剖学的主要成像方式。可以通过使用不同的脉冲序列和参数来产生不同的组织对比图像,从而形成同一解剖结构的不同模态。但是,在实践中,由于时间限制,会造成某些序列发生丢失;某些模态会受到随机噪声和非预期的图像伪影的影响,从而导致图像质量较差。上述因素使得对于同一被检测人员可用的对比图像的数量总是受到限制。因此,需要利用已经成功获得的其他模态合成丢失或损坏的模态;合成后的模态不仅可以替代丢失或损坏的模态,而且具有改善其他图像分析任务的潜在价值。
目前,有许多用于mri图像的单模态合成方法。需要对不同的病理特征采用其特定的方式,使用各种单模态合成方式提供的有效信息可以从理论上提高合成图像的质量并提高诊断的实用性,但是适用范围窄,实际运用效果差。而多模态合成的方向比使用单模态合成方法获得了更好的合成结果。目前对于多模态合成方法研究较少,且仅有的方式仍然存在很多缺点,会导致信息丢失和综合性能欠佳,造成合成图像不能够真实有效体现检测部位的形态。
作为最流行的深度学习技术之一,生成对抗网络(gan)已应用于图像合成领域。但是,现有方式在将gan扩展到多模式转换时,采用的方式是将不同的模态堆叠为输入,以单模态形式优化网络。由于不同的模式呈现出不同的物理状态,因此这些方法大大降低了从每种方式中提取信息的效率,导致合成结果不理想。
技术实现要素:
为了解决上述问题,本发明提出了基于潜在信息表征gan的多模态mri合成方法,能够灵活的接收多个输入模态,并将多输入模态进行合成,能够有效避免信息丢失,有效提高合成图像的保真度,获得真实体现检测部位的高品质图像;适用范围宽,计算效率高,且实际运用效果好。
为达到上述目的,本发明采用的技术方案是:基于潜在信息表征gan的多模态mri合成方法,包括步骤:
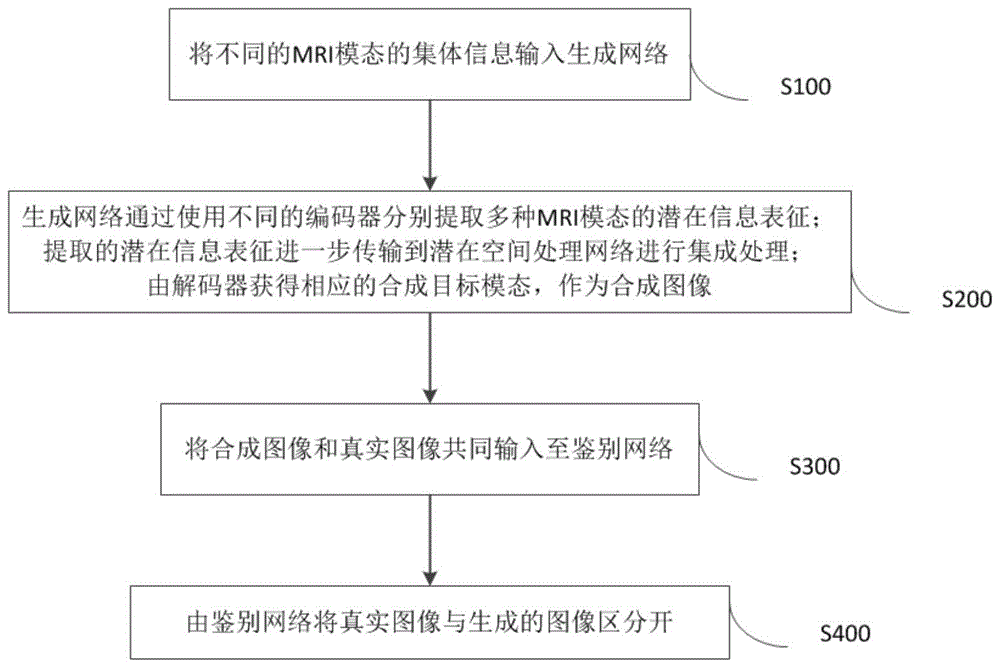
s100,将不同的mri模态的集体信息输入生成网络;
s200,生成网络通过使用不同的编码器分别提取多种mri模态的潜在信息表征;提取的潜在信息表征进一步传输到潜在空间处理网络进行集成处理;由解码器获得相应的合成目标模态,作为合成图像;
s300,将合成图像和真实图像共同输入至鉴别网络;
s400,由鉴别网络将真实图像与生成的图像区分开。
进一步的是,为了从多个模态中提取特定信息,在生成网络中包括有多个相互独立的编码器,每个编码器对应输入一个mri模态并提取该模态的潜在信息表征;编码器的数量取决于输入模态的数量。编码器在保留模态特定信息的潜在信息表征的同时保证了模态不变性;与使用相同的卷积核来提取不同模态的特征相比,使用特定的编码器分别提取每个模态的潜在表示可以提取更有效的多种模态的潜在信息表征进行合成。
进一步的是,所述编码器包括3个卷积块,每个卷积块结构相同,所述卷积块依次进行填充、归一化、激活和卷积处理;
在第一个卷积块中采用3×3的零填充,进行填充;在其余2个卷积块中应用1×1的零填充,进行填充;
在所述归一化处理过程中对数据进行实例归一化处理,即对单个输入图像的全局信息进行归一化调整;此方式能够有效消除由于混洗导致的平均值归一化和批量归一化的标准偏差,并减少了噪声的引入;所述激活函数采用leakyrelu激活函数,使网络更易于训练;将所述卷积层的步幅大小设置为2,以将特征图的尺寸减半,这样的处理方式不仅可以压缩图像大小,还可以减少最大池化层导致的详细信息丢失。
进一步的是,在所述生成网络中,将编码器所获得的潜在信息表征表示为lr(·)=e*(·|θ);
其中,e*(·|θ)为具有可学习参数θ的编码器函数;以独立地获取输入模式下的潜在信息表征。
进一步的是,所述潜在空间处理网络通过残差网络将每个编码器生成的潜在信息表征集成到单个潜在信息表征中:首先,直接连接不同模态下的潜在信息表征;然后,利用残差块的特性,通过特征映射的方式整合所述潜在信息表征,构成合成图像的潜在信息表征;借助残差网络,能够在不丢失信息的情况下成功地在各个卷积层中传输此类潜在表示,并最终完成多个潜在表示的融合;能够实现灵活地接收多种输入模态并保留其所有潜在信息表征;
所述残差块包括四个残差网络,每个所述残差网络包括镜像填充、批量归一化、leakyrelu激活和卷积处理。
进一步的是,所述合成图像的潜在信息表征,表示为:
其中,r*(·|ψ)为潜在空间处理中具有可学习参数ψ的残差集成函数;lr(t1)为t1输入模态的潜在信息表征,lr(t2)为t2输入模态的潜在信息表征,n为输入模态的个数,flair为目标模态。
进一步的是,将所述合成图像的潜在信息表征通过解码器进行解码,获得相应的合成目标模态作为合成图像;
解码器采用合成的多通道潜在信息表征作为输入,并输出所需的单通道目标模态图像作为合成图像;在所述解码器中首先使用两个连续转置卷积依次恢复图像的尺寸大小,然后通过两个卷积块获得相匹配的输出,最后,通过1×1卷积层转换为单通道的输出图像;其中两个卷积块将填充大小设置为2且卷积核大小设置为5。从而解决了多通道特性下输入输出通道大小不匹配问题;连续的转置卷积层可以稳定地集成潜在表示并完善目标模态的结构特征。
进一步的是,将所述合成图像的潜在信息表征通过解码器进行解码,获得相应的合目标模态作为合成图像;
在解码器中根据合成图像的潜在信息表征通过解码获得合成flair目标模态,表示为:
其中,d*(·|η)为具有可学习参数η的解码器函数。
进一步的是,设定所述鉴别网络的输入大小与生成网络的合成图像相同;所述鉴别网络包括5个卷积层,前四个卷积层的步长均为2且采用都4×4卷积核;最后一个卷积层包含sigmoid激活函数,以确定输入是真实图像还是合成图像。
进一步的是,在所述鉴别网络中将真实图像与生成的图像区分开,通过目标函数进行区分,所述目标函数为:
其中,鉴别网络中将真实图像与生成的图像进行区别,表示为:
其中,x1为t1输入模态,x2为t2输入模态,y为真实的目标模态;λ1和λ2为权重因子;上式中d是鉴别网络,g是生成网络,e是输入输出的期望值,
采用正则化度量标准并使用l1反馈生成器,选择l1损失以减少图像的模糊度,其表示如下:
为了处理l1损失函数固有的模糊预测,将嵌入图像生成网络训练中的梯度差损失函数:
其中
本发明通过将l1反馈生成器损失和图像梯度差损失(gdl)共同作为优化lr-cgan模型的目标函数,以确保合成图像不会严重偏离真实图像。
采用本技术方案的有益效果:
本发明利用来自不同mri模态的集体信息,由n个端到一个端的多对一多模态mri合成网络(称为lr-cgan模型)包含了生成网络和鉴别网络。所提出的多模态图像合成网络是通过基于gan模型从多个mri模态中提取潜在信息表征(lr)来执行的;它的生成网络使用n个编码器独立提取n种不同模式的固有潜在表征;然后通过采用残差结构将潜在表征集成到潜在空间处理网络中,利用解码器生成目标模态;最后,使用鉴别网络来区分真实图像和合成图像。能够灵活的接收多个输入模态,并将多输入模态进行合成,能够有效避免信息丢失,有效提高合成图像的保真度,获得真实体现检测部位的高品质图像。适用范围宽,且实际运用效果好。
在本发明中通过gan网络的添加使得能够呈现合成图像的高频信息,保证合成图像的真实完整。本发明从多种不同mri模态中生成高质量的合成图像,能够提高gan在多模态合成时的效率,提高合成结果的准确和真实性,合成图像能够真实有效体现检测部位的形态。
本发明无需使用最大化或平均化来自不同模态的潜在表示,而是直接将它们连接起来,并通过残差网络通过潜在空间处理对其进行融合,从而有效防止信息丢失,提高图像的保真度。
附图说明
图1为本发明的基于潜在信息表征gan的多模态mri合成方法流程示意图;
图2为本发明的实施例中lr-cgan模型的结构示意图;
图3为本发明的实施例中生成网络的结构示意图;
图4为本发明的实施例中生成t1c模态的多模式输入模型与单模式输入模型的合成图像结果对比图;
图5为本发明的实施例中生成flair模态的多模式输入模型与单模式输入模型的合成图像结果对比图;
图6为本发明的实施例中验证模型中关键组成部分的合成图像结果对比图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
在本实施例中,参见图1-图3所示,本发明提出了基于潜在信息表征gan的多模态mri合成方法,包括步骤:
s100,将不同的mri模态的集体信息输入生成网络;
s200,生成网络通过使用不同的编码器分别提取多种mri模态的潜在信息表征;提取的潜在信息表征进一步传输到潜在空间处理网络进行集成处理;由解码器获得相应的合成目标模态,作为合成图像;
s300,将合成图像和真实图像共同输入至鉴别网络;
s400,由鉴别网络将真实图像与生成的图像区分开。
作为上述实施例的优化方案,如图2和图3所示,为了从多个模态中提取特定信息,在生成网络中包括有多个相互独立的编码器,每个编码器对应输入一个mri模态并提取该模态的潜在信息表征;编码器的数量取决于输入模态的数量。编码器在保留模态特定信息的潜在信息表征的同时保证了模态不变性;与使用相同的卷积核来提取不同模态的特征相比,使用特定的编码器分别提取每个模态的潜在表示可以提取更有效的多种模态的潜在信息表征进行合成。
所述编码器包括3个卷积块,每个卷积块结构相同,所述卷积块依次进行填充、归一化、激活和卷积处理;
在第一个卷积块中采用3×3的零填充,进行填充;在其余2个卷积块中应用1×1的零填充,进行填充;
在所述归一化处理过程中对数据进行实例归一化处理,即对单个输入图像的全局信息进行归一化调整;此方式能够有效消除由于混洗导致的平均值归一化和批量归一化的标准偏差,并减少了噪声的引入;所述激活函数采用leakyrelu激活函数,使网络更易于训练;将所述卷积层的步幅大小设置为2,以将特征图的尺寸减半,这样的处理方式不仅可以压缩图像大小,还可以减少最大池化层导致的详细信息丢失。
在所述生成网络中,将编码器所获得的潜在信息表征表示为lr(·)=e*(·|θ);
其中,e*(·|θ)为具有可学习参数θ的编码器函数;以独立地获取输入模式下的潜在信息表征。
作为上述实施例的优化方案,如图2和图3所示,所述潜在空间处理网络通过残差网络将每个编码器生成的潜在信息表征集成到单个潜在信息表征中:首先,直接连接不同模态下的潜在信息表征;然后,利用残差块的特性,通过特征映射的方式整合所述潜在信息表征,构成合成图像的潜在信息表征;借助残差网络,能够在不丢失信息的情况下成功地在各个卷积层中传输此类潜在表示,并最终完成多个潜在表示的融合;能够实现灵活地接收多种输入模态并保留其所有潜在信息表征;
所述残差块包括四个残差网络,每个所述残差网络包括镜像填充、批量归一化、leakyrelu激活和卷积处理。
所述合成图像的潜在信息表征,表示为:
其中,r*(·|ψ)为潜在空间处理中具有可学习参数ψ的残差集成函数;lr(t1)为t1输入模态的潜在信息表征,lr(t2)为t2输入模态的潜在信息表征,n为输入模态的个数,flair为目标模态。
将所述合成图像的潜在信息表征通过解码器进行解码,获得相应的合成目标模态作为合成图像;
解码器采用合成的多通道潜在信息表征作为输入,并输出所需的单通道目标模态图像作为合成图像;在所述解码器中首先使用两个连续转置卷积依次恢复图像的尺寸大小,然后通过两个卷积块获得相匹配的输出,最后,通过1×1卷积层转换为单通道的输出图像;其中两个卷积块将填充大小设置为2且卷积核大小设置为5。从而解决了多通道特性下输入输出通道大小不匹配问题;连续的转置卷积层可以稳定地集成潜在表示并完善目标模态的结构特征。
将所述合成图像的潜在信息表征通过解码器进行解码,获得相应的合目标模态作为合成图像;
在解码器中根据合成图像的潜在信息表征通过解码获得合成flair目标模态,表示为:
其中,d*(·|η)为具有可学习参数η的解码器函数。
作为上述实施例的优化方案,如图2和图3所示,设定所述鉴别网络的输入大小与生成网络的合成图像相同;所述鉴别网络包括5个卷积层,前四个卷积层的步长均为2且采用都4×4卷积核;最后一个卷积层包含sigmoid激活函数,以确定输入是真实图像还是合成图像。
在所述鉴别网络中将真实图像与生成的图像区分开,通过目标函数进行区分,所述目标函数为:
其中,鉴别网络中将真实图像与生成的图像进行区别,表示为:
其中,x1为t1输入模态,x2为t2输入模态,y为真实的目标模态;λ1和λ2为权重因子;上式中d是鉴别网络,g是生成网络,e是输入输出的期望值,
采用正则化度量标准并使用l1反馈生成器,选择l1损失以减少图像的模糊度,其表示如下:
为了处理l1损失函数固有的模糊预测,将嵌入图像生成网络训练中的梯度差损失函数:
其中
本发明通过将l1反馈生成器损失和图像梯度差损失(gdl)共同作为优化本发明提出lr-cgan模型的目标函数,以确保合成图像不会严重偏离真实图像。
为了评估多模式输入模型与单模式输入模型相比的影响,并证明我们的模型可以灵活地接收多个输入,我们通过使用不同的模式输入来比较合成图像。具体来说,我们分别使用t2,t1+t2,t1+t2+flair作为生成t1c模态的输入,并使用t2,t1+t2,t1+t2+t1c作为生成flair模态的输入。表1、图4和图5分别定量和定性比较了实验结果,验证本发明所提出的合成方法。
表1中表示了所提出网络模型在不同输入下图像合成的性能:
表1
首先,观察到t1c模态的综合结果。如表1所示,由t1+t2+flair合成的t1c的平均psnr高于仅由t1+t2和t2合成的psnr。与使用单一模式的t2相比,采用两种模式(t1+t2)可获得更好的结果,psrn从27.73改善到29.36。这是因为t1模态包含丰富的解剖结构信息,可以更好地合成t1c模态。当将flair模态(t1+t2+flair)合并时,该模型会进一步产生改进的结果,psnr从29.36增加到30.77。表1中的nrmse和ssim值表明相同的结论。可视化结果如图4所示,由三种模态产生的合成图像提供了最佳的图像质量,并同时保留了图像对比度和详细的组织(如箭头所示)。此外,如果仅使用t2方式进行合成,则方框中的病变将大大丢失;尽管通过额外使用t1可以略微改善合成图像的质量,但仍比采用三种模态进行合成的图像质量差,三模态输入模型的差异最小。
然后,分析了flair模态的综合结果。为了进行定量比较,如表1所示,三模态输入模型的合成图像实现了最高的psnr和ssim,以及最低的nrmse。可视化结果如图5所示,,依次为使用t2,t1+t2,t1+t2+t1c作为生成flair模态的输入下的合成结果图,无论从对比度还是图像纹理来看,三模态输入模型的综合结果都显着改善了flair图像的细节(如箭头所示),与真实的flair图像极为相似,三模态输入模型的合成图像与真实图像之间的差异显然最小。
根据以上定性和定量结果,我们的模型不仅可以灵活地接收各种输入,而且可以融合所有输入信息以合成比单模态模型更高质量的图像。
为了研究该方法的关键组成部分的贡献,我们使用t1+t2作为输入来生成flair,以评估三个关键组成部分:对抗网络(gan),图像梯度差损失(gdl)和潜在空间处理网络(lspn)。表2和图6分别定量和定性比较了实验结果,验证本发明所提出的合成方法。
表2
为了评估本发明提出的lr-cgan模型的对抗网络的贡献,我们将提出的模型与去除了鉴别器的模型进行了比较。在表2中显示了有关psnr,ssim和nrmse的详细定量比较。如观察到的那样,在具有对抗网络的模型中,尽管ssim略有降低,但psnr从28.01升高到28.23,nrmse从0.178降低到0.170。从这些定量结果中,我们可以清楚地看到对抗训练方法的使用有助于提高合成图像的质量。图像结果如图6所示,合成图像类似于真实图像,因为没有错误地添加任何额外的结构,但是图像损失了可见的高频信息,使整个图像缺乏精细的结构信息;没有对抗网络的模型的误差几乎均匀地大于完整提出的模型。换句话说,对抗网络系统地减少了误差并提供了精细的结构信息。
通过图像梯度差损失来收集图像的边缘信息并改善图像的清晰度。为了评估梯度差损失函数的效果,将其从提出的模型中删除,并保留其他网络模块。定量结果总结在表2中。与没有gdl损失函数的模型相比,本发明模型的psnr从27.64增加到28.23,并且ssim和nrmse也呈现接近良好方向的趋势。这说明所提出的模型明显优于没有gdl损失函数的模型。图6中示出了所提出的方法的合成图像,从没有gdl损失函数的合成图像中,可以看出部分灰质不是很正确;无gdl损失的模型与完整模型之间的综合质量差异。因此,gdl损失的增加不仅纠正了模型的某些错误纹理合成,而且使图像的对比度更接近于真实情况。
为了评估模型的潜在空间处理网络(lspn)的效果,在提取潜在表示之后,删除潜在空间处理网络并直接对其进行解码以生成合成图像。结果列在表2中,从中我们可以看到lspn网络在所有三个指标中均显着提高了合成图像的质量,并且nrmse的改进明显。合成的结果在图6中,合成的图像呈现一定程度的对比度失真,即,图像总体上比真实图像明亮,而暗区比真实图像明显暗。因此,lspn是整合从不同模态中提取的特征的关键步骤,并且对所提出模型的性能做出了重要贡献。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!