基于Embedding技术的无监督关键词提取方法与流程
本发明涉及文本处理算法领域,更具体地,涉及一种基于embedding技术的无监督关键词提取方法。
背景技术:
随着文本数据(如学术论文、web网页、社交推文、热点新闻)的快速成长,对文本数据的分析和挖掘成为当前备受关注的重要研究领域。其中,如何从文本文档中提取反映文档主题的关键词(keyphrases,包括单词和短语)一直以来都是自然语言处理领域亟待解决的关键基础问题和研究热点,其研究成果可广泛用于文档检索、文档摘要、文本分类、话题检测、意图识别等具体应用领域。
无监督关键词提取方法中,基于图的关键词提取方法是目前最有效、被广泛研究的一类无监督提取方法。因为该类方法考虑了文档中词与词之间的关联信息(如共现关系、语义相似度)且可以融合单词的特性(如主题特性、位置特性等),因此取得了较好的提取效果,通常优于其他无监督方法,且在一些情况接近有监督的方法。从2004年最初提出的textrank方法至2017年发表于nlp领域顶会acl的saliencerank,十几年间研究者相继提出了诸多基于图的无监督算法,彼此之间不断借鉴改进。
textrank算法主要基于pagerank算法框架,该算法的原理包括“重要的单词往往和很多单词有关联”、“和重要的单词有关联的单词往往很重要”两点。算法具体先对文档进行切词处理和词性标注,得到单词集合。然后利用固定大小的窗口在文章中进行滑动,得到单词之间的共现关系,从而构建该文档对应的单词拓扑图。其中,图节点为各个单词,单词间的共现次数做为边权,即两个单词在同一个窗口内出现的次数。最后利用pagerank算法对图中的每个单词节点迭代计算分数,利用每个单词的最终评分即可筛选出文档的关键词。
关键词应当反应文章的主题,为此,清华大学的刘知远首次将lda主题模型融入textrank算法当中,提出了topicalpagerank(tpr)算法。该算法的主要原理为每个隐含主题下的单词,运行一次带主题偏好的pagerank算法,每个主题内的textrank算法都会给予那些主题关联度高的单词更大的分数。
2014年的wordattractionrank首次将word2vec词嵌入技术应用到无监督关键词提取领域,利用单词频率的dice系数和词向量的欧式距离定义了单词之间的关联性,作为单词拓扑图的边权。
2017年acl上发表的saliencerank是对topicalpagerank算法的改进,saliencerank(sr)算法将lda估计出得k个潜在主题组合成一个词的度量标准,叫做wordsalience,并将每个单词的wordsalience分数作为pagerank的重启概率以让算法更偏好于主题特异性高的单词,但是该算法仍然用单词的共现次数作为图的边权。
基于图结构的无监督关键词提取方法,绝大部分只是考虑了单一的词关联特征,比如textrank、tpr、sr算法都只使用了共现次数作为边权。然而单词之间关联特征往往是多方面的,如语义相似度、主题相似度、共现关系、句法依存关系等。即使两个单词不存在共现关系的时候,它们之间往往还会存在语义强相关的情况,或者主题强相关的情况等。因此考虑单一的关联特征,或者考虑较少的关联特征,会损失很多有用的语义信息,无法进一步提高算法的精度。
综合考虑单词的多个关联特征,并不是简单的加权求和,这样做往往效果并不好,或者适用性过低。它的难度在于如何将多种特征进行低维的向量化表示。原始的向量化表示往往是基于统计手法。这样做的缺点就是向量稀疏维度过大,运算时间过长,内存占用多大,计算关联性并不准确等。随着嵌入(embedding)技术的发展,利用无监督的神经网络算法训练得到单词的分布式向量表示成为主流。利用不同的词嵌入(embedding)技术,如图卷积词嵌入、共现拓扑图node2vec、主题词嵌入,最后拼接成混合词向量,可以很好地表征单词的语义、句法、共现关联以及主题特征。
对比目前主流的无监督关键词提取方法大多只使用共现关系或者语义相似度特征作为图的边权,本发明不仅考虑了共现关系和语义相似度,还考虑了句法依存关系和主题嵌入技术(可解决一词多义现象),使得关键词提取的效果大幅度提升。
技术实现要素:
本发明提供一种关键词提取的精度较高的基于embedding技术的无监督关键词提取方法。
为了达到上述技术效果,本发明的技术方案如下:
一种基于embedding技术的无监督关键词提取方法,包括以下步骤:
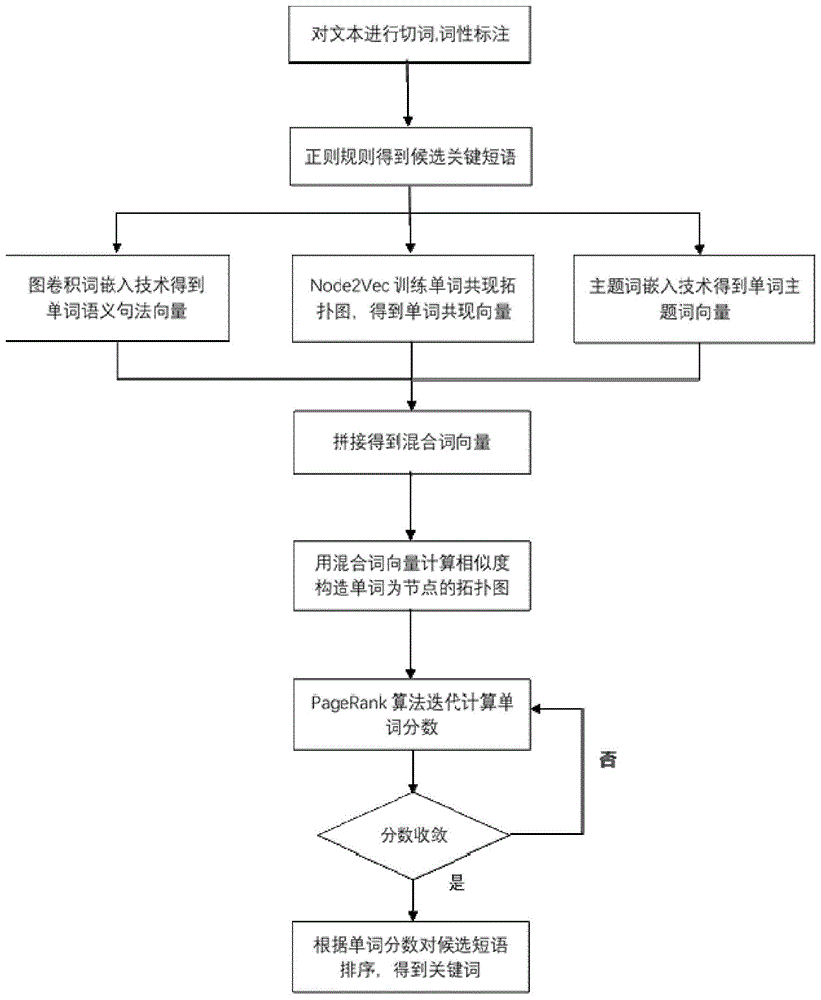
s1:对文档进行切词和词性标注,得到一个单词集合w;
s2:利用词性标注和“形容词+名词”模式得到一系列候选短语;
s3:利用无监督图卷积词嵌入技术得到集合w中每个单词的句法兼语义词向量gi;
s4:以w集合中单词的共现关系构造单词的共现拓扑图,使用node2vec技术训练得到单词的共现特征向量ni;
s5:利用主题词嵌入技术得到集合w中每个单词的主题词向量ti;
s6:将w集合中单词的三种向量进行拼接得到混合词向量vi=[gi,ni,ti],利用混合词向量得到单词之间的余弦相似度,以单词为节点,相似度作为边权构造单词的拓扑图。利用pagerank算法迭代单词的分数;
s7:根据单词的分数间接对候选短语排序,从而得到关键词。
进一步地,所述步骤s3的具体过程是:
s31:以句子为单位,构造每个句子的句法依存树;
s32:利用图卷积神经网络和句法依存树中单词的邻居关系去得到每个单词的隐层状态,即向量表示gi;
s33:利用每个单词的邻居集合去极大化该单词的条件概率,以此作为图卷积神经网络的损失函数,去训练得到单词的词向量。该向量具备单词的语义和句法依存特征。
进一步地,所述步骤s4的具体过程是:
s41:设置共现窗口,在文章中进行滑动,将两个单词出现在同一窗口的次数作为单词间的共现次数,以单词为节点,单词间的共现次数构造单词的共现拓扑图;
s42:利用node2vec技术,去训练单词的共现拓扑图,将单词节点向量化,每个单词的向量ni融入了该单词的共现关联特征和共现图的结构相似特征。
进一步地,所述步骤s5的具体过程是:
s51:利用lda主题模型得到文章中的k个潜在主题,每个单词分配一个主题;
s52:替每个单词和主题都保留不同的嵌入向量ui与ki,将单词和主题的向量进行拼接ti=[ui,ki],利用word2vec的原理去训练拼接后的向量ti;
s53:将训练好的单词向量和其对应的主题向量进行拼接,得到该单词的主题词向量ti,该向量融入了语义特征和主题特征。
进一步地,将步骤s3、s4和s5步骤中的三种词向量进行拼接,得到混合词向量vi=[gi,ni,ti],该向量兼具单词的语义特征、句法依存特征、共现关联特征以及主题特征。
与现有技术相比,本发明技术方案的有益效果是:
本发明方法利用图卷积词嵌入技术(gcnembedding)将单词的语义和句法依存关系向量化,利用node2vec技术训练单词共现关系拓扑图,有效地将单词的共现关系特征向量化,利用主题词嵌入(topicalwordembedding)技术将单词的主题特征和主题关联度向量化。将上述三种词向量进行拼接得到混合词向量,利用余弦相似度去构造单词拓扑图的边权。因为综合考虑了语义、句法、主题、共现多个特征,使得关键词提取效果得到进一步提升。此外,该方法使用了主题词嵌入技术,超参数定义较少,因此领域不敏感,适用性很高。无论是学术文章,新闻热点还是热门推文,均可高效地提取出关键词。
附图说明
图1为本发明方法流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种基于多种embedding技术地的更高效的无监督关键词提取方法,具体过程是:
s1:对文档数据进行预处理,包括切词,去除停用词,词性标注,去除标点符号和非法符号等,得到一个单词集合w。
s2:采用模式匹配结合正则规则来进行名词短语分块,具体利用词性标注和“形容词+名词”模式得到一系列候选关键短语。
s3:利用无监督图卷积词嵌入技术(gcnwordembedding)得到集合w中每个单词的词向量gi,该词限量兼具语义和句法特征。
s4:以w集合中单词的共现关系构造单词的共现拓扑图,使用node2vec技术训练得到单词的共现特征向量ni。
s5:利用主题词嵌入技术(topicalwordembedding)得到集合w中每个单词的主题词向量ti。
s6:将w集合中单词的三种向量进行拼接,利用混合词向量vi=[gi,ni,ti]计算单词之间的余弦相似度,以单词为节点,相似度作为边权构造单词的拓扑图。利用pagerank算法迭代单词的分数。
s7:根据单词的分数间接对候选短语排序,从而得到关键词。
步骤s3的具体过程是:
对于文章的每一个句子,利用斯坦福corenlp工具去提取句子中的句法依存关系,构造句法依存树(句法依存图)。这样就可以得到每个单词在句法依存图中的直接邻居集合。
对每个句法依存树使用k层图卷积神经网络进行训练,得到每个单词的向量表示,神经网络的前馈传播计算方式如下所示:
其中
该方法训练方式相当于word2vec模型中的cbow算法加上图卷积神经网络。
目标损失函数为:
即利用极大似然估计,最大化每个单词相对于其邻居集合的后验概率。
最终,将训练完成的每个单词的第k层隐层作为单词的词向量表示gi,该向量将会具备语义和句法特征。
步骤s4的具体过程是:
设置共现窗口,在文章中进行滑动,将两个单词出现在同一窗口的次数作为单词间的共现次数,以单词为节点,单词间的共现次数构造单词的共现拓扑图。
利用经典deepwalk算法改进的node2vec技术,训练出该拓扑图中的每个节点的向量化表示,具体对于每个节点,利用深度优先搜索和广度优先搜索两种随机游走的策略得到其近邻节点集合。
利用skipgram算法得到该节点的向量化表示,具体构造节点的embedding矩阵,该矩阵行数为节点个数,每一行权重代表该节点的向量。每个单词u的目标函数如下所示:
其中n(u)为该单词节点的近邻集合,f为节点的向量表示,即embedding矩阵对应的行向量。目标是极大化每个单词的近邻节点相对于该单词的后验概率。
最终得到每个单词节点的向量表示ni,具备了单词在这篇文章的共现关系特征和共现图的结构相似特征。
步骤s5的具体过程是:
利用lda主题模型得到文章中的k个潜在主题,每个单词分配一个主题。构造出单词和主题对。
为单词构造单词的embedding矩阵,为主题构造主题的embedding矩阵,即每个单词和每个主题都是可训练的低维向量。将单词和主题对的两个向量进行拼接,利用word2vec算法对拼接向量进行训练,不断更新两个embedding矩阵的权重。
最终得到每个单词的词向量ui,和每个主题的向量ki,将单词和其对应的主题向量进行拼接,就是该单词的主题词向量ti=[ui,ki]。该向量具备主题特征,同时可以表征一词多义现象。
步骤s6的具体过程是:
将s3、s4、s5每个步骤生成的单词词向量进行拼接,得到该单词的混合词向量,以单词为节点,混合词向量计算余弦相似度作为单词间的边权,构造出单词图。
对于构建好的单词图,初始化每个节点的分数为节点总数的倒数,通过如下pagerank算法公式去迭代每个单词的分数:
其中out(vj)是节点vj的出度,λ是权衡因子,一般取值0.85,r(vi)为节点vi的分数,wi,j是vj与vi通过混合词向量计算得到的余弦相似度。
经过多轮迭代收敛之后,每个单词的分数将不再改变,将每个候选词中的单词分数进行相加得到候选词的分数,取前几个最高得分的候选词就是需要提取的关键词。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!