广告投放的反作弊方法及系统与流程
本发明涉及广告投放领域,特别是一种广告投放的反作弊方法及系统。
背景技术:
进入移动互联网时代,移动广告给广告主带来丰厚流量收益的同时,广告作弊相关灰色产业链的潜在威胁也给业界人士敲响了警钟。毫无疑问,识别并对作弊的用户进行拦截对提高广告的质量和缩小与第三方监测公司的数据差异具有重要意义。
目前常见的作弊行为分为机器行为和人工行为,机器行为包括ip重复刷量、换不同ip重复刷量、机器智能作弊,流量劫持等。人工行为包括真水军作弊等。
目前反作弊的最佳策略在于让作弊成本剧增,使作弊行为的获利大幅度减少,从而尽量减小作弊行为在正常商业行为中的比例。目前业界主要通过一些强规则和运营经验来识别和拦截作弊用户,常用的规则包括设备号和ip排重,有效期内的曝光和点击频次,异常数据黑名单,sdk加密防护等等。
机器学习算法分成有监督的学习算法和无监督学习算法,线性回归(lr)属于有监督学习算法的一种,具有简单,计算速度快,可解释性强的特点,广泛运用于各个行业。
目前业界作反作弊具有以下几点不足:
1.过度依赖于业务规则,业务规则具有简单,可解释性强的特点,但是阈值设定都是根据经验,容易被破解。
2.机器学习算法lr还没有运用于广告反作弊中,机器学习算法的可解释性差,并且依赖于负样本。
3.用户的数据是实时变化的,依赖离线数据不能准确发现一些当天的新增作弊用户。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种广告投放的反作弊方法及系统,提高反作弊识别准确率,提高流量质量。
为解决上述技术问题,本发明所采用的技术方案是:一种广告投放的反作弊方法,包括以下步骤:
1)采集广告的曝光和点击数据,以及用户的曝光和点击数据;
2)对步骤1)的数据进行预处理,去除异常数据;
3)提取去除异常数据后的数据的特征,并进行特征抽取和特征转换,将特征向量化;
4)利用向量化后的特征标注广告请求中的负样本,按照正样本:负样本=k:1的比例生成样本数据,将所述样本数据按照m:n的比例随机分成训练集和测试集,将所述训练集输入到机器学习模型,根据测试集调节机器学习模型的超参数,得到预测模型;
5)将广告流量的实时数据和离线数据输入到所述预测模型,得到该广告流量是否为作弊流量的概率,若该概率值大于阈值,则判定为作弊流量,过滤广告并返回过滤标识;否则,直接返回广告。
步骤5)之前,还进行如下处理:
a)向广告投放引擎请求广告,广告投放引擎将服务端的日志数据写入消息中间件kafka;
b)处理kafka中的数据,统计实时数据;
c)配置反作弊的业务规则,若所述实时数据违反所述业务规则,则将请求的广告判定为作弊流量,将被访问设备的设备号和ip写入存储系统;
d)读取存储系统里的黑名单数据,过滤该请求的设备号和ip地址,如果设备号或者ip地址在黑名单中,则直接过滤广告,并返回过滤标识,其中,所述黑名单数据包括黑名单设备和ip地址;否则进入步骤5)。
相应地,本发明还提供了一种广告投放的反作弊系统,其包括离线系统、在线系统和预测单元;其中,所述离线系统包括:
数据采集单元,用于采集广告的曝光和点击数据,以及用户的曝光和点击数据;
预处理单元,用于对数据采集单元采集的数据进行预处理,去除异常数据,并提取去除异常数据后的数据的特征,进行特征抽取和特征转换,将特征向量化;
训练单元,用于利用向量化后的特征标注广告请求中的负样本,按照正样本:负样本=k:1的比例生成样本数据,将所述样本数据按照m:n的比例随机分成训练集和测试集,将所述训练集输入到机器学习模型,根据测试集调节机器学习模型的超参数,得到预测模型,并执行预测单元的操作;
所述在线系统包括:
计算引擎,处理kafka中的数据,统计实时数据;
规则引擎,配置反作弊的业务规则,若所述实时数据违反所述业务规则,则将请求的广告判定为作弊流量,将被访问设备的设备号和ip写入存储系统;
广告投放引擎:用于在接收到广告请求后,将服务端的日志数据写入消息中间件kafka;读取存储系统里的黑名单数据,过滤该请求的设备号和ip地址,如果设备号或者ip地址在黑名单中,则直接过滤广告,并返回过滤标识,其中,所述黑名单数据包括黑名单设备和ip地址;否则,执行预测单元的操作;
预测单元,用于将离线系统和在线系统的广告流量的实时数据和离线数据输入到所述预测模型,得到该广告流量是否为作弊流量的概率,若该概率值大于阈值,则判定为作弊流量,过滤广告并返回过滤标识;否则,直接返回广告。
所述业务规则包括:某一设备某个时间段被访问次数是否超过设定阈值;某一设备是否具备多个ip地址;某一设备同一时间段曝光次数是否大于设定阈值;某一设备同一时间段点击次数是否大于设定阈值。根据该规则判断请求的广告是否为作弊流量,简单易行,容易实现。
本发明中,实时数据可以是同一个设备访问接口的次数或者同一ip访问接口的次数。
本发明所述存储系统为redis,redis是一个高性能的key-value数据库。redis在部分场合可以对关系数据库起到很好的补充作用,使用方便。
与现有技术相比,本发明所具有的有益效果为:本发明合了业务规则和机器学习算法的优缺点,将两者结合起来,提高了广告投放的反作弊识别准确率,提高了流量质量,降低了广告主监测的数据和第三方广告平台监测的数据之间的差异。
附图说明
图1为本发明方法流程图。
具体实施方式
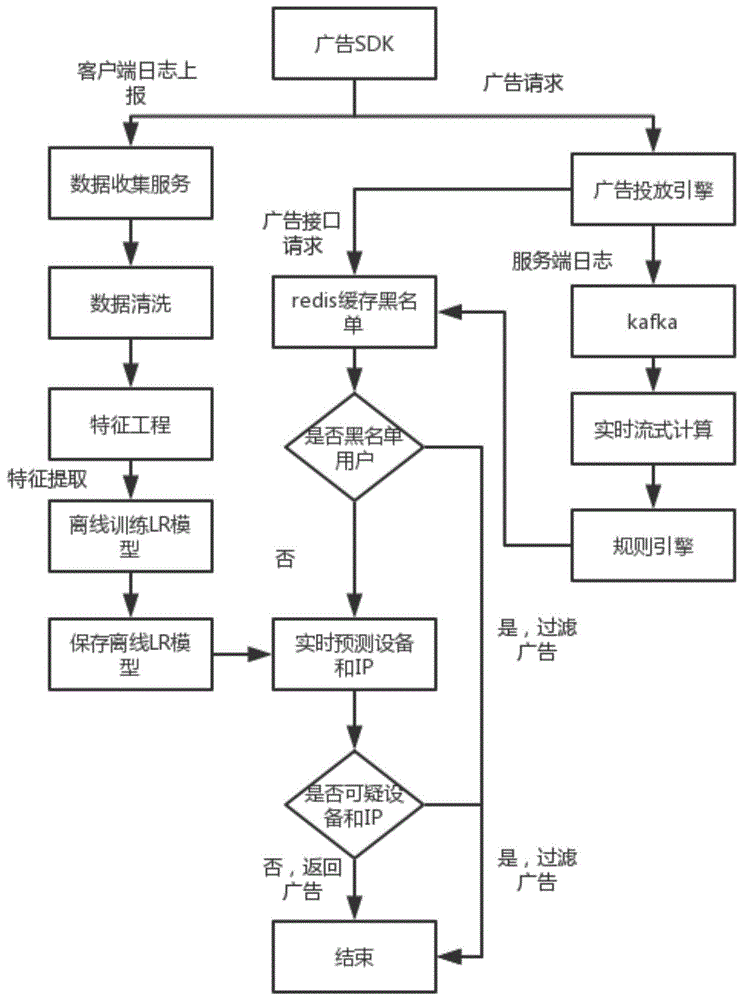
反作弊分成反作弊的识别和反作弊流量的拦截。反作弊识别分成业务规则识别和基于机器学习算法的识别两部分。基于机器学习算法的识别分成根据离线数据进行模型训练和基于实时接口数据进行实时预测两部分。
业务规则识别是根据一些经验,发现一些业务中常见的异常,比如高频访问,一个用户或者一个ip在单位时间内访问广告的次数超过正常范围,还有访问的ctr异常,某个用户某个时段访问某个广告的ctr超过正常范围等等,可以将业务规则应用规则引擎,制定成一条条规则,进行配置。
机器学习算法识别依赖于离线数据,可以根据最近一段时间的客户端上报的曝光和点击数据,以及服务端的请求数据进行清洗,特征提取,再结合平时发现的作弊用户(负样本)进行标注,训练得到一个用户(设备加ip)是异常用户的预测模型。即输入设备号和ip,输出该用户是否是异常用户的概率,根据概率值可以划分成正常用户,可疑用户和高危用户三类。对高危的用户流量直接进行拦截,直接不返回广告,可疑的流量纳入观察名单,正常的流量直接返回广告。通过业务规则发现一些明显的异常用户,然后再用机器学习算法发现一些多维度分析才能发现的异常用户,很好的结合了两者的优点,能够有效提高反作弊的识别准确率,降低误杀的风险。
本发明提供了一种实时广告投放系统中根据用户的数据控制是否返回广告的装置,该装置分为离线系统和在线系统两大部分。
离线系统的流程如下:
s1.离线系统中,广告sdk(软件开发工具包)通过数据收集服务上报广告的曝光和点击数据,数据收集服务存储用户的曝光,点击数据,具体包括用户的设备号,ip,机型,操作系统版本,访问时间,曝光的广告id等数据。
s2.通过数据清洗,去掉一些异常的数据(例如格式不对的异常值,乱码等数据)。
s3.通过数据挖掘或者标注数据,提取特征,如建立人的标签系统,进行特征抽取和特征转换,将特征向量化(数据标注主要包括人工打标签,比如某个设备号1小时内经常变换ip地址或者地域,我们就标注该设备的ip特征这一项为可疑设备,ip地址不频繁变换就标注为正常设备特征抽取主要包括规则提取,比如定义1天内某个设备的ip地址变化超过30次则为高频用户,10~30为正常用户,10次以下为低频用户;特征转换方法一般包括onehot编码,word2vec等方法,将普通的特征转换成向量)。
s4.标注作弊流量的负样本数据(作弊流量的负样本数据包括s3得到的向量化的特征和标注的分类,如对于某个作弊设备,负样本数据包括对作弊设备经s3提取得到的向量化的特征,和该作弊设备的分类)(通过数据挖掘和运营反馈得到),将正负样本按照k:1,随机生成数据(比如20%的负样本,80%的正样本,放到一起,然后打乱顺序,其中正样本即正常的广告请求,负样本即作弊广告请求),将数据按照m:n的比例随机分成训练集和测试集,将训练集输入sparkmlib的lr模型或者widedeep模型,根据测试集的auc来调节超参数,保存lr离线模型用于实时预测。
本发明中,k是常数,可根据实际使用设置,例如k可以设置为4;m:n可以为8:2(即将80%的数据作为训练集,20%的数据作为测试集),也可以为7:3(将70%的数据作为训练集,30%的数据作为测试集),m:n可以根据实际需求使用设置。
在线系统包括实时数据计算和实时预测两部分,在线系统的流程如下:
s1.广告sdk向广告投放引擎请求广告,投放引擎将服务端的日志数据写入消息中间件kafka。服务端数据包括访问的设备id,机型,ip,广告id等一些数据。
s2.实时流式计算引擎apacheflink或者sparkstreaming实时消费kafka,统计实时数据,如同一个设备访问接口的次数或者同一ip访问接口的次数,将数据输送至规则引擎。
s3.规则引擎配置了一些反作弊的业务规则,如同一个设备同一个时间段访问次数超过设定的阈值,则判定为作弊流量,将设备号和ip写入redis(一个开源的使用ansic语言编写、支持网络、可基于内存亦可持久化的日志型、key-value数据库,并提供多种语言的api。redis也可以定义为一个key-value存储系统)。
s4.广告投放引擎,读取redis里的黑名单数据进行过滤(分为设备号和ip),如果设备号或者ip在黑名单中,则直接过滤广告,返回过滤结果至广告客户端app(如果没有广告则告知客户端没有广告,客户端不展示广告,有广告,客户端展示广告数据)。否则根据用户数据进行实时预测。
s5.将用户的实时数据,结合用户的一些离线数据(用户行为数据,比如最近一段时间的活跃情况,在线时长,最近一次访问的时间),传输给缓存的lr模型,得到该流量(即s1中的广告sdk向广告投放引擎的请求)是否为作弊流量的概率,若该概率值大于阈值(一般是0.5,具体根据业务需求可以调节),则判定为作弊流量,过滤广告,返回过滤标识,否则,直接返回广告。
步骤s3中,业务规则包括:
1.同一个设备某个时间段访问次数超过某个阈值(可以根据实际需求设置);
2.同一个设备有多个(可以根据实际需求设置)ip地址;
3.同一个设备同一时间大量曝光(可以根据实际需求设置);
4.同一个设备同一时间大量点击(可以根据实际需求设置)。
- 还没有人留言评论。精彩留言会获得点赞!