一种基于灰色模糊聚类的数据处理方法及系统与流程
本发明涉及一种数据处理领域,尤其涉及一种基于灰色模糊聚类的数据处理方法及系统。
背景技术:
近年来随着技术的进步和政策方面的导向,数字政府的改革提出打破政府“数据孤岛”,优化营商环境需要各政府单位进行数据对接,日益严峻的安全问题要求各单位的数据能够有效共享,便民服务的优化升级需要各政府部门协作,实现群众的办事“零跑腿”,这些都促使各级政府积极推动跨部门政务数据共享。而跨部门政务数据共享是一个及其复杂的工程,受到众多影响因素的制约,需要通过深入和全面地分析各影响因素,进而分析其中的核心影响因素。然而传统的分析方法存在一定的弊端或者短板,因此,采用新的角度或方法进行跨部门政务数据共享影响因素的分析,成为诸多学者研究的焦点。
许多学者从理论及实证研究的角度,在政府跨部门数据共享方面做了有益的探索。1996年dawes首次针对政府跨部门间数据共享进行了系统性研究,在纽约州进行了实地调查,分析了173名政府人员对信息共享的利益和障碍的看法,从而提出基于组织和政策方面的政府跨部门间数据共享的理论框架,然而在20世纪90年代进行的调查却未能考虑促进跨部门间数据以电子方式共享的技术因素。landsberge和wolken在dawes提出的理论模型基础上,调研了五个州联邦和州政府官员,获取了两个案例的数据(环境报告和地理信息定位服务),提出了一个扩展的政府跨部门间数据共享模型,重点研究了技术基础设施、法律、管理和政策等因素的影响。以往的研究主要集中在从影响因素的概念模型入手,着重寻找对其有影响的因素,把揭示积极影响因素或阻碍数据共享因素作为研究重点,采用定性分析方法并提出相应的对策。并且学者对政务数据共享影响因素的分析,主要是采用问卷调查的方式,但是问卷调查评价结果具有模糊性,传统的研究方法不能反映各因素之间的模糊关系,如某一个影响因素,有部分评分者给与了很高的评分,另一部分评分者给了很低的评分,那么计算的平均分或总分并不能很好地反映评分者的实际态度,也不能较好反映各因素之间的强弱关系。
技术实现要素:
为了克服现有技术的不足,本发明提出一种基于灰色模糊聚类的数据处理方法及系统,即通过灰色关联分析识别因素之间的相关关系,采用模糊聚类的方法,实现关键因素的聚类。根据聚类的结果,构建态度曲线,对态度曲线不同因素进行分析,进而制定能有效推动政府数据共享的对策。
本发明的目的采用以下技术方案实现:
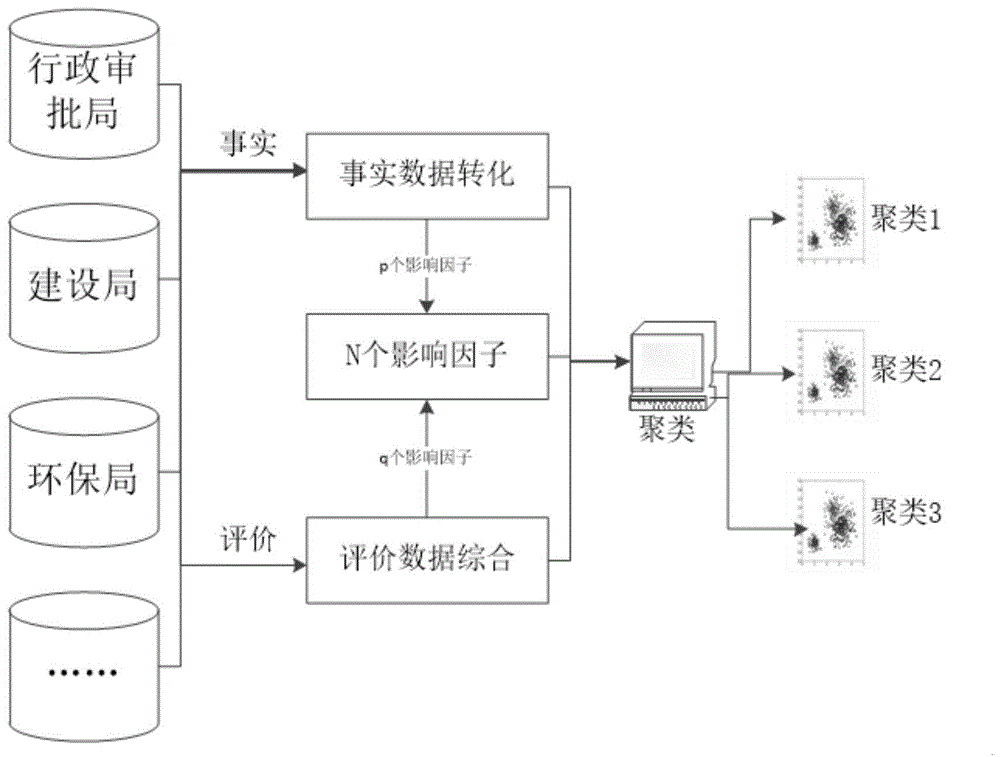
一种基于灰色模糊聚类的数据处理方法,数据采集:从各个政府部门采集数据,所属采集数据包含评价数据及事实数据;数据预处理:将所述评价数据进行综合,获得综合评价数据;所述事实数据转化为事实评价数据;所述综合评价数据及事实评价数据构成了n个评价因素,并生成评价向量xk=(xk1,xk2,…,xkj,…xkm),其中xkm为因素的影响程度,所述n个评价向量构成对象矩阵xn×m,标准化所述矩阵,计算关联系数及关联度;模糊聚类:根据所述关联度获得模糊相似矩阵r;根据传递闭包法获得传递包t(r),将t(r)中元素从大到小排序,λ∈[0,1]按照t(r)排序从大到小依次取值,得到不同λ水平的截集。
进一步地,所述数据预处理步骤,采用
进一步地,所述数据预处理步骤中,通过
进一步地,所述分辨率ρ取值为0.5。
进一步地,所述关联度
进一步地,所述模糊相似矩阵r=(rij)n×n,rij=1-|ri-rj|,(i,j=1,2,…n)。
进一步地,所述模糊相似矩阵r=(rij)n×n,rij=1-|ri-rj|,(i,j=1,2,…n)。
进一步地,所述传递包t(r)=rk,其中rkοrk=rk。
进一步地,所述因素的影响程度分为“1,2……f”f个等级,从1到f程度由弱变强,根据统计频次获得所述影响程度的值。
本发明还提供了一种基于灰色模糊聚类的数据处理系统,包含数据采集模块、数据预处理模块、模糊聚类模块及结果输出模块;所述数据采集模块从各个政府部门采集数据,所属采集数据包含评价数据及事实数据;所述数据预处理模块接收所述数据采集模块输出的评价数据及事实数据,将所述评价数据进行综合,获得综合评价数据;所述事实数据转化为事实评价数据;所述综合评价数据及事实评价数据构成了n个评价因素,并生成评价向量xk=(xk1,xk2,…,xkj,…xkm),其中xkm为因素的影响程度,所述n个评价向量构成对象矩阵xn×m,标准化所述矩阵,计算关联系数及关联度;所述模糊聚类模块根据所述关联度获得模糊相似矩阵r;根据传递闭包法获得传递包t(r),将t(r)中元素从大到小排序,λ∈[0,1]按照t(r)排序从大到小依次取值,得到不同λ水平的截集;所述结果输出模块根据不同λ水平的截集输出聚类。
本发明从各个部门分解出众多影响因数,并从众多影响因素中准确识别出关键因素,依据标准对各影响因素进行聚类达到定性分析的目的,然后通过对影响因素影响程度强弱的分析,识别出不同聚类的影响程度强弱,从而达到定量分析的目的。
附图说明
图1为本发明的跨部门数据影响因素的评价系统。
图2为本发明的政务数据共享影响因素灰色关联度综合评价图;
图3为本发明的政务数据共享影响因素动态聚类图;
图4为本发明的政务数据共享影响因素突出重点类的态度曲线;
图5为本发明的政务数据共享影响因素一般重点类的态度曲线。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述:
一种基于灰色模糊聚类的数据处理方法,数据采集、数据预处理、模糊聚类的过程。
数据采集过程是指从各个政府部门采集数据,所属采集数据包含评价数据及事实数据;评价数据是指各部门对某一事项的影响程度的评价,这些评价往往是无法根据客观的事实数据获得的,需要各个部门根据其工作进行总结或实际的需求进行主管评价而获得,例如:国家立法或者某项特定事项的推动、项目有民主的决策过程、项目合作参人与其他成员关系融洽等影响因数等。
事实数据是指各部门数据库及政府数据库中存在的业务数据,其评价过程是可以通过计算获得。如因素“具有足够的财政投入”可以根据部门请求的资金支持、实际的资金支持及业务最终完成的效果评价因素“具有足够的财政投入”的影响程度。又例如“关键项目参与人具有领先的技术能力”可根据其学历学位、论文等级及数量、最终实施的效果等量化指标对该因素的影响程度加以评价。
(一)数据预处理(灰色关联分析)
在数据预处理阶段,即能将所述评价数据进行综合,获得综合评价数据;所述事实数据转化为事实评价数据。所述综合评价数据及事实评价数据构成了n个评价因素。
根据评价因素可以确立研究对象矩阵。政务数据共享影响因素为n个,并且每个因素由m个等级评价,则待分类影响因素集为u={u1,u2,…,uk,…un}。其中,每个uk是一组因素评价向量,表示为xk=(xk1,xk2,…,xkj,…xkm),代表第k个因素的影响程度等级集,该等级集的计算方式参见本发明评价数据或事实数据的处理获得,即统计获得等级影响或通过客观数据计算方式获得等级影响。进而可得到研究对象矩阵:
数据标准化过程。为了减少不同数量级的数据进行比较时引起的“大数吞小数”问题,需要对原始数据进行数据规格化,将数据标准化至[0,1]区间。对矩阵x第j列采用标准化处理:
计算关联系数和关联度。参考序列和评价对象经数据标准化后,由(2)中第i个因素的j等级评价指标与参考序列间相应指标的关联系数。
其中,评价对象指标的最优参考序列为x0=(x01,x02,…,x0j,…,x0m),一般根据具体实际问题选取。ρ为分辨率,取值范围为(0,1),一般取0.5。
计算关联度时需要综合考虑研究对象中不同指标的影响程度,因此引入指标权重,即各影响因素影响等级的权重,可将每个因素的所有指标的关联系数综合为一个关联度,可得考虑权重后的关联度,关联度计算公式如(3)式。
其中,pj为第j个影响等级在评价对象中所占的权重;ri表示第i个影响因素与参考序列的加权关联度,该值越大,说明该序列和参考序列越相似,即该影响因素影响程度越强。
(二)模糊聚类
聚类分析就是根据事物间的不同特征、亲疏程度和相似性等关系,对它们进行客观分类的一种数学方法,其数学基础是数理统计中的多元分析。一般待聚类事物之间的界限较模糊,非常适合运用模糊聚类分析方法。政务数据共享的影响因素调研结果,同样具有模糊性的特点。因此聚类分析是采用相似度来衡量各因素间的亲疏程度,从而进行聚类。首先需要建立相似矩阵,其实质就是建立待评价因素集中两两对象之间的相似关系。本文采用关联度计算结果建立各影响因素间相似矩阵。
建立模糊相似矩阵。根据公式(3)计算得到的关联度建立各影响因素间的相似矩阵,利用欧式距离表示各影响因素间的差异,各影响因素相似系数见公式(4)所示,据此可得模糊相似矩阵为:r=(rij)n×n。
rij=1-|ri-rj|,(i,j=1,2,…n)(4)
其中,0≤rij≤1,rij越接近1表明两个因素相似性越高。
建立模糊等价矩阵。由(4)式求得的模糊相似矩阵一般仅具有自反性和对称性,而不具备传递性,需要采用传递闭包法将模糊相似矩阵改造为模糊等价矩阵,使矩阵具有传递性。传递闭包法是通过依次计算r2,r4,r8,…,找到k,使rkοrk=rk,r的传递闭包为t(r)=rk。
动态模糊聚类。将t(r)中元素从大到小排序,λ∈[0,1]按照t(r)排序从大到小依次取值,得到不同λ水平的截集,实现动态聚类。
根据本发明的灰色模糊聚类的数据处理方法,本发明构建了一种基于灰色模糊聚类的数据处理系统,包含数据采集模块、数据预处理模块、模糊聚类模块及结果输出模块;所述数据采集模块从各个政府部门采集数据,所属采集数据包含评价数据及事实数据;所述数据预处理模块接收所述数据采集模块输出的评价数据及事实数据,将所述评价数据进行综合,获得综合评价数据;所述事实数据转化为事实评价数据;所述综合评价数据及事实评价数据构成了n个评价因素,并生成评价向量xk=(xk1,xk2,…,xkj,…xkm),其中xkm为因素的影响程度,所述n个评价向量构成对象矩阵xn×m,标准化所述矩阵,计算关联系数及关联度;所述模糊聚类模块根据所述关联度获得模糊相似矩阵r;根据传递闭包法获得传递包t(r),将t(r)中元素从大到小排序,λ∈[0,1]按照t(r)排序从大到小依次取值,得到不同λ水平的截集;所述结果输出模块根据不同λ水平的截集输出聚类。本发明的系统能够完全应用本发明上文所述的所有方法。
当然,本发明的灰色模糊聚类的数据处理方法还可以放置于系统或存储器,即在系统或存储器中包含了执行代码,所述执行代码能够执行本发明的灰色模糊聚类的数据处理方法。
本发明还提供了灰色模糊聚类的数据处理方法及系统的一种具体实施例。
本发明采用了某一城市的政府各部门的业务数据及收集各部门反馈的评价数据,整理出六大类共计43个因素组成,每一个因素的影响程度分为“1,2,3,4,5,6,7”七个等级,从1到7程度由弱变强。其中评价数据能够在评价过程中就直接指定采用7个影响因数等级评价,事实数据根据计算出的数据影响值,并根据期望的范围,划分一定数据影响值范围属于的评价等级。
影响因素集为u={u1,u2,…,uk,…u43}。计算调查统计表中每个影响因素uk的评价向量xk=(xk1,xk2,xk3,xk4,xk5,xk6,xk7)。影响因素评价矩阵为x=[xij]43×7。根据计算得到的评价矩阵x进行数据标准化处理,可得影响因素的标准化矩阵,如表2所示。希望影响程度较大的等级5,6和7值越大越好,影响程度较小的等级1,2和3越小越好,而等级4属于过渡阶段,方便起见取中值。结合表1的标准化后数据构造参考序列为x0={0,0,0,0.5,1,1,1},再比较待评价因素与参考序列的关联关系,由公式(2)计算得到关联关系;经专家咨询并采用层次分析法确定评价等级的权重为p={0.01,0.02,0.03,0.04,0.25,0.30,0.35}。
表1政务数据共享的影响因素标准化后数据
由公式(3)计算得到关联度,部分结果见表2。依据关联度大小对其进行排序,值越大表明影响程度越高,可认定为关键因素。如图2所示。
表2关联系数和关联度(仅部分数据)
根据求得的关联度值公式(4)计算两两影响因素间的相似关系,构建模糊相似矩阵r,见表3所示。再采用传递闭包法将r改造为模糊等价矩阵t(r),见表4所示。
表3模糊相似矩阵
表4模糊等价矩阵
通过确定不同水平λ值,实现影响因素的动态聚类,动态聚类结果如图3所示。由图可知,选取不同λ值,将形成分类细化程度不同的聚类结果。λ值越大,分类越细。结合关联度计算以及图2,当λ=1时,43个因素各为一类,各因素影响强弱排序见图2,因素3影响程度最强,因素18影响程度最弱;当λ=0.9849时,可将影响因素分为三类:影响因素从强到弱依次为:第一类是{3,11,14,2,12},对应的影响因素是{d3,o2,o5,d2,o3},第二类是{32,1,13},对应的影响因素是{om3,d1,o4},第三类是:其他;当λ=0.9758时,如果将响因素分为两类:关键因素:{3,11,14,2,12},其他为非关键因素。同时,动态聚类结果与关联度分析结果一致,能较好反映各因素的影响程度,对于指导实践有重大的价值。
在政务数据共享的建设过程中,所有因素都发挥了一定的影响作用。将影响因素分为三类是为了更好地制定措施、政策,以推动政务数据共享的建设。根据灰色模糊聚类的结果,可将影响因素分为三类:影响因素从强到弱依次为:突出重点类{d3,o2,o5,d2,o3},一般重点类{om3,d1,o4},其他类。根据类中的影响因素所对应的评分,构建态度曲线,根据态度曲线提出相应的对策建议。如下图4-图5所示。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!