一种基于智能体学习的合作博弈集群视情维修方法与流程
所属技术领域
本发明提供了一种基于智能体学习的合作博弈装备集群视情维修方法,尤其使用了一种基于智能体学习的合作博弈方法,能够支持在多层次上的集群维修,属于可靠性工程领域。
背景技术:
面向任务可靠性的装备集群维修是一个多层次的维修执行过程,维修策略需要在多个层次上制定。在装备集群和设备层次上的可靠性模型是非常复杂的,从而对制定多层次的维修策略带来巨大挑战。所以基于装备状态的视情维修在装备集群编队的任务过程中被广泛应用,是维持和保证装备集群的任务成功所必要的手段。采用基于装备状态的视情维修可以在保证任务可靠性的同时降低维修损耗,节约维修成本。当前针对装备集群的视情维修通常只是在的特定组件、单元或模块进行,缺少面向装备集群进行多层次的维修,无法有效综合编队、装备、分系统(或组件)多层次状态提出更加合理的维修策略。装备集群的视情维修应该在满足任务可靠性的基础上,通过合理的建立维修模型,选择合适的维修策略,从而有效降低维修成本,减少资源消耗,提高维修效率。在此类问题中既需要考虑装备编队、装备对象、装备组件的状态以及任务可靠性,还需要综合考虑维修费用、维修时间、维修资源等约束,本质上这类问题属于多约束条件下的维修策略选择、制定以及执行问题。
本发明针对考虑装备集群多层次的视情维修的维修规划问题,根据智能体学习的思想提出了一种合作博弈的装备集群维修策略制定方法,可以为具有以上特征的集群维修问题提供支撑。
技术实现要素:
本发明旨在为装备的集群维修提供一种基于智能体学习的合作博弈方法,该方法能够有效针对装备集群的多层次维修的特征,从而为集群的视情维修提供技术支持。
本方法的目的是提出一种基于智能体学习的合作博弈集群视情维修方法,该方法主要包括以下几个步骤。
步骤一:制定初始的维修策略
在装备集群任务前根据任务要求以及装备对象的状态,选择任务执行对象,并制定初始的维修策略。
步骤二:判断初始维修策略下的收益
根据初始的维修策略,计算在该策略下的维修收益,如果能够满足任务要求和维修限制要求,则进入步骤八;如果没有达到则进入到合作博弈算法流程,进入步骤三。
步骤三:计算装备对象的学习信号
确定学习信号是为了有效减少维修策略的博弈空间,提高找到最优维修策略的可能性。每个装备作为博弈参与者都有四种状态,在学习过程中需要根据装备的四种状态来确定在第r轮学习中装备i的学习信号ai(r),根据状态可以得到3种学习信号。
步骤四:选择需要改变维修策略的博弈参与者
在下一轮博弈中,所有的装备对象都会有三种学习信号,根据学习信号做出相应的策略调整,必须要调整策略的装备记为ad1,ad2,...,adh,需要调整的博弈参与者的数量不能超过4。
步骤五:生成博弈者的策略减少空间
在下一轮的博弈时,装备i的初始维修策略空间ssi(r+1)包含的策略数量总是2n,为了提高博弈效率,需要在进入下一轮博弈之前根据博弈算法与学习信号,将不符合优化方向的策略剔除出初始策略空间并形成策略减少空间ssr'(r+1)。
步骤六:建立博弈矩阵
在第r+1轮博弈中如果从每个需要进行策略调整的adi的ssr'(r+1)中选择一个策略,则这些策略将构成编队层次的维修策略。如果ssr'(r+1)的策略数量是ni,则博弈矩阵中的元素数量为
步骤七:计算动作集合的收益并找到帕累托平衡解
在第r+1轮博弈中每个博弈者选择维修策略之后则构成一个动作集合a{k1,k2,...,kh},根据每个博弈者的收益可以计算得到当前动作集合下的收益
步骤八:根据退火算法判断是否结束循环
每一轮博弈后会得到一个帕累托平衡解,并输出方案收益。进一步判断是否满足退火收敛,如果满足则终止博弈流程并将此轮平衡解方案最为最优方案;如果没有满足则重新进入下一轮博弈。
附图说明
图1多层次装备维修策略制定过程示意
图2基于智能体学习的合作博弈基本流程
图3智能体学习博弈的基本过程原理
具体实施方式
为使本发明的技术方案、特征及优点得到更清楚的了解,以下结合附图,作详细说明。
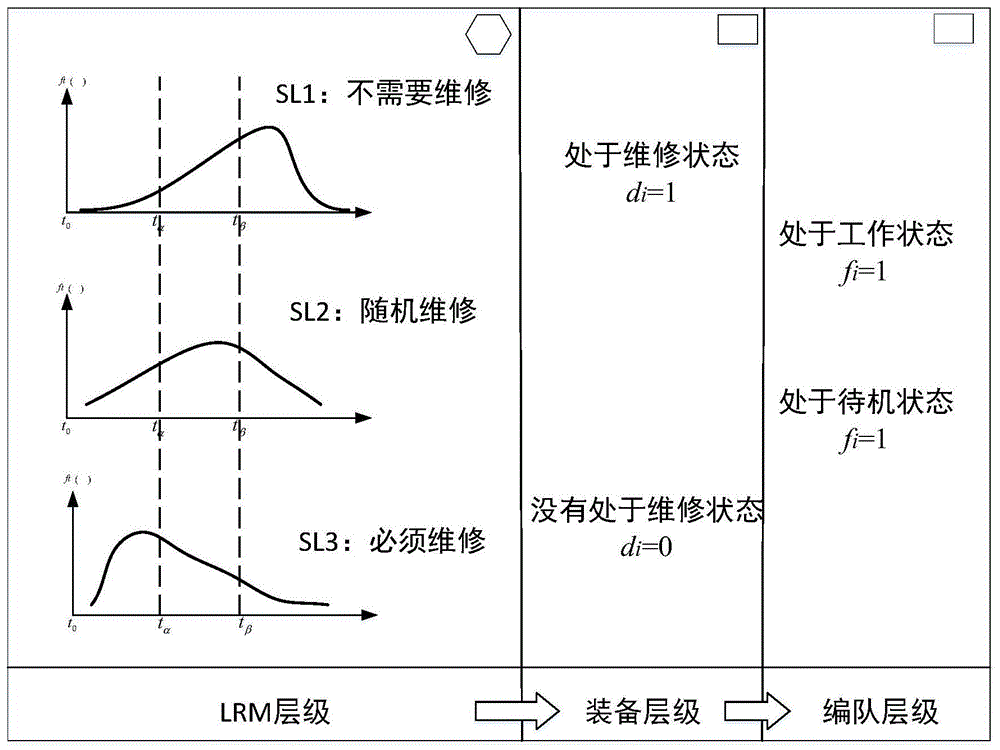
本发明提供了一种基于智能体学习的合作博弈装备集群视情维修方法,能够在如图1所示的多层次上的集群维修策略制定上提供支持。
本发明的整体架构,见图2所示,下面以实例进一步说明本发明的实质内容,但本发明的内容并不限于此。
步骤一:制定初始维修策略
在装备集群任务前根据任务要求以及装备对象的状态,选择任务执行对象,并制定初始的维修策略。如图1所示,装备的lrm的寿命状态可以分成三种:必须维修状态、随机维修状态、不需要维修状态。
装备i的第j个lrm的维修状态可以使用uij表示,uij=1表示该lrm是维修状态,uij=0表示该lrm没有处于维修状态。
例1,某关键lrm机群包含15架飞机,每个飞机包含6个关键lrm,每lrm的寿命服从正态分布n(μ,σ2),机群的任务可靠度的门限值rm为(1-10-9),每次任务出动8架飞机,每次任务时长2小时,任务出动选择状态较好的8架(2,3,4,8,10,12,13,15)飞机执行任务,但是任务可靠度为0.9999187621没有满足任务可靠度要求,所以制定了初始的维修方案:[0,0,0,1,0,0]t,[0,0,0,0,0,0]t,[0,0,0,0,0,0]t,[0,0,0,1,0,0]t,[0,1,0,0,0,0]t,[0,1,0,0,0,0]t,[0,0,0,0,0,1]t,[0,0,1,0,0,0]t。
步骤二:判断初始维修策略下的收益
根据初始的维修策略,计算在该策略下的维修收益,如果能够满足任务要求和维修限制要求,则进入步骤九;如果没有达到则进入到合作博弈算法流程,进入步骤三。
例2,接例1。当根据初始的维修策进行维修后,经过仿真计算可以得到维修后的任务可靠度rf为0.9999792129,花费11400,虽然任务可靠度提升但是仍然没有满足任务可靠度要求,所以需要进入到和合作博弈环节寻找优化解。
步骤三:计算装备对象的学习信号
确定学习信号是为了有效减少维修策略的博弈空间,提高找到最优维修策略的可能性。每个装备作为博弈参与者都有四种状态,在学习过程中需要根据装备的四种状态来确定在第r轮学习中装备i的学习信号ai(r),根据状态可以得到3种学习信号。
根据学习信号可以减少在博弈过程中的选择策略的数量,在本算法中装备i的学习信号ai(r)的值分别是1,0,-1。当ai(r)=1时表示智能体的学习方向应该是向降低维修成本方向学习;当ai(r)=-1时表示智能体的学习方向应该是向提高和保证任务可靠性的学习;其余情况下ai(r)=0表示智能体保持当前的策略,基于智能体的学习基本过程如图3所示。
智能体的学习的方向应该根据维修策略后编队总收益和装备的状态进行调整。根据图装备的状态可以分成四种:不维修且待机状态,维修并待机状态,不维修并任务状态,维修并且任务状态。装备维修策略变化后,编队的总收益w>0,此时应该向提高w的方向进行学习;当w=0时,此时的学习的方向应该向保证编队任务可靠度的方向进行学习。
例3,接例2.当编队的任务可靠度没有达到任务可靠度的门限值时,此时w=0,智能体学习的方向应该向保证编队任务可靠度的方向进行学习,例如在调整维修策略时可以增加装备维修的分系统数量。
步骤四:选择需要改变维修策略的博弈参与者
在下一轮博弈中,所有的装备对象都会有三种学习信号,根据学习信号做出相应的策略调整,必须要调整策略的装备记为ad1,ad2,...,adh,需要调整的博弈参与者的数量不能超过4。
例4,接例2。根据机群15架飞机的状态,选择出状态较好的8架(2,3,4,8,10,12,13,15)飞机执行任务,在初始维修成策略下不能满足任务要求,在进入到博弈学习的环节中,可以选择2,4,8,12作为博弈参与者并记为ad2,ad4,ad8,ad10。
步骤五:生成博弈者的策略减少空间
在下一轮的博弈时,装备i的初始维修策略空间ssi(r+1)包含的策略数量总是2n,为了提高博弈效率,需要在进入下一轮博弈之前根据博弈算法与学习信号,将不符合优化方向的策略剔除出初始策略空间并形成策略减少空间ssr'(r+1)。
首先为了提高博弈效率,可以采用多次小博弈来减少ssi(r+1)。规定装备初始策略si(r)在每次变化中只调整一个元素,则ssi(r+1)中包含的策略数量减少为n+1,ssi(r+1)可以表示为:
ssi(r+1)=[si(r),si(r+1)1,si(r+1)2,...,si(r+1)k,...,si(r+1)n]
其中si(r+1)k表示在下一轮博弈中初始维修策略只调整第i个元素。
当选择在ssi(r+1)中维修策略si(r+1)k后,应该计算对应着的维修花费和风险,该策略下的花费和风险分别为:
其中
如果学习信号ai(r)=1,当δcik≤0时,si(r+1)k是可行性的策略;如果ai(r)=-1,当δrik≥0时,si(r+1)k是可行性的策略,装备i的装备策略减少空间ssr'(r+1)是由所有的可行性策略组成的。
例5,如果某装备的维修初始策略是si(r)是[0,0,0,1]t,则ssi(r+1)是{[0,0,0,1]t,[1,0,0,0]t,[0,1,0,0]t,[0,0,1,0]t,[0,0,0,0]t}。当ai(r)=1时,[1,0,0,0]t和0,0,1,0]t对应的δcik≤0;当ai(r)=-1时,[0,0,0,0]t对应的δrik≥0;此时这三个策略构成ssr'(r+1)。
步骤六:建立博弈矩阵
在第r+1轮博弈中如果从每个需要进行策略调整的adi的ssr'(r+1)中选择一个策略,则这些策略将构成编队层次的维修策略。如果ssr'(r+1)的策略数量是ni,则博弈矩阵中的元素数量为
例6,在某机群中包含5架飞机,其中两架飞机需要调整维修策略,剩下的保持原有的维修策略。需要调整的飞机ad1和ad2的策略减少空间分别是{sa,sb}和{sc,sd,se},剩下的3架飞机的维修策略是sx,sy和sz,则博弈矩阵中的元素数量为6,分别是{sa,sc,sx,sy,sz}、{sb,sc,sx,sy,sz}、{sa,sd,sx,sy,sz}、{sb,sd,sx,sy,sz}、{sa,se,sx,sy,sz}、{sb,se,sx,sy,sz}。
步骤七:计算动作集合的收益并找到帕累托平衡解
在第r+1轮博弈中每个博弈者选择维修策略之后则构成一个动作集合a{k1,k2,...,kh},根据每个博弈者的收益可以计算得到当前动作集合下的收益
装备i的收益可以计算为:
其中s是切换因子。当rf在第r+1轮博弈中大于rm,则s=1,否则为0。g是惩罚因子,当在第r轮博弈中维修策略满足可靠性要求但是在第r+1轮中不满足,此时g=-1,否则为0.
当在当作集合a{k1,k2,...,kh},根据每个博弈者的收益可以计算得到当前动作集合下的收益:
则帕累托平衡解可以表达为:
例7,接例1-4。经过博弈过程的仿真计算,选择出的最佳方案为:飞机出动的变成1,3,4,5,7,8,10,对应的维修策略分别是[0,0,0,1,0,0]t,[0,0,0,0,0,0]t,[0,0,0,0,0,0]t,[1,0,0,0,0,0]t,[0,0,0,1,0,0]t,[0,0,1,0,0,0]t,[0,0,0,1,0,0]t,[0,0,0,0,0,1]t。并且满足任务可靠性要求以及维修时间限制要求。
步骤八:根据退火算法判断是否结束循环
每一轮博弈后会得到一个帕累托平衡解,并输出方案收益。进一步判断是否满足退火收敛,如果满足则终止博弈流程并将此轮平衡解方案最为最优方案;如果没有满足则重新进入下一轮博弈。
根据退出博弈参数γ来决定是否退出合作博弈算法,否退出合作博弈算法,当γ<δ时(δ为一个足够小的正数),结束博弈。采用模拟退火的方式,令博弈的概率随时间降低。博弈参数可表示为
退火温度在算法中的表示为:
tck+1=λtck
其中λ是退火系数。
例8,接例1-4。设此时的δ是0.001,退火系数λ=0.7。根据仿真计算结果,当进行了22次博弈合作之后收益不再变化,经过连续退火8次操作可以得到最终的优化解,此时γ=0.000202小于0.001,满足收敛条件,退出合作博弈。
- 还没有人留言评论。精彩留言会获得点赞!