一种动作示范方法和系统与流程
本申请涉及机器学习技术领域,特别涉及一种动作示范方法和系统。
背景技术:
现代社会,人们越来越注重健康和运动。在屏幕前跟随教学视频学习瑜伽、舞蹈、健美操等,是一种简便的学习方式。但是,各种运动都有其相应的标准动作,如果人们在学习中不能很好地做到与教学视频中的标准动作一致,则无法得到有效的锻炼和提升。为此,需要借助于动作比对系统来帮助人们尽量接近标准动作。
现有的一种动作比对系统的主要原理是:首先,由学习者自主完成动作,然后,动作比对系统根据学习者的图像取得学习者的串流动作及多个身体节点,同时提供虚拟示范者(即:视频中的示范者)的串流动作及多个身体节点,在时间上将二者对齐,然后根据对比演算二者之间的关系数值产生对比结果,最后,将该数值以分数的方式反馈给学习者,或者根据学习者与示范者的关系数值的差距大小进行颜色标识或文本声音的提醒。
现有另一种系统是提供一个可视化的虚拟的游戏环境,将示范者的动作和学习者的动作同时投影到该游戏环境中,学习者可以在该环境中多方向查看自己的动作,包括与之对应的示范者的动作,从而可以让学习者通过观察,主观评价自己的动作是否规范。
上述现有技术的主要问题在于:
1.从示范者动作和学习者动作中提取特征进行数值比对(例如:可能是进行肢体关节角度对比等等),然后经过降噪等过程进行处理,最后将对比结果进行展示,这样的复杂计算过程会浪费一定的时间。
2.现有的对比结果一般通过数值结果、颜色标注或文字显示进行展示,或者将示范者和学习者投影到相同空间,由学习者自己主观对比评价,这些结果展示方式都不够直接,交互体验较差。
3.现有的对比提示方法无法使学习者实时获知练习的动作和节奏是否正确。学习者总是先自主做动作,之后才知道自己做的是否标准,这种输出结果的方式有延迟,不能使学习者及时地获知自身的动作或节奏是否规范,而且过于笼统,学习者无法确切地知道是哪个动作不规范,因而无法真正有效地帮助学习者纠正自身的动作。
技术实现要素:
本申请提供了一种动作示范方法和系统,以实时为学习者提供适应于学习者体型特征的示范动作。
本申请公开了一种动作示范方法,包括:
从示范视频中实时提取示范者的身体关键点,从学习者视频中实时提取学习者的身体关键点;
根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,得到重塑后的示范者身体关键点;
将所述重塑后的示范者身体关键点定位到学习者对应的身体关键点上,对所述重塑后的示范者身体关键点和学习者视频进行叠加显示。
较佳的,所述根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,具体包括:
根据学习者各相邻身体关键点之间的距离和对应的示范者各相邻身体关键点之间的距离,计算对应的各两个距离之间的比值;
计算所述各比值的均值或者加权平均值,将计算结果作为重塑比例;
按照所述重塑比例对示范者的身体关键点之间的距离进行伸长或缩短。
较佳的,计算所述加权平均值所需的各个比值的权值根据身体关键点的精确度,按照精确度越高,权值越高的方式确定;
或者,计算所述加权平均值所需的各个比值的权值根据提取所述身体关键点所采用的关键点提取算法的精确度确定,所采用的关键点提取算法的精确度越高,对应的身体关键点之间距离的比值的权值越高。
较佳的,所述将所述重塑后的示范者身体关键点定位到学习者对应的身体关键点上,具体包括:
选取处于示范者动作变化最小的身体部位的n个身体关键点,其中,n≥2;
计算示范者的所述n个身体关键点与学习者对应的n个身体关键点之间的距离的方差,在所述n个身体关键点相对位置不变的条件下,将所述方差最小的位置作为定位位置。
较佳的,所述对所述重塑后的示范者身体关键点和学习者视频进行叠加显示,具体包括:
在显示屏中弱化所述学习者的实时视频图像,并将所述重塑的示范者的身体关键点展示在学习者实时视频图像的上层。
较佳的,该方法还包括以下的至少一种:
为所述重塑的示范者的身体关键点填充人体轮廓;
根据学习者和示范者身体关键点的对比结果,以语音或者图示的方式提示学习者改进动作。
较佳的,所述从示范视频中实时提取示范者的身体关键点,具体包括:
如果所述示范视频中存在至少两个示范者,则通过目标检测算法检测出所述示范视频中的每一个示范者,选择所述至少两个示范者中处于最前排、最中间的示范者作为示范者,并针对所选择的示范者做身体关键点检测。
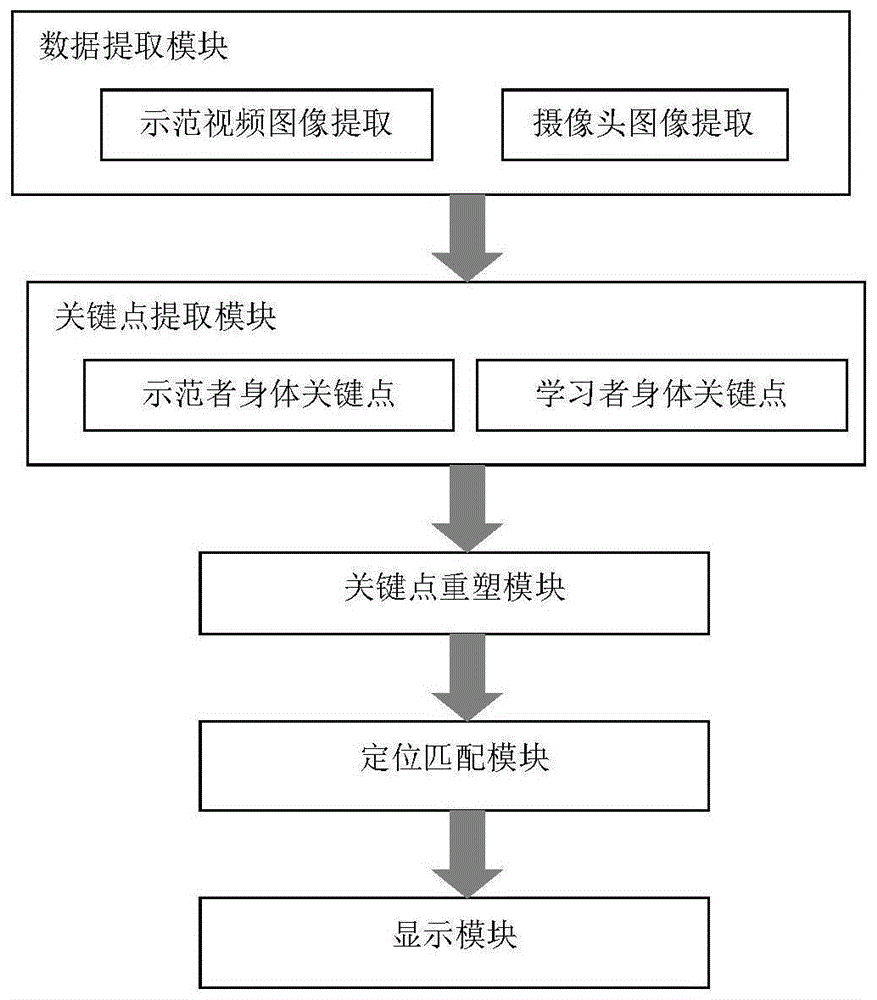
本申请还公开了一种动作示范系统,包括:数据提取模块、关键点提取模块、关键点重塑模块、定位匹配模块和显示模块;其中:
所述数据提取模块,用于提取示范者视频和学习者视频,并提供给所述关键点提取模块;
所述关键点提取模块,用于从所述示范视频中实时提取示范者的身体关键点,从所述学习者视频中实时提取学习者的身体关键点;
所述关键点重塑模块,用于根据所述学习者的身体关键点之间的关系对所述示范者的身体关键点进行重塑,得到重塑后的示范者身体关键点;
所述定位匹配模块,用于将所述重塑后的示范者身体关键点定位到学习者对应的身体关键点上;
所述显示模块,用于对所述重塑后的示范者身体关键点和学习者视频进行叠加显示。
较佳的,所述关键点重塑模块具体用于:
根据学习者各相邻身体关键点之间的距离和对应的示范者各相邻身体关键点之间的距离,计算对应的各两个距离之间的比值;
计算所述各比值的均值或者加权平均值,将计算结果作为重塑比例;
按照所述重塑比例对示范者的身体关键点之间的距离进行伸长或缩短。
较佳的,所述关键点重塑模块具体用于:
根据身体关键点的精确度,按照精确度越高,权值越高的方式确定计算所述加权平均值所需的各个比值的权值;
或者,根据提取所述身体关键点所采用的关键点提取算法的精确度,按照所采用的关键点提取算法的精确度越高,对应的身体关键点之间距离的比值的权值越高的方式确定计算所述加权平均值所需的各个比值的权值。
较佳的,所述定位匹配模块具体用于:
选取处于示范者动作变化最小的身体部位的n个身体关键点,其中,n≥2;
计算示范者的所述n个身体关键点与学习者对应的n个身体关键点之间的距离的方差,在所述n个身体关键点相对位置不变的条件下,将所述方差最小的位置作为定位位置。
较佳的,所述显示模块具体用于:
弱化显示所述学习者的实时视频图像,并将所述重塑的示范者的身体关键点展示在学习者实时视频图像的上层。
较佳的,所述显示模块还用于执行以下操作的至少一种:
为所述重塑的示范者的身体关键点填充人体轮廓;
根据学习者和示范者身体关键点的对比结果,以语音或者图示的方式提示学习者改进动作。
较佳的,所述关键点提取模块具体用于:
当所述示范视频中存在至少两个示范者时,通过目标检测算法检测出所述示范视频中的每一个示范者,选择所述至少两个示范者中处于最前排、最中间的示范者作为示范者,并针对所选择的示范者做身体关键点检测。
由上述技术方案可见,本申请通过提取示范者的身体关键点和学习者的身体关键点,并根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,能够从示范者的标准动作中训练出适合学习者体型特征的个性化的示范动作,并通过将个性化的示范动作定位至学习者对应的身体关键点上,再采取叠加显示的方式展示到摄像头捕捉到的学习者的实时视频影像上,能够让学习者在做动作时实时纠正自身的动作姿势以及节奏,从而避免了采用现有技术需要查看数值比对结果的繁琐和主观评价的不确定性。
此外,对于示范视频中存在多个示范者的场景,本申请采用自上而下的检测方法,首先通过目标检测算法检测出示范视频中的每一个示范者,然后,将示范视频中的多个示范者中处于最前排、最中间的示范者选作示范者,并针对该选出的单个示范者做身体关键点检测,并对该示范者采用本申请方案进行处理,从而解决了示范视频中有多个示范者时如何提取示范者身体关键点的问题。
附图说明
图1为本申请动作示范系统的组成结构示意图;
图2为本申请实施例中示范者与学习者的身体关键点提取效果图;
图3为本申请实施例中从示范视频的多人中检测出示范者的示意图;
图4为本申请实施例中关键点重塑比例计算过程示意图;
图5为本申请实施例中定位匹配过程示意图;
图6为本申请实施例中显示过程的处理示意图;
图7为本申请实施例中的显示效果图。
具体实施方式
为使本申请的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本申请作进一步详细说明。
为解决现有技术所存在的问题,本申请提出一种动作示范方法和系统,其主要原理为:通过实时提取示范视频中示范者的身体关键点,同时通过系统的前置摄像头实时捕获学习者视频,并从中提取学习者的身体关键点,然后按照学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,最后通过显示屏将重塑后的示范动作实时定位映射到学习者的视频影像上,能够实时为学习者提供适应于学习者体型特征的示范动作,从而让学习者能够实时跟随示范者做出相应的规范的动作。
本申请提供的动作示范系统的组成结构如图1所示,该系统可以实时提取视频示范者的身体关键点,同时系统前置摄像头可以捕获学习者影像,并提取学习者身体关键点,根据二者关键点匹配,示范者关键点可以对学习者关键点进行学习,按照学习者点位信息进行拉伸与缩放,训练出适合学习者位置与体型的私人示范者身体关键点,并且实时定位在学习者身上,让学习者实时跟着私人示范者做出动作,相当于示范者手把手教学。
根据图1,本申请动作示范系统主要包括以下5个组成部分:
1)数据提取模块:主要负责提取示范者视频和学习者视频,提供给关键点提取模块。
本申请的系统中需要具备视频播放器与摄像头装置,视频播放器可以播放学习者想要学习动作的视频,本申请称为“示范视频”;而摄像头用于拍摄设备前方学习者的影像(本申请称为“学习者视频”)并展示出来。这样,系统的显示模块中可以同时显示示范者和学习者的影像信息。
2)关键点提取模块:主要用于提取示范者的身体关键点和学习者的身体关键点。较佳的,所提取的身体关键点需要覆盖身体四肢主要关节部位。
目前的关键点提取技术有:利用kinect设备采集并获取深度图像,然后经过特定处理,将人体目标从环境中提取出来并进行平滑处理,再使用图像细化算法(如hilditch细化算法和zhang快速并行细化算法)实现人体关键点的提取。
此外,还有基于深度学习卷积神经网络(cnn)训练得到复杂的映射关系,从而提取更复杂的高阶特征等方法。当前随着深度学习技术的发展,关键点提取技术(亦可称为关键点检测技术)的效果不断提升,关键点提取技术已经开始广泛应用于计算机视觉的相关领域,这些关键点提取技术的效果在关键点提取领域已获得验证,本文不再赘述。
如果示范视频中包含多人,则采用自上而下的检测方法,首先通过目标检测算法将每一个人检测出来,然后将多人中最前排、最中间的人选作本发明的示范者,最后,在检测框的基础上针对所选出的示范者做人体骨骼关键点检测。
3)关键点重塑模块:根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,得到重塑后的示范者身体关键点,这些重塑后的身体关键点即可构成适合于学习者的个性化的标准示范动作。也就是说,本模块主要用于示范者身体关键点对学习者身体关键点进行学习,得出适合于学习者体型特征的用于对示范者的身体关键点进行重塑的重塑比例,然后按照该重塑比例对示范者的身体关键点进行重塑。
一种比较简单的计算重塑比例的方法为:根据学习者各相邻身体关键点之间的距离和对应的示范者各相邻身体关键点之间的距离,计算各对等的两个距离之间的比值,然后求各比值的均值,将该均值作为重塑比例。按照该重塑比例对示范者的身体关键点之间的距离进行伸缩,即可得到重塑后的示范者身体关键点。
除此之外,比例计算部分也可以基于上述计算得到的各个比值,通过计算各个比值的加权平均值的方式得到重塑比例。各个比值的权值则可以根据关键点的精确度高低进行确定,或者通过多次实验数据确定最优的权值,也可以根据关键点算法的精确度来调整,精确度越高的关键点之间距离的比值的权值越大,精确度越低的关键点之间距离的比值的权值越小。
4)定位匹配模块:用于将示范者的身体关键点数据定位至摄像头实时拍摄的学习者图像中。定位的具体方案可以是:选取动作中变化较小的部位,比如躯干部分,选取位于示范者躯干部分的若干个身体关键点进行定位,在保证这若干个身体关键点相对位置不变的情况下,使选出的身体关键点与学习者的对应身体关键点之间的距离的方差最小,则认为匹配成功。
5)显示模块:主要用于示范者重塑身体关键点数据和学习者视频的图形显示。具体而言:
首先,弱化显示屏中学习者自身的实时视频图像,然后,将重塑的示范者的身体关键点展示在学习者图像的上层。
考虑到如果仅仅显示重塑的示范者的身体关键点,则这种显示方式不够直接,为此,可以进一步为这些身体关键点填充人体轮廓,从而可以为学习者提供互动感更强的交互体验。此外,还可以根据学习者和示范者身体关键点的对比结果,以语音或图示的方式提示学习者哪个身体部位对比标准动作应该如何改进。
基于上述动作示范系统,本申请还提供了一种动作示范方法,该方法包括以下步骤:
首先,从示范视频中实时提取示范者的身体关键点,从学习者视频中实时提取学习者的身体关键点;
然后,根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,得到重塑后的示范者身体关键点;
最后,将所述重塑后的示范者身体关键点定位到学习者对应的身体关键点上,对所述重塑后的示范者身体关键点和学习者视频进行叠加显示。
上述方法中,所述根据学习者的身体关键点之间的关系对示范者的身体关键点进行重塑,具体包括:
根据学习者各相邻身体关键点之间的距离和对应的示范者各相邻身体关键点之间的距离,计算对应的各两个距离之间的比值;
计算所述各比值的均值或者加权平均值,将计算结果作为重塑比例;
按照所述重塑比例对示范者的身体关键点之间的距离进行伸长或缩短。
以上计算加权平均值的方法中涉及如何确定各个比值的权值,该权值可以根据身体关键点的精确度,按照精确度越高,权值越高的方式确定;也可以根据提取身体关键点所采用的关键点提取算法的精确度确定,所采用的关键点提取算法的精确度越高,对应的身体关键点之间距离的比值的权值越高。
本申请方法中,将重塑后的示范者身体关键点定位到学习者对应的身体关键点上,具体包括:
选取处于示范者动作变化最小的身体部位的n个身体关键点,其中,n≥2;
计算示范者的所述n个身体关键点与学习者对应的n个身体关键点之间的距离的方差,在所述n个身体关键点相对位置不变的条件下,将所述方差最小的位置作为定位位置。
本申请所述的对重塑后的示范者身体关键点和学习者视频进行叠加显示,具体包括:在显示屏中弱化所述学习者的实时视频图像,并将所述重塑的示范者的身体关键点展示在学习者实时视频图像的上层。
为了进一步提高交互体验的互动感,还可以为所述重塑的示范者的身体关键点填充人体轮廓。或者,进一步地,根据学习者和示范者身体关键点的对比结果,以语音或者图示的方式提示学习者改进动作。
本申请提供的方法中,当所述示范视频中存在至少两个示范者时,则通过目标检测算法检测出所述示范视频中的每一个示范者,选择所述至少两个示范者中处于最前排、最中间的示范者作为示范者,并针对所选择的示范者做身体关键点检测。
下面结合附图,通过一个具体实施例对本申请作进一步详细说明。本实施例的具体流程包括:
1.准备阶段:
学习者打开摄像头进行拍摄,设备的屏幕显示学习者图像,学习者根据屏幕显示调整好自己在摄像头前面的位置。同时,学习者打开想要学习的示范视频,准备在设备上播放。
2.关键点提取过程:
本实施例的系统学习示范视频(也可称为:教学视频),训练出示范者标准动作的身体关键点信息。由于每一套示范视频都是固定的,因此,为了避免重复计算,可以提前针对每一个示范视频提取其中的示范者身体关键点(也可称为:动作关键点)串流信息,并保存在视频数据中。对于学习者而言,当摄像头开始显示学习者的图像时,系统就可以开始提取学习者的身体关键点了。
本实施例提取16个关键点:左眼、右眼、嘴巴、脖子、左肩、右肩、左手肘、右手肘、左手腕、右手腕、左髋部、右髋部、左膝、右膝、左脚踝、右脚踝。示范者与学习者的身体关键点提取效果图如图2所示,图中左侧是示范者,右侧是学习者。
当示范视频中包含多人的时候,本实施例采用自上而下的检测方法,首先通过目标检测算法将每一个人检测出来,然后将多人中最前排、最中间的人选作本实施例的示范者,然后再针对此人做人体关键点检测,具体过程如图3所示。
3.关键点重塑比例计算过程
由于在以上的步骤中已经提取出示范者和学习者的身体关键点信息,在示范视频开始播放,且学习者摄像头获取影像的时候就可以得到示范者各个身体部位在设备中显示的长度信息(如图4上半部分①~⑧所示)和学习者各个身体部位在设备中显示的长度信息(如图4上半部分
本实施例使用简单的计算各长度之间的比值,并对各个比值取均值的方法来获得重塑比例,如下所示:
⑨的长度是①的2.34倍;
⑩的长度是②的2.13倍;
计算以上比值的均值,得出学习者身体关键点之间的长度
同时,该步骤的替代方案还有:对于比值数据可以采用加权计算的方式,根据身体关键点中膝盖到脚踝的关键点精确度最高,则这二者之间长度比例的权重适当增加,精确度低的关键点间的长度比例的权值降低。同时,由于学习者相对于摄像头的位置变化,可以随着学习的进行,不断地进行重塑比例的学习和调整。
4.定位匹配过程
在计算出重塑比例之后就可以对示范者重塑之后的关键点信息进行定位匹配。本实施例的定位过程如图5所示:
由于学习者动作可能不标准,所以挑选人体肢体中比较稳定不易变动的躯干中的关键点,本实施例选取三个定位点分别为:左髋部、右髋部、左肩与右髋部以及右肩与左髋部的交点。示范者和学习者分别定位这三个点在显示屏幕的位置,将示范者的三个点的位置分别记为pos_1teacher,pos_2teacher,pos_3teacher,将学习者的三个点的位置分别记为pos_1user,pos_2user,pos_3user,示范者定位点保持相对位置不变,同时主动靠近学习者定位点,最终以坐标差值最小方差为目标(如下公式),最小的方差结果对应的位置就是示范者要定位的位置:
5.输出显示阶段
定位匹配之后,要将示范者身体动作以比较适合学习者接受的形势展现出来。首先,弱化学习者自身在摄像头中的实时视频图像,将图像透明度降低,然后将示范者的关键点展示在学习者图像的上层。本实施例中使用更直接明了的轮廓展示给学习者,该轮廓是将模板中的轮廓按照关键点之间的长度进行各肢体比例的调整,并进行姿势重组,显示出骨骼关键点的填充轮廓图,显示过程如图6所示。
更进一步,显示图像可以是示范者提取出的轮廓根据关键点比例调整后的轮廓图。同时,可以根据示范者和学习者身体关键点的对比值以语音的形式提示学习者,例如两腿分开得大一些,胳膊抬高30度等。最终展示给学习者的效果图如图7所示。
采用本实施例提供的上述技术方案,学习者在做动作时能够实时纠正自己错误的动作与姿势,没有延迟。并且,学习者与示范者之间的对比结果更清晰可见,可以使学习者更直接地了解自己的动作错误所在。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!