支持权重稀疏的存内计算架构及其数据输出方法与流程
本发明涉及电路设计技术领域,更具体地,涉及一种支持权重稀疏的存内计算架构及其数据输出方法。
背景技术:
存内计算是一种新兴的电路架构,不同于传统的存储与计算分离的冯诺依曼架构,存内计算将存储和计算融为一体,在存储单元的内部完成计算。相比于传统结构,存内计算具有高并行度、高能量效率的特点,对于需要大量并行矩阵向量乘法操作的算法,特别是神经网络算法,是一种更优的替代方案。
神经网络算法是目前人工智能技术的一种重要算法,由大量的矩阵向量乘法操作组成,适合于使用存内计算电路实现高能效处理。传统存内计算架构在神经网络算法的应用中,包含m行n列的存储单元阵列,每一行通过数模转换器(dac)将图像输入存储单元,然后与存储在存储单元中的神经网络权重(每一行的n列为一个n-bit的权重数据)进行乘累加操作。
在每一个时钟周期,存储单元阵列中的m行dac会打开输入,这m行的乘累加结果在每一列的模数转换器(adc)上转换为数字信号输出。即,由存内计算得到的结果需要通过adc等模块,将模拟电压/电流信号转换为数字信号到数字电路中存储和处理。记第i行输入的图像为ai,第i行第(j*n)~(j*n+n-1)列的n-bit的权重数据为wij,则adc输出的乘累加结果为
在实际应用中,考虑到神经网络算法中存在的冗余性,通过稀疏技术,可以将算法中大量的权重数据(weight)置为0,从而降低神经网络的计算开销。但是,在存内计算中0的分布往往是离散的,不规则的。由于存内计算往往是并行计算,即使绝大多数权重是0,只要有一个非0的权重,相应输出结果对应的adc就需要打开,将产生大量的功耗,甚至可占据整个存内计算模块95%的功耗开销。
技术实现要素:
为了克服上述问题或者至少部分地解决上述问题,本发明实施例提供一种支持权重稀疏的存内计算架构及其数据输出方法,用以有效降低存内计算在神经网络模型权重稀疏应用中的功耗,提高应用的可行性。
第一方面,本发明实施例提供一种支持权重稀疏的存内计算架构,包括:
存储单元阵列,包含多个子存储单元块,每列所述子存储单元块的输出端口对应设置有模数转换单元;
运算模块,用于按照各所述子存储单元块,对所述存储单元阵列中存储的神经网络模型权重进行稀疏训练,使得每个所述子存储单元块中存储的权重被训练为全零值或非全零值;
检测模块,用于当检测到所述模数转换单元对应的所述子存储单元块处于工作状态且存储的权重为全零值时,关断所述模数转换单元,并将所述模数转换单元的输出置为零。
进一步的,所述运算模块还用于,在进行稀疏训练的过程中,适应性调整所述子存储单元块的行数和列数,以适配所述存储单元阵列的总行数和总列数。
进一步的,所述运算模块还用于,在将所述子存储单元块中存储的权重训练为全零值后,将所述子存储单元块标记为稀疏块;
相应的,所述检测模块还用于,通过检测各所述子存储单元块是否包含稀疏块标记,检测所述子存储单元块存储的权重是否为全零值。
其中可选的,所述模数转换单元具体为模拟/数字转换器adc、采样放大电路sa或者存内计算处理单元pu。
其中可选的,所述运算模块具体用于,利用1bit的稀疏标记sparsityindex,标记所述子存储单元块是否为稀疏块。
进一步的,所述运算模块还用于,在每一个时钟周期,对应打开所述存储单元阵列的行数和列数分别与所述子存储单元块的行数和列数一致。
第二方面,本发明实施例提供一种基于如上述第一方面所述的支持权重稀疏的存内计算架构的数据输出方法,包括:
按照各所述子存储单元块,对所述存储单元阵列中存储的神经网络模型权重进行稀疏训练,使得每个所述子存储单元块中存储的权重被训练为全零值或非全零值;
若检测到所述模数转换单元对应的所述子存储单元块处于工作状态且存储的权重为全零值,则关断所述模数转换单元,并将所述模数转换单元的输出置为零,否则,根据所述模数转换单元对应的处于工作状态的子存储单元块的输入以及处于工作状态的子存储单元块中存储的权重,进行乘加运算,并通过打开所述模数转换单元,输出乘加运算结果。
本发明实施例提供的支持权重稀疏的存内计算架构及其数据输出方法,通过对存内计算的存储单元阵列中的权重进行按块稀疏训练,并将存内计算的存储单元阵列进行子存储单元块划分,实现神经网络模型权重的按块稀疏,同时通过关断稀疏块对应的模数转换单元,能够有效降低存内计算在神经网络模型权重稀疏应用中的功耗,提高应用的可行性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
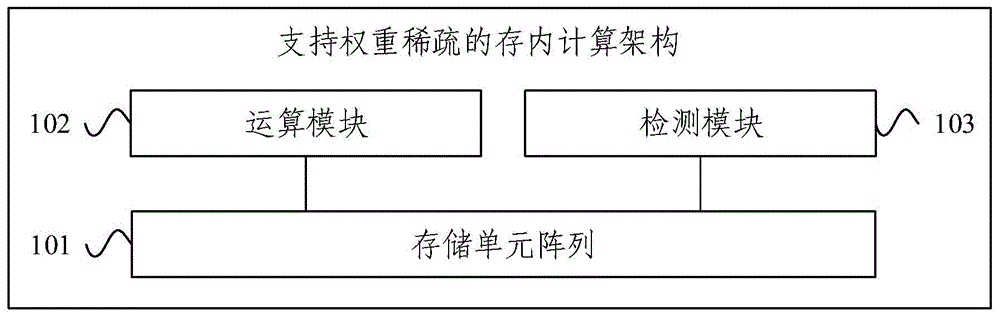
图1为本发明实施例提供的支持权重稀疏的存内计算架构的结构示意图;
图2为根据本发明实施例提供的支持权重稀疏的存内计算架构的电路结构示意图;
图3为本发明实施例提供的基于支持权重稀疏的存内计算架构的数据输出方法的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明实施例的一部分实施例,而不是全部的实施例。基于本发明实施例中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明实施例保护的范围。
本发明实施例针对现有技术的存内计算在神经网络应用中的功耗过高的问题,通过对存内计算的存储单元阵列中的权重进行按块稀疏训练,并将存内计算的存储单元阵列进行子存储单元块划分,实现神经网络模型权重的按块稀疏,同时通过关断稀疏块对应的模数转换单元,能够有效降低存内计算在神经网络模型权重稀疏应用中的功耗,提高应用的可行性。以下将具体通过多个实施例对本发明实施例进行展开说明和介绍。
图1为本发明实施例提供的支持权重稀疏的存内计算架构的结构示意图,该架构可用于实现通过支持规则的权重稀疏方式,关闭对应的模数转换电路单元,从而降低存内计算电路系统的功耗。如图1所示,该系统包括存储单元阵列101、运算模块102和检测模块103。其中:
存储单元阵列101包含多个子存储单元块,每列子存储单元块的输出端口对应设置有模数转换单元;运算模块102用于按照各子存储单元块,对存储单元阵列中存储的神经网络模型权重进行稀疏训练,使得每个子存储单元块中存储的权重被训练为全零值或非全零值;检测模块103用于当检测到模数转换单元对应的子存储单元块处于工作状态且存储的权重为全零值时,关断模数转换单元,并将模数转换单元的输出置为零。
可以理解为,本发明实施例的支持权重稀疏的存内计算架构通过将神经网络的权重经过规则的稀疏方式进行训练,使存储在存内计算电路中的权重按块稀疏,在执行相应稀疏权重的计算时,可以直接跳过,并关断相应的模数转换电路单元来节省功耗。因此其至少应包括存储单元阵列101、运算模块102和检测模块103,分别用于实现对神经网络模型权重的存储、对神经网络模型权重的按块稀疏训练和通过检测稀疏块关断对应的模数转换单元以实现节能的处理流程。
具体而言,如图2所示,为根据本发明实施例提供的支持权重稀疏的存内计算架构的电路结构示意图,存储单元阵列101包括m行n列的存储单元,其被按照m行n列的小块进行切分,每个m行n列的小块构成一个子存储单元块。其中每一小块的权重在算法训练的过程中,将被训练为全部为0的值(稀疏)或者不全部为0的值。同时,在每一列的子存储单元块的乘加输出端,设置有对应的模数转换单元,用于将存内计算得到的结果,如模拟电压/电流信号等,转换为数字信号到数字电路中存储和处理。
其中可选的,模数转换单元具体为模拟/数字转换器adc、采样放大电路sa或者存内计算处理单元pu。也即,在不同的存内计算架构中,adc也可以是采样放大电路(sensingamplifier,sa)或者存内计算处理单元(processingunit,pu)等。无论采用哪种,实现的功能都是将存内计算的计算结果从模拟电压或电流转换为数字电路表示。
运算模块102主要用于实现存内计算架构中的计算功能,具体通过神经网络算法,将神经网络模型权重按块训练为稀疏形式,对应到存内计算中存储单元阵列的m行n列的子存储单元块。也即,通过按块稀疏训练,使得每个子存储单元块中存储的权重要么全为零值(即实现全零值),要么不全为零值(即实现非全零值)。
检测模块103则在稀疏训练的基础上,对各子存储单元块内存储的权重情况进行检测,以确定每个模数转换单元对应的子存储单元块的存储状态。也即,确定其是空闲的还是处于工作状态的,并确定其中处于工作状态的子存储单元块所存储的权重是全为零的还是不全为零的。若某一模数转换单元对应的处于工作状态的子存储单元块所存储的权重是全为零值的,则对应关断该模数转换单元。并且,由于存内计算的存储单元阵列是以m行作为一个时钟周期作为运算单元,一个稀疏块由于存储的数据全部为0,则可直接确定对应的乘累加结果也为0。因此检测模块103在关断对应模数转换单元的基础上,会将该模数转换单元的输出置为零。
本发明实施例提供的支持权重稀疏的存内计算架构,通过对存内计算的存储单元阵列中的权重进行按块稀疏训练,并将存内计算的存储单元阵列进行子存储单元块划分,实现神经网络模型权重的按块稀疏,同时通过关断稀疏块对应的模数转换单元,能够有效降低存内计算在神经网络模型权重稀疏应用中的功耗,提高应用的可行性。
另外,在上述各实施例的基础上,运算模块还可用于,在进行稀疏训练的过程中,适应性调整子存储单元块的行数和列数,以适配存储单元阵列的总行数和总列数。
可以理解为,在通过神经网络进行按块稀疏训练的过程中,可对各块的行数和列数进行适配性调整,从而也将子存储单元块的行数和列数进行适应切分,以适配存储单元阵列的总行数和总列数。
进一步的,运算模块还用于,在每一个时钟周期,对应打开存储单元阵列的行数和列数分别与子存储单元块的行数和列数一致。也就是说,在每一个时钟周期内,打开的存储单元阵列的行数与子存储单元块的行数保持一致,打开的存储单元阵列的列数与权重的bit数保持一致。
进一步的,运算模块还用于,在将子存储单元块中存储的权重训练为全零值后,将子存储单元块标记为稀疏块;相应的,检测模块还用于,通过检测各子存储单元块是否包含稀疏块标记,检测子存储单元块存储的权重是否为全零值。
可以理解为,在通过神经网络算法,将某一子存储单元块中存储的权重全部训练为零值后,对该子存储单元块进行标记,也即将其标记为稀疏块,得到相应的稀疏块标记。其中稀疏块被称作sparsityweightblock(swb)。其中可选的,运算模块具体用于,利用1bit的稀疏标记sparsityindex,标记子存储单元块是否为稀疏块。也即,可以通过一个1bit的稀疏标记sparsityindex,来标记当前对应adc对应的权重数据块是否是一个swb。如果是swb,则控制adc断电,并在后续电路中直接输出0,降低adc的运行功耗。
于是相应的,检测模块在检测各子存储单元块是否是稀疏块时,只需检测各子存储单元块是否包含有对应的稀疏块标记,来检测各子存储单元块中存储的权重是否全部为零值。如,当某一子存储单元块包含有对应的稀疏块标记时,即表明其中存储的权重是全部为零的。
基于相同的发明构思,本发明实施例还提供一种基于如上述各实施例的支持权重稀疏的存内计算架构的数据输出方法,该方法通过应用上述各实施例提供的支持权重稀疏的存内计算架构,实现对神经网络模型权重的按块稀疏,并能有效降低能耗。因此,在上述各实施例的支持权重稀疏的存内计算架构中的描述和定义,可以用于本发明实施例中各个处理步骤的理解,具体可参考上述实施例,此处不在赘述。
作为本发明的一个实施例,所提供的基于如上述各实施例的支持权重稀疏的存内计算架构的数据输出方法如图3所示,为本发明实施例提供的基于支持权重稀疏的存内计算架构的数据输出方法的流程示意图,包括以下处理过程:
s301,按照各子存储单元块,对存储单元阵列中存储的神经网络模型权重进行稀疏训练,使得每个子存储单元块中存储的权重被训练为全零值或非全零值。
可以理解为,本步骤主要实现存内计算架构中的数据计算,具体通过神经网络算法,将神经网络模型权重按块训练为稀疏形式,对应到存内计算中存储单元阵列的m行n列的子存储单元块。也即,通过按块稀疏训练,使得每个子存储单元块中存储的权重要么全为零值(即实现全零值),要么不全为零值(即实现非全零值)。
s302,若检测到模数转换单元对应的子存储单元块处于工作状态且存储的权重为全零值,则关断模数转换单元,并将模数转换单元的输出置为零,否则,根据模数转换单元对应的处于工作状态的子存储单元块的输入以及处于工作状态的子存储单元块中存储的权重,进行乘加运算,并通过打开模数转换单元,输出乘加运算结果。
可以理解为,本步骤在稀疏训练的基础上,对各子存储单元块内存储的权重情况进行检测,以确定每个模数转换单元对应的子存储单元块的存储状态。也即,确定其是空闲的还是处于工作状态的,并确定其中处于工作状态的子存储单元块所存储的权重是全为零的或者不全为零的。
若某一模数转换单元对应的处于工作状态的子存储单元块所存储的权重是全为零值的,则对应关断该模数转换单元。并且,由于存内计算的存储单元阵列是以m行作为一个时钟周期作为运算单元,一个稀疏块由于存储的数据全部为0,则可直接确定对应的乘累加结果也为0。因此在关断对应模数转换单元的基础上,会将该模数转换单元的输出置为零。
另外,若某一模数转换单元对应的处于工作状态的子存储单元块存储的权重不是全为零值的,则对应打开该模数转换单元。同时,对该模数转换单元对应的处于工作状态的子存储单元块的输入及其中存储的权重进行乘加运算,输出相应的乘加运算结果。
本发明实施例提供的基于如上述各实施例所述的支持权重稀疏的存内计算架构的数据输出方法,通过对存内计算的存储单元阵列中的权重进行按块稀疏训练,并将存内计算的存储单元阵列进行子存储单元块划分,实现神经网络模型权重的按块稀疏,同时通过关断稀疏块对应的模数转换单元,能够有效降低存内计算在神经网络模型权重稀疏应用中的功耗,提高应用的可行性。
为进一步说明本发明实施例的技术方案,本发明实施例根据上述各实施例提供如下具体的处理过程,但不对本发明实施例的保护范围进行限制。
本发明实施例经由数字电路和模拟电路的前端设计、后端设计及晶元制造后,得到了包含本发明实施例的存内计算架构实例的集成电路芯片。工艺制程采用台积电65nm工艺,而后封装芯片后测试功耗和性能。芯片面积3.0mmx3.0mm,包含了4个相同的发明实例,每一个发明实例的面积为0.37mm×0.40mm。测试运行频率50-100mhz,对应电压为0.90-1.05v。
数据存储与运算过程包括:
通过神经网络算法,将权重训练为稀疏形式,对应存内计算阵列的m行n列的swb。
存内计算阵列每一个周期的打开行数与m保持一致,n与权重的bit数保持一致。m和n均可在算法训练过程中进行灵活调整以适配实际的存内计算阵列。
基于swb的adc的动态关断。每一个m行n列的swb对应一个1bit的稀疏标记,在执行当前swb的乘累加操作时进行adc的动态打开和关断。
试验表明,本发明实施例通过支持权重稀疏,动态关断adc,降低了存内计算架构的功耗开销。同时,本发明实施例在不同神经网络算法上进行了稀疏训练与芯片测试,在基于mnist和cifar-10两种图像识别测试集上,使用vgg16和resnet18两种神经网络算法模型,实现了20~39倍的权重数据分块压缩,即swb的比例占到了所有权重的95%~97.4%。对于基于cifar-10的vgg16网络,采用4bit输入图像和4bit权重,在实际芯片的发明实例部分实现了2.4倍~13.6倍的功耗节省(随着网络不同层的swb比例变化),平均节省为10.1倍。
可以理解的是,以上所描述的存内计算架构的实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,既可以位于一个地方,或者也可以分布到不同网络单元上。可以根据实际需要选择其中的部分或全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上实施方式的描述,本领域的技术人员可以清楚地了解,各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品,也可以以硬件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如u盘、移动硬盘、rom、ram、磁碟或者光盘等,包括若干指令,用以使得一台计算机设备(如个人计算机,服务器,或者网络设备等)执行上述各方法实施例或者方法实施例的某些部分所述的方法。
另外,本领域内的技术人员应当理解的是,在本发明实施例的申请文件中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本发明实施例的说明书中,说明了大量具体细节。然而应当理解的是,本发明实施例的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。类似地,应当理解,为了精简本发明实施例公开并帮助理解各个发明方面中的一个或多个,在上面对本发明实施例的示例性实施例的描述中,本发明实施例的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。
最后应说明的是:以上实施例仅用以说明本发明实施例的技术方案,而非对其限制;尽管参照前述实施例对本发明实施例进行了详细的说明,本领域的技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!