一种基于深度学习的人脸识别方法、系统和可读存储介质与流程
本发明涉及图像处理技术领域,更具体的,涉及一种基于深度学习的人脸识别方法、系统和可读存储介质。
背景技术:
传统的个人身份验证手段如口令、证件、ic卡等方式,由于与身份人的可分离性,致使伪造、盗用、破译等现象时有发生,已经不能满足现代社会经济活动和社会安全防范的需要。生物特征识别包括指纹、掌纹、语音、人脸、虹膜、步态、掌静脉等。生物特征识别技术先投入广泛应用的是指纹、掌纹扫描识别技术,但是却常常因为受到皮肤纹理及干燥程度等条件制约出现误判,引发不必要的麻烦,已远远不能满足人们的需求。随着科学技术的不断发展,以及社会对于身份识别越来越高的要求,生物特征识别技术逐渐呈多样化发展,例如虹膜识别、声音识别、笔迹识别、签名识别、人脸识别等各项生物特征识别技术。
人脸识别技术是结合模式识别技术与计算机视觉技术的智能识别技术,具有广泛的应用,比如,在信息安全领域为防止身份证盗用情况,可以利用基于人脸识别的人证比对技术;在在学校、公司以及住宅小区等的安全监控,甚至考勤制度都可以通过自动的人脸识别技术来完成;在寻找遗失儿童和老人、追查逃犯等任务中也可以利用人脸识别技术来提高破案效率等。
现有的人脸识别技术在复杂环境条件下,存在识别准确准确率低的问题,因此需要开发一种基于深度学习的人脸识别方法是亟不可待的。
技术实现要素:
为了解决上述现有技术中在复杂环境条件下,存在识别准确准确率低的缺陷,本发明提出了一种基于深度学习的人脸识别方法、系统和可读存储介质。
为了解决上述的技术问题,本发明第一方面公开了一种基于深度学习的人脸识别方法,具体包括:
采集人脸图像;
对采集的人脸图像进行预处理,所述预处理包括:直方图均衡、平滑去噪;
提取预处理后人脸图像的特征,输出统一维度的特征向量;
构建神经网络识别模型,利用现有的人脸图像数据集进行训练,得到训练后的神经网络识别模型;
将已提取的人脸图像特征向量输入神经网络识别模型,输出识别结果。
本方案中,在所述预处理之前还包括通过利用mtcnn神经网络对人脸图像进行人脸框的获取和特征点的标定。
本方案中,所述人脸框标定是从采集的人脸图像中根据预设的尺寸来获取包含人脸的区域,所述特征点包括人脸上若干可选的特征点。
本方案中,所述采集人脸图像是通过高清摄像头获取的实时视频帧或人脸图像。
本方案中,所述预处理后的人脸图像为150*150像素图像。
本方案中,所述提取预处理后人脸图像的特征是利用lbp算子提取人脸图像的纹理特征,lbp算子的表达式为:
其中,(xc,yc)代表邻居的中心像素,ic图像中心像素值,ip图像邻居范围内其他像素点的值,h(x)表示为
本方案中,构建的神经网络识别模型,包括输入层、架体循环的卷积层、池化层,三个全连接层,最后一层为softmax层,其中,卷积层的卷积核大小为3*3,步长为一个像素,填充为一个像素,其中softmax层的函数形式为:
其中,zj表示当前神经元的输入,总的类别个数为n个,分子表示当前输入的指数,分母表示总的输入指数之和,aj的结果在0到1之间。
本方案中,利用现有的人脸图像数据集进行训练包括前向传播和反向传播,具体步骤如下:
前向传播:训练样本从输入层进入网络,通过上一层的结点以及对应的连接权值进行加权和运算,结果加上一个偏置项,通过非线性函数得到的结果就是本层结点的输出,逐层运算得到输出层结果;若输出层的实际输出与期望输出不同,则转至误差反向传播;若输出层的实际输出与期望输出相同,则结束;
反向传播:期望输出与实际输出之差按原通路反传计算,通过隐层反向传播直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将误差信号作为修正各单元权值的根据。
本发明第二方面提供了一种基于深度学习的人脸识别系统,该系统包括:存储器、处理器,所述存储器中包括一种基于深度学习的人脸识别方法程序,所述一种基于深度学习的人脸识别方法程序被所述处理器执行时实现如下步骤:
采集人脸图像;
对采集的人脸图像进行预处理,所述预处理包括:直方图均衡、平滑去噪;
提取预处理后人脸图像的特征,输出统一维度的特征向量;
构建神经网络识别模型,利用现有的人脸图像数据集进行训练,得到训练后的神经网络识别模型;
将已提取的人脸图像特征向量输入神经网络识别模型,输出识别结果。
本方案中,在所述预处理之前还包括通过利用mtcnn神经网络对人脸图像进行人脸框的获取和特征点的标定。
本方案中,所述人脸框标定是从采集的人脸图像中根据预设的尺寸来获取包含人脸的区域,所述特征点包括人脸上若干可选的特征点。
本方案中,所述采集人脸图像是通过高清摄像头获取的实时视频帧或人脸图像。
本方案中,所述预处理后的人脸图像为150*150像素图像。
本方案中,所述提取预处理后人脸图像的特征是利用lbp算子提取人脸图像的纹理特征,lbp算子的表达式为:
其中,(xc,yc)代表邻居的中心像素,ic图像中心像素值,ip图像邻居范围内其他像素点的值,h(x)表示为
本方案中,构建的神经网络识别模型,包括输入层、架体循环的卷积层、池化层,三个全连接层,最后一层为softmax层,其中,卷积层的卷积核大小为3*3,步长为一个像素,填充为一个像素,其中softmax层的函数形式为:
其中,zj表示当前神经元的输入,总的类别个数为n个,分子表示当前输入的指数,分母表示总的输入指数之和,aj的结果在0到1之间。
本方案中,利用现有的人脸图像数据集进行训练包括前向传播和反向传播,具体步骤如下:
前向传播:训练样本从输入层进入网络,通过上一层的结点以及对应的连接权值进行加权和运算,结果加上一个偏置项,通过非线性函数得到的结果就是本层结点的输出,逐层运算得到输出层结果;若输出层的实际输出与期望输出不同,则转至误差反向传播;若输出层的实际输出与期望输出相同,则结束;
反向传播:期望输出与实际输出之差按原通路反传计算,通过隐层反向传播直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将误差信号作为修正各单元权值的根据。
本发明第三方面提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中包括基于深度学习的人脸识别方法程序,所述一种基于深度学习的人脸识别方法程序被处理器执行时,实现如上述任一项所述的一种基于深度学习的人脸识别方法的步骤。
本发明公开了一种基于深度学习的人脸识别方法、系统和可读存储介质,通过对采集的人脸图像进行预处理,利用lbp算子提取维数统一的纹理特征,构建神经网络识别模型并训练,将提取的特征向量输入神经网络识别模型,完成人脸识别,本发明提高了抗光照干扰能力,从而提高了人脸识别的准确率。
附图说明
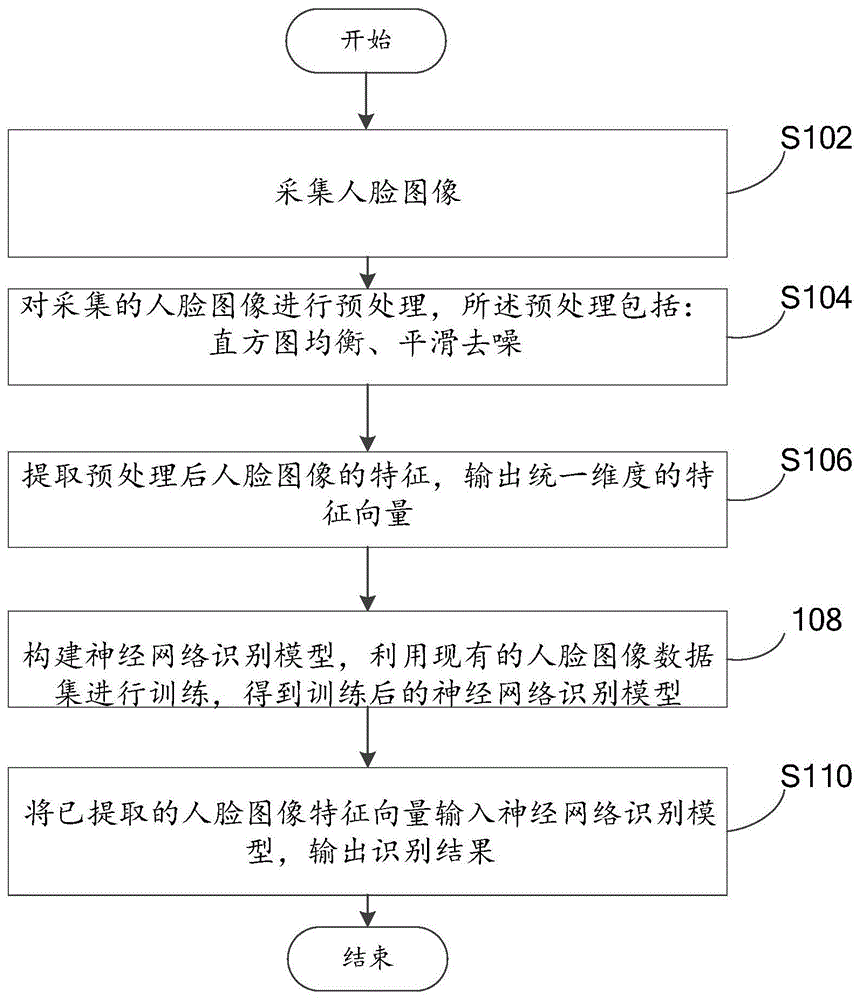
图1示出了本发明一种基于深度学习的人脸识别方法流程图。
图2示出了本发明一种基于深度学习的人脸识别系统框图;
具体实施方法
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
本发明的识别方法可适用于那些需要人脸识别设备,如考勤机,检票机、刷脸支付终端等。人脸识别,即通过采集获取人脸图像,通过特征提取,与预存的人脸图像特征匹配,即可完成识别。当然,本发明并不限制具体使用方式或设备的种类,任何采用本发明的技术方案都将落入本发明保护范围内。
图1示出了本发明一种基于深度学习的人脸识别方法流程图。
如图1所示,本发明实施例第一方面提供了一种基于深度学习的人脸识别方法,包括:
s102:采集人脸图像;
需要说明的是,在一个具体的实施例中可以通过高清摄像头获取视频帧或者人脸图像,也可以通过其他的装置采集人脸图像。
s104:对采集的人脸图像进行预处理,所述预处理包括:直方图均衡、平滑去噪;
所述直方图均衡将原始图像中比较集中的灰度区间映射到整个图像的不同灰度范围中。具体而言,直方图均衡化的实质是将图像进行非线性拉伸,重新分配图像的像素值,使在一定灰度范围内图像各个像素值的个数大体相同。处理后原先随机分布的图像直方图,会变成均匀分布的直方图样。
所述平滑去噪处理在于平滑效果越好,图像质量改善越好,且不会损坏图像的重要特征信息。
本方案中,在所述预处理之前还包括通过利用mtcnn神经网络对人脸图像进行人脸框的获取和特征点的标定。
更具体地,所述人脸框标定是从采集的人脸图像中根据预设的尺寸来获取包含人脸的区域,所述特征点包括人脸上若干可选的特征点。具体的特征点如:额头眉骨对称点各选取一个点,鼻尖选取一个点,下巴中间选取一个点。
根据本发明实施例,所述预处理后的人脸图像可以为150*150像素图像或其他预设尺寸的人脸图像。具体的图像尺寸大小由本领域技术人员根据实际需要调整和确认。
s106:提取预处理后人脸图像的特征,输出统一维度的特征向量;
本发明中通过提取纹理特征来克服光照变化的影响,本发明用过lbp算子提取特征,实现原理为,选取一块像素3×3大小的邻域,将图像中心像素的值和周围的8个像素点的值进行对比,如中心点的像素值比周围邻域像素值大,则邻域值记为1,否则记为0。
具体原理表达式如下:
其中,(xc,yc)代表邻居的中心像素,ic图像中心像素值,ip图像邻居范围内其他像素点的值,h(x)表示为
需要说明的是,提取的特征向量维数是统一,均符合后续神经网络识别模型的输入要求。
s108:构建神经网络识别模型,利用现有的人脸图像数据集进行训练,得到训练后的神经网络识别模型;
本发明中,构建的神经网络识别模型,包括输入层、架体循环的卷积层、池化层,三个全连接层,最后一层为softmax层,其中,卷积层的卷积核大小为3*3,步长为一个像素,填充为一个像素,其中softmax层的函数形式为:
其中,zj表示当前神经元的输入,总的类别个数为n个,分子表示当前输入的指数,分母表示总的输入指数之和,aj的结果在0到1之间。
其中,可以采用的已有人脸图像数据集包括feret人脸数据库或cmumulti-pie人脸数据库或yale人脸数据库。
对已构建的神经网络识别模型进行训练,主要包括前向传播和反向传播,所述前向传播:训练样本从输入层进入网络,通过上一层的结点以及对应的连接权值进行加权和运算,结果加上一个偏置项,通过非线性函数得到的结果就是本层结点的输出,逐层运算得到输出层结果;若输出层的实际输出与期望输出不同,则转至误差反向传播;若输出层的实际输出与期望输出相同,则结束;
所述反向传播:期望输出与实际输出之差按原通路反传计算,通过隐层反向传播直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将误差信号作为修正各单元权值的根据。
s110:将已提取的人脸图像特征向量输入神经网络识别模型,输出识别结果。
图2示出了一种基于深度学习的人脸识别系统框图。
本发明第二方面提供了一种基于深度学习的人脸识别系统,该系统包括:存储器21、处理器22,所述存储器中包括一种基于深度学习的人脸识别方法程序,所述一种基于深度学习的人脸识别方法程序被所述处理器执行时实现如下步骤:
s102:采集人脸图像;
需要说明的是,在一个具体的实施例中可以通过高清摄像头获取视频帧或者人脸图像,也可以通过其他的装置采集人脸图像。
s104:对采集的人脸图像进行预处理,所述预处理包括:直方图均衡、平滑去噪;
所述直方图均衡将原始图像中比较集中的灰度区间映射到整个图像的不同灰度范围中。具体而言,直方图均衡化的实质是将图像进行非线性拉伸,重新分配图像的像素值,使在一定灰度范围内图像各个像素值的个数大体相同。处理后原先随机分布的图像直方图,会变成均匀分布的直方图样。
所述平滑去噪处理在于平滑效果越好,图像质量改善越好,且不会损坏图像的重要特征信息。
本方案中,在所述预处理之前还包括通过利用mtcnn神经网络对人脸图像进行人脸框的获取和特征点的标定。
更具体地,所述人脸框标定是从采集的人脸图像中根据预设的尺寸来获取包含人脸的区域,所述特征点包括人脸上若干可选的特征点。具体的特征点如:额头眉骨对称点各选取一个点,鼻尖选取一个点,下巴中间选取一个点。
本方案中,所述预处理后的人脸图像可以为150*150像素图像或其他预设尺寸。具体的图像尺寸大小由本领域技术人员根据实际需要调整和确认。
s106:提取预处理后人脸图像的特征,输出统一维度的特征向量;
本发明中通过提取纹理特征来克服光照变化的影响,本发明通过lbp算子提取特征,实现原理为,选取一块像素3×3大小的邻域,将图像中心像素的值和周围的8个像素点的值进行对比,如中心点的像素值比周围邻域像素值大,则邻域值记为1,否则记为0。
具体原理表达式如下:
其中,(xc,yc)代表邻居的中心像素,ic图像中心像素值,ip图像邻居范围内其他像素点的值,h(x)表示为
需要说明的是,提取的特征向量维数是统一,均符合后续神经网络模型的输入要求。
s108:构建神经网络识别模型,利用现有的人脸图像数据集进行训练,得到训练后的神经网络识别模型;
本发明中,构建的神经网络识别模型,包括输入层、架体循环的卷积层、池化层,三个全连接层,最后一层为softmax层,其中,卷积层的卷积核大小为3*3,步长为一个像素,填充为一个像素,其中softmax层的函数形式为:
其中,zj表示当前神经元的输入,总的类别个数为n个,分子表示当前输入的指数,分母表示总的输入指数之和,aj的结果在0到1之间。
其中,可以采用的已有人脸图像数据集包括feret人脸数据库或cmumulti-pie人脸数据库或yale人脸数据库。
对已构建的神经网络识别模型进行训练,主要包括前向传播和反向传播,所述前向传播:训练样本从输入层进入网络,通过上一层的结点以及对应的连接权值进行加权和运算,结果加上一个偏置项,通过非线性函数得到的结果就是本层结点的输出,逐层运算得到输出层结果;若输出层的实际输出与期望输出不同,则转至误差反向传播;若输出层的实际输出与期望输出相同,则结束;
所述反向传播:期望输出与实际输出之差按原通路反传计算,通过隐层反向传播直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将误差信号作为修正各单元权值的根据。
s110:将已提取的人脸图像特征向量输入神经网络识别模型,输出识别结果。
本发明第三方面提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中包括基于深度学习的人脸识别方法程序,所述一种基于深度学习的人脸识别方法程序被处理器执行时,实现如上述任一项所述的一种基于深度学习的人脸识别方法的步骤。
其中具体包括:
s102:采集人脸图像;
需要说明的是,在一个具体的实施例中可以通过高清摄像头获取视频帧或者人脸图像,也可以通过其他的装置采集人脸图像。
在一个具体的实施例中可以通过高清摄像头获取视频帧或者人脸图像;
s104:对采集的人脸图像进行预处理,所述预处理包括:直方图均衡、平滑去噪;
所述直方图均衡将原始图像中比较集中的灰度区间映射到整个图像的不同灰度范围中。具体而言,直方图均衡化的实质是将图像进行非线性拉伸,重新分配图像的像素值,使在一定灰度范围内图像各个像素值的个数大体相同。处理后原先随机分布的图像直方图,会变成均匀分布的直方图样。
所述平滑去噪处理在于平滑效果越好,图像质量改善越好,且不会损坏图像的重要特征信息。
本方案中,在所述预处理之前还包括通过利用mtcnn神经网络对人脸图像进行人脸框的获取和特征点的标定。
更具体地,所述人脸框标定是从采集的人脸图像中根据预设的尺寸来获取包含人脸的区域,所述特征点包括人脸上若干可选的特征点。具体的特征点如:额头眉骨对称点各选取一个点,鼻尖选取一个点,下巴中间选取一个点。
本方案中,所述预处理后的人脸图像可以为150*150像素图像或其他预设尺寸。
s106:提取预处理后人脸图像的特征,输出统一维度的特征向量;
本发明中通过提取纹理特征来克服光照变化的影响,本发明通过lbp算子提取特征,实现原理为,选取一块像素3×3大小的邻域,将图像中心像素的值和周围的8个像素点的值进行对比,如中心点的像素值比周围邻域像素值大,则邻域值记为1,否则记为0。
具体原理表达式如下:
其中,(xc,yc)代表邻居的中心像素,ic图像中心像素值,ip图像邻居范围内其他像素点的值,h(x)表示为
需要说明的是,提取的特征向量维数是统一,均符合后续神经网络模型的输入要求。
s108:构建神经网络识别模型,利用现有的人脸图像数据集进行训练,得到训练后的神经网络识别模型;
本发明中,构建的神经网络识别模型,包括输入层、架体循环的卷积层、池化层,三个全连接层,最后一层为softmax层,其中,卷积层的卷积核大小为3*3,步长为一个像素,填充为一个像素,其中softmax层的函数形式为:
其中,zj表示当前神经元的输入,总的类别个数为n个,分子表示当前输入的指数,分母表示总的输入指数之和,aj的结果在0到1之间。
其中,可以采用的已有人脸图像数据集包括feret人脸数据库或cmumulti-pie人脸数据库或yale人脸数据库。
对已构建的神经网络识别模型进行训练,主要包括前向传播和反向传播,所述前向传播:训练样本从输入层进入网络,通过上一层的结点以及对应的连接权值进行加权和运算,结果加上一个偏置项,通过非线性函数得到的结果就是本层结点的输出,逐层运算得到输出层结果;若输出层的实际输出与期望输出不同,则转至误差反向传播;若输出层的实际输出与期望输出相同,则结束;
所述反向传播:期望输出与实际输出之差按原通路反传计算,通过隐层反向传播直至输入层,在反传过程中将误差分摊给各层的各个单元,获得各层各单元的误差信号,并将误差信号作为修正各单元权值的根据。
s110:将已提取的人脸图像特征向量输入神经网络识别模型,输出识别结果。
本发明公开了一种基于深度学习的人脸识别方法、系统和可读存储介质,通过对采集的人脸图像进行预处理,利用lbp算子提取维数统一的纹理特征,构建神经网络识别模型并训练,将提取的特征向量输入神经网络识别模型,完成人脸识别,本发明提高了抗光照干扰能力,从而提高了人脸识别的准确率。
在本申请所提供的几个实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元;既可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
另外,在本发明各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
或者,本发明上述集成的单元如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!