基于遮挡感知和特征金字塔匹配的相机自运动估计方法与流程
本发明涉及单目图像深度预测和相机自运动估计领域,具体涉及一种基于遮挡感知和特征金字塔匹配的相机自运动估计方法。
背景技术:
对于机器人或无人驾驶汽车而言,通过图像估计深度和自身运动是至关重要的任务。先前的有监督深度估计方法可以通过端到端的卷积神经网络学习图像和深度之间的关系。同样,视觉里程计也可以通过端到端卷积神经网络学习得到连续帧之间相机的自运动。但是获取深度需要昂贵的高线数激光雷达,获取准确的相机运动需要昂贵的高精度gps/imu设备,而且很多已经采集视频的场景没有办法后期再获得准确的稠密深度和位姿作为训练标签,这限制了在新场景的适用性。
相机在运动过程中,单目无监督方法会遇到遮挡、运动物体等问题,运动物体导致两帧匹配的点不满足对极几何约束,遮挡会造成无法正确找到两帧之间的点的正确匹配。先前为了匹配两帧之间的点所提出的光度误差损失函数还会受到光照变化和物体表面非朗伯的影响。在现实场景中,光度一致性假设往往不能得到满足,光照变化和物体表面的反射性质对光度误差有较大的影响。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于遮挡感知和特征金字塔匹配的相机自运动估计方法,可以预测单目图像深度和单目图像序列之间相机的自运动。
为实现上述目的,本发明采用如下技术方案:
一种基于遮挡感知和特征金字塔匹配的相机自运动估计方法,包括以下步骤:
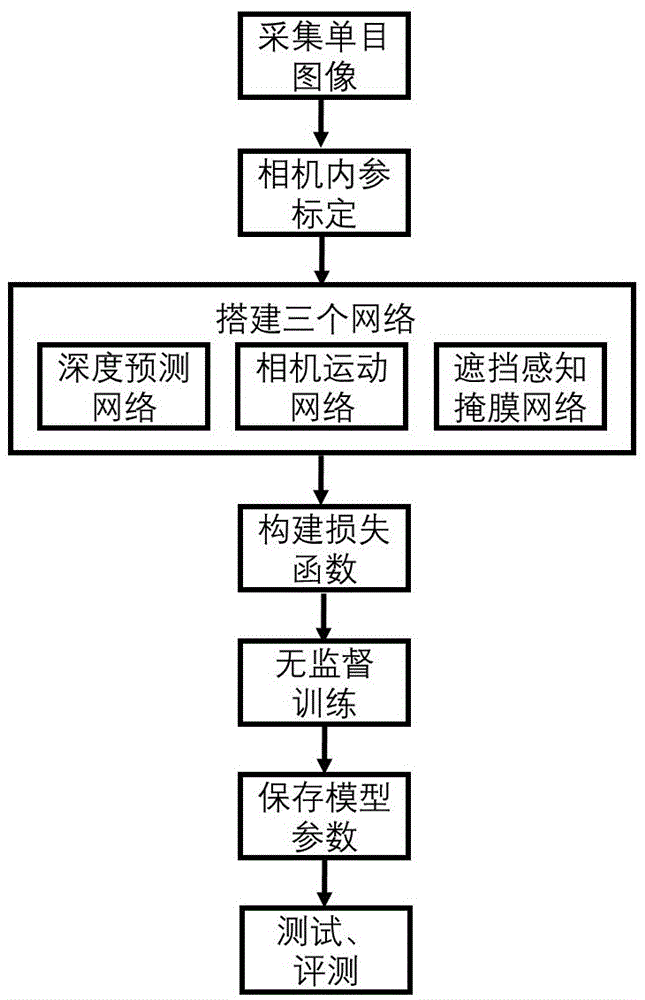
步骤s1:通过单目相机采集图像,并预处理,剔除相机静止时采集的图像,保留相机运动时采集的图像作为图像样本;
步骤s2:标定单目相机的相机内参和畸变系数,并将图像样本按比例分为训练集和验证集;
步骤s3:构建深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型;
步骤s4:根据得到的深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型,构建无监督学习的损失函数;
步骤s5:根据训练集,分别训练深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型,得到训练后的深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型;
步骤s6:根据得到的验证集,分别验证训练后的三个网络模型,并保存三个网络模型的参数,得到优化后的深度预测网络模型和相机运动网络模型;
步骤s7:将待测单帧图像输入优化后的深度预测网络模型,得到对应深度图;将待测多帧图像输入相机运动网络模型,,得到相机的自运动预估结果。
进一步的,所述步骤s1具体为:
步骤s11:将单目相机安装在移动装置上,采集视频;
步骤s12:提取采集的视频序列中的图像,使用帧间差分法剔除相机没有运动时采集的图像;采集的连续帧图像in和in-1分别表示当前帧和前一帧;统计对应像素的差异,如果当前帧和前一帧相同位置像素值in(p)和in-1(p)的差异累计小于阈值,即∑p|in(p)-in-1(p)|<阈值,就剔除in图像,得到图像样本。
进一步的,所述步骤s2具体为:
步骤s21:相机从不同角度不同位置采集标定板的图像;
步骤s22:根据采集的标定板图像,使用opencv自带的张正友标定法标定相机内参和畸变参数,并对步骤s1中所有图像消畸变;
步骤s23:将消畸变后的图像按照100:1划分为训练集和验证集。
进一步的,所述步骤s4具体为:
步骤s41:输入目标图像in到深度预测网络模型,并输出预测的深度dn;
步骤s42:输入目标图像in和附近帧if到相机运动网络模型,并输出预测的相机从in到附近帧if的自运动tt→f,附近帧if为当前帧的前后帧;
步骤s43:输入图像in和附近帧if遮挡感知掩膜网络模型,并输出附近帧if所对应的一致性掩膜mf,通过一致性掩膜mf得到遮挡掩膜vf;
步骤s44:从不同视角观察朗伯的物体表面,表面亮度都是一致的,构建光度误差损失lp;
步骤s45:为了使得深度平滑并且边缘锐利,构建基于图像梯度的深度平滑损失函数
其中
步骤s46:计算掩膜正则项和掩膜平滑损失,其中掩膜正则项为
步骤s47:构建目标帧和附近帧的特征金字塔,通过特征金字塔计算特征金字塔匹配误差损失函数lf;
步骤s48:根据步骤s44、s45、s46和s47构建总的损失函数l=lp+λsls+λmlm+λmslms+λflf,其中λs,λm,λms,λf分别表示深度平滑损失函数、掩膜正则项、掩膜平滑损失函数和特征金字塔损失函数的权重。
进一步的,所述步骤s43具体为:
步骤s431:输入图像in和附近帧if到遮挡感知掩膜网络模型,并输出附近帧if多对应的一致性掩膜mf;
步骤s432:根据得到的一致性掩膜m-1,m1∈mf中提取遮挡掩膜v-1,v1∈vf分别表示像素从目标帧投影到前后帧是否可见,m-1,m1分别表示前后帧中像素满足光度一致性假设的概率;pn为图像上的点,当m-1(pn)>m1(pn)时,表示pn在前一帧比后一帧可见概率更高,令v-1(pn)=1,v1(pn)=0;同样的,当m-1(pn)<m1(pn)时,令v-1(pn)=0,v1(pn)=1;若m-1(pn)=m1(pn),v-1(pt)=0.5,v1(pt)=0.5,表示前后帧都可见。
进一步的,所述步骤s47具体为:
步骤s471:输入目标帧in和附近帧if到同样参数的深度预测网络模型;深度预测网络结构的编码部分卷积产生l=5层特征金字塔,他们对应的通道数为64,64,128,256,512;目标帧的特征金字塔中的特征图用
步骤s472:根据预测的目标图像深度dn和相机自运动tt→f,获得附近帧特征图投影位置
步骤s473:双线性插值合成投影位置
其中
步骤s474:使用余弦相似度衡量目标特征图
本发明与现有技术相比具有以下有益效果:
本发明使用单目摄像头采集的图像进行学习,通过单帧图像预测深度,通过多帧图像估计相机自运动,并且可以克服遮挡,运动物体和光照变化等影响。
附图说明
图1为本发明实施例的结构框图;
图2为本发明实施例中步骤s2中所使用的标定板;
图3为本发明实施例中步骤s3中编码部分resnet-18网络架构表;
图4为本发明实施例中步骤s3中编码部分resnet-18的深度学习网络架构图;
图5为本发明实施例中步骤s3中解码部分网络架构表;
图6为本发明实施例中步骤s4损失函数构建结构图;
图7为本发明实施例中步骤s47特征金字塔损失函数的结构框图;
图8为本发明实施例中步骤s7网络输出结果图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种基于遮挡感知和特征金字塔匹配的相机自运动估计方法,包括以下步骤:
步骤s1:通过单目相机采集图像,并预处理,剔除相机静止时采集的图像,保留相机运动时采集的图像作为图像样本;
步骤s2:标定单目相机的相机内参和畸变系数,并将图像样本按比例分为训练集和验证集;
步骤s3:构建深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型;
步骤s4:根据得到的深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型,构建无监督学习的损失函数;
步骤s5:根据训练集,分别训练深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型,得到训练后的深度预测网络模型,相机运动网络模型和遮挡感知掩膜网络模型;
步骤s6:根据得到的验证集,分别验证训练后的三个网络模型,并保存三个网络模型的参数,得到优化后的深度预测网络模型和相机运动网络模型;
步骤s7:将待测单帧图像输入优化后的深度预测网络模型,得到对应深度图;将待测多帧图像输入相机运动网络模型,,得到相机的自运动预估结果。
在本实施例中,所述步骤s1具体为:
步骤s11:将单目相机安装在移动装置上,采集视频;
步骤s12:提取采集的视频序列中的图像,使用帧间差分法剔除相机没有运动时采集的图像;采集的连续帧图像in和in-1分别表示当前帧和前一帧;统计对应像素的差异,如果当前帧和前一帧相同位置像素值in(p)和in-1(p)的差异累计小于阈值,即∑p|in(p)-in-1(p)|<阈值,就剔除in图像,得到图像样本。
在本实施例中,所述步骤s2具体为:
步骤s21:相机从不同角度不同位置采集标定板的图像;
步骤s22:根据采集的标定板图像,使用opencv自带的张正友标定法标定相机内参和畸变参数,并对步骤s1中所有图像消畸变;
步骤s23:将消畸变后的图像按照100:1划分为训练集和验证集。
在本实施例中,所述步骤s3,具体包括以下步骤:
步骤s31:深度预测网络和遮挡感知掩膜网络,他们的结构相同,结构都为编码-解码架构,并使用跳跃连接将解码部分浅层信息传递给编码部分;首先搭建编码部分;
步骤s32:再搭建解码部分。
所述步骤s31所涉及的深度预测网络和遮挡感知掩膜网络的编码部分如下:
搭建resnet-18的深度学习卷积神经网络架构作为编码部分,输入rgb图像,通道数为3,resnet-18的卷积神经网络结构如图3所示;
输入层:输入一张rgb图像;
conv1:本实施例中第一个卷积层的尺寸是7×7,卷积深度为64,设定步长为2,采用单位为2的0填充方式;
maxpool:本实施例中设定第一个池化步长为2,池化尺寸为3×3,池化方式为最大池化;
conv2_x:如图4所示,本实施例中resnet-18卷积神经网络的残差连接部分,x是这一层残差块的输入,也称作f(x)为残差,x为输入值,f(x)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,f(x)加入了这一层输入值x,然后再进行激活后输出。在第二层输出值激活前加入x,这条路径称作shortcut连接。f(x)如下式所示:
f(x)=h(x)-x
conv3_x、conv4_x、conv5_x与conv2_x的结构相似,差别就是输入x的向量尺寸和各个卷积层的卷积深度不同;
所述步骤s32所涉及的深度预测网络和遮挡感知掩膜网络的解码部分如下:
解码部分的卷积神经网络结构如图5所示,输入为步骤s31得到的特征,由conv1、conv2_x,conv3_x,conv4_x,conv5_x输出。
upconv5:本实施例中卷积层的尺寸是3×3,卷积深度为256,设定步长为1,采用单位为1的0填充方式,最后采用elu激活。upconv4,upconv3,upconv2,upconv1与upconv5参数相同除了通道数不一样,通道数分别为128,64,32,16。
iconv5:本实施例中输入为upconv5输出的上采样和步骤s31中conv4_x输出的特征图,卷积层的尺寸是3×3,卷积深度为256,设定步长为1,采用单位为1的0填充方式,最后采用elu激活。iconv4,iconv3,iconv2,iconv1与iconv5参数相同,除了通道数不一样,通道数分别为128,64,32,16。
disp4:本实施例中输入为iconv5输出,卷积层的尺寸是3×3,卷积深度为256,设定步长为1,采用单位为1的0填充方式,最后采用sigmoid激活。disp3,disp2,disp1与disp4相同。
所述步骤s3所涉及的相机运动网络如下:
相机编码网络部分与所述步骤s31编码部分结构相同。
所述步骤s3所涉及的相机运动网络解码部分如下:
相机运动网络解码部分解码部分输入为相机编码网络部分得到的特征,由conv_1、conv2_x,conv3_x,conv4_x输出。
conv_1:本实施例中卷积层的尺寸是1×1,卷积深度为256,设定步长为1,使用relu激活;
conv_2:本实施例中卷积层的尺寸是3×3,卷积深度为256,设定步长为1,采用单位为1的0填充方式,使用relu激活;
conv_3:本实施例中卷积层的尺寸是3×3,卷积深度为256,设定步长为1,采用单位为1的0填充方式,使用relu激活;
conv_4:本实施例中卷积层的尺寸是1×1,卷积深度为6,设定步长为1,变形为6*1输出;
在本实施例中,所述步骤s4具体为:
步骤s41:输入目标图像in到深度预测网络模型,并输出预测的深度dn;
步骤s42:输入目标图像in和附近帧if到相机运动网络模型,并输出预测的相机从in到附近帧if的自运动tt→f,附近帧if为当前帧的前后帧;
步骤s43:输入图像in和附近帧if遮挡感知掩膜网络模型,并输出附近帧if所对应的一致性掩膜mf,通过一致性掩膜mf得到遮挡掩膜vf;
步骤s44:从不同视角观察朗伯的物体表面,表面亮度都是一致的,构建光度误差损失lp;
步骤s45:为了使得深度平滑并且边缘锐利,构建基于图像梯度的深度平滑损失函数
其中
步骤s46:计算掩膜正则项和掩膜平滑损失,其中掩膜正则项为
步骤s47:构建目标帧和附近帧的特征金字塔,通过特征金字塔计算特征金字塔匹配误差损失函数lf;
步骤s48:根据步骤s44、s45、s46和s47构建总的损失函数l=lp+λsls+λmlm+λmslms+λflf,其中λs,λm,λms,λf分别表示深度平滑损失函数、掩膜正则项、掩膜平滑损失函数和特征金字塔损失函数的权重。
在本实施例中,所述步骤s43具体为:
步骤s431:输入图像in和附近帧if到遮挡感知掩膜网络模型,并输出附近帧if多对应的一致性掩膜mf;
步骤s432:根据得到的一致性掩膜m-1,m1∈mf中提取遮挡掩膜v-1,v1∈vf分别表示像素从目标帧投影到前后帧是否可见,m-1,m1分别表示前后帧中像素满足光度一致性假设的概率;pn为图像上的点,当m-1(pn)>m1(pn)时,表示pn在前一帧比后一帧可见概率更高,令v-1(pn)=1,v1(pn)=0;同样的,当m-1(pn)<m1(pn)时,令v-1(pn)=0,v1(pn)=1;若m-1(pn)=m1(pn),v-1(pt)=0.5,v1(pt)=0.5,表示前后帧都可见。
在本实施例中,所述步骤s47具体为:
步骤s471:输入目标帧in和附近帧if到同样参数的深度预测网络模型;深度预测网络结构的编码部分卷积产生l=5层特征金字塔,他们对应的通道数为64,64,128,256,512;目标帧的特征金字塔中的特征图用
步骤s472:根据预测的目标图像深度dn和相机自运动tt→f,获得附近帧特征图投影位置
步骤s473:双线性插值合成投影位置
其中
步骤s474:使用余弦相似度衡量目标特征图
在本实施例中,所述步骤s6具体包括以下步骤:
步骤s61:在本实施例中,保存下模型训练过程中每个epoch卷积神经网络参数;
步骤s62:在本实施例中,使用验证集对步骤s61中保存的每个卷积神经网络参数验证,留下结果最好的作为最终模型参数。
在本实施例中,所述步骤s7具体包括以下步骤:
步骤s71:将步骤2中得到的测试集数据输入步骤6训练好的深度神经网络中,分别将单帧图像输入到深度预测网络,将3帧连续图像输入相机运动网络,得到对应深度图和相机自运动。得到的深度图样例如图8所示。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!