一种基于BERT并融合可区分属性特征的刑事案件刑期预测方法与流程
本发明涉及一种基于bert并融合可区分属性特征的刑事案件刑期预测方法,属于自然语言处理和深度学习技术领域。
背景技术:
近年来,随着大数据的蓬勃发展,人工智能的研究得到突破性的进展,并且成为各个领域所关注的焦点,其引领各个领域朝着智能化方向发展,如:无人驾驶汽车,图像识别,机器翻译,问答系统,文本分类,情感分析等任务的突破创新都离不开人工智能技术,这为人们的生活带来极大方便。当然,司法领域也不例外,随着智慧法院这一名词的诞生及其裁判文书的大量公开,使用自然语言处理技术对其文本进行挖掘分析、预测等逐渐成为关注点。
刑事案件预测作为司法领域不可或缺的一部分,主要包括罪名预测,法条预测,刑期预测等,其旨在根据刑事案件中的案例事实描述来预测出判决结果。而刑期预测作为刑事案件预测中的关键子任务之一,在法律助手系统中起着重要作用,并且随着人工智能的火热在现实生活中得到广大人民的喜爱。刑期预测的出现,一方面可以为不了解裁判过程、不懂法律知识的人们提供有效的咨询;另一方面还为法官提供判案参考,不至于因为某些相似案件而干扰他们判断,从而减轻他们的工作量,提高审判的效率。
技术实现要素:
本发明提供了一种基于bert并融合可区分属性特征的刑事案件刑期预测方法,以用于进行刑期预测。
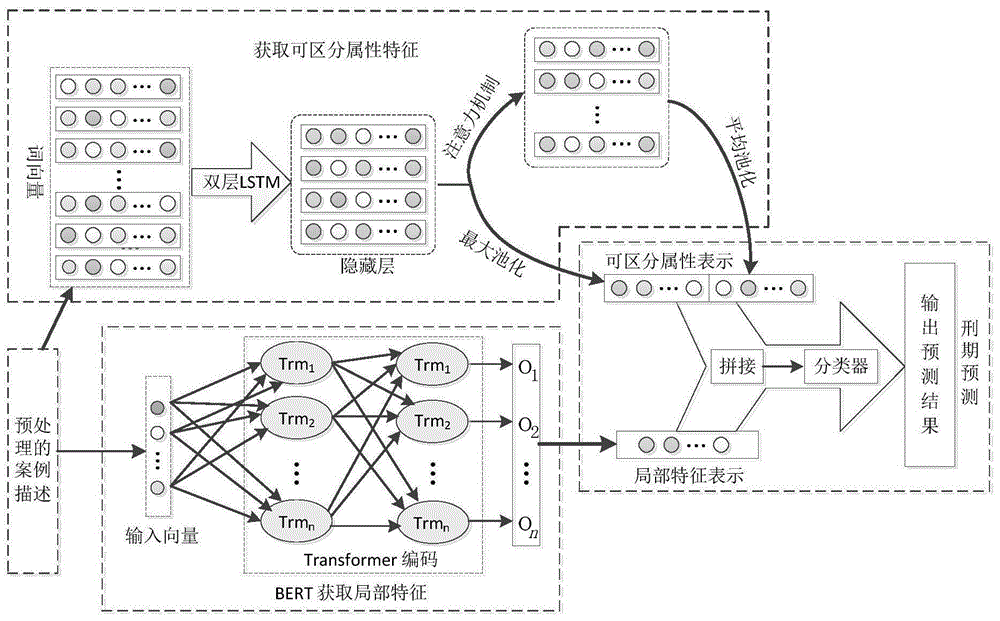
本发明的技术方案是:一种基于bert并融合可区分属性特征的刑事案件刑期预测方法,所述方法的具体步骤如下:
step1、对语料抽取实验所需案例描述和标签,作为实验数据;并对数据进行清洗、预处理、词向量预训练操作;
step2、利用带注意力机制的双层lstm从预训练的案例描述中获得可区分属性特征;
step3、对仅做清洗的实验数据通过bert模型获得局部重要信息特征;
step4、将step2步骤中获得的可区分属性特征与step3步骤获得的局部重要信息特征进行拼接,然后在bert模型的下游通过softmax分类器进而得到刑期预测的模型。
所述step1具体为:
step1.1、从语料中抽取刑期预测所需的案例描述和标签作为实验数据;其中每一条实验数据由刑期标签及其对应案例描述组成;
step1.2、对抽取的案例描述数据进行去重和无用数据的数据清洗,从而得到清洗后的实验数据;
step1.3、把step1.2步骤中获得的清洗后的实验数据中的案例描述做预处理;
step1.4、采用skip-gram模型对预处理后的案例描述进行词向量预训练,得到案例描述中每个词的向量表示;其中,定义每条案例描述所对应词序列是x={x1,x2,…,xn},x为案例描述的词序列,xn表示第n个词;经过预训练后其对应的词向量为e=[e1,e2,…,en]∈rn×d,e表示每条案例描述的向量表示,en表示案例描述中第n个词的词向量,n表示案例描述中词的个数,d表示每个词向量的维数;r表示实数域。
所述预处理具体为:采用python第三方库中的工具包jieba完成,包括中文分词、去停用词操作。
所述step2具体为:
step2.1、将预训练的案例描述中每个词所对应的词向量作为lstm的输入;经过双层lstm后,得到案例描述中所有词的隐藏状态表示h=[h1,h2,…,hn],hn表示第n个词的隐层状态表示;
step2.2、将step2.1步骤得到的案例描述中所有词的隐层状态表示h经过最大池化层,进而得到融合重要语义信息的向量表示
step2.3、将step2.1步骤得到的案例描述中所有词的隐层状态表示h作为attention的输入,来获取对案例描述有重要意义的词表示s=[s1,s2,…,sn];sn表示对案例描述有重要意义的词表示的第n个元素值;
step2.4、将step2.3步骤得到的重要意义的词表示s通过平均池化从而得到关键信息表示y=(y1,y2,…,ym,…,yd),ym=mean(s1m,s2m,…,sim,…,snm),m∈[1,d],ym表示关键信息表示的第m个元素值,sim表示重要意义词表示si中的第m个元素值,i∈[1,n],mean表示平均;
step2.5、将step2.2步骤得到的重要语义信息向量与step2.4步骤得到的关键信息向量进行拼接操作,最后得到可区分属性特征的向量表示a。
所述step3具体为:
step3.1、将仅做清洗的实验数据作为bert第一个编码层的输入,通过bert对实验数据中的每条案例描述的头尾分别加上cls和sep标签,并且从0开始给每个刑期标签类进行编号,用编号替代刑期标签的文字表达;将加标签的每条案例描述通过嵌入层进而表示成向量的形式,然后分别与不同权重矩阵相乘得到第i个自注意力机制所对应的qi、ki、vi三个不同的矩阵向量;其中qi、ki、vi分别表示为第i个自注意力机制的查询矩阵、键矩阵、值矩阵,i表示自注意力机制的个数;其中,bert模型中含有12个编码层,每层有12个自注意力机制;
step3.2、将通过step3.1步骤得到的向量qi、ki进行计算评分,并通过softmax进行标准化,获得案例描述中具体的某个词对其他词重要度;然后为了提取重要的局部信息,通过step3.1步骤得到的值矩阵vi将不相关的信息淹没,从而得到第i个自注意力机制的输出表示;
step3.3、将step3.2步骤中通过所有自注意力机制获得的输出表示矩阵进行拼接,然后通过全连接层得到每个编码层的输出,然后将其输出与bert的输入进行求和,最后进行归一化操作;
step3.4、将step3.3步骤的输出经过前馈神经网络层,并进行归一化处理后的输出作为下一编码层的输入;
step3.5、除去最后一个编码层,其余每个编码层都重复以上step3.1-step3.4四个步骤,到最后一编码层时,在step3.3步骤结束后经过pooler层提取出每个案例描述的第一个词所对应的向量表示,即标记cls所对应的向量表示;
step3.6、将step3.5步骤得到的向量表示进行全连接后得到融合了局部重要信息特征的向量表示b。
本发明的有益效果是:与现有的刑期预测方法相比,考虑了刑事案例中局部信息的重要性,而bert可以很好的对重要信息重点关注并充分学习吸收,从而高效获取局部特征,同时,bert中输入的初始数据为经过清洗的数据,该考虑了实验数据质量对后面实验结果的影响,并且bert泛化能力强,可以提高刑期预测的准确率;与现有的刑期预测方法相比,考虑了罪名和法条相同,而刑期不同的案例情况,通过子任务之间的依赖关系并不能有效的预测刑期,进而提出通过可区分属性来辅助刑期预测,并且在获取可区分属性特征时,为了更好的获取案例描述中的语义信息,考虑使用双层lstm;通过将局部信息特征与可区分属性特征进行融合,可以有效的解决罪名和法条相同,而刑期不同的案例情况,通过子任务之间的依赖关系不能有效的预测刑期的问题,达到预测的效果。
附图说明
图1为本发明中的总体框架图;
图2为本发明中获取关键信息的模型图;
图3为本发明中获取局部有用信息的模型图。
具体实施方式
实施例1:如图1-3所示,一种基于bert并融合可区分属性特征的刑事案件刑期预测方法,所述方法的具体步骤如下:
step1、从cail2018大赛中获取到语料,对语料抽取实验所需案例描述和标签,作为实验数据;并对数据进行清洗、预处理、词向量预训练操作;
step2、利用带注意力机制的双层lstm从预训练的案例描述中获得可区分属性特征;
step3、对仅做清洗的实验数据通过bert模型获得局部重要信息特征;
step4、将step2步骤中获得的可区分属性特征与step3步骤获得的局部重要信息特征进行拼接,然后在bert模型的下游通过softmax分类器进而得到刑期预测的模型。
进一步地,可以设置所述step1具体为:
step1.1、从语料中抽取刑期预测所需的案例描述和标签作为实验数据;其中每一条实验数据由刑期标签及其对应案例描述组成;
如一条实验数据:有期徒刑0-6个月2015年3月一天的凌晨,被告人刘某某在攀枝花市东区炳草岗大梯道爵士网吧内,趁罗某、谭某、范某某睡着之机,将罗某的三星note3型手机、谭某的三星8160型手机、将范某某的黑色三星9082型手机盗走。经攀枝花市东区物价局价格认证中心鉴定,三星8160手机价值人民币400元,三星note3手机价值人民币1,680元、三星9082型手机价值人民币500元。
step1.2、由于step1.1抽取的案例描述数据中有重复数据和无用数据,对抽取的案例描述数据进行去重和无用数据的数据清洗,从而得到清洗后的实验数据;(如假设有10条实验数据,如果10条实验数据中存在2条案例描述数据相同的,则去重;如果存在1条无用数据(即案例描述中给出了作案时间、地点、动机的为有用数据,其余为无用数据;或者也可以根据经验对无用数据的判断进行调整),则去除)
step1.3、把step1.2步骤中获得的清洗后的实验数据中的案例描述做预处理;
step1.4、选择google公司的开源工具包word2vec,采用skip-gram模型对预处理后的案例描述进行词向量预训练,得到案例描述中每个词的向量表示;其中,定义每条案例描述所对应词序列是x={x1,x2,…,xn},x为案例描述的词序列,xn表示第n个词;经过预训练后其对应的词向量为e=[e1,e2,…,et,…,en]∈rn×d,e表示每条案例描述的向量表示,en表示案例描述中第n个词的词向量,n表示案例描述中词的个数,d表示每个词向量的维数;r表示实数域。
进一步地,可以设置所述预处理具体为:采用python第三方库中的工具包jieba完成,包括中文分词、去停用词操作。
进一步地,可以设置所述step2具体为:
step2.1、将step1.4步骤中预训练的案例描述中每个词所对应的词向量作为lstm的输入;经过双层lstm后,得到案例描述中所有词的隐藏状态表示h=[h1,h2,…,hn],hn表示第n个词的隐层状态表示;
step2.2、将step2.1步骤得到的案例描述中所有词的隐层状态表示h经过最大池化层,进而得到融合重要语义信息的向量表示
step2.3、将step2.1步骤得到的案例描述中所有词的隐层状态表示h作为attention的输入,来获取对案例描述有重要意义的词表示s=[s1,s2,…,sn];sn表示对案例描述有重要意义的词表示的第n个元素值;
step2.4、将step2.3步骤得到的重要意义的词表示s通过平均池化从而得到关键信息表示y=(y1,y2,…,ym,…,yd),ym=mean(s1m,s2m,…,sim,…,snm),m∈[1,d],ym表示关键信息表示的第m个元素值,sim表示重要意义词表示si中的第m个元素值,i∈[1,n],mean表示平均;
step2.5、将step2.2步骤得到的重要语义信息向量与step2.4步骤得到的关键信息向量进行拼接操作,最后得到可区分属性特征的向量表示a。
进一步地,可以设置所述step3具体为:
step3.1、将step1.2步骤处理完的仅做清洗的实验数据作为bert第一个编码层的输入,通过bert对实验数据中的每条案例描述的头尾分别加上cls和sep标签,并且从0开始给每个刑期标签类进行编号,用编号替代刑期标签的文字表达;将加标签的每条案例描述通过嵌入层进而表示成向量的形式,然后分别与不同权重矩阵相乘得到第i个自注意力机制所对应的qi、ki、vi三个不同的矩阵向量;其中qi、ki、vi分别表示为第i个自注意力机制的查询矩阵、键矩阵、值矩阵,i表示自注意力机制的个数;其中,bert模型中含有12个编码层,每层有12个自注意力机制;
step3.2、将通过step3.1步骤得到的向量qi、ki进行计算评分,并通过softmax进行标准化,获得案例描述中具体的某个词对其他词重要度;然后为了提取重要的局部信息,通过step3.1步骤得到的值矩阵vi将不相关的信息淹没,从而得到第i个自注意力机制的输出表示;
step3.3、将step3.2步骤中通过所有自注意力机制获得的输出表示矩阵进行拼接,然后通过全连接层得到每个编码层的输出,然后将其输出与bert的输入进行求和,最后进行归一化操作;
step3.4、将step3.3步骤的输出经过前馈神经网络层,并进行归一化处理后的输出作为下一编码层的输入;
step3.5、除去最后一个编码层,其余每个编码层都重复以上step3.1-step3.4四个步骤,到最后一编码层时,在step3.3步骤结束后经过pooler层提取出每个案例描述的第一个词所对应的向量表示,即标记cls所对应的向量表示;
step3.6、将step3.5步骤得到的向量表示进行全连接后得到融合了局部重要信息特征的向量表示b。
所述步骤step2.1的具体步骤为:
step2.1.1、将案例描述中每个词所对应的词向量et作为lstm的输入,通过其遗忘门操作,将细胞状态中不重要的信息遗忘掉,计算公式为:
ft=σ(wf[ht-1,et]+bf)(1)
step2.1.2、通过输入门决定新信息是否要输入到细胞状态中,该步骤由输入门控和tanh层构成,计算公式为:
it=σ(wi[ht-1,et]+bi)(2)
step2.1.3、根据step2.1.1步骤和step2.1.2步骤得到的输出来更新旧细胞状态,从而将有用的新信息添加到细胞状态中,计算公式为:
step2.1.4、通过输出门确定输出的信息,并且根据step2.1.3步骤的结果得到第一层lstm最终的隐层状态h,计算公式为:
ot=σ(wo[ht-1,et]+bo)(5)
ht=ot*tanh(ct)(6)
step2.1.5、最终得到的隐层状态h作为第二层lstm的输入,同理经过以上四个步骤最终得到案例描述中所有词的隐藏状态表示h=[h1,h2,…,hn](n代表每个案例描述词的个数);
以上步骤中,ft表示lstm在第t个词时刻的遗忘状态,它通过激活函数σ以一定的概率来确定上一层隐藏细胞状态的信息是否要删除,ht-1为第t-1个词的隐藏状态,et代表第t个词的词向量;it为输入第t个词时刻的状态表示,其与候选细胞状态
所述步骤step2.3的具体步骤为:
step2.3.1、根据step2.1步骤中得到的案例描述中所有词的隐层状态表示h,计算每个词的注意力权重系数aii,计算公式为:
eii=tanh(wahj+ba)tui(7)
其中,eij表示对案例描述第j个词隐藏状态和第i个词上下文向量进行线性变换,hj是编码器案例描述中第j个词隐藏状态表示,ui为第i个词上下文向量表示,wa是所有词共享的权重矩阵,ba是偏置矩阵。
step2.3.2、根据step2.3.1与各词的隐状态进行加权求和,从而得到融合重要意义词的表示,计算公式为:
其中,si表示第i个重要意义词的向量表示,aij表示当前词i对第j个词的注意力权重系数,hj表示第j个词的隐藏状态表示;
所述步骤step3.1的具体步骤为:
step3.1.1、根据step3.1的案例描述的输入,通过计算分别得到qi,ki,vi向量,其计算公式为:
qi=wiq·e;ki=wik·e(i∈[0,11]);vi=wiv·e(10)
其中,qi,ki,vi分别表示为第i个注意力机制头的查询矩阵,键矩阵和值矩阵,wiq,wik,wiv分别为第i个头对应的自注意力机制通过学习得到的三个不同的权重矩阵,e为案例描述中的词向量矩阵。
所述步骤step3.2的具体步骤为:
step3.2.1、首先根据step3.1得到的qi,ki进行计算评分,并进行归一化处理,从而得到具体的某个词对输入文本中的其他词的重要性,计算公式为:
其中,sore表示当前某个词对其他词的影响值打分结果,qi,ki,vi由步骤3.1.1所得,
step3.2.2、为了提取重要的局部信息,通过step3.1步骤得到的向量vi将不相关的信息淹没,从而得到自注意力机制得输出,计算公式为:
zi=sore·vi(12)
其中,vi由步骤3.1.1所得,zi表示通过第i个注意力机制头得到的案例描述重要信息。
所述步骤step3.3的具体步骤为:
step3.3.1、将多头自注意力机制经过step3.2.2分别得到的输出zi(i∈[0,11])拼接通过全连接层得到z;
step3.3.2、根据step3.3.1得到的z与bert的输入e进行求和操作,即
step3.3.3、对step3.3.2得到的
在这里,
所述步骤step4的具体步骤为:
将步骤step2与step3的结果进行拼接最终得到融合局部信息和可区分特征的案例描述向量通过softmax分类器进行训练,从而达到刑期预测目的,其公式为:
e=connect(a,b)(15)
pre=softmax(e)(16)
在这里,connect函数表示拼接操作,向量e表示融合局部信息和可区分特征的案例描述向量,长度为3d,其第i个元素的softmax值为
为了验证本发明对刑事案件刑期预测的效果,将采用统一的评价标准:准确率(acc)、宏精确率(mp)、宏召回率(mr)以及f1值作为本实验的评价指标:
本发明为了验证该发明的有效性、可行性设计以下四组实验进行验证:
实验一:本发明为了给后面实验提供更有效的预训练向量,在cail2018所有数据集上分别选择窗口大小为3,5,7,向量维度大小分别取100维,200维,300维进行多组实验对比,表1所示为不同窗口及其不同维度对本发明实验的影响。
表1窗口大小及其维度对双层lstm+attention模型性能影响
由于本发明使用word2vec训练的词向量是为获取可区分属性特征提供的,使用的模型是双层lstm+attention模型,因此本实验通过该模型中来测试不同窗口大小及其向量维度得到的词向量对该模型的影响,从而选择最适合该模型的词向量。从上表整体来看不同窗口及其维度大小对模型影响差别不大,其主要还是受语料质量的影响大,但是窗口和维度过高过低时效果都不理想,当窗口大小为5,向量维度200维组合时模型获取可区分属性效果有所提升,达到58.8%,因此本发明在训练词向量时窗口大小选择为5,向量维度选择200维。分析原因主要是窗口或维度过低时捕获到的信息不够全面,而过高时又往往会捕获到干扰的信息,所以导致其过高过低都不太理想。
实验二:为了验证可区分属性特征对本发明刑期预测的影响,本发明使用cail2018数据集作为测试集,通过是否融合该特征做了对比实验,实验结果如表2所示:
表2特征组合实验结果
在刑事案件案例描述测试集上通过不同特征进行实验时,由表2中实验结果表明:只考虑局部信息进行刑期预测的效果相比并不理想,主要原因是案例描述数据中存在相似案例但刑期判决不同的案例,比如盗窃案,案例中的作案地点性质,金额等影响刑期判决,然而只通过一些潜在表面的局部语义信息是不能起到很好的预测效果的,这便需要一些可区分的属性特征来区别类似案例,从而提高预测的效果,因此,当只用可区分属性信息特征进行刑期预测实验时比局部信息预测时有些许提升,尽管提升不太大,足以证明可区分属性对于相似案例是起一定作用的。最后本发明综合考虑将两特征融合实验,预测结果在f1上比单特征提升大约0.6%-2.1%,固说明本发明使用的方法综合性能较好。
实验三:针对子任务之间罪名和法条一致,刑期不同的案例问题,为了验证本发明方法中的特征比刑期与罪名、法条等子任务之间的依赖关系有利于提高预测的准确性,使用cail2018数据集作为测试集,实验结果如表3所示:
表3本发明方法与子任务依赖方法对比实验结果
由表3可以看出,在刑事案件案例描述的测试集上,本发明方法相比topjudge[1]和fla[2]通过子任务之间的依赖关系,即利用罪名和法条来辅助刑期预测的方法有所提升。分析原因主要是针对罪名和法条一致而刑期不同的案例情况时,通过子任务之间的依赖关系并不能对刑期预测起到辅助作用,而本发明方法考虑到此类案例的情况,并且考虑案例描述中局部案件要素信息的重要性,因此相比效果有所提升。
实验四:为了验证本发明方法的有效性,在cail2018测试集上,将本发明方法与cail2018现有几种刑期预测方法中进行实验比较,实验结果如表4所示:
表4本发明方法与现有方法对比实验
在刑事案件案例描述测试集中,通过将以上基线方法进行复现,且参数设置与本发明方法一致。通过实验表明,本发明提出的方法与传统机器学习方法进行刑期预测方法相比f1值有明显提升,且本发明具有较好的泛化能力。与cnn和harnn方法相比,本发明方法在f1值上有所提升,分析主要原因是cnn方法通过多卷积层对案例描述进行编码和分类时时从全局获取了案例描述的上下文语义特征,harnn方法在获取案例描述重要句子信息时同样通过全局出发获取的,并没有很好的考虑局部案件要素信息及其罪名法条一致而刑期不同的案例情况;本发明通过创造性的劳动,提出局部顺序信息很重要,而发现gcn针对的是全局词共生,对局部信息不敏感,因此本申请采用了bert,通过该模型可以很好的获取局部案件要素信息,并且其不需进行预处理,分词等操作,简洁方便,进而证明了本发明方法的有效性能。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!