一种结合标签构建与社区关系规避的专家推荐方法与流程
本发明属于数据挖掘技术领域,具体涉及一种结合标签构建与社区关系规避的专家推荐方法。
背景技术:
专家是科技评价或评审工作的主体,专家库中所选取的专家的个人素养及学术水平直接关系到科技评价或评审活动的质量,并最终影响科技咨询与决策工作的质量与科学性。因此,建设科学的专家库以及挑选合适的专家进行科技评价或评审至关重要。然而,目前我国存在专家库信息不完整、更新不及时等问题。同时在评审专家挑选时存在效率低以及违规等问题,主要表现在以下两个方面。(1)目前专家库中的专家主要来源于高等院校、科研院、各类科技政府机构所等机构,数据信息主要是由这些机构中的专家个人填写,极大地影响了专家数据库中专家信息的完整性、可靠性、及时性。从而导致专家数据库中专家信息尤其是学术研究信息的片面性、滞后性,无法准确反映专家实际工作情况。(2)目前在专家挑选时主要凭借直觉、印象、资历、名气、地位等“软”因素进行主观判断。存在未严格遵循项目回避、单位回避、特别要求的回避等原则,从专家库中抽取专家;缺乏选择高水平、高责任心、无利益冲突的评审专家的科学依据。
这不仅大大降低挑选专家的工作效率,还容易存在覆盖面不全、人工干预多、专家学者对科技咨询内容了解程度不一致等问题;在实际评审工作中,也频繁地出现由于人际关系网或个人名人效应造成的领导项目、人情项目、照顾平衡项目等不良现象。这一切都严重影响了科技评价或评审的科学性、公正性、独立性以及客观性。
技术实现要素:
本发明针对目前科技评价或者评审工作时挑选专家存在的问题,提出了一种结合标签构建与社区关系规避的专家推荐方法。用以提高科技评价或评审时专家挑选的工作效率;提高科技评价或评审的科学性、公正性、独立性以及客观性。
为实现上述目的,本发明采用的技术方案为:一种结合标签构建与社区关系规避的专家推荐方法,包括以下步骤。
步骤1:对科技领域的专利数据库和论文数据库进行采集,提取出论文数据库中的作者以及专利数据库中的发明人,形成专家列表。然后对专家的属性信息补全,根据属性信息完成专家属性抽取和领域标签抽取。根据专家之间的关系形成科技领域的专家库。最后根据专家发表的论文数、论文影响因子、论文被引数、h指数和专利数等维度进行建模,计算专家在相关领域的影响力。
步骤2:根据科技评审资料提取相关的科技领域,然后根据专家的领域标签过滤匹配度高的专家集合s1。同时提取科技评审资料中相关的申请人信息,作为需要直接规避的专家。然后根据社区发现算法以及专家之间的复杂关系,得到专家的社区关系。根据需要直接规避的专家及其关系比较紧密的专家社区关系,得到需要规避的专家集合s2。然后将推荐的专家集合s1中过滤掉需要规避的专家集合s2得到初步推荐的专家,即s=s1-s2。
步骤3:得到初步推荐专家后按照影响力与其他限制条件进行二次过滤,并按照相关领域影响力排序得到最终的专家推荐列表。
需要规避的专家集合s2的算法执行过程如下。
(1)给定网络g(v,e),其中v为点集,e为边集,将网络g中的每条边初始一个社区,即p0=(c1,c2,…,c|e|)。
(2)找出最相似的属于不同社区的两条边eik和ejk,并将这两条边所属的社区进行合并。其中相似度按照如下公式计算:
其中n+(i)={x|d(i,j)≤1},d(i,j)表示节点i和x之间的最小距离。即n+(i)包含了节点i本身和i的邻居节点。
(3)重复执行(2)直到网络中所有的边被分到一个社区中。在此过程中,将每次迭代的结果存储在一个树状图中。
(4)在(3)得到的树状图中找出划分密度(partitiondensity)最大的那层社区划分结果作为最终社区结构。其中划分密度d定义为:
其中mc和nc分别表示社区c包含边的条数和节点的个数。
(5)将单链接层次聚类的结果转化为节点的集合,形成最终的专家的社区关系结构。
(6)根据需要直接规避的专家及其关系比较紧密的专家社区关系,得到需要规避的专家集合s2。
步骤1中专家领域标签抽取过程如下。
(1)根据领域标签内容,对采集论文的分类进行匹配,并对采集的论文信息进行检索,根据匹配的论文数据建立领域标签论文集合,形成全部论文领域标签数据集,作为训练样本。
(2)使用fasttext算法对数据进行训练,形成全领域标签分类模型。
(3)基于上述步骤训练好的模型,对于专家的论文进行预测打分,形成专家的领域标签,一个专家可以命中多个标签,涉及多个不同的领域。
步骤1中构建专家库是指完成科技领域专家库的构建。需要根据专家的论文专利合作关系、同事关系和校友关系等复杂的人际关系,对专家关系进行连接。其中专家之间共同发表论文或者专利则形成合作关系;专家所属机构相同则形成同事关系;专家的教育背景存在时间与地点吻合度较高的则形成校友关系。
权5:步骤1中还包括专家评估:根据专家发表的论文数、论文影响因子、论文被引数、h指数和专利数等维度进行建模,计算专家在相关领域的影响力。其中过程如下。
(1)对专家数据清洗与转换,对论文数、论文影响因子、论文被引数、h指数、专利数等维度缺失数据进行处理。由于数据各个维度之间的数值往往相差很大,因此有必要对整体数据进行归一化处理,也就是将它们都映射到一个指定的数值区间,这样就不会对后续的数据分析产生重大影响。
(2)建立数学模型,计算专家领域影响力。其中x表示专家在某领域的论文数x1、论文影响因子x2、论文被引数x3、h指数x4和专利数xn等维度指标组成的向量集,t表示不同维度的加权集,则数学模型y=tx计算得到某领域的影响力。其中:数学模型y=t1*x1=t2*x2+...+tn*xn。
权6:步骤3中获得最终专家推荐列表的具体步骤如下。
(1)得到初步推荐专家后,根据专家影响力将相关领域影响力较弱的专家进行过滤。同时也可以根据用户指定的条件进行二次过滤。
(2)在步骤(1)中根据专家评估模型计算出了专家在相关领域的影响力,此时根据领域影响力进行排序,将影响力高的排序到推荐专家列表前列。
(3)经过一系列分析之后,得到最终的专家推荐列表。在合理规避有合作关系、同事关系、项目组关系等关系转件后,推荐高水平、高影响力和高责任心的专家。
本申请的技术效果:本发明结合专家之间的同事关系、合作关系、校友关系等等复杂关系,合理的进行专家规避,根据专家的领域标签以及影响力推荐高水平、高影响力、高责任心的专家。有效的提高了专家挑选的工作效率,同时提高了科技评价或评审的科学性、公正性、独立性以及客观性。
相对于目前我国科技领域的信息管理技术相对落后,严重影响科技评审、专家评价的公正性、客观性、科学性,信息获取具有滞后性、片面性。本发明专家库的建设以及推荐服务以解决科技领域的信息服务问题为目标,为各级政府、科研院所、企业等提供更加及时、有效、全面、准确、可定制的信息服务,可节省在进行项目评审、科技评价等日常工作的人力成本和时间成本。
相对于目前在科技评价或评审时专家挑选存在覆盖面不全、人工干预多、专家学者对科技咨询内容了解程度不一致等问题。在实际评审工作中,也频繁地出现由于人际关系网或个人名人效应造成的领导项目、人情项目、照顾平衡项目等不良现象。本发明通过建设科技领域专家库,然后基于链接密度聚类的重叠社区发现算法,合理的规避同单位同项目等要求的专家,推荐高水平、高影响力、高责任心的专家,提高了科技评价或评审的科学性、公正性、独立性以及客观性。
附图说明
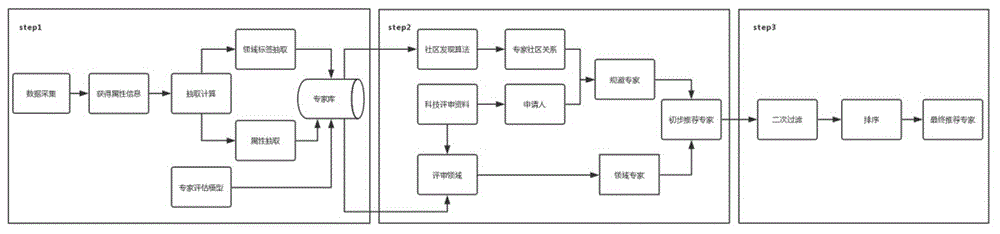
图1是本发明的整体流程图。
图2是fasttext模型架构图。
图3是本发明中建立科技领域专家库建立的流程图。
图4是基于链接的重叠社区发现示意图。
图5是基于链接的重叠社区发现算法的流程图。
图6是本发明中建立初步推荐专家的流程图。
图7是本发明中建立最终推荐专家的流程图。
具体实施方式
本发明针对目前科技评价或者评审工作时挑选专家存在的问题,提出了一种结合标签构建与社区关系规避的专家推荐方法。结合专家之间的同事关系、合作关系、校友关系等等复杂关系,合理的进行专家规避,根据专家的领域标签以及影响力推荐高水平、高影响力、高责任心的专家。有效的提高了专家挑选的工作效率,同时提高了科技评价或评审的科学性、公正性、独立性以及客观性。
该专家推荐方法的整体流程图如图1所示,包括以下步骤1-3。
步骤1:对科技领域的专利数据库和论文数据库进行采集,提取出论文数据库中的作者以及专利数据库中的发明人,形成专家列表;然后对专家的属性信息补全,根据属性信息完成专家属性抽取和领域标签抽取;根据专家之间的关系形成科技领域的专家库;最后根据专家发表的论文数、论文影响因子、论文被引数、h指数和专利数等维度进行建模,计算专家在相关领域的影响力,其具体流程图如图3所示。
其中,建设科技领域专家库的具体步骤如下:
(1-1)数据采集:对科技领域的专利和论文数据进行采集,提取出论文中的作者以及专利中的发明人,形成专家列表。然后对专家进行消歧,属性信息补全。
(1-2)抽取计算:根据专家的属性信息进行专家属性抽取和领域标签抽取,完善专家的信息,特别是专家的领域标签。
其中专家领域标签抽取过程如下:
①根据领域标签内容,对采集论文的分类进行匹配,并对采集的论文信息进行检索,根据匹配的论文数据建立领域标签论文集合,形成全部论文领域标签数据集,作为训练样本。
②使用fasttext算法对数据进行训练,形成全领域标签分类模型。
③基于上述步骤训练好的模型,对于专家的论文进行预测打分,形成专家的领域标签,一个专家可以命中多个标签,涉及多个不同的领域。
上述的fasttext算法结合了自然语言处理和机器学习中最成功的理念,这些包括了使用词袋以及n-gram袋表征语句,还有使用子词(subword)信息,并通过隐藏表征在类别间共享信息。
fasttext模型架构如下:
其中x1,x2,...,xn-1,xnx1,x2,...,xn-1,xn表示一个文本中的n-gram向量,每个特征是词向量的平均值(x1等表示一个文本中的n-gram向量)。与cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别,如图2。
科技领域标签数据,标签数量在几十到上百个不等,对于此类有大量类别的数据集,fasttext使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fasttext模型使用了层次softmax技巧。层次softmax技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
fasttext也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用huffman算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
fasttext可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此fasttext还加入了n-gram特征。在fasttext中,每个词被看做是n-gram字母串包。为了区分前后缀情况,"<",">"符号被加到了词的前后端。除了词的子串外,词本身也被包含进了n-gram字母串包。
(1-3)构建专家库:主要完成科技领域专家库的构建。需要根据专家的论文专利合作关系、同事关系、校友关系等复杂的人际关系,对专家关系进行连接。其中专家之间共同发表论文或者专利则形成合作关系;专家所属机构相同则形成同事关系;专家的教育背景存在时间与地点吻合度较高的则形成校友关系。
(1-4)专家评估:根据专家发表的论文数、论文影响因子、论文被引数、h指数、专利数等维度进行建模,计算专家在相关领域的影响力。其中过程如下:
①对专家数据清洗与转换,对论文数、论文影响因子、论文被引数、h指数、专利数等维度缺失数据进行处理。由于数据各个维度之间的数值往往相差很大,因此有必要对整体数据进行归一化处理,也就是将它们都映射到一个指定的数值区间,这样就不会对后续的数据分析产生重大影响。
②建立数学模型,计算专家领域影响力。其中x表示专家在某领域的论文数x1、论文影响因子x2、论文被引数x3、h指数x4、专利数xn等维度指标组成的向量集,t表示不同维度的加权集,则y=tx计算得到某领域的影响力。其中:y=t1*x1=t2*x2+...+tn*xn。(向量集x表示专家在某领域的论文数x1、论文影响因子x2、论文被引数x3、h指数x4、专利数xn等维度指标组成向量集)
步骤2:根据科技评审资料提取相关的科技领域,然后根据专家的领域标签过滤匹配度高的专家集合s1;同时提取科技评审资料中相关的申请人信息,作为需要直接规避的专家;然后根据社区发现算法以及专家之间的复杂关系,得到专家的社区关系;根据需要直接规避的专家及其关系比较紧密的专家社区关系,得到需要规避的专家集合s2;然后将推荐的专家集合s1中过滤掉需要规避的专家集合s2得到初步推荐的专家,即s=s1-s2。其流程图如图6所示。
该步骤中,根据科技评审资料中的技术领域信息以及申请人信息,得到相关领域的推荐专家以及需要规避的专家,得到初步推荐的专家列表,具体步骤如下:
(2-1)根据科技评审资料提取相关的科技领域,然后根据专家库中的专家领域标签过滤匹配度高的专家,得到专家集合s1。
(2-2)根据科技评审资料提取相关的申请人信息,作为需要直接规避的专家。然后根据社区发现算法以及专家之间的复杂关系,得到专家的社区关系。根据需要直接规避的专家及其关系比较紧密的专家社区关系,得到需要规避的专家集合s2。专家集合s2主要包含需要直接规避的专家、与申请人具有直接或者间接同事与合作等关系的专家。其中重叠社区发现算法如图4所示。
基于链接的重叠社区发现算法,将连边作为考虑对象,构造以原图中连边为节点的线图(linegraph),发现链接社区结构,链接社区的重叠节点对应于节点的重叠社区。该算法包含两个阶段,给定网络g(v,e),首先对边集e进行单链接层次聚类,得到若干互不相交的边子集,然后将链接聚类的结果转化为节点社区。算法的执行过程描述如下:
1、将网络g中的每条边初始一个社区,即p0=(c1,c2,…,c|e|)。
2、找出最相似的属于不同社区的两条边eik和ejk,并将这两条边所属的社区进行合并。其中相似度按照如下公式计算:
其中n+(i)={x|d(i,j)≤1},d(i,j)表示节点i和x之间的最小距离。即n+(i)包含了节点i本身和i的邻居节点。
3、重复执行2直到网络中所有的边被分到一个社区中。在此过程中,将每次迭代的结果存储在一个树状图中。
4、在3得到的树状图中找出划分密度(partitiondensity)最大的那层社区划分结果作为最终社区结构。其中划分密度d定义为:
其中mc和nc分别表示社区c包含边的条数和节点的个数。
5、将单链接层次聚类的结果转化为节点的集合,形成最终的专家的社区关系结构。(社区关系结构是得到整的专家库中专家的社区关系)
该算法的流程图如图5所示。
(2-3)将推荐的专家集合s1中过滤掉需要规避的专家集合s2得到初步推荐的专家列表,即s=s1-s2。
步骤3:得到初步推荐专家后按照影响力与其他限制条件进行二次过滤,并按照相关领域影响力排序得到最终的专家推荐列表,参见图7。
该步骤中,获得最终专家推荐列表的具体步骤如下:
(3-1)得到初步推荐专家后,根据专家影响力将相关领域影响力较弱的专家进行过滤。同时也可以根据用户指定的条件进行二次过滤。
(3-2)在步骤(3-1)中根据专家评估模型计算出了专家在相关领域的影响力,此时根据领域影响力进行排序,将影响力高的排序到推荐专家列表前列。
(3-3)经过一系列分析之后,得到最终的专家推荐列表。在合理规避有合作关系、同事关系、项目组关系等关系转件后,推荐高水平、高影响力、高责任心的专家。
- 还没有人留言评论。精彩留言会获得点赞!