基于极限学习机和密度聚类的海量报文掉线状态分析方法与流程
本发明涉及报文分析方法,尤其涉及基于极限学习机和密度聚类的海量报文掉线状态分析方法。
背景技术:
目前,报文掉线的实时分析的方法主要是借鉴离群点检测的方法和机器学习的方法。离群点检测的方法有:统计学方法,基于距离的方法,基于密度的方法等,但是离群点检测方法都需要人为设定一个阈值,阈值的设定对检测的准确度有较大的影响,并且算法的适应性和广泛性较差;机器学习的方法有:bp神经网络,宽度学习,极限学习机等,但是机器学习的方法在面对海量数据时,有神经网络过于复杂、训练时间太长和容易陷入局部最优值等缺点。因此,开发一种适应性强,运算速度快且准确率高的海量报文掉线分析系统,对于提高电网工作效率、经济效益具有重要的意义。
技术实现要素:
本发明要解决的技术问题和提出的技术任务是对现有技术方案进行完善与改进,提供基于极限学习机和密度聚类的海量报文掉线状态分析方法,以达到兼顾运算速度及准确性的目的。为此,本发明采取以下技术方案。
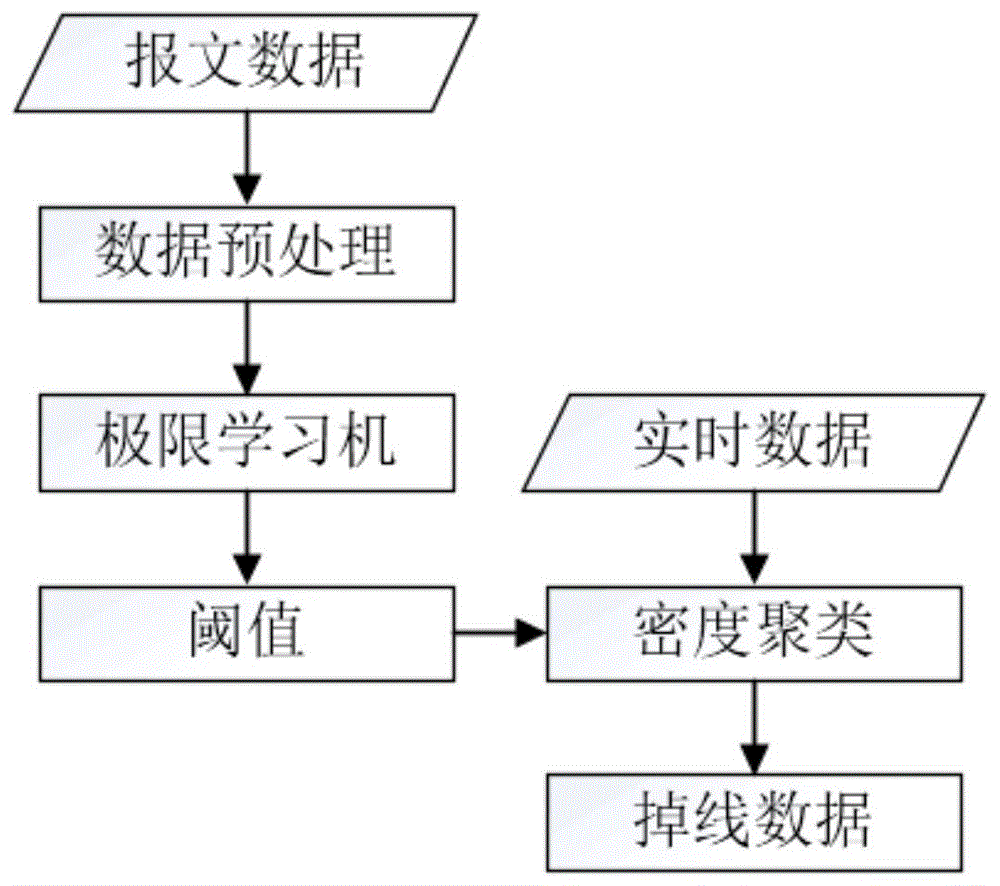
基于极限学习机和密度聚类的海量报文掉线状态分析方法,包括以下步骤:
1)选取历史数据,包含正常数据和掉线数据;
2)对报文数据进行预处理;
3)将预处理之后的且带有标签的数据导入极限学习机中;
4)通过极限学习机得出密度聚类的阈值;
5)设定密度聚类的阈值;
6)获取实时数据,并对实时数据进行预处理,并将处理后的实时数据导入密度聚类模型中;
7)根据设定的密度聚类的阈值,通过密度聚类模型的密度聚类选出掉线数据;
8)整理掉线数据。
本发明结合了机器学习方法的优势与聚类算法的优势,利用极限学习机来给出聚类算法中关键的阈值,可以拓宽聚类算法的应用范围和提高密度聚类算法的准确度。
作为优选技术手段:在步骤1)中,选取历史的报文数据要求是:日志类型为掉线数据,正常数据与掉线数据均为n。
作为优选技术手段:步骤2)中,报文数据预处理是把选取好的2n个报文数据中的时间差与时间标签截取出来,把时间差与时间标签进行归一化处理,使其值域在[0,1]。
作为优选技术手段:时间差预处理方法为:首先选取报文数据最小的时间单位秒,然后筛选出最大的时间差δtmax和最小的时间差δtmin,归一化公式为:
时间标签的预处理方法为:首先把数据按时间顺序排列,然后把第一数据的时间标签设为t1=1,然后下一个数据为t2=1+δt,其中δt为第一个数据与第二个数据的时间差(s),归一化公式为:
归一化之后的报文数据记为矩阵(xi,yi)。
作为优选技术手段:在步骤4)中,极限学习机对应的连续的目标函数为f(xi),给定所构造的网络l个单隐含层节点和隐含层节点的激励函数g(xi),由于存在βi、wi和bi,可以使得slfns以0误差逼近n个样本,elm的模型的数学表达为:
其中,j=1,2,…,n;网络输入权重向量wi表示输入节点与隐含层节点的权重;bi为隐含层节点的阈值;隐含层节点的参数wi与bi是在值域为[-1,1]中随机取值的;网络输出权重向量βi表示隐含层节点与输出层节点的权重;i=1,2,…,l。
将正常的报文数据代入elm的网络中,解得elm各节点的参数,并且把输出层记为h1,;将掉线的报文数据代入已定好参数的elm网络中,得到输出层,记为h2。
作为优选技术手段:在步骤5)中,密度聚类的阈值设定时,分别对输出层h1,h2进行统计分析,选取一个能最大程度区分正常数据与掉线数据的值设定为阈值r。
作为优选技术手段:在步骤7)中,密度聚类方法为:
设实时数据预处理之后为矩阵a=[a1,a2,…,am]t,其中ai=(xi,yi),然后,计算ai与其最近的k个点之间的马氏距离k-distance(ai)。
k-distance(ai)=(ai-aj)tσ-1(ai-aj)
式中协方差矩阵
对于矩阵a中的任意点ai,把所有距离ai不大于k-distance(ai)的数据对象所形成的领域称之为ka距离领域;
计算可达距离:设ai、aj为数据集中的任意两个数据点,那么数据点ai到数据点aj之间的可达距离为点ai的k距离k-distance(ai)与ai、aj之间距离较大的一个,记为
reach-dist(ai-aj)=max{d(ai-aj),k-distance(ai)}
计算局部可达密度:数据点ai的局部可达密度是指ai点到其领域内的最大的前k个距离平均值的倒数,这是对ai点局部密度的度量,记为
其中,lrdk(ai)为局部可达密度,nk(ai)为k近邻领域内包含点的数目,reach-dist(ai-aj)为可达距离;lrdk(ai)值较大表明ai点在k个点的分布比较稠密,因此为正常点;反之当lrdk(ai)值较小时,表明数据点ai在k个点的分布比较稀疏,则该数据点可能为离群点;
计算局部离群因子lof:局部离群因子表征了数据点的离群程度,也是衡量一个数据点离群的可能性大小的指标,记为
最后,若lofk(ai)>r,则ai为掉线数据,若lofk(ai)≤r,则ai为正常数据。
有益效果:本发明结合了机器学习方法的优势与聚类算法的优势,利用极限学习机来给出聚类算法中关键的阈值,可以拓宽聚类算法的应用范围和提高密度聚类算法的准确度。在面对海量报文数据时,聚类相对于神经网络有较块的响应速度,更适合应用于像报文这类需要较快知道是否掉线的问题。
附图说明
图1是本发明的流程图。
具体实施方式
以下结合说明书附图对本发明的技术方案做进一步的详细说明。
如图1所示,本发明提供一种基于极限学习机和密度聚类的海量报文掉线状态分析系统,如图1所示,该方法具体步骤如下:
步骤1,选取一段日志类型为3的历史数据,包含正常数据和掉线数据;
步骤2,对报文数据进行预处理;
步骤3,将预处理之后的且带有标签的数据导入极限学习机中;
步骤4,通过极限学习机得出密度聚类的阈值;
步骤5,设定密度聚类的阈值;
步骤6,导入实时数据;
步骤7,通过密度聚类选出掉线数据;
步骤8,整理掉线数据。
在具体的应用中,主要通过某电力公司提供的报文数据来验证系统的有效性。具体的步骤如下:
步骤1的选取历史的报文数据要求是:日志类型为3,正常数据与掉线数据均为n;
步骤2中的报文数据预处理是把选取好的2n个报文数据中的时间差与时间标签截取出来,
然后,把时间差与时间标签进行归一化处理,使其值域在[0,1]。时间差预处理方法为:首先选取报文数据最小的时间单位秒,然后筛选出最大的时间差δtmax和最小的时间差δtmin,归一化公式为:
时间标签的预处理方法为:首先把数据按时间顺序排列,然后把第一数据的时间标签设为t1=1,然后下一个数据为t2=1+δt,其中δt为第一个数据与第二个数据的时间差(s),归一化公式为:
其中,步骤4把归一化之后的报文数据记为矩阵(xi,yi),极限学习机对应的连续的目标函数为f(xi),给定所构造的网络l个单隐含层节点和隐含层节点的激励函数g(xi),由于存在βi、wi和bi,可以使得slfns以0误差逼近n个样本,elm的模型的数学表达为:
其中,j=1,2,…,n;网络输入权重向量wi表示输入节点与隐含层节点的权重;bi为隐含层节点的阈值;隐含层节点的参数wi与bi是在值域为[-1,1]中随机取值的;网络输出权重向量βi表示隐含层节点与输出层节点的权重;i=1,2,…,l。
首先,把正常的报文数据代入elm的网络中,解得elm各节点的参数,并且把输出层记为h1,;然后,把掉线的报文数据代入已定好参数的elm网络中,得到输出层,记为h2。
其中,步骤5密度聚类的阈值设定方法为:分别对输出层h1,h2进行统计分析,选取一个能最大程度区分正常数据与掉线数据的值设定为阈值r。
其中,步骤6导入实时数据前,需要对实时数据按照步骤2的方法对数据进行预处理,预处理之后的数据可以使得密度聚类有更好的效果。
其中,步骤7的密度聚类的算法为:
设实时数据预处理之后为矩阵a=[a1,a2,…,am]t,其中ai=(xi,yi),然后,计算ai与其最近的k个点之间的马氏距离k-distance(ai)。
k-distance(ai)=(ai-aj)tσ-1(ai-aj)
式中协方差矩阵
对于矩阵a中的任意点ai,把所有距离ai不大于k-distance(ai)的数据对象所形成的领域称之为ka距离领域;
计算可达距离:设ai、aj为数据集中的任意两个数据点,那么数据点ai到数据点aj之间的可达距离为点ai的k距离k-distance(ai)与ai、aj之间距离较大的一个,记为
reach-dist(ai-aj)=max{d(ai-aj),k-distance(ai)}
计算局部可达密度:数据点ai的局部可达密度是指ai点到其领域内的最大的前k个距离平均值的倒数,这是对ai点局部密度的度量,记为
其中,lrdk(ai)为局部可达密度,nk(ai)为k近邻领域内包含点的数目,reach-dist(ai-aj)为可达距离;lrdk(ai)值较大表明ai点在k个点的分布比较稠密,因此为正常点;反之当lrdk(ai)值较小时,表明数据点ai在k个点的分布比较稀疏,则该数据点可能为离群点;
计算局部离群因子lof:局部离群因子表征了数据点的离群程度,也是衡量一个数据点离群的可能性大小的指标,记为
最后,若lofk(ai)>r,则ai为掉线数据,若lofk(ai)≤r,则ai为正常数据。
其中,步骤8整理掉线数据:根据掉线数据的时间标签补全截去部分的数据,然后按不同区域以时间顺序生成表格。
当然,本发明还可以有其它数据的实例,在不背离本发明精神及其实质的情况下,熟悉领域的技术人员可根据本发明作出各种相应的改变或变形,但这些相应的改变或变形都应属于本发明所附的权利要求的保护范围。
以上图1所示的基于极限学习机和密度聚类的海量报文掉线状态分析方法是本发明的具体实施例,已经体现出本发明实质性特点和进步,可根据实际的使用需要,在本发明的启示下,对其进行形状、结构等方面的等同修改,均在本方案的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!