一种商业楼宇的日负荷预测方法与流程
本发明涉及能源物联大数据领域,具体为一种商业楼宇的日负荷预测方法。
背景技术:
楼宇用电能耗占全球总体耗能的40%,而且这个比例还在持续增加,特别是在发展中国家。楼宇负荷预测是楼宇能效管理系统、建筑内的各个用能子系统评估诊断、优化控制用电以及调度规划的重要基础。结合精确的负荷预测,可以分析楼宇负荷曲线高峰以及可控负荷的节能潜力,为制定基于需求响应的柔性负荷控制机制提供支撑。
智能用电是规划智能电网的基础和重要环节,商业楼宇能耗的准确预测能够帮助电网系统进行高效管理和合理分配电能资源,对于开展智能用电业务有着重要意义,商业楼宇能耗管理者(例如楼宇所有者或工程师)需要在不久的将来或提前一天准确预测能源需求,以便能够更好地管理能源使用。
传统的对商业楼宇的预测方法是根据以往的历史数据对未来目标日进行用电量的预测,实践证明,传统基于统计的方法在商业楼宇负荷预测方面表现普遍较差。
技术实现要素:
本发明提供的一种商业楼宇的日负荷预测方法,解决了传统基于统计的方法在商业楼宇负荷预测方面表现普遍较差的问题。
基于上述目的,本发明提供的一种商业楼宇的日负荷预测方法,包括如下步骤:
采集待预测楼宇的选定时间段每日的日负荷数据和该选定时间段每天的的小时负荷数据;
根据小时负荷数据生成小时负荷时间序列曲线,
对小时负荷时间序列曲线进行聚类分析处理,得出聚类数;
根据日负荷数据生成日负荷时间序列曲线;
通过对聚类数和日负荷时间序列曲线进行训练,得出svr模型;
通过svr模型对待预测商业楼宇进行未来目标日的负荷预测。
可选的,所述选定时间段为同一季度连续的一段时间。
可选的,所述采集待预测楼宇的选定时间段每日的日负荷数据和该选定时间段每天的的小时负荷数据之后还包括
将采集的日负荷数据和小时负荷数据等比例缩放;
探测并删除异常数据;
删除冗余数据;
填充缺失数据;
得出第一日负荷数据和第一小时负荷数据;
对所述第一小时负荷数据进行聚类分析处理,得出聚类数;
根据所述第一日负荷数据生成日负荷时间序列曲线;
通过对聚类数和日负荷时间序列曲线进行训练,得出svr模型,并保存该模型。
可选的,所述对小时负荷时间序列曲线进行聚类分析处理包括对小时负荷数据进行k-shape聚类分析。
可选的,所述对小时负荷时间序列曲线进行k-shape聚类分析处理,包括
将具有相似负荷模式的小时负荷时间序列曲线聚为一类;
得到多组分类数据,每组分类数据包括一个簇数和与该簇数对应的均方误差;
选定任意三个相邻的簇数k-1,k,k+1,计算k的均方误差与k-1的均方误差的差值d1,计算k的均方误差与k+1的均方误差的差值d2,并计算||d1|-|d2||=δd;
选取δd最小的簇数k作为聚类数。
可选的,所述根据日负荷数据生成日负荷时间序列曲线之后还包括:按照时间先后顺序,将全部日负荷数据分为训练集和测试集。
可选的,所述所述通过对聚类数和日负荷时间序列曲线进行训练包括:以商业楼宇的日负荷值和所述聚类数作为输入,滞后一天的负荷值作为标签,进行训练得出svr模型,并保存模型。
可选的,所述将采集的数据等比例缩放包括:通过如下公式将数据归一化到0~1范围内。
其中xnorm为归一化后数据,x为原始数据,xmax和xmin分别为原始数据集的最大值和最小值。
可选的,所述通过svr模型对待预测商业楼宇进行未来目标日的负荷预测之后还包括,采集同一区域多个商业楼宇的日负荷数据和小时负荷数据,对所述日负荷预测方法进行验证。
基于相同的发明创造,本发明还提供了一种执行商业楼宇的日负荷预测方法的装置,包括
采集模块,采集待预测楼宇的选定时间段每日的日负荷数据和该选定时间段每天的的小时负荷数据;
第一数据处理模块,根据小时负荷数据生成小时负荷时间序列曲线,对小时负荷时间序列曲线进行聚类分析处理,得出聚类数;
第二数据处理模块,根据日负荷数据生成日负荷时间序列曲线;
训练模块,通过对聚类数和日负荷时间序列曲线进行训练,得出svr模型,并保存该模型;
通过svr模型对待预测商业楼宇进行未来目标日的负荷预测。
有益效果为:通过聚类分析得出聚类数,以建筑物日负荷值和聚类数作为训练输入得到svr模型,有效降低了预测误差,提升了预测精度,可对目标日的日负荷进行预测。
附图说明
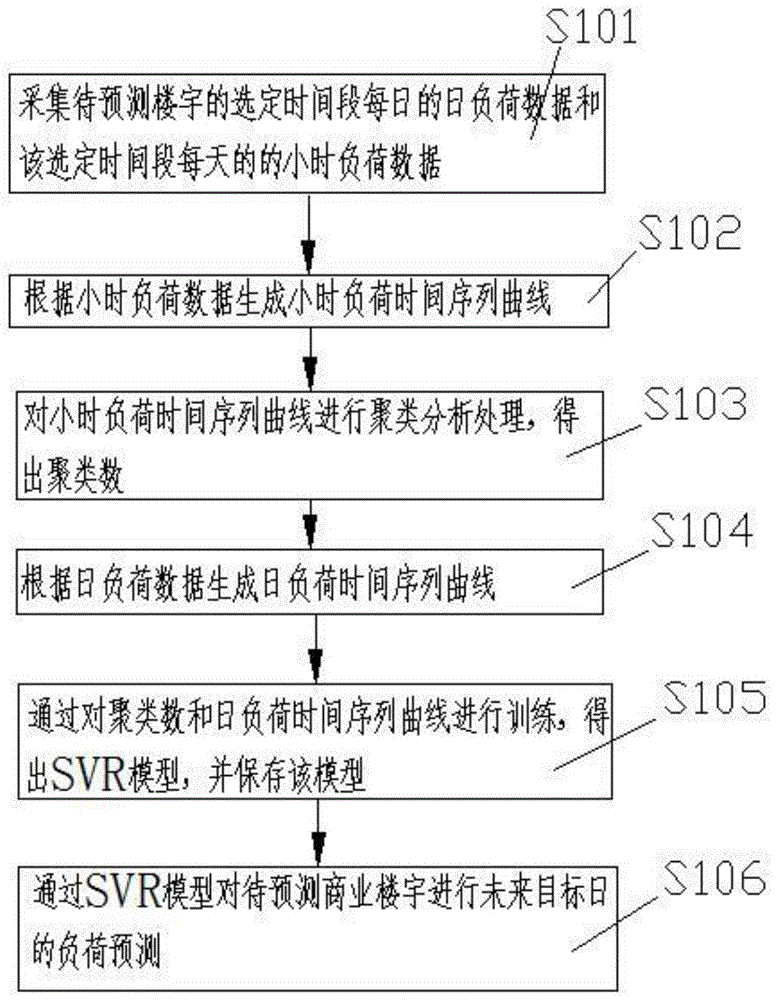
图1为实施例商业楼宇的日负荷预测方法步骤流程图;
图2为实施例商业楼宇的日负荷预测方法装置连接图;
图3为实施例商业楼宇的日负荷预测方法验证流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
为达到上述目的,如图1所示本发明实施例提供了一种商业楼宇的日负荷预测方法,具体步骤可以如下:
s101采集待预测楼宇的选定时间段每日的日负荷数据和该选定时间段每天的小时负荷数据;
举例来说,采集步行街上一个楼宇的六、七、八月份共九十二天的日负荷数据和小时负荷数据,采用同一季度的日负荷数据和小时负荷数据,数据之间不会出现波动过大的情况。值得注意的是,可以选择六、七、八月份,也可以选择同一季度连续的一段时间。
为了提高预测模型的收敛速度和精度,将数据归一化到0~1内。公式如下:
该方法实现对原始数据的等比例缩放,其中xnorm为归一化后的数据,x为原始数据,xmax和xmin分别为原始数据集的最大值和最小值。
执行坏数据、异常数据探测;
执行冗余数据删除,假设发现部分楼宇存在超过2208个数据点的情况,将超出的部分进行了删除处理,
执行缺失数据填充,发现采集的数据存在个别数据点缺失情况,采用插值方式填充了缺失数据。
s102根据小时负荷数据生成小时负荷时间序列曲线。
s103对小时负荷时间序列曲线进行聚类分析处理,得出聚类数;根据商业楼宇的小时负荷值生成九十二条小时负荷时间序列曲线,对该楼宇的小时负荷时间序列曲线进行k-shape聚类分析处理,将具有相似负荷模式的曲线聚为一类。
可以采用应用基于thorndike的elbow方法选择最合适的簇数,k-shape聚类分析后得到多组分类数据,每组分类数据包括一个簇数和与该簇数对应的均方误差;
选定任意三个相邻的簇数k-1,k,k+1,计算k的均方误差与k-1的均方误差的差值d1,计算k的均方误差与k+1的均方误差的差值d2,并计算||d1|-|d2||=δd;
选取δd最小的簇数k作为聚类数;
通过计算所有时间序列数据的质心,并将每个时间序列数据聚为最接近质心那一类来更新聚类成员。为了解决缩放不变性,在分配步骤中,将每个时间序列数据集z标准化,以使数据集的平均值为0,标准差为1。计算距离质心的公式如下所示:
其中,
s104根据日负荷数据生成日负荷时间序列曲线;按照时间的先后顺序,将全部日负荷时间序列曲线数据分为两个部分:训练集为前70天,测试集为后22天;
s105通过对聚类数和日负荷时间序列曲线进行训练,得出svr模型,并保存该模型;
以商业楼宇的日负荷值和聚类数作为输入,之后一天的值作为标签,进行训练得出svr模型,并保留模型。
如图3所示,采集同一区域多个商业楼宇的日负荷数据和小时负荷数据,对所述日负荷预测方法进行验证。
采集同一步行街上十个楼宇的日负荷数据和小时负荷数据,对上述步骤进行验证。
通过svr模型对待预测商业楼宇进行未来目标日的负荷预测。
与上述实施例相对应,如图2所示,本发明还提供了一种执行商业楼宇的日负荷预测方法的装置,包括
采集模块,采集待预测楼宇的选定时间段每日的日负荷数据和该选定时间段每天的的小时负荷数据;
第一数据处理模块,根据小时负荷数据生成小时负荷时间序列曲线,对小时负荷时间序列曲线进行聚类分析处理,得出聚类数;
第二数据处理模块,根据日负荷数据生成日负荷时间序列曲线;
训练模块,通过对聚类数和日负荷时间序列曲线进行训练,得出svr模型,并保存该模型;
s106通过svr模型对待预测商业楼宇进行未来目标日的负荷预测。
传统的对商业楼宇的预测方法是根据以往的历史数据对未来目标日进行用电量的预测,实践证明,传统基于统计的方法在商业楼宇负荷预测方面表现普遍较差,不仅计算步骤繁琐,处理数据所耗时间多,而且楼宇用电的规律性不易获取。通过k-shape聚类分析得出聚类数,以每个建筑物日负荷值和所聚类别数作为训练输入,有效降低了预测误差,提升了预测精度。k-shape更适用于时间序列的聚类,在比较的时候尽量保留时间序列的形状,该算法的核心是迭代增强过程,可以生成同质且较好分离的聚类。以每个建筑物日负荷值和所聚类别数作为训练输入,有效降低了预测误差,提升了预测精度。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!