一种基于面部运动单元的三维非真实感表情生成方法与流程
本发明涉及基于面部运动单元(au)的三维非真实感表情生成方法,属于智能情感计算技术领域。
背景技术:
在人类情感信息的表达方式中,除了肢体动作和语言信息外,面部也是人类表达信息的重要部位,通过面部的动作表达人类的情感信息是人类日常交流的主要方式之一。人脸表情中含有丰富的信息,mehrabian提出人类情感信息有55%是通过人脸传递的,而声音、言语等方式仅占了45%。随着计算机技术的发展,人类对人机交互的要求越来越高,情感计算也受到广泛关注,它要求计算机不仅能识别人类情感,还能理解人类情感并做出应答,从而使计算机能够像人与人一样进行情感交流,既有表情的识别又有表情动作的互动。识别面部表情并对面部情感信息做出表情应答,是一个完整的过程。在智能人机交互过程中,人类希望计算机能够像人一样,对人类的表情做出应答和模仿。
表情动画生成方法主要是将表情的发出者作为表情的模板,使目标对象模仿模板表情,主流方法通过定位面部的特征点,根据特征点的信息重建面部表情及面部动作。但是,选取的特征过点多会影响计算效率,选取的特征点少则会影响表情的表达效果。除此而外,目前的方法在目标重建表情过程中并不理解重建表情的种类,造成表情信息丢失。
在人机交互过程中,需要提取参与者的表情信息并对提取的表情信息做出应答,显然,对于人类丰富多态的表情做出回应,已有的基于将源人物面部表情动作映射到目标人物面部图像的方式在人机交互过程中缺乏灵活性。
著名心理学家保罗·艾克曼基于解剖学,根据肌肉的动作状态来表征人类表情,提出面部运动单元的概念,每一个面部运动单元代表与其他面部运动单元互不干扰的面部动作,由不同的面部运动单元组成具有表情意义的面部动作。基于au的表情动画生成方法,可以通过au组合生成表情,人作为面部动作的捕捉对象不再是方法的必要条件,并且可以更丰富化人类表情动作,从而更细致更贴近真实表情。
在河北工业大学张满囤、葛新杰、吴鸿韬、李智、魏玮、2013年07月10日公开、公开号cn103198508a、发明名称为“人脸表情动画生成方法”的中国发明专利申请中,提出一种基于运动捕捉数据的人脸动画生成方法,他们首先使用摄像机捕捉人脸的正面照片,使用径向基函数技术对人脸变形,重新映射人脸的纹理部分,通过将面部划分成不同的区域进行局部形变,最后融合成人脸模型。该发明需要设备记录生气、悲伤、厌恶、惊讶、恐惧和高兴六种基本表情,通过其他方法感知后进行处理,通过41个特征点提取特征。该发明在设备提取数据时采用的六种基础表情,而人类表的面部表情丰富多彩、多种多样,每一种基础表情又由不同的表达方式,例如,微笑和大笑,都属于高兴;因而表达的丰富性不够。其次,基于特征点提取特征的方法,特征点位置的精确度直接影响算法后续的准确性,并不能避免特征点提取存在误差的问题。
在大连东锐软件有限公司王春成、刘鑫、郑媛媛、2018年12月28日公开、公开号cn109101953a、发明名称为“基于人类面部表情的分区要素化的表情动作生成方法”的中国发明专利申请中,提出基于人类面部表情的分区要素化的表情动作生成方法,通过采集多个对象的面部表情各部分的运动数据建立数据库;根据外部输入表达内心情感参数,取面部综合表情动作参数l为最终面部表情参数r;将最终面部表情参数r用于控制目标模型运动,生成表情动作。该方法在建立数据库过程中,需要扫描采集多个对象的各个面部的不同角度的运动数据,无疑增加数据采集的工作量。
技术实现要素:
本发明技术解决问题:为了克服现有表情动画生成对特征点几何位置依赖的不足,本发明提出了一种基于面部运动单元的三维非真实感表情生成方法,面部运动单元au具有独立、互不干扰的特点,独立的动作单元并不一定具有独立的语义信息,多个动作单元的组合则表达了有意义的情绪状态。本发明的方法不仅能够提取表情动画生成过程中的表情信息,而且摆脱了现存方法需要表情模板或特征点定位不准确的问题。相对于二维图像,三维模型提供了更丰富的空间信息。本方法大大提高了表情动画生成的灵活性并丰富了表情信息。
本发明技术解决方案:一种基于面部运动单元的三维非真实感表情生成方法,包括以下步骤:
1、建立三维au模型基础训练集
1.1)使用建模工具建立具有完整信息的三维中性面部模型。根据面部动作编码系统facs和人体面部肌肉分布,以中性模型为基础,建立与au对应的三维模型基础训练集。
1.2)生成目标对象的au模型数据
对于生成目标对象的au模型,形成扩增训练集,采用构造对抗神经网络的方式。构造的对抗神经网络分为两个部分:一是输入目标对象的三维中性模型和步骤1.1)中的au模型y,网络职能提取模型的特征信息,根据au模型的特征信息,逐步调整目标模型的参数,最后输出目标的三维au模型;二是输出模型的验证网络,网络职能是将调整参数后的目标模型与输入的目标模型、输入的au模型对比,计算损失函数和生成模型的相似度,调整模型参数,生成可靠性高的模型。
所述对抗神经网络由编码器b、生成网络g与判别网络d组成。除了重建损失之外,潜在向量
判别器de尝试将数据与训练分布pd和au模型y的生成分布f(b(xe),y)的采样数据区分开,而生成器ge预期生成分布f(b(xe),y)混淆了de。因此,训练de和ge具有类似的最小-最大目标函数:
计算模型的损失函数,利用空间点在傅里叶空间中哈达玛积(hadamardproduct)构造三维网格数据的卷积运算,描述三维空间形状特征,计算目标的au模型与输入模型之间的相似度,作为模型的损失函数。设置损失阈值,作为判别器de的判别真实模型与生成器ge生成的模型的相似度。
2、面部表情分析
2.1)分析目标表情的设计
构造一个卷积神经网络作为二维表情图像的au分析模型,设计并实现深度卷积神经网络。此网络中包括了卷积层、捷径层、全连接层、输出层。对于捷径层,为了加强特征信息的对比,在隔一层卷积层之间加入一个捷径层,如下式为捷径层的形式化描述:o(x)=ωix+x,其中ωi为第i个卷积层的卷积模板参数,x为卷积层输入,o(x)为输入与卷积层运算的输出相叠加作为捷径层。
每一个卷积层都通过一组卷积参数模板对上一层特征图像进行卷积运算,并获得与卷积参数模板个数相同的特征图像作为输出层,卷积层的激活函数采用有泄漏的线性整流函数:
多标签的交叉熵损失函数:
其中,v是全体au集合,r是图像中人像au区域的集合,y(r,v)=1表示v号au在区域r上出现。模型会将输入图像规范化,将图像划分成s×s的格子。每个边框负责检测目标中心落在其中的可信度和精度有多大,并预测b个边框以及置信度,置信度表示一个边框内含有au的可信度,形式为:
2.2)训练表情au分析模型
2.2.1)利用步骤2.1)的方法构建一个au识别的深度卷积神经网络结构;
2.2.2)对卷积神经网络中的参数初始化,一般卷积层的卷积核用标准差为0.01的高斯函数初始化,偏置初始化为0;
2.2.3)卷积神经网络初始化后,开始训练表情au分析的卷积神经网络,对输入的训练数据,首先将图片标准化,神经网络的第三层和第五层为捷径层,为上一层的输出和输入层的和值,提取并加强图像特征,第六层到第十层对图像的特征进行分类,并在输出层输出结果。最后,计算输入的训练集图像经过卷积神经网络各层后得到的结果与真实数据分布图之间的损失,即
2.3)表情图像au分析
对于二维图像表情分析,由上述步骤2.2)训练得到au分析模型,然后进行检测:获取的检测图像,首先提取图像块,将图形块缩放到固定像素大小,输入到卷积神经网络中,通过卷积神经网络处理,产生对应的au数据。
3、生成三维表情模型
3.1)根据人类面部肌肉收缩和舒张,面部呈现出不同的面部动作,人脸面部动作的程度直接影响面部表情,根据步骤2.3)对表情分析au信息,对于每一个面部动作设置一个强度值γi表示面部肌肉的收缩和舒张程度,代表au的表达强度。0≤γi≤1,γi=0表示该au未参与面部表情活动,γi=1表示面部肌肉舒张和收缩均达到最大程度,au表达达到最大强度。
3.2)对于三维au模型m由纹理信息和形状信息组成,模型m是由中性表情模型n形变得到,因此,模型m与模型n具有相同的顶点集。因此可以提取模型m相对与中性表情模型n的信息特征:形状信息δs和纹理信息δt。其中:δsm=sm-sn,δtm=tm-tn,sm表示模型m的形状信息,sn表示中性表情模型n的形状信息,tm表示模型m的纹理信息,tn表示中性表情模型n的纹理信息。并且形状信息δs和纹理信息δt存在一一对应的映射关系。
3.3)根据步骤3.2)中提取的基础模型的特征信息:形状信息δs和纹理信息δt,及步骤3.1)对面部表情设置的阈值γi,将特征信息融合到三维中性模型中,三维面部表情模型的形状模型
有益效果:
本发明与现有技术相比的优点在于:
(1)采用由中性模型到au模型进而形成模型基础训练集的方式,不需要基于特征点的方式提取面部特征,克服现有表情动画生成对特征点几何位置依赖的不足,从而避免了在提取特征过程中面部对齐、特征点提取以及模型之间的差异等产生的误差,使特征提取更加精确。
(2)基于au组合生成特定表情的3d模型,只需要输入对应的au数据信息,通过基础au模型与表情的对应关系,即可生成表情模型,解决了现有方法需要获取相关表情几何信息作为数据源的问题,方法使用者通过控制相关au的参数,更方便的灵活生成目标表情。
(3)在表情合成上,根据面部肌肉运动而划分的au单元融合表情,不仅方便控制面部的局部动作,而且使产生的表情更加丰富多样。
附图说明
图1是本发明方法流程图;
图2是facs中性表情图;
图3是人体面部肌肉分布图;
图4是生成器网络结构图;
图5是目标模型生成图;
图6是神经网络结构图;
图7是表情生成图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。
本发明提出了一种基于面部运动单元的三维非真实感表情生成方法。包括:
步骤1,建立标准的三维面部中性模型,以中性模型为基础,建立与au对应的三维模型基础训练集。
使用gan网络生成au与对应三维模型的扩增训练集。将已经建立的三维模型基础训练集中的au模型,与目标对象模型作为gan网络的输入,使用gan网络生成目标对象的au模型,建立目标对象的au模型与三维人脸模型的对应关系,扩增训练集。
步骤2,对所要生成的目标对象的面部表情进行分析,输入人脸二维图像,使用神经网络分析人脸表情,获取表情的au模型数据。
步骤3,根据得到的表情au数据信息,以及目标对象的相关au模型数据,目标对象的au模型是由中性模型形变形成,独立提取每个au模型特征,并叠加到中性模型,融合生成目标表情的三维模型。
au是面部动作表达的基础,au具有独立、互不干扰的特点,独立的动作单元并不一定具有独立的语义信息,多个动作单元的组合则表达了有意义的情绪状态。基于au的特点,本发明将面部表情分解到基础的au,使用基于au的面部模型融合形成面部表情,不仅可以实现基于六种基础表情的表情仿真,也可以实现基于面部运动单元的表情迁移,实现了面部表情到模型的表情迁移。
本发明根据每个au的特征,采用由一个初始的中性模型为出发点,为每一个au建立一个三维模型,通过与中性模型做差值提取模型特征。对于基于特征点的表情生成方法,在面部对齐的过程,即使同一个人脸在不同的环境下,面部对齐总存在误差。
本发明采用由同一个模型衍生其他模型的方式,避免了在提取特征过程中面部对齐、特征点提取以及模型之间的差异等产生的误差,提高了au模型特征提取的精度。基于au模型的表情融合,只需要知道所要生成的表情的au数据信息就可以生成目标模型,摆脱了传统方法需要表情发出者作为数据源的问题,对于表情的au数据分析,本发明使用卷积神经网络对二维图像分析表情的au组合。在表情合成上,根据面部肌肉运动而划分的au单元融合表情,不仅方便控制面部的局部动作,而且使产生的表情更加丰富多样。
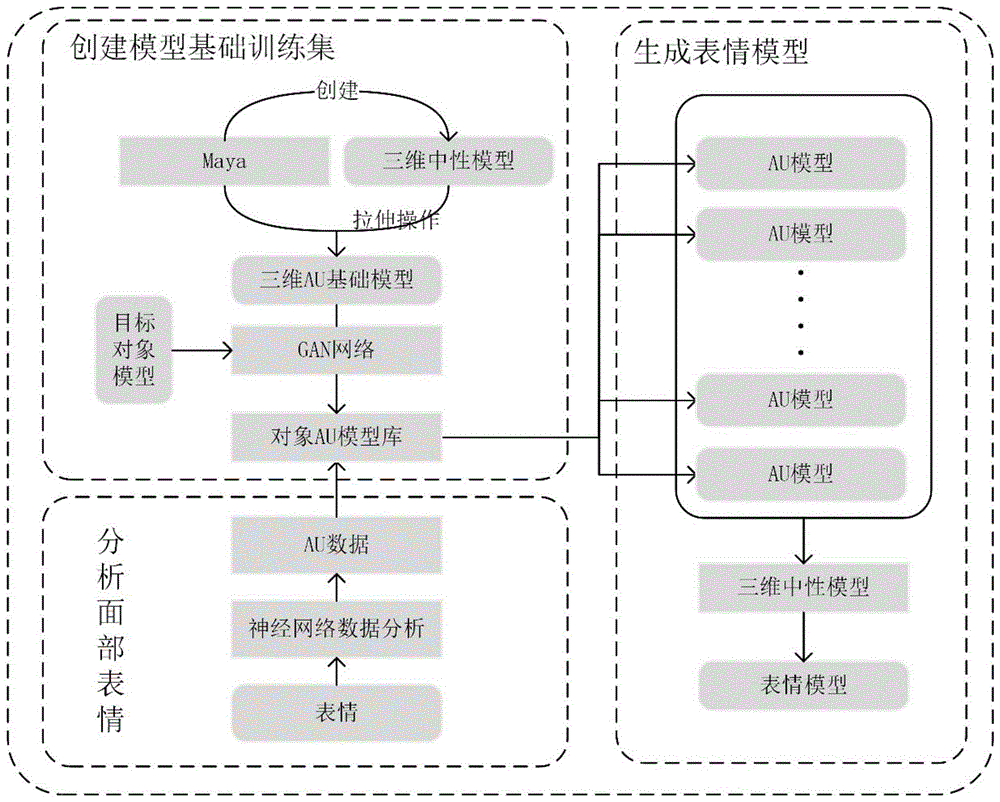
如图1所示,本发明基于面部运动单元的三维非真实感表情生成方法主要有创建模型基础训练集并扩增训练集、分析面部表情数据和生成表情模型三个阶段。
步骤1创建模型基础训练集并扩增训练集
目前创建三维模型的方法诸多,如众多研究者研究出使用二维图像生成三维模型的方法,基于二维图像创建三维模型,需要多张图像才能创建出完整的模型,并且存在模型的深度数据计算差等问题。也有许多专业的建模工具和动画工具,如maya、3dmax、autocad等强大的专业工具。
步骤1.1创建三维中性模型
根据facs中对中性表情的描述以及提供的中性表情的插图,如图2所示,使用maya创建中性表情模型,根据不同需求,可以创建出不同精细程度的头像模型。
步骤1.2创建三维au基础模型
依据解剖学对人脸面部肌肉的解析,如图3所示,保罗·艾克曼对面部划分了au。根据保罗·艾克曼在facs中对au的描述以及插图示例,使用maya软件对步骤1.1)中的中性模型依据解剖学中肌肉的分布进行拉伸等操作,创建出每个au单元对应的au模型,形成基础训练集。参与面部运动的面部顶点产生顶点位移,无关位置的顶点的位移量为零。
步骤1.3gan网络设计
如图4所示,用于生成目标对象的三维模型的gan网络(生成式对抗网络)分为四个部分,即编码器b、产生器g、判别器de和判别器dq。网络中的卷积层采用5×5的卷积核。
图4中的编码器b有三层结构,模型有4096个顶点组成,第一层将模型的形状信息根据坐标系xyz划分成64×64×3的矩阵,第二层将第一层的64×64×3的矩阵通过5×5×9卷积操作提取的特征维度为32×32×9,第三层经过卷积核:5×5×18后,提取的特征维度为16×16×18。判别器dq接收编码器b处理后的数据
步骤1.4生成对象au模型库
根据设计的gan网络,将所要生成对象的无表情三维模型和基础训练集中的au模型作为gan网络的输入,通过gan网络生成与au对应的目标对象的三维模型。如图5所示,将目标的中性模与基础训练集中的模型model_1输入gan网络中,gan网络通过提取目标模型的中性模型特征、基础训练集中模型的特征、以及输入au模型的标签,经过处理,不断调整模型参数,直到生成目标的模型model_1。以此类推,基础训练集中的模型model_2、model_3…model_n和目标的中性模型分别输入gan网络中,分别生成目标模型的模型model_2、model_3…model_n。最后形成扩展训练集。
步骤2分析面部表情
步骤2.1表情分析模型设计
本发明用于分析面部表情的卷积神经网络分为两个部分,一部分是对图像特征加强的捷径层设计,一部分是提取特征识别au的设计。如图6所示,捷径层设计的第一层是输入层,第二层和第四层是上一层经过1个5×5、1个3×3和1个1×1卷积核卷积计算形成,第三层和第五层是上一层与输入层形成的特征叠加层。神经网络中的池化层的步长为2。第五层到第六层之间经过卷积计算,含有128个7×7的卷积核,第六层到第七层之间经过卷积计算,含有256个3×3的卷积核,第七层到第八层之间经过卷积计算,含有512个3×3的卷积核,第八层到第九层之间经过卷积计算,含有1024个3×3的卷积核,第九层到第十层之间经过卷积计算,含有1024个3×3的卷积核。第十一层是全连接层,第十二层是输出层,本发明含有23个au,将标准化的图像划分成7×7的网格,每个网格预测两个边框,因此输出是7×7×33。表示7×7网格中每个网格中预测的au数据。
正如上面提到的,发明的卷积神经网络需要学习到从一个图像块到一个au数据分析的非线性映射。因此,需要训练卷积神经网络来解决这个回归问题。为了达到这个目标,需要计算输入训练图像与预测图像的损失函数:
步骤2.2获取训练样本
使用已有的ck+表情数据库作为数据集,将数据集以2:3分为测试集和训练集。
步骤2.3图像预处理
首先,使用标注工具labelimg在训练集的图像上标注出au的标签以及au的特征在面部的区域,形成数据文件作为训练数据的输入。其次,对于输入的图像,首先将图像标准化,通过图像采用将图像转变为224×224,输入卷积神经网络中训练模型。
步骤2.4训练表情分析模型
在训练卷积神经网络时,首先要对卷积神经网络中的参数初始化,一般卷积层的卷积核用标准差为0.01的高斯函数初始化,偏置初始化为0。同时设置好学习率ε,对于训练集的m个样本{x(1),...,x(m)}和其对应的目标y(i),i∈[1,m],计算估计梯度
步骤2.5面部表情分析测试
将待测二维图像输入分析系统,系统输出图像中的au数据。
步骤3生成表情模型
步骤3.1提取模型特征
根据步骤2对所生成表情的分析,从步骤1.4)创建的扩展训练集中提取相关au模型。根据每个au模型和中性模型差异性,提取相关au单元的特征信息并存储。由步骤1.4)得到的au模型与中性模型之间顶点一一对应,将au模型与中性模型做差值,提取au模型相对中性模型的特征信息,特征信息分为形状信息δsi=si-sn和纹理信息δti=ti-tn,sn为中性模型的形状信息,δsi为第i个模型的形状特征,tn为中性模型的纹理信息,δti为第i个模型的纹理特征。每个au模型和中性模型的顶点能够实现双射,能够精确的提取au模型的运动信息和纹理信息。
步骤3.2面部表情融合
根据步骤3.1)提取的au特征信息和步骤2)对所生成表情的分析,对中性表情进行au特征融合生成新的表情模型。根据au的独立性,可以对已经经过生成的模型形状s'在进行au单元融合s=s'+δsi*γi,阈值γi表示第i个au的表达程度,调整阈值γi可以调整表情的局部信息,表情生成起始模型形状s'为中性模型。纹理信息t=t'+δti*γi。形成目标表情的三维模型。在信息融合时,面部对齐过程产生的误差是影响表情生成质量的影响因素之一,传统方法采用取平均模型与特征信息差值进行叠加,这样并不能避免面部对齐过程中误差产生的影响。在步骤1)中,由中性模型产生au模型,从而代替了面部对齐过程。
如图7所示,将提取目标的au_10和au_25的特征与中性模型融合,形成了图中融合au_10和au_25特征的模型m,从目标的au_5和au_25模型中提取模型特征,调整模型m、au_5模型和au_25模型参数,将三个模型融合形成最终模型,如图中表情“震惊”的模型。
输入目标模型的中性模型与生成表情的相关au模型,通过融合特征生成目标模型。首先融合中性模型与第一个au模型的特征,得到融合后的模型后,再融合第二个相关模型的特征,直到最后一个模型的特征融合完成,生成目标模型。
步骤3.3多角度表情图像生成
对于融合形成的三维表情模型,改变观察模型的不同角度、光照等条件,提取图像的多角度表情图像。
本发明基于au的3d模型到非真实感的表情生成的映射,使用由一个模型衍生其余au模型的方法,避免了模型信息提取过程中的面部对齐操作,从而避免了面部对齐所产生的误差。使用au组合产生表情的方式,达到了人为可以控制参数进而调整面部动作,从而避免了传统表情生成方式需要人或者图像表现出表情作为表情数据源的缺点。将表情程度考虑到表情融合过程中,从而达到了专业的控制表情微动作,产生的表情多样化和更加逼真。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!