一种分级神经网络的案件情节精准量刑系统的制作方法
本发明涉及电子司法辅助技术,特别涉及一种分级神经网络的案件情节精准量刑系统。
背景技术:
司法办案、判案等工作主要依靠司法人员掌握的法律知识和积累的工作经验,存在“同案不同判”、“案多人少”等现实矛盾。目前法院、检察院、司法办案主要依靠一线业务人员的经验,员额制改革导致中层骨干流失,导致队伍年轻化。年轻化就意味着年轻法官和检察官的审判经验或者司法经验是不足的,从而导致同案不同判的现象发生。
对于办案经验的掌握,主要依靠业务人员学习以往案例和时间积累,培养一个合格的法官和检察官需要几年甚至十几年的时间。导致一线合格的办案人员无法短时间补充,现实工作中,存在案多人少的现象。
目前通过人工智能进行辅助办案的技术是稀少而缺乏的。
目前市面上的辅助办案系统一般还停留在关键词检索的阶段,既使用案由或当事人信息以及案件编号等进行检索,无法做到基于案情描述的语义检索,推送出来的类似案件相关度不够高,办案人员往往需要阅读数篇甚至数十篇裁判文书才能找到相关的案件,这样的数据系统包括https://openlaw.cn/,http://wenshu.court.gov.cn/裁判文书网等系统。
目前市面上并没有针对案件情节的精准量刑系统。
技术实现要素:
本发明的目的在于提供一种分级神经网络的案件情节精准量刑系统,用于解决上述现有技术的问题。
本发明一种分级神经网络的案件情节精准量刑系统,其中,包括:罪名预测级以及情节量刑预测级;罪名预测级包括:定罪特征库、文本向量化表示模块、定罪分类神经网络以及预测罪名和案由模块;情节量刑预测级包括:高概率罪名案由排序过滤模块、情节量刑引擎案由量刑情节库、以及量刑估计模块;案件描述文本输入给文本向量化表示模块后,通过文本向量化表示模块获定罪语料库中的语料,每个语料对应一个向量,用于表征整个文本;案件描述文本的向量化矩阵作为定罪分类神经网络的输入,计算每项罪名的概率,得出各定罪罪名的概率,并发送给预测罪名和案由模块,预测罪名和案由模块根据罪名预测结果,得到罪名对应的特定的法条结果;以案情描述文本和第一级的各项罪名概率为高概率罪名案由排序过滤模块输入,选择过滤前k个概率最高的案由和罪名,针对这k个案由,以自然语言形式的案件事实为输入;针对某个高概率案由,生成案件描述的向量化矩阵,首先抽取获得情节判定库中的语料,每个语料对应一个向量,用于表征整个文本;将该案情描述的向量化矩阵作为情节量刑引擎的输入的输入,计算各项情节的概率,再计算案件刑期,得到最终结果。
根据本发明的分级神经网络的案件情节精准量刑系统的一实施例,其中,计算各项情节的概率包括:采用3组卷积核分别为2个3临近词卷积核(1a,1b),2个4临近词卷积核(2a,2b),2个5临近词卷积核(3a,3b)分别对案件的(m*n)维的向量化文本进行卷积,结果进行激活函数后获得6个一维向量结果,在对这6个向量结果进行maxpooling池化抽样后连接得到一个新的(p*1)维向量,然后在将向量作为多层感知的输入进入多层感知机;针对可能b个情节,多层感知机应有b个输出,得出各情节的概率,并选择出高于概率门限的情节组成情节向量表(b*1)维,概率大于门限t时,表征该情节的位置1,小于门限t时,则置0。
根据本发明的分级神经网络的案件情节精准量刑系统的一实施例,其中,案由量刑情节库,抽取方式可以使用正则方式抽取,将案件中的定罪特征词进行one-hot编码,或使用cbow与skip-gram模型进行词向量编码。
根据本发明的分级神经网络的案件情节精准量刑系统的一实施例,其中,计算每项罪名的概率包括:采用3组卷积核分别为2个3临近词卷积核(1a,1b),2个4临近词卷积核(2a,2b),2个5临近词卷积核(3a,3b)分别对案件的(m*n)维的向量化文本进行卷积,结果进行激活函数后获得6个一维向量结果,在对这6个向量结果进行maxpooling池化抽样后连接得到一个新的(p*1)维向量,然后在将该向量作为多层感知的输入进入多层感知机,针对n个罪名,多层感知机有n个输出并得出各定罪罪名的概率。
根据本发明的分级神经网络的案件情节精准量刑系统的一实施例,其中,案件描述文本输入给文本向量化表示模块后,通过文本向量化表示模块获得m个定罪语料库中的语料,每个语料对应一个向量,向量维度为(1*n),将m个向量按顺序合并产生(m*n)维矩阵,用于表征整个文本。
根据本发明的分级神经网络的案件情节精准量刑系统的一实施例,其中,高概率案由k,生成案件描述的向量化矩阵,首先抽取获得m个情节判定库中的语料,每个语料对应一个向量,向量维度为(1*n),将个向量按顺序合并产生(m*n)维矩阵,用于表征整个文本。
本发明具有的效果包括:
(1)实现机器如何掌握法律知识:将人掌握的法律法规等海量司法资料,转化为机器可掌握的层次化、形式化、结构化司法知识;将海量的裁判文书进行解析,形成机器可以识别的结构化信息和知识库;将一线业务专家积累形成的工作实践经验,通过大量裁判文书标注的方式转化为机器可以运用的知识。通过以上结构化后的海量数据,对深度神经网络进行训练,使其具有一线办案人员的智能,使计算机具能够完成案件情节的精准量刑辅助办案系统。
(2)实现机器如何运用法律知识:部署已经收敛好的深度神经网络,将自然语言描述的案情描述输入计算机,自动对案情描述解析,给出参考的量刑建议以及对应的法条和案由依据。
附图说明
图1所示为一种分级神经网络的案件情节精准量刑系统原理图;
图2所示为一种分级神经网络的案件情节精准量刑系统架构图;
图3为一案件实例的示意图;
图4所示为计算每项罪名的概率具体算法模型结构图;
图5所示为单案由算法结构示意图;
图6所示为案件描述的向量化矩阵示意图;
图7所示为各项情节的概率的算法模型结构图;
图8为计算案件刑期的模型算法结构图;
图9为实际系统输出结果。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
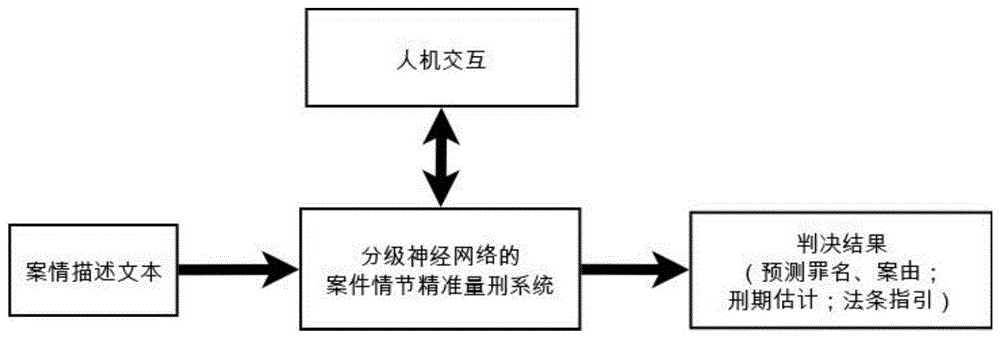
图1所示为一种分级神经网络的案件情节精准量刑系统原理图,如图1所示,分级神经网络的案件情节精准量刑系统包括:罪名和案由预测、量刑刑期预测、法条指引功能以及人机交互。
图2所示为一种分级神经网络的案件情节精准量刑系统架构图,如图2所示,一种分级神经网络的案件情节精准量刑系统架构包括两级第一级为罪名预测级第二级为情节量刑预测级。
如图2所示,第一级为“罪名预测级”:以自然语言形式的案件事实为输入,对输入文本进行分词处理。通过案件定罪特征库对文本进行抽取,其中定罪特征库可以由法律专业人士通过人工进行知识梳理创建,也可以通过海量案件数据的词频统计得到,抽取方式可以使用正则方式抽取,将案件中的定罪特征词进行one-hot编码,或更优的使用cbow与skip-gram模型进行词向量编码。
如图2所示,罪名预测级包括:定罪特征库、文本向量化表示模块、定罪分类神经网络以及预测罪名和案由模块。情节量刑预测级包括:高概率罪名案由排序过滤模块、情节量刑引擎案由量刑情节库、以及量刑估计模块。
输入一段自然语言形式的案件描述文本(案件事实)给罪名预测级以及情节量刑预测级,并最终输出案件的判决结果。
图3为一案件实例的示意图,如图3所示,案件描述文本输入给文本向量化表示模块后,通过文本向量化表示模块获得m个定罪语料库中的语料,每个语料对应一个向量,向量维度为(1*n),将m个向量按顺序合并产生(m*n)维矩阵,用于表征整个文本。
然后将该案情描述的向量化矩阵作为定罪分类神经网络的输入,计算每项罪名的概率。图4所示为计算每项罪名的概率具体算法模型结构图,如图4所示,采用3组卷积核分别为2个3临近词卷积核(1a,1b),2个4临近词卷积核(2a,2b),2个5临近词卷积核(3a,3b)分别对案件的(m*n)维的向量化文本进行卷积,结果进行激活函数后获得6个一维向量结果,在对这6个向量结果进行maxpooling池化抽样后连接得到一个新的(p*1)维向量,然后在将该向量作为多层感知的输入进入多层感知机(mlp),针对n个罪名,多层感知机应有n个输出并通过softmax函数得出各定罪罪名的概率,并发送给预测罪名和案由模块。预测罪名和案由模块根据罪名预测结果检索相关的规则知识库,得到罪名对应的特定的法条结果。
如图2所示,第二级为“情节量刑预测级”:以案情描述文本和第一级的各项罪名概率为高概率罪名案由排序过滤模块输入,选择过滤前k个概率最高的案由和罪名,针对这k个案由,以自然语言形式的案件事实为输入。第二级的某个单案由算法结构和第一级定罪算法是相似的。
图5所示为单案由算法结构示意图,如图5所示,案由量刑情节库由法律专业人士知识梳理而成,抽取方式可以使用正则方式抽取,将案件中的定罪特征词进行one-hot编码,或更优的使用cbow与skip-gram模型进行词向量编码。
图6所示为案件描述的向量化矩阵示意图,如图6所示,针对某个高概率案由k,生成案件描述的向量化矩阵。首先抽取获得m个情节判定库中的语料,每个语料对应一个向量,向量维度为(1*n),将个向量按顺序合并产生(m*n)维矩阵,用于表征整个文本。
图7所示为各项情节的概率的算法模型结构图,如图7所示,然后将该案情描述的向量化矩阵作为情节量刑引擎的输入(情节判定神经网络)的输入,计算各项情节的概率,其算法结构和第一级中的定罪模型结构相似。采用3组卷积核分别为2个3临近词卷积核(1a,1b),2个4临近词卷积核(2a,2b),2个5临近词卷积核(3a,3b)分别对案件的(m*n)维的向量化文本进行卷积,结果进行激活函数后获得6个一维向量结果,在对这6个向量结果进行maxpooling池化抽样后连接得到一个新的(p*1)维向量,然后在将该向量作为多层感知的输入进入多层感知机(mlp);针对可能b个情节,多层感知机应有b个输出,同时使用softmax函数得出各情节的概率,并选择出高于概率门限的情节组成情节向量表(b*1)维(概率大于门限t时,表征该情节的位置1,小于门限t时,则置0)。再将该情节向量表使用特定案由k的量刑神经网络计算案件刑期,图8为计算案件刑期的模型算法结构图,如图8所示,图9为实际系统输出结果。
针对案件情节精准量刑,本发明创新性地提出了两级分级深度神经网络系统,第一级为“罪名预测级”,第二级为“情节量刑预测级”。两级分级系统的好处:第一级为“罪名预测级”深度神经网络,第二级为“情节量刑预测级”深度神经网络。
该架构的好处在于将罪名和案由的预测同各个案由情节量刑的预测分开,极大地降低了神经网络算法的维度,对于案由和罪名的模型训练可以和具体某种案由的情节量刑判定的模型训练分开,从而降低系统整体模型的复杂程度,有助于极大提升训练效率和运算速度。
本发明创新性地将案由特征库构建和特定案由的情节判定库分开构建,有助于进行裁判文书样本的标注,降低对于标注人员的要求。
该发明针对某一特性案件描述,可以按概率高低排序给出预测的案由,情节量刑、法条指引等信息,有助于一线业务办案人员进行综合评估多案由的疑难案件。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!