一种基于均值漂移和XGBoost的异常用电判别方法与流程
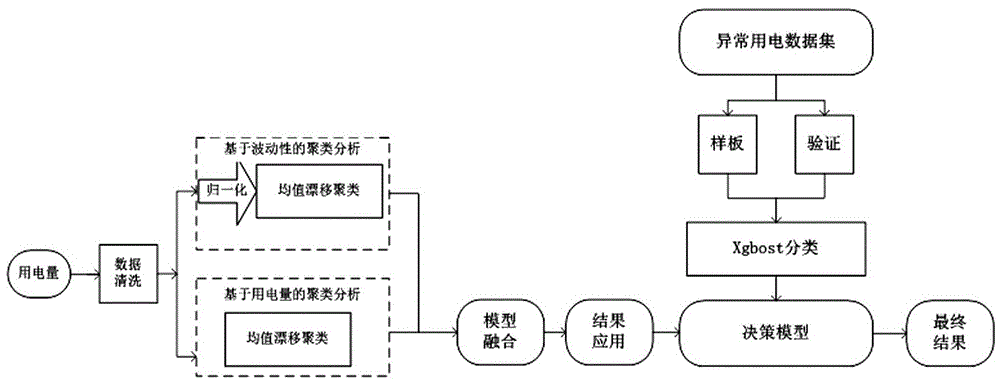
本发明属于电力
技术领域:
,尤其涉及一种基于均值漂移和xgboost的异常用电判别方法,具体是一种数据分析与挖掘的方法。
背景技术:
:当前,对于用电异常行为的手段除了常规用电检查手段外,也借助了一些数据统计手段,例如:按用户用电性质、电量同比、环比核查,对台区、专变用户和电量异常用户进行分析,排查可能存在异常用电的用户。利用基于标准的k-means聚类分析方法来实现用户用电分析是一种常见方法,但是,k-means需要事先确定分几类合适,并且,不能单一地从用电量和用电特征就判定是否异常用电。并且,上述手段需要大量的人工核查识别工作,效率较低且工作量大,在面向动辄上千万条记录的用电量数据时,常用方法无法运行。普通居民每日的用电量比较有限,商业用电用电量一般会比较大;居民用电工作日与周末用电量可能会有波动,部分24小时营业的商业用电则相对平稳。如果在档案中登记为居民用电的,但是用电量与用电波动性方面却较为符合商业用电的特征,则认为该用户异常用电的可能性较大。聚类个数不能简单地认定为居民和非居民2种,所以采用均值漂移算法来对用电量与用电波动性进行聚类,再结合两者结果输出结果,但这样的结果往往误判率较高,或者输出结果集数量较多,无法进一步筛选。技术实现要素:针对上述现有技术中存在的问题,本发明提供了一种基于均值漂移和xgboost的异常用电判别方法,其目的是为了实现在海量的用电数据中,快速、高效、准确地找出在居民用电中的异常情况,辅助用电稽查,规范用电。为实现上述发明目的,本发明是采用如下技术方案来实现的:一种基于均值漂移和xgboost的异常用电判别方法,包括以下步骤:步骤1:采集台区用户的日冻结用电量信息,通过行列转置将日期转置为列标,定义公式pij(i=1,2,…,k;j=1,2,…,n)表示用户i在第j天的用电量;步骤2:基于用电量信息及用电量归一化后的用电波动性进行均值漂移聚类分析;步骤3:对步骤2得到的均值漂移聚类结果差别进行标识,并对聚类分析结果取交集,形成初始疑似异常用电列表;步骤4:从已经确认的异常用电名单中选取80%作为样本进行训练学习,形成基于用电数据的决策树模型;用决策树模型对剩余20%的异常用电名单的数据进行验证,并不断优化调整决策树模型;步骤5:利用步骤4中得到的决策树模型对步骤3中的疑似异常用电列表进行二次筛选,得到最终的异常用电名单。所述用电量归一化方法指面向所有数据统一的归一化处理,表示如下:其中:pij表示第i个用户第j个日期的用电量。所述均值漂移聚类分析的方法步骤如下:步骤2.1:选取随机中心点c;步骤2.2:计算其他数据点与中心点c的欧氏距离小于半径h的集合m;步骤2.3:计算从中心点开始到集合m中每个元素的向量,将这些向量相加,得到偏移向量;步骤2.4:将该中心点沿着偏移的方向移动,移动距离就是该偏移向量的模;中心点偏移方法,表示如下:xt+1=mt+xt其中,mt为t状态下求得的偏移均值;xt为t状态下的中心;步骤2.5:迭代步骤2.2~2.4,得到偏移向量的大小满足偏移量阈值的中心点;步骤2.6:迭代步骤2.1~2.5,对各点进行归类。所述偏移向量计算方程,表示如下:其中,sh:表示以x为中心点,半径为h的高维球区域;k:表示包含在sh范围内点的个数;xi:表示包含在sh范围内的点。进一步的,步骤3中所述均值漂移聚类结果进行标识与交集的方法,表示如下:取用电量聚类结果中心曲线中除去数量最少的,以及居民用户占比在5%以下或95%以上的类别集合c1;以及用电波动性最大的聚类类别c2,取c1∩c2。进一步的,步骤4中所述基于用电数据的决策树模型建立步骤如下:步骤4.1:对异常用电名单中选取的80%样本进行行列转置,缺失补0;步骤4.2:设置num_class为2,利用xgboost算法建模;步骤4.3:模型验证,参数调整。进一步的,步骤4中所述决策树模型,其目标函数表示如下:其中i表示第i个样本,表示第i个样本的预测误差,l表示预测误差,k表示建立了k个回归树,fk表示回归树的复杂度的函数。所述步骤1中采集台区用户的日冻结用电量信息,日冻结电量的数据以列的列式存储,一个用户一天的数据为一条记录;一个用户一年的数据为365条记录;首先按照日期由远及近的方式进行排列,并通过行列转置将日期转换为列标,使得整理后的数据每行代表一个用户,上表中用户日冻结用电量信息转换之后记录;用公式pij(i=1,2,…,k;j=1,2,…,n)表示用户i在第j天的用电量。所述步骤2中:基于用电量的均值飘移聚类分析,是根据用户的日用电量信息将用户按照均值标称的思路进行分类,在一年的用电量数据中:s1.在用电量数据,长度为365的数列集合中随机选取一个作为初始中心点c;s2.计算得出其他数据点与当前中心点欧氏距离小于半径h的所有点;s3.计算从中心点开始到集合m中每个元素的向量,将这些向量相加,得到偏移向量;偏移均值的公式如下:其中,sh:表示以x为中心点,半径为h的高维球区域;k:表示包含在sh范围内点的个数;xi:表示包含在sh范围内的点;s4.将该中心点沿着偏移的方向移动,移动距离就是该偏移向量的模;移动公式如下:xt+1=mt+xt其中,mt为t状态下求得的偏移均值;xt为t状态下的中心;s5.迭代步骤s2~s4,直到偏移向量的大小满足设定的阈值要求,记住此时的中心点;s6.迭代步骤s2-s5,直到所有的点都被归类;s7.根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。所述步骤4中从已经确认的异常用电名单中选取80%作为样本进行训练学习,形成基于用电数据的决策树模型,是对样本数据同样作行列转置,并将缺失的值补0;给定相应的训练参数,包括树的最大深度,收缩步长;使用归一化指数函数softmax进行训练;分类结果为异常和正常二分类,设置分类结果参数num_class类别个数为2模型输出值是样本为第一类的概率,将概率值转化为0或1,即异常和正常两类。本发明的优点及有益效果是:随着用户用电分析的逐步深入,发现一些用电客户的用电特征与当时档案登记的用电类型不一致,例如,登记为居民用电,但是用电量及用电特征与商业用电很相像,猜测其在实际用电过程中出现了异常用电的现象。发明将用户分为具有特征的几类,并利用xgboost决策树算法来提升结界输出的准确性。本发明利用机器学习的方法,进一步过滤结果,以用电量和用电波动相结合的方式,找出异于常规的用电特征,在此基础上利用决策树模型进行二次过滤,异常用电的判断更加高效准确。本发明方法相关参数经过实际验证,满足实际需求。异常用电的查找准确率在80%以上,解决了异常用电客户的检测问题,其应用市场较为广阔。附图说明为了便于本领域普通技术人员理解和实施本发明,下面结合附图及具体实施方式对本发明作进一步的详细描述,以下实施例用于说明本发明,但应当理解本发明的保护范围并不受具体实施方式的限制。图1为本发明异常用电判别方法流程图;图2为本发明针对样例数据对用电量进行聚类的结果;图3为本发明针对样例数据对用电波动性进行聚类的结果。具体实施方式本发明是一种基于均值漂移和xgboost的异常用电判别方法,包括以下步骤:步骤1:采集台区用户的日冻结用电量信息,通过行列转置将日期转置为列标,定义公式pij(i=1,2,…,k;j=1,2,…,n)表示用户i在第j天的用电量;上式中:pij表示用户i在第j天的用电量,i表示用户,j表示第j天。步骤2:基于用电量信息及用电量归一化后的用电波动性进行均值漂移聚类分析;所述用电量归一化方法,指面向所有数据统一的归一化处理,表示如下:其中:pij表示第i个用户第j个日期的用电量。所述均值漂移聚类分析的方法具体步骤如下:步骤2.1:选取随机中心点c;步骤2.2:计算其他数据点与中心点c的欧氏距离小于半径h的集合m;步骤2.3:计算从中心点开始到集合m中每个元素的向量,将这些向量相加,得到偏移向量;所述偏移向量计算方程,表示如下:其中,sh:表示以x为中心点,半径为h的高维球区域;k:表示包含在sh范围内点的个数;xi:表示包含在sh范围内的点。步骤2.4:将该中心点沿着偏移的方向移动,移动距离就是该偏移向量的模;中心点偏移方法,表示如下:xt+1=mt+xt其中,mt为t状态下求得的偏移均值;xt为t状态下的中心;步骤2.5:迭代步骤2.2~2.4,得到偏移向量的大小满足偏移量阈值的中心点;步骤2.6:迭代步骤2.1~2.5,对各点进行归类;步骤3:对步骤2得到的均值漂移聚类结果差别进行标识与交集,形成初始疑似异常用电列表;所述均值漂移聚类结果进行标识与交集的方法,表示如下:取用电量聚类结果中心曲线中除去数量最少的,以及居民用户占比在5%以下或95%以上的类别集合c1;以及用电波动性最大的聚类类别c2,取c1∩c2。步骤4:从已经确认的异常用电名单中选取80%作为样本进行训练学习,形成基于用电数据的决策树模型。用决策树模型对剩余20%的异常用电名单的数据进行验证,并不断优经调整决策树模型。基于用电数据的决策树模型建立步骤如下:步骤4.1:对异常用电名单中选取的80%样本进行行列转置,缺失补0;步骤4.2:设置num_class为2,利用xgboost算法建模;步骤4.3:模型验证,参数调整。所述决策树模型,其目标函数表示如下:其中i表示第i个样本,表示第i个样本的预测误差,l表示预测误差,k表示建立了k个回归树,fk表示回归树的复杂度的函数。步骤5:利用步骤4的决策树模型对步骤3的疑似异常用电列表进行二次筛选,得到最终的异常用电名单。本发明具体步骤为针对用电量数据,首先进行数据清洗与相关处理;利用均值漂移方法对用电量数据进行聚类;将数据归一化后同样进行聚类;选取用电量大且用电波动幅度大的用户作为疑似异常用电用户;利用已知的异常用电样本数据,基于xgboost分类进行训练形成模型,对前期聚类形成的结果进行差别,输出最终结果,如图1所示,图1为本发明异常用电判别方法流程图。实施例1:本发明具体实施步骤如下:步骤1.采集台区用户的日冻结用电量信息,日冻结电量的数据以列的列式存储,一个用户一天的数据为一条记录。一个用户一年的数据为365条记录,如表1所示。首先按照日期由远及近的方式进行排列,并通过行列转置将日期转换为列标,使得整理后的数据每行代表一个用户,上表中用户日冻结用电量信息转换之后记录,如表2所示。用公式pij(i=1,2,…,k;j=1,2,…,n)表示用户i在第j天的用电量。上式中:pij表示用户i在第j天的用电量,i表示用户,j表示第j天。步骤2.基于用电量的均值飘移聚类分析。根据用户的日用电量信息将用户按照均值标称的思路进行分类,同样以一年数据为例。s1.在用电量数据,长度为365的数列集合中随机选取一个作为初始中心点c;s2.计算得出其他数据点与当前中心点欧氏距离小于半径h的所有点;s3.计算从中心点开始到集合m中每个元素的向量,将这些向量相加,得到偏移向量;偏移均值的公式如下:其中,sh:表示以x为中心点,半径为h的高维球区域;k:表示包含在sh范围内点的个数;xi:表示包含在sh范围内的点。s4.将该中心点沿着偏移的方向移动,移动距离就是该偏移向量的模;移动公式如下:xt+1=mt+xt其中,mt为t状态下求得的偏移均值;xt为t状态下的中心。s5.迭代步骤s2~s4,直到偏移向量的大小满足设定的阈值要求,记住此时的中心点。s6.迭代步骤s2-s5,直到所有的点都被归类。s7.根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。步骤3.根据步骤2得到的均值漂移聚类得到的结果,对每个类别的用户用电量特性进行分析,确定每类用户的用电特点。步骤4.基于用电波动性的用户聚类分析。根据步骤1的用户用电量数据,对同一个用户一年的用电量数据进行0-1归一化处理,用电量归一化方法公式如下:其中:pij表示第i个用户第j个日期的用电量。此步骤消除用电量大小对用电波动性特征的影响,归一化后利用步骤2的方法再进行聚类。步骤5.根据步骤2对用电量归一化之后的数据进行基于均值漂移聚类得到的结果,对每个类别的用户用电波动性特性进行分析,确定每类用户的用电波动性特点。步骤6.综合上述分布情况的统计,获取不同用电量类别的的特性及不同用电波动性类别的特性,一般为用电量大并且用电波动幅度较大的居民用户为疑似取异常用电的用户,具体方法为取用电量聚类结果中心曲线中除去数量最少的,以及居民用户占比在5%以下或95%以上的类别集合c1;以及用电波动性最大的聚类类别c2,取c1∩c2。步骤7.依据已确定为异常用电名单的数据,取其中80%作为样本数据,形成基于用电数据的决策树模型。对样本数据同样作行列转置,并将缺失的值补0。给定相应的训练参数,如树的最大深度,收缩步长。使用归一化指数函数softmax目标函数进行训练。因为分类结果为异常和正常二分类,设置分类结果参数num_class类别个数为2模型输出值是样本为第一类的概率,因此将概率值转化为0或1,即异常和正常两类。步骤8.利用步骤7生成的决策树模型,对异常用电名单的数据中剩余的20%进行分类,并与结果进行验证,计算模型分类的准确率,以调整相关参数,进一步优化模型,最终将模型固化。步骤9.利用步骤8固化的模型对步骤6输出的异常用电用户进行分类过滤,输出为最终的异常用电用户。结论:本发明所述的基于均值漂移和xgboost的异常用电判别方法,通过本发明的实施,能够快速准确地找出异常用电的用户,实现了自动化的稳定科学的判别方法。表1:用户的日冻结用电量信息notqbhyhbhyhmcdate…power106900xxxxxxx张xx2017/01/01…4.9206900xxxxxxx张xx2017/01/02…5.1…………………36506900xxxxxxx张xx2017/12/31…4.8表2:将用户日冻结用电量信息转换之后记录tqbhyhbh01010102…123106900xxxxxxx4.95.1…4.8当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1