一种构建基于不同长度名字刺激的ERP范式的方法与流程
本发明涉及erp范式领域,尤其涉及一种构建基于不同长度名字刺激的erp(event-relatedpotential,事件相关电位)范式的方法。
背景技术:
erp是外加一种特定刺激在脑的某一部位,或者当该刺激具有特殊的心理意义时,在大脑引起的电位变化,它代表大脑中一定的认知过程。p300是在刺激后约300ms出现的一个正电位。研究认为p300波幅与投入的心理资源量成正相关,其潜伏期随任务难度的增加而变长。一些研究认为p300代表认知任务的结束,另一些研究则认为其反映的是工作记忆的更新过程,可能代表着神经系统的某种基本活动,因此常成为erp的代名词。
目前bci(braincomputerinterface,脑机接口)领域中常用的erp范式有很多,包括视觉诱发、听觉诱发、触觉诱发,这些范式称为单通道范式,此外也有视听联合诱发范式、听觉和触觉结合诱发范式等多通道范式。但是多通道诱发范式的响应机制还不完全清楚,而且可能会出现刺激竞争的现象出现,所以单通道范式成为了当下使用最多的erp范式。眼睛是人类接收外界信息的最重要渠道,研究证明,人类大脑收集的外界信息有82%都是通过眼睛获取,而耳朵是仅次于眼睛的第二重要渠道,因此视觉诱发范式能够满足目前科研工作者们的大部分研究。
但是基于视觉范式的bci有其缺陷性,在使用过程中受试者必须目光注视着屏幕,有时还必须跟随着刺激画面的移动而移动,眼睛的注意力程度决定了实验结果的好坏,而听觉范式只需要听声音,往往只需要比视觉更小的注意力,且结果受眼球运动的影响不大。因此怎样找到合适的bci范式,有针对性地进行训练,是研究者们首先要解决的问题。
技术实现要素:
本发明提供了一种构建基于不同长度名字刺激的erp范式的方法,扩充了bci技术中使用的范式种类,使用自己的名字和不同长度的其他人名字刺激被试大脑,诱发被试的erp,利用不同长度的名字在语义和节律上的不同,它们刺激产生的erp波形的具有相同点和不同点,分析其差异性,以此设计合适的范式,并将其运用到bci中,通过听觉通道检测受试者的意识状态,详见下文描述:
一种构建基于不同长度名字刺激的erp范式的方法,所述方法包括:
使用eprime编写听觉刺激,刺激范式为oddball范式,每次实验的内容对于每名被试除了自己的名字不一样,其他都是一样的,passive和active分别代表被试处于被动不计数状态和主动计数状态;
将一次实验分为4个不同状态下的实验,称为4个block,每个block又分为5个trial,trial内的实验是一样的一个trial包含连续的20个iteration,每个iteration里有5个刺激,其中包括1个目标刺激和4个非目标刺激,序列伪随机呈现,相邻的两个刺激不会相同;每个刺激的持续时间为600ms,刺激间隔为500-800ms随机,整个实验流程控制在30min以内;
设置两组实验刺激,一组实验的非目标刺激为三个汉字长度的名字,另一组实验的非目标刺激为两个汉字长度的名字;
使用64导的ag/agcl电极帽获取eeg数据,用neuroscannuamp放大器进行信号的放大和打标签,并且将采集到的脑电数据传输到处理电脑上,用matlab软件对采集到的数据进行处理和分类,并进行特征提取。
所述特征提取具体为:对幅值特征和分类特征进行提取。
本发明提供的技术方案的有益效果是:
1、本方法选择了以名字为主要刺激的听觉范式,将非目标刺激设置为不同长度的名字,在传统的bci-erp研究上分析了不同的非目标刺激对大脑的影响;
2、本方法主要探究当背景刺激的名字长度与自己名字一样时,和背景刺激名字长度与自己名字的不同反应,使用bci时会产生不同的差异,从差异的大小程度可以解析出大脑的激活状态,建立意识检测方案;
3、本方法有益于对人体大脑状态的检测,扩充了bci技术中的范式选择,帮助解决非正常视力人群的bci使用等问题,可以应用于多个领域。
附图说明
图1为实验设计图;
图2为实验流程图;
图3为叠加erp波形图示例;
图4为平均脑电地形图示例;
图5为线性svm分类界面示例。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
本发明探究了被试大脑被动地对不同长度的陌生人名字的反应状态,以期检测被试在使用bci时的大脑反应。研究证明,名字刺激在erp研究中能够引发比单纯的正弦波音调更高的p300振幅。oddball范式经常被用来诱发erp-p300,其反应了大脑内的认知过程,它的产生和注意力集中有关。由于中国人的名字长度不相同,大脑在处理的时候可能有不同的认知过程,导致产生的p300振幅和潜伏期也不尽相同,当目标刺激确定为被试自己名字时,非目标刺激的名字长度就成为了变量。本发明通过比较不同长度名字之间的波形和显著性差异,从大脑对不同节律的刺激方面思考并设计范式,并将其运用于bci,探究不同刺激对被试大脑的不同激活状态。
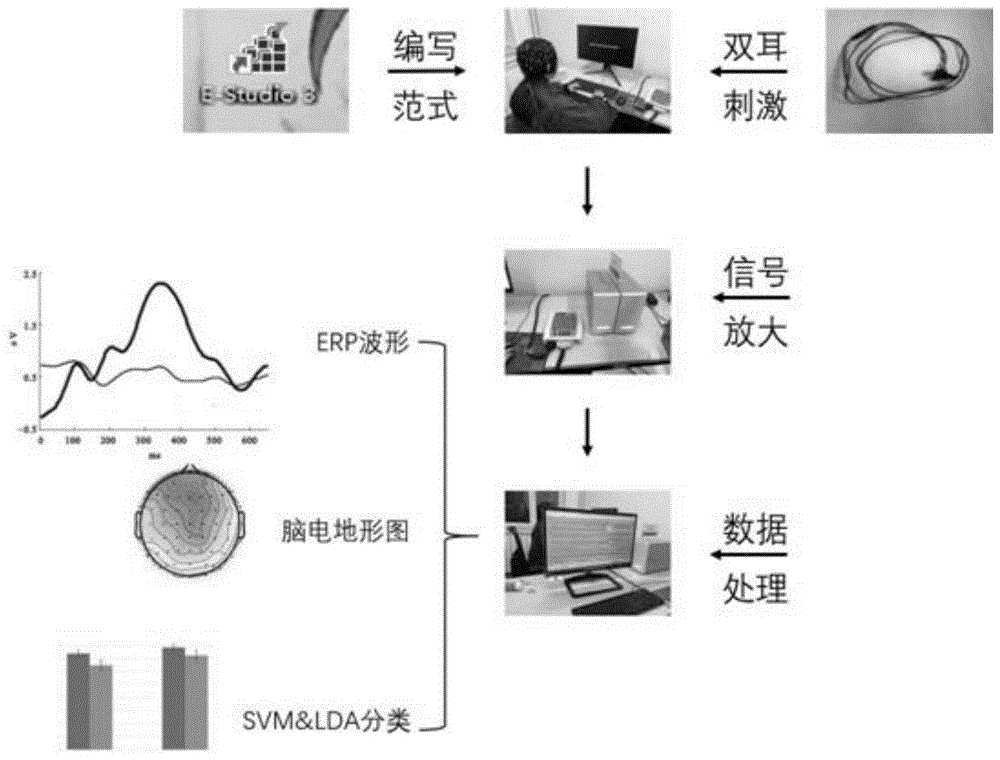
实验流程:用eprime软件编写范式,通过主机和显示屏呈现刺激。本方法使用64导的ag/agcl电极帽获取eeg数据,用neuroscannuamp放大器进行信号的放大和打标签,并且将采集到的脑电数据传输到处理电脑上,用matlab软件对采集到的数据进行处理和分类等过程。
本方法画出erp波形,分析不同长度的名字刺激之间的波形差异,并对平均波形做了逐行t检验(本领域的专业术语,本发明实施例对此不做赘述),画出具有显著性差异的区间,分析不同长度名字出现差异的时间段和特征。将数据放入支持向量机(supportvectormachine,svm)进行分类测试,观察其他不同长度名字之间的区别,找到相似性和差异性,分析本方法范式的可行性。
实施例2
如图1所示,本方法的设计包括:听觉刺激部分、脑电放大器采集部分、计算机处理部分等。
该设计的整套流程为:刺激声音为一名母语为汉语的男性中国人录制,使用专业的声卡与麦克风,在专门的录音棚,并且声音文件后期经过adobeaudition软件的去噪处理和平滑等。有了声音文件之后,使用eprime软件编写听觉刺激范式,受试者坐在电脑显示屏前的椅子上,声音通过插在电脑主机上的入耳式耳机进行双耳刺激。
本发明的系统使用neuroscan数字放大器进行脑电信号的采集,采样率为1000hz,做实验的过程中被试头上戴着ag/agcl电极帽。数据经过打包后传输到处理pc上,进行预处理和结果的分析等相关计算,包括画出刺激的erp波形、脑电地形图、t检验、进行svm分类等,根据所得结果对本发明设计的范式进行评估。
1)刺激范式
本发明中涉及的实验部分为使用eprime编写的听觉刺激,刺激范式为脑电研究中常用的oddball范式,该范式的特点是出现目标刺激和非目标刺激,他们以一定比例出现会诱发被试大脑的事件相关电位。
如图2所示。每次实验的内容对于每名被试来说除了自己的名字不一样,其他都是一样的,一次实验即为1名被试所做的实验。图中3cc代表非目标刺激为三个汉字长度的名字,同理2cc代表非目标刺激为两个汉字长度的名字,passive和active分别代表被试处于被动不计数状态和主动计数状态。本发明将一次实验分为4个部分,分别代表4次不同状态下的实验,称为4个block。每个block又分为5个trial,trial内的实验是一样的,设置5个trial的目的是为了让被试能有充分的休息时间,避免疲劳程度对实验的影响。一个trial包含连续的20个iteration,每个iteration里有5个刺激,其中包括1个目标刺激和4个非目标刺激,序列伪随机呈现,相邻的两个刺激不会相同。每个刺激的持续时间为600ms,刺激间隔为500-800ms随机,整个实验流程控制在30min以内。
本发明实验的重点是探究不同长度的名字刺激对大脑的影响,因此设计了不同长度背景名字下的oddball实验。在一次实验的5个刺激中,目标刺激的长度是不能更改的,因为它是被试自己的名字,但是非目标刺激为陌生人的名字,因此它可以改变。
于是本发明设置两组实验刺激,一组实验的非目标刺激为三个汉字长度的名字,另一组实验的非目标刺激为两个汉字长度的名字,以此探究大脑对节律不同的刺激反应。由于实验不要求被试特别关注其他人的名字,所以非目标刺激引发的波形从某种意义上来说更能体现大脑的自然反应。
2)预处理
在对信号进行正式的处理之前,本发明还需要对它进行一定的预处理,这是为了去除信号里的噪声。被试做实验的时候很可能有眼球的转动和肢体的不自觉运动,预处理的根本目的就是为了去除眼电扰动和肌肉伪影,净化信号。一般包括:变参考,滤波,降采样,独立成分分析(independentcomponentcorrelationalgorithm,ica)等简单过程。本发明先将全脑信号减去双耳乳突的平均值,这是一个空间滤波的过程;再把信号通过0.5-40hz的滤波器,滤除无关的高频信号;接下来将1000hz的信号降采样至100hz,为了凸显出erp波形;最后进行ica,根据ica的结果去除眼电和运动伪影。所有的预处理过程都由matlab的eeglab工具包完成。
3)特征提取
本发明根据幅值特征,提取了各个刺激的刺激前200ms到刺激后1000ms数据段进行分析,减去刺激前200ms的平均值进行去基线处理,以保证波形的稳定。进行时间段的划分之后,用一个阈值检测算法对所有的epoch进行峰值检测,若epoch中存在幅值大于80μv和小于-80μv的波,则在接下来的分析中排除这个epoch。这个过程对于不同长度的名字来说都是一样的,因为尽管非目标刺激的名字长度不一样,但是经过处理之后将每个刺激的刺激时间都固定在600ms,排除了时间长短可能造成的变化,专注于分析不同长度名字本身对大脑的影响。
(1)幅值特征:
erp波形的每个波峰都代表一定的含义,其中的p3波与定向活动有关,反映了认知过程,有研究证明p3的产生与大脑活动有密切关系,因此它成为了erp成分中的一支独宠,甚至有些资料上直接用p3来代表erp。本发明不关注目标刺激引发的波形,而是将分析重点放在不同长度的非目标刺激引发的波形差异上,当被试为两个字时对三个字的名字反应与被试为三个字时对两个字的名字反应,都可能不一样。画出平均波形之后,用t检验对不同名字的波形进行统计学分析,观察大脑对不同长度的非目标刺激之间的差异。
由于波形图一般只能表示出某个导联的时域特征,为了反映所有导联的大脑空间特征,本发明将波形图上显示p3时间窗的所有导联绘制成平均脑电地形图,得到反映头皮导联空间特征的大脑关系图。同样也分析了三个汉字长度的名字和两个汉字长度的名字的差异性,对两种长度的名字引发的特征进行平均,绘制出平均地形图之后再对每个导联进行t检验,画出导联间的差异地形图,可以从空间上很直观地观察出不同长度非目标刺激激活的大脑各个区域之间的显著性差异。
(2)分类特征:
在进行svm分类之前,为了保证样本量和特征维度的相互匹配,本发明通过利用权重向量w的后向消除过程进行特征筛选,称为svm递归特征消除法。首先,初始化特征子集f为所有特征的集合,每次选取一个特征,计算不考虑该特征时候模型的精度,若精度提升,则将该特征剔除f,直至精度不再下降。
根据式(1)计算权重系数w,排序分数c定义为w的平方如式(2),将c排序,删除对应最小c值的特征向量,重复此过程直到达到设定精度停止。
ci=(wi)2(2)
式中的参数如下:l代表特征数,i代表第i个特征,α代表拉格朗日乘子,y是判别函数,x是输入向量。
将特征值筛选到与样本量互相匹配,然后进行数据分类。采取留一法和线性svm相结合的方式进行分类,留一法是机器学习中对样本进行评估的一类方法,而svm则是机器学习中用得最多的分类方法。本发明将目标刺激与不同的非目标刺激进行分类训练,分别计算出三个字情况下的正确率和两个字情况下的正确率,算出每次所得正确率的平均值,将两者进行对比,并且通过t检验计算p值,分析两者在统计学上的差异性。
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!