一种基于Transformer模型的文本语义相似度预测方法
本发明涉及文本分析技术领域,尤其是涉及一种基于transformer模型的文本语义相似度预测方法。
背景技术:
文本语义相似度作为自然语言处理领域的一个基础课题,对文本分类、文本聚类、信息检索以及自动问答系统等研究方向具有重要的应用价值。对于任意两个文本对象——自然语言话语或者两段描述性的短文本,去判断这两个对象是否具有某种关系、是否具有相同的表达意图或者描述的是否是同一件事,即为这两个文本对象的语义相似度预测研究。
对于文本语义相似度的预测研究,传统方法大致分为三个阶段:数据统计、词向量优化、深度学习。在数据统计阶段,常常利用tf-idf(termfrequency–inversedocumentfrequency,词频-逆文本频率)技术、lda文档主题生成模型等方法,通过对文本的词进行定量分析,基于词频率、逆文本频率以及表达主题等方面,来判断两个文本对象是否具有相同或者相似的意图或描述,上述这些方法更加侧重于对词表面意思的挖掘,即利用广泛的语言表达,对每个词进行数据统计,以获得词的丰富信息,并推广到句子中,进行意图或描述的识别,由于只关注了词的表面信息,对于一些深层次隐含信息,则存在获取不到或者获取不足的问题;
在词向量优化阶段,一般利用文本嵌入技术,将词映射到高维空间,让每个词都能够拥有自己的数据分布,这就意味着词的信息被扩大了,也更加容易计算词与词之间的关系,在此阶段具有代表性就是word2vec(词向量模型)、glove模型等,这种方式不但可以获取词的向量表示,还可以计算词之间的距离,以及对词进行聚类分析,在一定程度上增加了隐含语义关系,但其依旧局限于词表面信息,不能充分获取深层次隐含信息;
在深度学习阶段,目前通常使用深度神经网络对文本特征进行抽取,并进行模式学习,以实现较好的特征提取效果,无论从语义信息捕获还是从泛化能力,都比传统的方法要好,常用的特征提取器主要有rnn(recurrentneuralnetwork,递归神经网络)、cnn(convolutionalneuralnetworks,卷积神经网络)和transformer模型,其中,rnn因其网络结构,使得其天生具有很好的长距离依赖捕获能力,在处理文本序列上具有很好的优势,但也因此损失了部分加速优化训练的能力;而cnn在加速优化方面优于rnn,但其对长距离依赖的处理能力欠佳;transformer模型则在处理文本数据上具有良好的泛化性能,且结合了rnn和cnn的优点,既具有良好的长距离依赖捕获能力,同时能够进行加速优化,但其语义信息捕捉能力较差,无法识别特定标识。
综上所述,对于文本语义相似度的预测研究,主要存在两方面问题:1、无法获取到文本深层次隐含信息;2、语义捕捉能力不足,上述两个问题最终将导致文本语义相似度预测结果的准确度不高。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种文本语义相似度预测方法,基于transformer模型良好的泛化性能,通过在嵌入信息上丰富向量表示,以提高特征捕获能力,从而保证文本语义相似度预测结果的准确性。
本发明的目的可以通过以下技术方案来实现:一种基于transformer模型的文本语义相似度预测方法,包括以下步骤:
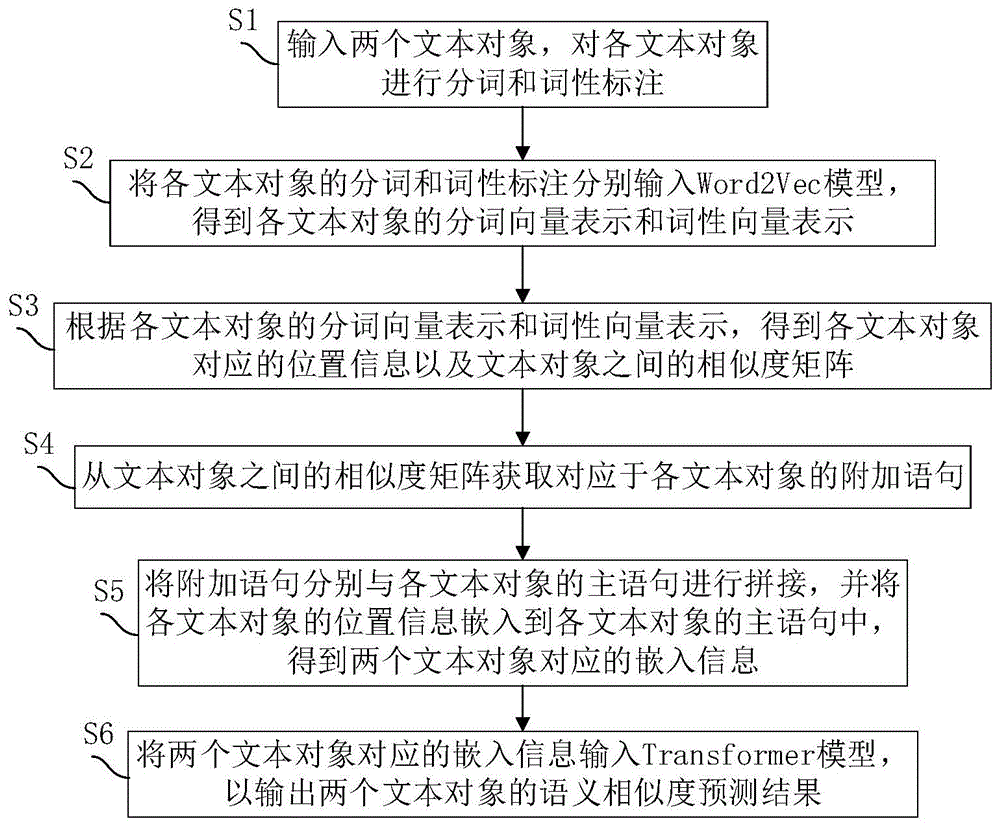
s1、输入两个文本对象,对各文本对象进行分词和词性标注;
s2、将各文本对象的分词和词性标注分别输入word2vec模型,得到各文本对象的分词向量表示和词性向量表示;
s3、根据各文本对象的分词向量表示和词性向量表示,得到各文本对象对应的位置信息以及文本对象之间的相似度矩阵;
s4、从文本对象之间的相似度矩阵获取对应于各文本对象的附加语句;
s5、将附加语句分别与各文本对象的主语句进行拼接,并将各文本对象的位置信息嵌入到各文本对象的主语句中,得到两个文本对象对应的嵌入信息,其中,主语句由该文本对象的所有分词按顺序排列组成;
s6、将两个文本对象对应的嵌入信息输入transformer模型,以输出两个文本对象的语义相似度预测结果。
进一步地,所述步骤s3具体包括以下步骤:
s31、根据各文本对象的分词向量表示和词性向量表示,基于各文本对象中分词之间的关系以及词性之间的关系,计算得到各文本对象的位置信息;
s32、根据各文本对象的分词向量表示,计算得到文本对象之间的分词相似矩阵;
s33、根据各文本对象的词性向量表示,计算得到文本对象之间的词性相似矩阵;
s34、结合分词相似矩阵和词性相似矩阵,计算得到文本对象之间的相似度矩阵。
进一步地,所述步骤s31的具体过程为:
s311、根据各文本对象的分词向量表示和词性向量表示,对于各文本对象,基于文本对象中所有分词的排列顺序,使用已知的分词依次对每一个分词进行编码,具体为:对于第一个分词,根据其后所有分词对其进行编码,从第二个分词开始,则使用当前分词前面的所有分词对当前分词进行编码,即得到文本对象中各分词的位置信息;
s312、利用softmax函数平衡文本对象中各分词位置信息的概率分布,得到该文本对象的位置信息。
进一步地,所述步骤s311具体是根据文本对象的分词向量表示和词性向量表示,通过计算文本对象中分词之间的相似度、欧式距离以及对应词性之间的相似度和欧式距离,并基于文本对象中所有分词的排列顺序,使用已知的分词依次对每一个分词进行编码,具体为:对于第一个分词,根据其后所有分词对其进行编码,从第二个分词开始,则使用当前分词前面的所有分词对当前分词进行编码,得到文本对象中各分词的位置信息:
pe1=pe1(a-1)
psumij=i+sim(wi,wj)+sim(pi,pj)+dist(wi,wj)+dist(pi,pj)
pmulij=i×sim(wi,wj)×sim(pi,pj)×dist(wi,wj)×dist(pi,pj)
其中,pe1为文本对象中第一个分词的位置信息,a为文本对象中分词的总数量,pel为文本对象中除第一个分词外的第l个分词的位置信息,pei(k)为第i个分词的编码,k为已知分词的数量,对于第一个分词而言,其对应的已知分词数量为位于第一个分词之后的所有分词的数量,从第二个分词开始,其对应的已知分词数量为位于该分词之前的所有分词的数量;
pesumik为第i个分词与其已知分词之间求和关系的累加值,pemulik为第i个分词与其已知分词之间求积关系的累积值,psumij为同一个文本对象中第i个分词和第j个分词之间的求和关系值,pmulij为同一个文本对象中第i个分词和第j个分词之间的求积关系值;
sim(wi,wj)、dist(wi,wj)分别为同一个文本对象中第i个分词向量表示wi和第j个分词向量表示wj之间的相似度、欧氏距离,sim(pi,pj)、dist(pi,pj)分别为同一个文本对象中第i个分词词性向量表示pi和第j个分词词性向量表示pj之间的相似度、欧式距离。
进一步地,所述步骤s312中文本对象的位置信息具体为:
pe=softmax([pe1,pe2,pe3...pea])。
进一步地,所述步骤s32中文本对象之间的分词相似矩阵具体为:
matrixαβ-sim=sim(wαμ,wβτ)(μ=1,2...m,τ=1,2...n)
其中,matrixαβ-sim为文本对象α与文本对象β之间的分词相似矩阵,wαμ为文本对象α中第μ个分词向量表示,wβτ为文本对象β中第τ个分词向量表示,sim(wαμ,wβτ)为文本对象α中第μ个分词与文本对象β中第τ个分词的相似度,m为文本对象α中分词总数量,n为文本对象β中分词总数量。
进一步地,所述步骤s33中文本对象之间的词性相似矩阵具体为:
matrixαβ-pos=sim(pαμ,pβτ)(μ=1,2...m,τ=1,2...n)
其中,matrixαβ-pos为文本对象α与文本对象β之间的词性相似矩阵,pαμ为文本对象α中第μ个分词词性向量表示,pβτ为文本对象β中第τ个分词词性向量表示,sim(pαμ,pβτ)为文本对象α中第μ个分词词性与文本对象β中第τ个分词词性的相似度。
进一步地,所述步骤s34中文本对象之间的相似度矩阵具体为:
matrixαβ=softmax(matrixαβ-sim+matrixαβ-pos)
其中,matrixαβ为文本对象α与文本对象β之间的相似度矩阵。
进一步地,所述步骤s6中的模型由依次连接的双线性采样模块、transformerblock和线性发生器组成,其中,双线性采样模块用于对两个文本对象的嵌入信息进行信息交互,transformerblock采用八个注意力头的结构。
进一步地,所述双线性采样模块对两个文本对象的嵌入信息进行信息交互的计算公式为:
bilinear(sen′α,sen′β)=sen′α×r×sen′β+b
sen′α={peα+senα,senβ-sim}
sen′β={peβ+senβ,senα-sim}
senα-sim=matrixαβ×senβ
其中,bilinear(sen′α,sen′β)为文本对象α的嵌入信息sen′α与文本对象β的嵌入信息sen′β之间的信息交互,r为权重矩阵,b为偏置值,
peα为文本对象α的位置信息,senα为文本对象α的主语句,senα-sim为文本对象α的附加语句;
peβ为文本对象β的位置信息,senβ为文本对象β的主语句,senβ-sim为文本对象β的附加语句。
与现有技术相比,本发明具有以下优点:
一、本发明通过对文本对象进行分词和词性的向量表征,基于文本对象中分词之间以及词性之间的相互关系,首先对文本对象中分词进行编码,后续扩展得到整个文本对象的位置信息,基于分词之间以及词性信息之间的相似度和欧式距离进行挖掘,能够全面有效地获取到文本对象的深层次隐含信息。
二、本发明利用文本对象之间的相似度矩阵得到附加语句,基于信息融合方法,将该附加语句对应地与文本对象的主语句进行拼接,同时嵌入对应的文本对象位置信息,既能够提高文本对象之间的交互性,同时丰富了文本对象表征,在嵌入信息上增加了特殊的有关位置信息的输入标识,有利于提高transformer模型对语义信息的捕捉能力。
三、本发明通过对文本对象的嵌入信息进行再一次地信息交互,能够进一步促进transformer模型对文本对象内部信息以及文本对象之间的信息进行关联,从而保证语义相似度预测结果的准确性。
附图说明
图1为本发明的方法流程示意图;
图2为实施例中的应用过程示意图;
图3为实施例中的应用效果示意图;
图4为实施例中文本对象的附加语句示意图;
图5为实施例中文本对象的嵌入信息示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
如图1所示,一种基于transformer模型的文本语义相似度预测方法,包括以下步骤:
s1、输入两个文本对象,对各文本对象进行分词和词性标注;
s2、将各文本对象的分词和词性标注分别输入word2vec模型,得到各文本对象的分词向量表示和词性向量表示;
s3、根据各文本对象的分词向量表示和词性向量表示,得到各文本对象对应的位置信息以及文本对象之间的相似度矩阵;
s4、从文本对象之间的相似度矩阵获取对应于各文本对象的附加语句;
s5、将附加语句分别与各文本对象的主语句进行拼接,并将各文本对象的位置信息嵌入到各文本对象的主语句中,得到两个文本对象对应的嵌入信息,其中,主语句由该文本对象的所有分词按顺序排列组成;
s6、将两个文本对象对应的嵌入信息输入transformer模型,以输出两个文本对象的语义相似度预测结果。
将上述方法应用于本实施例,其具体应用过程如图2所示,主要分为嵌入层、信息融合层和预测层:
采用第三方中文处理工具,分别将待进行预测判断的一对文本对象进行分词和词性标注,得到每个文本对象的分词列表和词性列表;
分别将每个文本对象的分词列表和词性列表输入word2vec模型中进行训练,以获得嵌入表示,其中,分词列表和词性列表分别作为待学习的嵌入数据,且词性列表的词性顺序与分词列表的词顺序相同;
根据文本对象中分词之间的关系以及词性之间的关系,从嵌入表示中获得文本对象之间的相似度矩阵和文本对象各自的位置信息;
从文本对象之间的相似度矩阵获得文本对象各自对应的附加语句;
对获得的信息进行融合:将附加语句对应地与文本对象的主语句进行拼接,并将文本对象的位置信息对应地嵌入到主语句的向量表示中,以得到两个文本对象的嵌入信息;
将两个文本对象的嵌入信息输入transformer模型中进行训练,以输出文本语义相似度预测结果,其中,模型采用包含两个transformerblock堆叠的形式,并在transformerblock之前对两个文本对象的嵌入信息再一次进行信息交互。
本实施例中,在嵌入层输入的两个文本对象为s1和s2,如图3所示,首先对s1和s2进行分词和词性标注,得到对应的分词列表和词性列表,s1的分词总数量为n,s2的分词总数量为m,之后利用训练好的word2vec词向量模型,分别得到对应的分词向量表示和词性向量表示:sen1={w11,w12,…w1n},sen2={w21,w22,…w2m},p1={p11,p12,…p1n},p2={p21,p22,…p2m},利用s1和s2对应的分词向量表示和词性向量表示,获得s1和s2各自的位置信息pe、s1和s2之间的相似度矩阵matrix:
1、获取s1和s2之间的分词相似矩阵和词性相似矩阵,分词相似矩阵matrixsim的计算如公式(1)所示:
matrixsim=sim(w1i,w2j)(i=1,2…m,j=1,2…n)(1)
即文本对象s1的第i个分词和文本对象s2的第j个分词的相似度,本实施例中,得到的matrixsim的维度为m×n。
词性相似矩阵matrixpos的计算如公式(2)所示:
matrixpos=sim(p1i,p2j)(i=1,2…m,j=1,2…n)(2)
即文本对象s1的第i个分词的词性p1i和文本对象s2的第j个分词的词性p2j的相似度,本实施例中,得到的matrixpos的维度为m×n。
按照公式(3)计算得到最终的相似度矩阵matrix,本实施例中,相似度矩阵matrix的维度为m×n:
matrix=softmax(matrixsim+matrixpos)(3)
2、在单个文本对象中,对于每一个分词的生成信息,均使用已知的分词对每一个分词进行编码,具体做法如下所示:
psumij=i+sim(wi,wj)+sim(pi,pj)+dist(wi,wj)+dist(pi,pj)(4)
pmulij=i×sim(wi,wj)×sim(pi,pj)×dist(wi,wj)×dist(pi,pj)(5)
其中,sim(wi,wj)、dist(wi,wj)分别表示同一文本对象中第i个词和第j个词之间的相似度、欧氏距离,sim(pi,pj)、dist(pi,pj)则分别表示同一文本对象中第i个词性和第j个词性之间的相似度、欧式距离;
k表示用于信息计算的已知分词数量,pei(k)表示在使用已知k个分词的情况下,得到第i个词的位置信息,wj为除去当前词wi之外的已知的其他分词,相应的pi,pj即为当前分词wi和其他分词wj所对应的词性;
对于第一个分词的位置信息pe1,我们使用其后的所有分词为先验知识,则有:
pe1=pe1(a-1)(9)
a为文本对象包含的分词数量,相应的其他单词的位置信息pel(l=2,3…a)如下所示:
利用上述的公式,可以得到文本对象中所有分词的位置信息,最后使用softmax函数平衡概率分布,得到文本对象的位置信息:
pe=softmax([pe1,pe2…pea])(11)
在信息融合层,如图4所示,从s1和s2之间的相似度矩阵matrix中分别获取s1和s2的附加语句,之后将s1和s2的附加语句分别对应地拼接到s1和s2的主语句之后,并将s1和s2各自的位置信息pe对应地嵌入到s1和s2的主语句向量表示中,得到如图5所示的s1和s2的嵌入信息。
在预测层,使用了2层传统的变换块(transformerblock),每层变换块均采用八个注意力头,并使用双线性采样模块(bilinear)对两个嵌入信息sen′1和sen′2进行再一次信息交互:
bilinear(x1,x2)=x1×r×x2+b(12)
input=bilinear(sen′1,sen′2)(13)
其中,r为权重矩阵,b为偏置值,x1,x2为输入的变量,即为输入的嵌入信息sen′1和sen′2。
综上所述,利用先验模型对文本内容的信息进行扩充,利用分词级别的编码,扩展到整个文本对象级别的编码,并利用词性信息对文本对象之间的关系进行挖掘,从语法、句法和词法的角度去获取这种关系;同时,应用信息融合策略,增强了文本对象之间的交互信息,以及基于生成关系的位置信息,将文本对象内部分词之间的关系添加到位置信息中,以便transformer模型能够学习到分词的顺序关系,并能够对文本对象内部和文本对象之间的信息进行关联;
本发明利用transformer模型的特征提取能力,利用其自身的自注意力优势以及对长距离依赖关系的捕获,在处理文本数据上具有良好的泛化性能,以及对比文本对象的结构特征,包括语法、句法、词法、句序(对比的顺序,采用主语句和附加语句拼接的形式)等信息,丰富了文本对象表征,提高了文本对象内部信息和文本对象之间信息的利用率;
并通过增加特殊输入标识,比如相似度矩阵、位置信息(设计了基于生成关系的位置信息,不同的分词在不同的文本对象的位置信息是不同的,并在设计位置信息时,将分词之间的关系以及词性之间的关系,包括相似度、欧式距离等信息添加到位置信息中),将语法、句法和词法的信息直接进行向量表征,让transformer模型在已有的信息上进行学习,能够增强transformer模型对语义信息的捕捉能力,从而提高语义相似度预测结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!