一种虚拟机迁移过程中活跃内存预测迁移方法与流程
本发明涉及虚拟机迁移技术领域,尤其涉及一种虚拟机迁移过程中活跃内存预测迁移方法。
背景技术:
大数据的产生,当今世界已经进入了一个数据爆炸的时代,尽管计算机硬件性能发展迅速,计算能力仍然是应用的瓶颈。云计算通过提供可配置的计算资源共享池,构成了一个高性能、高利用率、高可靠性的计算集群,规模的动态可伸缩,为计算带来了无限的可能,可以满足日益增长的用户规模和任务需求。为了实现这种无限的计算能力,云计算平台需要为不同的用户提供完全相互隔离的运行环境,还要对海量的计算资源进行动态分配并解决平台内部负载均衡以及数据安全和服务有效性的问题。
虚拟化作为云计算平台的核心,是实现上述特性的最佳解决方案,虚拟化技术在软件层面上对计算机的各种实体资源进行抽象化,打破了实体资源在物理结构上的限制,实现了虚拟机与物理资源之间的重映射,使得计算资源的隔离、整合与分配成为可能。虚拟机迁移技术作为虚拟化关键技术之一,能够为云计算平台的资源整合与分配、系统负载的动态调整、解决单点失效、优化系统能耗等多方面提供更具灵活性、可扩展性、易操作性的解决方案,是云计算平台实现负载均衡,提高系统容错性,保障系统可靠性和可扩展性的核心技术。
虚拟机迁移主要分为静态迁移和动态迁移。静态迁移过程中宿主虚拟机会停机很长一段时间无法提供服务,效率比较低而且用户体验不佳。动态迁移在整个迁移过程中保持虚拟机的持续运行,持续提供服务,迁移效率高,是目前研究的重点。
目前主流迁移方法是预拷贝算法和后拷贝算法。预拷贝迁移会首先迁移全部内存页面,同时在宿主主机端保持虚拟机持续运行并记录下运行过程中产生的脏页面,然后继续将所有脏页面拷贝至目的主机并再次记录这个过程中新产生的脏页面,如此循环经过多次迭代拷贝,直至脏页面的数量小于预设值、迭代拷贝达到指定次数或总体迁移页面数达到指定数量时,停止虚拟机的运行并完成最后一批脏页面的迁移,最后在目的主机上恢复虚拟机的运行。预拷贝迁移具有较短的停机时间并且在迁移前后都能够保证虚拟机的平稳运行,但是当虚拟机运行内存写密集型应用或网络传输速率较低时往往经过多次迭代拷贝依旧无法达成收敛,导致整体迁移时间过长,而且对脏页面的多次迭代拷贝也加大了网络传输数据量并长期占用网络资源。另外,在需要将虚拟机迁移至其他主机以降低宿主主机的负载的情况下,虚拟机仍旧会在宿主主机上继续运行一段时间,导致宿主主机的负载无法立即得到缓解,也不利于负载均衡模块以及能耗管理模块对系统进行整体调配。
后拷贝迁移在迁移开始时暂停宿主主机上虚拟机的运行,然后将虚拟机的基本信息、cpu上下文等恢复运行所必须的核心信息迁移至目的主机,随后立即在目的主机上恢复虚拟机的运行。虚拟机在恢复运行之后如果访问了尚未完成迁移的内存页面则会引发缺页错误,此时虚拟机会被挂起并向宿主主机发送远程缺页请求来获取所缺页面。宿主主机持续不断的将虚拟机的内存页面推送至目的主机,直至全部内存页面都发送完毕,与此同时持续监听来自于目的主机的缺页请求,并在接收到缺页请求后第一时间将所缺页面发送至目的主机。后拷贝迁移过程,虚拟机只在迁移核心信息时停止运行,迁移核心信息所花费的时间很短,因此后拷贝迁移具有虚拟机停机时间短的优点。后拷贝迁移的缺点在于虚拟机在目的主机上恢复运行时内存并不完整,经常会由于访问到尚未迁移完毕的内存页面而发生缺页错误导致虚拟机被挂起。在向宿主主机发出缺页请求与得到所缺页面之间存在网络延时,导致恢复运行后的虚拟机的工作性能出现衰退。
如果能够降低迁移过程中缺页错误的发生几率,将极大的提升预(后)拷贝算法迁移效率。通过对缺页错误的发生规律进行分析可以发现,虚拟机恢复运行初期由于内存迁移的完成度最低,此时发生缺页错误几率最高,而随着内存不断被主动推送至目的主机,缺页错误发生的几率也越来越低,性能退化的现象会逐渐缓解。因此,若能有效减少虚拟机恢复初期的缺页错误数量即可大幅提高后拷贝算法的效率。基于如上分析,我们提出了预记录(pre-record)算法,通过延长虚拟机在宿主主机的执行时间并记录即将被访问的内存页面,构成预记录内存页面集pps(pre-recordedpageset),迁移时优先迁移pps中内存页面,力图将被访问概率高的内存页优先迁移至目的主机,从而降低缺页错误发生的几率。
技术实现要素:
针对上述现有技术的不足,本发明提供一种虚拟机迁移过程中活跃内存预测迁移方法。
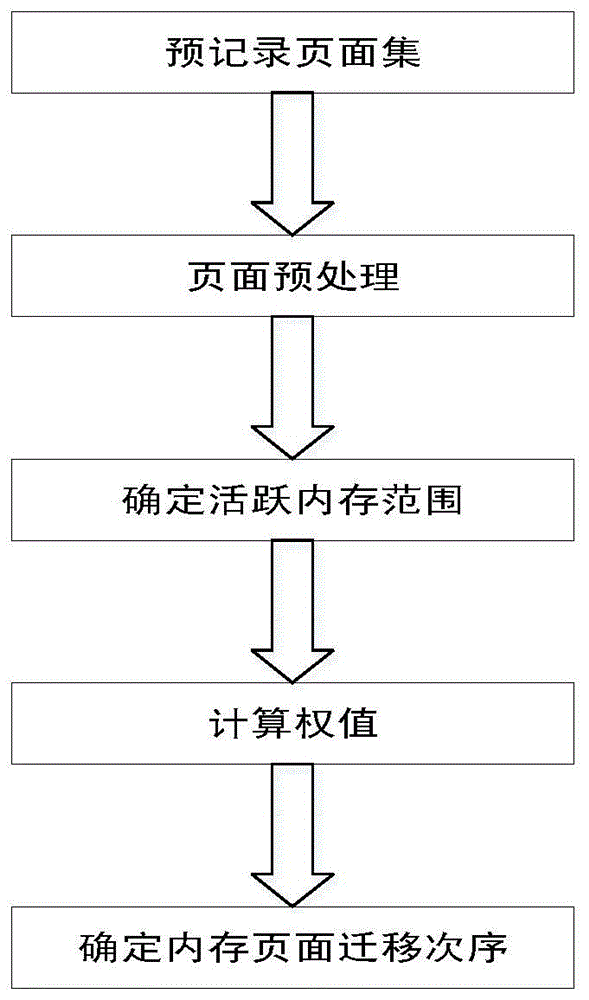
为解决上述技术问题,本发明所采取的技术方案是:一种虚拟机迁移过程中活跃内存预测迁移方法,其流程如图1所示,包括如下步骤:
步骤1:在迁移虚拟机核心数据的过程中保持虚拟机正常运行,虚拟机管理器记录一段时间内被访问过的内存的地址和被访问时间,形成预记录页面集;
步骤2:采用六元组表示每个内存页的方法,对预记录页面集进行预处理,得到内存页的集合p={p1,p2,p3,…,pi,…,pn},n为预记录页面的总数量,pi表示第i个内存页;
步骤2.1:将每个内存页地址转化为页框号:
其中,pagei表示当前内存页的页框号,addri表示第i个元素的内存地址addri,pagesize表示页的大小;
步骤2.2:判断集合p中是否已经存在页框号为pagei的元素,若不存在则将计算出的pagei插入集合p中的指定位置中创建一个新元素,初始访问次数numi=1,最新访问时间tmax=1;若存在则执行步骤2.3;
步骤2.3:增加页框号为pagei的内存页的访问次数numi,即numi=numi+1;更新内存页的最新访问时间,tmax=max{tmax,ti};更新被访问时间集合,将ti插入到集合ti中;
步骤2.4:采用六元组表示集合p中的每个内存页,记为pi={pagei,numi,tmax,ti,cluster,iscore};
其中,pagei表示当前内存页的页框号;numi为该内存页被访问的总次数;tmax为该页面最近一次被访问的时间;ti是页面所有被访问时间的集合;cluster为当前内存页的聚类号,根据聚类结果赋予相应的类号,未聚类前初始值均为-1;iscore指明当前内存页是否为聚类中的核心点。
步骤3:利用不规则顺序数列分布的特性对dbscan算法进行优化,采用优化后的iss-dbscan算法对内存页集合p进行聚类分析,即用预记录页面的地址作为特征进行聚类分析,将地址相近的页面划分为同一类簇,每个类簇都表示一块活动内存,进而推算出活动内存的位置与地址范围,确定活跃内存。活跃内存是具有高被访问概率的内存页框范围,也称之为“热区”;
步骤3.1:内存页集合p中所有的物理页框号按照从小到大的顺序进行排列,并构成一个不规则顺序数列,记为p’={page1,page2,…,pagei,…,pagen};
步骤3.2:在不规则顺序数列p’中判断当前节点pagei的邻域ε,并将ε邻域划分为左右两个部分分别为左邻域和右邻域,将两个部分中节点的数量分别记为εleft和εright;
步骤3.3:数据初始化:设置三个变量σcur、σleft和σcore,其中σcur保存当前节点的序号,σleft保存当前节点的左邻域的左边界点的序号,σcore保存区域扩张过程中最新发现的核心点的序号,于是可以将σcur、σleft和σcore指向的节点记为
步骤3.4:计算当前节点的密度并与核心点阈值m进行比较,判断当前节点
所述计算当前节点的密度并与核心点阈值m进行比较,判断当前节点
步骤3.4.1:找出领域ε的左边界节点pageleft和右边界节点pageright,在两个边界节点之间的所有节点都在当前节点的ε邻域内;
步骤3.4.2:计算出当前节点pagei的密度ρ(pagei)=right-left,其中right、left分别表示右边界和左边界节点编号;
步骤3.4.3:将密度ρ(pagei)与核心点阈值m相比较,判断当前节点是否为核心点,如果
步骤3.4.4:记录当前核心点,即σcore=σcur,将当前节点
步骤3.5:以步骤3.4发现的核心点为基础扩张区域;
步骤3.5.1:以σcur为起点,判断其与基础核心点σcore是否密度可达,如果密度不可达,将
步骤3.5.2:如果密度可达,进一步判断新节点是核心点还是边界点;如果新节点是一个核心点,将旧核心点和新核心点之间的节点都加入当前类簇cluster中,即将
步骤3.5.3:如果不是核心点,说明该节点为边界点,只将该节点归入当前聚类中但不修改σcore,把下一个节点赋给σcur,即σcur++;
步骤3.5.4:返回3.4.1继续扩张区域,至遍历所有节点止,即σcur≤n,n是节点的数量。
步骤3.6:清空σcore,并将σcur和σleft都指向区域外的第一个节点,然后返回到步骤3.4,寻找新的聚类区域,直至遍历集合中的所有节点;最后得到的类簇,每个类簇都表示一块活动内存。
步骤4:根据预记录页面被访问的时间、访问次数以及活跃内存与预记录页面的距离,计算每个活跃内存页面的优先级权值及其邻域范围;
步骤4.1:确定预记录页面的优先级。将页面pagei的所被访问时间的集合ti(ti={t1,t2,…,tnumi})内的元素进行累加,其值作为页面pagei的优先级。即页面pagei的优先级计算公式为:
其中,wi为页面pagei的优先级,numi表示被访问的次数。
步骤4.2:确定预记录页面的邻域范围,其示意图如图2所示;设某个热区中内存页的集合为p={p1,p2,…,pn},预记录页面集合为p={p1,p2,…,pm},n和m分别为热区内内存页面的总数量和预记录页面的数量,预记录页面的优先级集合为w={w1,w2,…,wm},将预记录页面pi(1≤i≤m)的邻域的左界记为neileft[i],右界记为neiright[i],该页面的邻域范围计算公式如下:
步骤5:以内存页面的优先级权值作为优先级的评判依据,调整活跃内存页面的发送次序。先按预记录页面优先级迁移预记录页面,然后迁移具有高被访问概率的“热区”中的页面,最后迁移剩余其他页面。在迁移热区中页面时以邻域为单位进行分批迁移,首先迁移具有最大tmax的预记录页面所处邻域范围内的页面,然后根据优先级wi的值的次序迁移其他邻域范围内的页面,直至“热区”中的所有页面迁移完毕。
采用上述技术方案所产生的有益效果在于:
(1)本发明采用六元组{该页面所在页框号,该内存页被访问的总次数,该页面最近一次被访问的时间,该页面所有被访问时间的集合,聚类号,该页面是否为聚类中的核心点}表示每个内存页,能够更有效地表示页面被访问情况;
(2)本发明利用不规则顺序数列分布的特性对dbscan算法进行优化,采用iss-dbscan算法对内存页集合p进行聚类分析,确定活跃内存范围,更能体现当前内存的活跃状态;
(3)本发明采用局部性原理计算活跃内存页面的优先级权值,即根据预记录页面被访问的时间、访问次数以及活跃内存与预记录页面的距离,计算每个活跃内存页面的权值;以内存页面的优先级权值作为优先级的评判依据,调整活跃内存页面的发送次序,提高了虚拟机迁移效率。
附图说明
图1为本发明一种虚拟机迁移过程中活跃内存预测迁移方法的流程图;
图2为本发明预记录页面的邻域示意图;
图3为本发明实施例中采用iss-dbscan算法进行预测分析需要耗费的时间;
图4为本发明实施例中不同负载情况下各迁移算法的工作效率。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示,本实施例的方法如下所述。
步骤1:使用预记录算法进行虚拟机迁移,在迁移虚拟机核心数据的过程中保持虚拟机正常运行,虚拟机管理器会记录下这段时间内被访问过的内存的地址和被访问时间。这一阶段被称为预记录阶段,这些被记录的内存页面被称为预记录页面,由预记录页面构成的集合称为预记录页面集。在预记录阶段,每当客户虚拟机对内存进行读写访问时,虚拟机管理器会记录下当前访问的内存地址和访问时间,可以创建一个二元组来记录这些信息,记为ri=(addri,ti),其中addri表示该次访问所对应的内存地址,ti表示该次访问的发生时间。创建集合r来保存所有的客户虚拟机对内存进行访问的信息,记为r={r1,r2,r3,…,rn},n为对内存访问的总次数。
步骤2:为了便于进行聚类分析,需要对预记录页面的信息进行预处理,对数据进行规范化,同时提取出有用的信息,以降低后期计算的工作量。
步骤2.1:对集合r中的元素进行转换,将每个内存页地址转化为页框号:
其中,pagei表示当前内存页的页框号,addri表示第i个元素的内存地址addri,pagesize表示页的大小;
以页框为单位可以降低计算规模,本实施例假设页框大小为4kb,计算量将缩减4096倍,可以极大的加快计算速度。
将addri转换为pagei后可以发现,同一个内存页可能在不同的时间点被多次访问,新的结果中应该能够表示出每个内存页被访问的情况。
将内存地址转换为页框号之后得到的内存页的集合用p来表示,记为p={p1,p2,p3,…,pn},n为预记录页面的总数量,集合p即为预记录页面集,集合p的创建过程如下:
步骤2.2:判断集合p中是否已经存在页框号为pagei的元素,若不存在则将计算出的pagei插入集合p中的指定位置中创建一个新元素,初始访问次数numi=1,最新访问时间tmax=1;若存在则执行步骤2.3;
步骤2.3:增加页框号为pagei的内存页的访问次数numi,即numi=numi+1;更新内存页的最新访问时间,tmax=max{tmax,ti};更新被访问时间集合,将ti插入到集合ti中;
步骤2.4:采用六元组表示集合p中的每个内存页,记为pi={pagei,numi,tmax,ti,cluster,iscore};
其中,pagei表示当前内存页的页框号;numi为该内存页被访问的总次数;tmax为该页面最近一次被访问的时间;ti是页面所有被访问时间的集合;cluster为当前内存页的聚类号,根据聚类结果赋予相应的类号,未聚类前初始值均为-1;iscore指明当前内存页是否为聚类中的核心点。
为了便于聚类,在生成集合p的同时对p中的元素根据页框号进行排序。
步骤3:利用不规则顺序数列分布的特性对dbscan算法进行优化,采用优化后的iss-dbscan算法对内存页集合p进行聚类分析,即用预记录页面的地址作为特征进行聚类分析,将地址相近的页面划分为同一类簇,每个类簇都表示一块活动内存,进而推算出活动内存的位置与地址范围,确定活跃内存;活跃内存是具有高被访问概率的内存页框范围,也称之为“热区”;
步骤3.1:内存页集合p中所有的物理页框号按照从小到大的顺序进行排列,并构成一个不规则顺序数列,记为p’={page1,page2,…,pagei,…,pagen};
预记录页面集合p中保存了被访问内存的物理页框号,物理页框号代表着页框在物理内存上的位置,因此以物理页框号为关键字进行聚类分析可以找出哪些页框在物理分布上呈现聚簇的趋势。物理页框号的取值范围为0~max_page,max_page为虚拟机的最大页框数。预记录页面集合p中的所有的物理页框号构成了一个数列,记为p’={pagen}。所有页框都已经按照从小至大的顺序进行排列,只是相邻的两个元素之间的距离是没有规律的,于是对预记录页面的聚类分析可以化简为在一维空间中对不规则(irregular)的顺序数列(sequentialseries)进行聚类分析。
步骤3.2:在不规则顺序数列p’中判断当前节点pagei的邻域ε,并将ε邻域划分为左右两个部分分别为左邻域和右邻域,将两个部分中节点的数量分别记为εleft和εright;
步骤3.3:数据初始化:设置三个变量σcur、σleft和σcore,其中σcur保存当前节点的序号,σleft保存当前节点的左邻域的左边界点的序号,σcore保存区域扩张过程中最新发现的核心点的序号,于是可以将σcur、σleft和σcore指向的节点记为
步骤3.4:计算当前节点的密度并与核心点阈值m进行比较,判断当前节点
所述计算当前节点的密度并与核心点阈值m进行比较,判断当前节点
步骤3.4.1:找出邻域ε的左边界节点pageleft和右边界节点pageright,在两个边界节点之间的所有节点都在当前节点的ε邻域内;
步骤3.4.2:计算出当前节点pagei的密度ρ(pagei)=right-left,其中right、left分别表示右边界和左边界节点编号;
步骤3.4.3:将密度ρ(pagei)与核心点阈值m相比较,判断当前节点是否为核心点,如果
步骤3.4.4:记录当前核心点,即σcore=σcur,将当前节点
步骤3.5:以步骤3.4发现的核心点为基础扩张区域;
步骤3.5.1:以σcur为起点,判断其与基础核心点σcore是否密度可达,如果密度不可达,将
步骤3.5.2:如果密度可达,进一步判断新节点是核心点还是边界点;如果新节点是一个核心点,将旧核心点和新核心点之间的节点都加入当前类簇cluster中,即将
步骤3.5.3:如果不是核心点,说明该节点为边界点,只将该节点归入当前聚类中但不修改σcore,把下一个节点赋给σcur,即σcur++;
步骤3.5.4:返回3.5.1继续扩张区域,至遍历所有节点止,即σcur≤n,n是节点的数量。
步骤3.6:清空σcore,并将σcur和σleft都指向区域外的第一个节点,然后返回到步骤3.4,寻找新的聚类区域,直至遍历集合中的所有节点;最后得到的类簇,每个类簇都表示一块活动内存。
iss-dbscan聚类算法的时间复杂度和空间复杂度:
算法时间复杂度:假设节点总数量为n,在对每个节点进行分析时主要完成以下几项工作:(1)移动σcur指向当前节点;(2)计算并移动左邻域σleft;(3)比较节点
算法空间复杂度:在使用iss-dbscan算法进行聚类分析时,需要额外建立一个大小与集合中节点数量相同的数组来保存每个节点的聚类号,此外还要保存三个游标σcur、σleft和σcore,因此算法的空间复杂度为o(n)+o(3)=o(n)。在对预记录页面集合进行聚类分析时,集合中的节点为六元组,记为pi={pagei,numi,tmax,ti,cluster,iscore}。其中cluster用来记录节点的聚类号,不需要再创建额外的数组来保存聚类号,只需要保存三个游标,因此算法的空间复杂度为o(n)。
步骤4:根据预记录页面被访问的时间、访问次数以及活跃内存与预记录页面的距离,计算每个活跃内存页面的优先级权值及其邻域范围;
步骤4.1:确定预记录页面的优先级。将页面pagei的所被访问时间的集合ti(ti={t1,t2,…,tnumi})内的元素进行累加,其值作为页面pagei的优先级。即页面pagei的优先级计算公式为:
wi为页面pagei的优先级,numi表示被访问的次数。
步骤4.2:确定预记录页面的邻域范围,其示意图如图2所示。
当前节点pagei的邻域范围是利用优先级来确定的。夹在两个预记录页面之间的内存页面分别归属于不同的邻域,邻域的分界点由两端的预记录页面的优先级决定。假设有两个相邻的预记录页面分别为pa和pb,优先级分别为wa和wb,pa和pb之间共有y个页面,那么前
热区中第一个预记录页面的左界为热区中的第一个页面,最后一个预记录页面的右界为热区中的最后一个页面。设某个热区中内存页的集合为p={p1,p2,…,pn},预记录页面集合为p={p1,p2,…,pm},n和m分别为热区内内存页面的总数量和预记录页面的数量,于是有m≤n且
步骤5:以内存页面的优先级权值作为优先级的评判依据,调整活跃内存页面的发送次序。先按预记录页面优先级迁移预记录页面,然后迁移具有高被访问概率的“热区”中的页面,最后迁移剩余其他页面。在迁移热区中页面时以邻域为单位进行分批迁移,首先迁移具有最大tmax的预记录页面所处邻域范围内的页面,然后根据优先级wi的值的次序迁移其他邻域范围内的页面,直至“热区”中的所有页面迁移完毕。
在利用被访问时间的累加值作为优先级时,访问次数多的旧页面的优先级会比新页面高,通常来讲这是符合正常规律的。但是预记录页面集合中最后一个被访问的页面具有特殊性。通常来讲系统对内存的访问具有延续性,因此,在系统接下来运行的过程中有很大几率会访问最后一个被访问页面的邻域内的页面。而通过
本实施例实验环境是三台物理主机通过路由器连接组成局域网络作为迁移环境,其中一台物理主机作为nfs服务器保存虚拟机的磁盘文件,另外两台主机分别作为迁移中的宿主主机和目的主机。实验使用的负载程序为memtester内存测试软件,在memtester上实现了顺序、逆序、完全随机、高斯随机和帕累托随机这五种内存读写模式,通过实验来观察本发明的方法在各种内存读写模式下的工作性能。
实验中并发运行10个memtester进程,每个进程占有30mb内存空间。修改预记录页面集的最大扩展次数,使预记录页面集的最大存储空间分别为20mb、40mb、60mb、80mb和100mb,同时修改宿主主机端预执行的停止条件,在核心信息迁移完毕后保持虚拟机运行,直至预记录页面集达到存储空间上限之后才停止虚拟机。通过这样的方式来让iss-dbscan算法对不同大小的数据集进行分析,观察算法的处理时间,实验结果如图3所示。实验结果表明本发明的方法可以在很短的时间内完成预测工作。尽管随着预记录页面集的存储空间的上限的提高,iss-dbscan算法需要处理的数据量逐渐加大,算法耗费的时间也呈现递增的趋势,但与迁移中虚拟机的停机时间相比仍旧处于较低的水平。当预记录页面集的存储空间为100mb时,预测需要花费的时间约占停机时间的50%,而当存储空间为20mb时,预测所需要的时间仅占停机时间的10%。与线性回归预测法相比,在数据集规模较小的情况下iss-dbscan算法的耗时略有增加,但是随着数据集规模的增加,iss-dbscan所要花费的时间增长速度要明显要低于线性回归预测,当预计录页面集的存储空间达到100mb时,预测所花费的时间仅为线性回归预测的60%,并且随着数据集规模的增加这个差距将会进一步增大。
本实施例还在负载应用的数量不同、占用内存空间的大小不同以及对内存的访问模式不同的情况下,观察本发明的方法在减少预记录迁移过程中远程缺页错误数量方面所发挥的作用,并与未经优化的预记录迁移和基于线性回归预测的预记录迁移相比较,观察在不同情况下预测算法的效果。实验结果如图4所示。实验结果表明iss-dbscan聚类分析可以进一步降低预记录迁移过程中远程缺页错误的数量,从而提高迁移算法的工作效率。从实验结果中可以看出,当负载进程数量较少且单个进程占用空间较大时,虽然两种算法在完全随机模式下均无法得到理想的效果,但是线性回归预测在顺序和逆序的内存访问模式中工作的效果更佳,而iss-dbscan算法在各种随机分布的访问模式中均可以获得不错的效果提升。而随着负载进程数量的增多且单个进程占用的空间逐渐缩小,iss-sbscan算法开始发挥优势,特别是在实验(d)中,无论是在顺序、逆序还是各种随机访问模式下,iss-dbscan的效果均要优于线性回归预测,并且即使在完全随机的模式下也可以有效的减少缺页错误的数量。这是因为线性回归预测的侧重点在于对访问趋势进行预测,而iss-dbscan聚类分析更加侧重于对活动内存所处区域的预测。在负载应用所占内存较大且对内存的访问有明显的趋势性时线性回归预测能够发现访存轨迹的趋势性从而获得更好的优化效果。而在负载应用进程数量较多且占用内存页较小时,各个进程在预记录页面集中留下的记录会趋于分散并造成趋势性减弱,线性回归预测的效果也会减弱。而此时iss-dbscan聚类分析可以很好的分辨出各个进程的活动内存的位置并优先进行迁移,从而获得更加优异的优化效果。在完全随机访问的模式下各个预测算法均很难找出访存轨迹中的变化规律并对虚拟机下一阶段将要访问的内存做出预测,没有办法有效的减少缺页错误的数量。而此时iss-dbscan算法却可以通过聚类分析的方法找出虚拟机中活动内存的位置,并且在进程占有内存页较小时能够发挥更好的效果,这也是本发明的方法最大的优势所在。
- 还没有人留言评论。精彩留言会获得点赞!