基于虚拟数据库的电力通信网络异地异构数据源整合方法与流程
本发明涉及电力通信技术领域,具体为基于虚拟数据库的电力通信网络异地异构数据源整合方法。
背景技术:
在电力通信网络中,存在大量的异地异构数据,用户通过远程调度和访问方法进行异地异构数据方位和查询。异地异构数据的数据结构复杂,导致数据调用容易出错,开发成本高,其数据源整合也因此成为该领域研究的重点内容。
特征提取方法是一种采用特征提取技术抽取虚拟数据库异地异构数据的平均互信息特征量,结合关联规则挖掘方法进行虚拟数据整合。通过对异地异构数据源的采集,搭建hive数据仓库,并对异地异构数据源进行分析与整理,最后采用java开发语言搭建异地异构数据源整合系统,实现异地异构数据源的整合。但上述方法存在时间开销较大、查准率低等问题。
技术实现要素:
本发明主要是提供基于虚拟数据库的电力通信网络异地异构数据源整合方法,解决现有技术中方法存在时间开销较大、查准率低等问题。
为了解决上述技术问题,本发明采用如下技术方案:
基于虚拟数据库的电力通信网络异地异构数据源整合方法,该方法包括以下步骤:
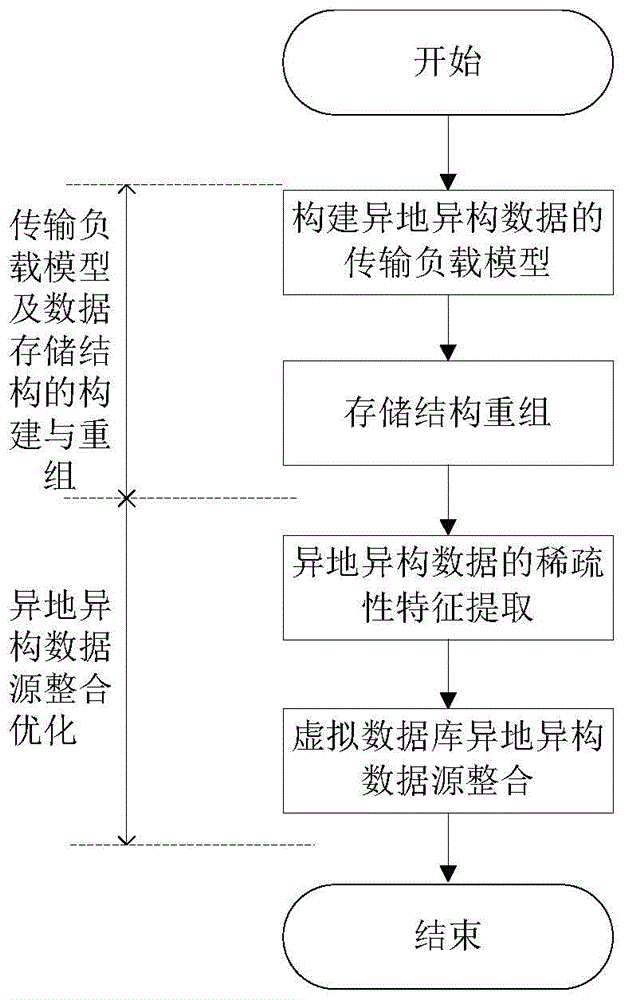
步骤一,进行传输负载模型及数据存储结构的构建与重组;
为实现对虚拟数据库异地异构数据源整合算法的优化设计,需利用虚拟数据库异地异构数据存储节点的分布式结构重组方法,构建异地异构数据的传输负载模型;利用相空间重构方法进行虚拟数据库异地异构数据的特征重构,根据重构特征建立虚拟数据库异地异构存储结构模型。
步骤二,进行异地异构数据源整合优化;
在传输负载模型与数据存储结构的基础上,进行异地异构数据源整合及优化。本节将采用虚拟数据库技术实现数据源整合的过程,该技术的主要内容包括对异地异构数据的稀疏性特征提取,以及数据源整合模型的构建。
使用时,首先需提取异地异构数据源中的数据特征,在对异地异构数据的特征提取基础上,通过挖掘虚拟数据库异地异构数据的有效特征值,构建虚拟数据库异地异构数据的整合模型,实现虚拟数据库异地异构数据源整合。
进一步,其中所述步骤一包括以下子步骤:
a,构建异地异构数据的传输负载模型;
为了在模糊网格区域聚类环境下,得到源组合模式下异地异构数据的边缘特征分布集;
b,存储结构重组;
采用相空间重构方法进行虚拟数据库异地异构数据的特征重构,实现储存结构的重组。
进一步,其中所述步骤二包括以下子步骤:
a,异地异构数据的稀疏性特征提取;
在采用相空间重构方法进行虚拟数据库异地异构数据的数据存储结构重构的基础上,进行异地异构数据源整合方法的优化设计。
b,虚拟数据库异地异构数据源整合。
进一步,所述a步骤包括:
a01,用二元有向图g=(v,e)表示虚拟数据库异地异构数据的图模型结构,其中,v是虚拟数据库的分布节点的顶点集;e是虚拟数据库异地异构数据的有向边集合;
a02,设m1,m2lmn为虚拟数据库异地的sink存储节点,采用多元回归分析方法提取异地异构数据的相关性统计特征量,得到虚拟数据库的分布式拓扑结构模型;
a03,结合a02中的所述虚拟数据库的分布式拓扑结构模型,获取虚拟数据库异地异构数据检测的测度信息;
a04,在存储网络结构模型中,数据组合模型的有向图向量的加权系数为ws={w1,w2,l,wk},在虚拟数据库异地异构数据的信息覆盖区域,假设m个传输链路层,统计数据的离散分布形式为x(k-1),….,x(k-m),则虚拟数据库异地异构数据的模糊节点差分xs的估计值:
式(1)中,ws代表差分系数,基于模糊节点差分的估计值,构建虚拟数据库异地异构数据的传输负载模型:
式(2)中
式(3)中,ω(t)为虚拟节点的数据维数;ph(t)为虚拟数据库异地异构数据source与sink储存节点之间的距离;bi为异地异构数据的传输负载损失量。
进一步,所述b步骤包括:
b01,对异地异构数据进行离散融合处理:
式(4)中,tv代表顶点集的融合系数;βv代表数据离散估计参量;adj(a,c)表示重构向量a与c的个数,经式(4)得到异地异构数据的离散融合函数tr;
b02,利用b01中的所述tr函数求得异地异构数据分布特征集t0的统计特征量:
t0={t1,t2,...,t0}(5)
其中,对所述特征集t0求解特征量:
根据求得的所述特征量进行特征重组:
βd=(mpdist-d+1)/mpdist,d∈[2,mpdist](7)
采用特征提取技术在所述特征重组的数据特征中抽取平均互信息特征量,得到虚拟数据库异地异构数据的存储结构重构过程为:
i(q,s)=h(q)-h(q|s)(8)
其中
b03,结合所述平均互信息特征量,采用模糊相关性特征匹配方法进行虚拟数据库异地异构数据的主成分分析,实现数据存储结构重组。
通过对异地异构数据进行离散融合处理,计算密集场景中虚拟数据库异地异构数据分布特征集t0的统计特征量,完成储存结构的重组。
通过虚拟数据库异地异构数据的传输负载模型及数据存储结构的构建与重组,完成虚拟数据库异地异构数据的采集及结构化。在传输负载模型及及数据存储结构的基础上进行数据源的优化整合。
进一步,所述a步骤包括:
a01,根据虚拟数据库异地异构数据的属性挖掘结果进行源组合,得到数据源整合的判决准则满足:
准则(1):
准则(2):
根据所述判决准则,进行所述虚拟数据库异地异构数据的主成分分析,在数据的特征分布属性集中,设{u1,...,un}代表包含的若干虚拟节点集合的所述数据库异地异构数据的类空间分布集合,{v1,...,vm}代表语义本体节点集合,r=[ru,v]n×m表示所述虚拟数据库异地异构数据的属性规则集;
a02,结合所述虚拟数据库异地异构数据的特征编码方法进行信息采样,采用分组检测方法,进行所述虚拟数据库异地异构数据的分集调度,推公式如下:
用cintrai(n)表示所述虚拟数据库异地异构数据访问节点i的最优间隔,cinteri(n)表示竞争节点i的总时隙,得到所述虚拟数据库异地异构数据的分布式重组结构式为:
x(n)={x(n),x(n+τ),…,x(n+(m-1)τ)}n=1,2,…,n(13)
其中,τ表示所述虚拟数据库异地异构数据在高维相空间中的嵌入延迟;
a03,结合所述虚拟数据库异地异构数据的离散融合处理,对数据库中的异地异构数据进行整合处理。
进一步,所述b步骤包括:
b01,设置虚拟数据库异地异构数据特征构成的数据集合x,建立状态转移模型,所述虚拟数据库异地异构数据的特征评价概念集表达式为:
挖掘所述虚拟数据库异地异构数据的属性关联规则为:
特征量表示为:
b02,采用云稀疏散乱点结构重组方法,得到第i个所述虚拟数据库异地异构数据的散乱点集为pi=(pi1,pi2,lpid),其中:
j∈ni(k),ni(k)={||xj(k)-xi(k)||<rd(k)}(15)
调整所述虚拟数据库异地异构数据的关联规则项,构建所述虚拟数据库异地异构数据的模糊信息融合模型:
在强干扰下的所述虚拟数据库异地异构数据源整合的边值收敛条件满足如下边界函数为:
b03,采用点云结构网格分区方法进行异地异构数据的稀疏性特征提取和融合处理,建立所述异地异构数据的主成分分析模型,采用非线性统计序列分析方法进行所述虚拟数据库异地异构数据结构重组,得到虚拟数据库异地异构数据源整合模型为:
其中,k=n-(m-1)τ表示的虚拟数据库异地异构数据源整合的嵌入维数,m为虚拟节点和虚拟链路层数,si=(xi,xi+τ,…,xi+(m-1)τ)t是空间分布特征量。
据此,采用相似度融合方法实现对虚拟数据库异地异构数据源整合。
有益效果:该发明构建虚拟数据库异地异构数据的传输负载模型及数据存储结构,用以提取数据存储结构的稀疏性特征;基于挖掘虚拟数据库异地异构数据的属性关联规则特征量,利用特征量融合异地异构数据的模糊信息,建立数据整合模型,实现虚拟数据库异地异构数据源整合。解决了现有的方法中存在时间开销较大、查准率低等问题。
附图说明
图1为本实施例的实施流程示意图;
图2为本实施例的虚拟数据库的分布式拓扑结构模型图;
具体实施方式
以下将结合实施例对本发明涉及的基于虚拟数据库的电力通信网络异地异构数据源整合方法技术方案进一步详细说明。
如图1、图2所示,本实施例的基于虚拟数据库的电力通信网络异地异构数据源整合方法,该方法包括以下步骤:
步骤一,进行传输负载模型及数据存储结构的构建与重组;
为实现对虚拟数据库异地异构数据源整合算法的优化设计,需利用虚拟数据库异地异构数据存储节点的分布式结构重组方法,构建异地异构数据的传输负载模型;利用相空间重构方法进行虚拟数据库异地异构数据的特征重构,根据重构特征建立虚拟数据库异地异构存储结构模型。
步骤二,进行异地异构数据源整合优化;
在传输负载模型与数据存储结构的基础上,进行异地异构数据源整合及优化。本节将采用虚拟数据库技术实现数据源整合的过程,该技术的主要内容包括对异地异构数据的稀疏性特征提取,以及数据源整合模型的构建。
使用时,首先需提取异地异构数据源中的数据特征,在对异地异构数据的特征提取基础上,通过挖掘虚拟数据库异地异构数据的有效特征值,构建虚拟数据库异地异构数据的整合模型,实现虚拟数据库异地异构数据源整合。
进一步,其中所述步骤一包括以下子步骤:
a,构建异地异构数据的传输负载模型;
为了在模糊网格区域聚类环境下,得到源组合模式下异地异构数据的边缘特征分布集;
b,存储结构重组;
采用相空间重构方法进行虚拟数据库异地异构数据的特征重构,实现储存结构的重组。
进一步,其中所述步骤二包括以下子步骤:
a,异地异构数据的稀疏性特征提取;
在采用相空间重构方法进行虚拟数据库异地异构数据的数据存储结构重构的基础上,进行异地异构数据源整合方法的优化设计。
b,虚拟数据库异地异构数据源整合。
进一步,所述a步骤包括:
a01,用二元有向图g=(v,e)表示虚拟数据库异地异构数据的图模型结构,其中,v是虚拟数据库的分布节点的顶点集;e是虚拟数据库异地异构数据的有向边集合;
a02,设m1,m2lmn为虚拟数据库异地的sink存储节点,采用多元回归分析方法提取异地异构数据的相关性统计特征量,得到虚拟数据库的分布式拓扑结构模型;
a03,结合a02中的所述虚拟数据库的分布式拓扑结构模型,获取虚拟数据库异地异构数据检测的测度信息;
a04,在存储网络结构模型中,数据组合模型的有向图向量的加权系数为ws={w1,w2,l,wk},在虚拟数据库异地异构数据的信息覆盖区域,假设m个传输链路层,统计数据的离散分布形式为x(k-1),….,x(k-m),则虚拟数据库异地异构数据的模糊节点差分xs的估计值:
式(1)中,ws代表差分系数,基于模糊节点差分的估计值,构建虚拟数据库异地异构数据的传输负载模型:
式(2)中
式(3)中,ω(t)为虚拟节点的数据维数;ph(t)为虚拟数据库异地异构数据source与sink储存节点之间的距离;bi为异地异构数据的传输负载损失量。
进一步,所述b步骤包括:
b01,对异地异构数据进行离散融合处理:
式(4)中,tv代表顶点集的融合系数;βv代表数据离散估计参量;adj(a,c)表示重构向量a与c的个数,经式(4)得到异地异构数据的离散融合函数tr;
b02,利用b01中的所述tr函数求得异地异构数据分布特征集t0的统计特征量:
t0={t1,t2,...,t0}(5)
其中,对所述特征集t0求解特征量:
根据求得的所述特征量进行特征重组:
βd=(mpdist-d+1)/mpdist,d∈[2,mpdist](7)
采用特征提取技术在所述特征重组的数据特征中抽取平均互信息特征量,得到虚拟数据库异地异构数据的存储结构重构过程为:
i(q,s)=h(q)-h(q|s)(8)
其中
b03,结合所述平均互信息特征量,采用模糊相关性特征匹配方法进行虚拟数据库异地异构数据的主成分分析,实现数据存储结构重组。
通过对异地异构数据进行离散融合处理,计算密集场景中虚拟数据库异地异构数据分布特征集t0的统计特征量,完成储存结构的重组。
通过虚拟数据库异地异构数据的传输负载模型及数据存储结构的构建与重组,完成虚拟数据库异地异构数据的采集及结构化。在传输负载模型及及数据存储结构的基础上进行数据源的优化整合。
进一步,所述a步骤包括:
a01,根据虚拟数据库异地异构数据的属性挖掘结果进行源组合,得到数据源整合的判决准则满足:
准则(1):
准则(2):
根据所述判决准则,进行所述虚拟数据库异地异构数据的主成分分析,在数据的特征分布属性集中,设{u1,...,un}代表包含的若干虚拟节点集合的所述数据库异地异构数据的类空间分布集合,{v1,...,vm}代表语义本体节点集合,r=[ru,v]n×m表示所述虚拟数据库异地异构数据的属性规则集;
a02,结合所述虚拟数据库异地异构数据的特征编码方法进行信息采样,采用分组检测方法,进行所述虚拟数据库异地异构数据的分集调度,推公式如下:
用cintrai(n)表示所述虚拟数据库异地异构数据访问节点i的最优间隔,cinteri(n)表示竞争节点i的总时隙,得到所述虚拟数据库异地异构数据的分布式重组结构式为:
x(n)={x(n),x(n+τ),…,x(n+(m-1)τ)}n=1,2,…,n(13)
其中,τ表示所述虚拟数据库异地异构数据在高维相空间中的嵌入延迟;
a03,结合所述虚拟数据库异地异构数据的离散融合处理,对数据库中的异地异构数据进行整合处理。
进一步,所述b步骤包括:
b01,设置虚拟数据库异地异构数据特征构成的数据集合x,建立状态转移模型,所述虚拟数据库异地异构数据的特征评价概念集表达式为:
挖掘所述虚拟数据库异地异构数据的属性关联规则为:
特征量表示为:
b02,采用云稀疏散乱点结构重组方法,得到第i个所述虚拟数据库异地异构数据的散乱点集为pi=(pi1,pi2,lpid),其中:
j∈ni(k),ni(k)={||xj(k)-xi(k)||<rd(k)}(15)
调整所述虚拟数据库异地异构数据的关联规则项,构建所述虚拟数据库异地异构数据的模糊信息融合模型:
在强干扰下的所述虚拟数据库异地异构数据源整合的边值收敛条件满足如下边界函数为:
b03,采用点云结构网格分区方法进行异地异构数据的稀疏性特征提取和融合处理,建立所述异地异构数据的主成分分析模型,采用非线性统计序列分析方法进行所述虚拟数据库异地异构数据结构重组,得到虚拟数据库异地异构数据源整合模型为:
其中,k=n-(m-1)τ表示的虚拟数据库异地异构数据源整合的嵌入维数,m为虚拟节点和虚拟链路层数,si=(xi,xi+τ,=,xi+(m-1)τ)t是空间分布特征量。
据此,采用相似度融合方法实现对虚拟数据库异地异构数据源整合。
该发明构建虚拟数据库异地异构数据的传输负载模型及数据存储结构,用以提取数据存储结构的稀疏性特征;基于挖掘虚拟数据库异地异构数据的属性关联规则特征量,利用特征量融合异地异构数据的模糊信息,建立数据整合模型,实现虚拟数据库异地异构数据源整合。解决了现有的方法中存在时间开销较大、查准率低等问题。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!